您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,于1.2版本引入。主要目的是为了解决数据流与外部系统交互时的通信延迟(比如等待外部系统的响应)成为了系统瓶颈的问题。对于实时处理,当需要使用外部存储数据的时候,需要小心对待,不能让与外部系统之间的交互延迟对流处理的整个工作进度起决定性的影响。
例如,在mapfunction等算子里访问外部存储,实际上该交互过程是同步的:比如请求a发送到数据库,那么mapfunction会一直等待响应。在很多案例中,这个等待过程是非常浪费函数时间的。与数据库异步交互,意味着单个函数实例可以并发处理很多请求,同时并发接收响应。那么,等待的时候由于也会发送其它请求和接收其它响应,被重复使用而节省了时间。至少,等待时间在多个请求上被摊销。这就使得很多使用案例具有更高的吞吐量。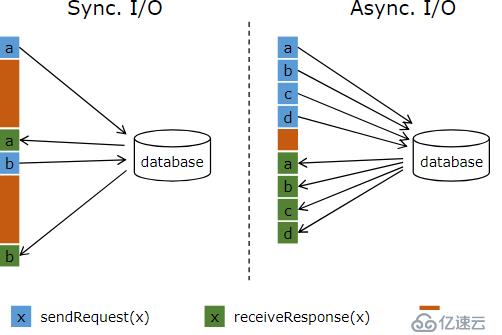
图1.1 flink--异步IO
注意:通过增加MapFunction的到一个较大的并行度也是可以改善吞吐量的,但是这就意味着更高的资源开销:更多的MapFunction实例意味着更多的task,线程,flink内部网络连接,数据库的链接,缓存,更多内部状态开销。
使用flink的异步IO时,需要所连接的数据库支持异步客户端。幸运的是很多流行的数据库支持这样的客户端。假如没有异步客户端,也可以创建多个同步客户端,放到线程池里,使用线程池来完成异步功能。当然,该种方式相对于异步客户端更低效。
flink异步IO的API支持用户在data stream中使用异步请求客户端。API自身处理与数据流的整合,消息顺序,时间时间,容错等。
假如有目标数据库的异步客户端,使用异步IO,需要实现一下三步:
1、实现AsyncFunction或者RichAsyncFunction,该函数实现了请求异步分发的功能。
2、一个callback回调,该函数取回操作的结果,然后传递给ResultFuture。
3、对DataStream使用异步IO操作。
可以看看AsyncFunction这个接口的源码
public interface AsyncFunction<IN, OUT> extends Function, Serializable {
void asyncInvoke(IN var1, ResultFuture<OUT> var2) throws Exception;
default void timeout(IN input, ResultFuture<OUT> resultFuture) throws Exception {
resultFuture.completeExceptionally(new TimeoutException("Async function call has timed out."));
}
}主要需要实现两个方法:
void asyncInvoke(IN var1, ResultFuture<OUT> var2):
这是真正实现外部操作逻辑的方法,var1是输入的参数,var2则是返回结果的集合
default void timeout(IN input, ResultFuture<OUT> resultFuture)
这是当异步请求超时的时候,会调用这个方法。参数的用途和上面一样而RichAsyncFunction由于继承了RichAsyncFunction类,所以还提供了open和close这两个方法,一般我们的用法是,open方法中创建连接外部存储的client连接(比如连接mysql的jdbc连接),close 用于关闭client连接,至于asyncInvoke和timeout两个方法的用法和上面一样,这里不重复。一般我们常用的是RichAsyncFunction。
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** The database specific client that can issue concurrent requests with callbacks */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// issue the asynchronous request, receive a future for result
final Future<String> result = client.query(key);
// set the callback to be executed once the request by the client is complete
// the callback simply forwards the result to the result future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// create the original stream
DataStream<String> stream = ...;
// 将异步IO类应用于数据流
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);要注意的是,最后需要将查询到的数据放入 resultFuture 中,即通过resultFuture.complete来将结果传递给框架。第一次调用 ResultFuture.complete的时候 ResultFuture就会完成。所有后续的complete调用都会被忽略。
参数有4个,in、asyncObject、timeout、timeUnit、capacity
in:输入的数据流
asyncObject:异步IO操作类对象
timeout:
异步IO请求被视为失败的超时时间,超过该时间异步请求就算失败。该参数主要是为了剔除死掉或者失败的请求。
timeUnit:时间的单位,例如TimeUnit.MICROSECONDS,表示毫秒
capacity:
该参数定义了同时最多有多少个异步请求在处理。即使异步IO的方式会导致更高的吞吐量,但是对于实时应用来说该操作也是一个瓶颈。限制并发请求数,算子不会积压过多的未处理请求,但是一旦超过容量的显示会触发背压。当一个异步IO请求多次超时,默认情况下会抛出一个异常,然后重启job。如果想处理超时,可以覆盖AsyncFunction.timeout方法。
AsyncFunction发起的并发请求完成的顺序是不可预期的。为了控制结果发送的顺序,flink提供了两种模式:
1). Unordered
结果记录在异步请求结束后立刻发送。流中的数据在经过该异步IO操作后顺序就和以前不一样了,也就是请求的顺序和请求结果的顺序的不能保证一致。当使用处理时间作为基础时间特性的时候,该方式具有极低的延迟和极低的负载。调用方式AsyncDataStream.unorderedWait(...)
2). Ordered
该种方式流的顺序会被保留。结果记录发送的顺序和异步请求被触发的顺序一样,该顺序就是原来流中事件的顺序。为了实现该目标,操作算子会在该结果记录之前的记录为发送之前缓存该记录。这往往会引入额外的延迟和一些Checkpoint负载,因为相比于无序模式结果记录会保存在Checkpoint状态内部较长的时间。调用方式AsyncDataStream.orderedWait(...)
当使用事件时间的时候,异步IO操作也会正确的处理watermark机制。这就意味着两种order模式的具体操作如下:
1). Unordered
watermark不会超过记录,意味着watermark建立了一个order边界。记录仅会在两个watermark之间无序发射。当前watermark之后的记录仅会在当前watermark发送之后发送。watermark也仅会在该watermark之前的所有记录发射完成之后发送。这就意味着在存在watermark的情况下,无序模式引入了一些与有序模式相同的延迟和管理开销。开销的大小取决于watermark的频率。也就是watermark之间是有序的,但是同一个watermark内部的请求是无序的
2). Ordered
watermark的顺序就如记录的顺序一样被保存。与处理时间相比,开销没有显著变化。请记住,注入时间 Ingestion Time是基于源处理时间自动生成的watermark事件时间的特殊情况。
异步IO操作提供了仅一次处理的容错担保。它会将在传出的异步IO请求保存于Checkpoint,然后故障恢复的时候从Checkpoint中恢复这些请求。
1、maven的pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>SparkDemo</groupId>
<artifactId>SparkDemoTest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.1.0</spark.version>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.3</hadoop.version>
<scala.binary.version>2.11</scala.binary.version>
<flink.version>1.6.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.0</version>
</dependency>
<!--因为spark和es默认依赖的netty版本不一致,前者使用3.x版本,后者使用4.1.32版本
所以导致es使用的是3.x版本,有些方法不兼容,这里直接使用使用新版本,否则报错-->
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.32.Final</version>
</dependency>
<!--flink-->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.1</version>
<!--<scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>1.6.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--mysql异步客户端-->
<!-- https://mvnrepository.com/artifact/io.vertx/vertx-core -->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>3.7.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-jdbc-client</artifactId>
<version>3.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.vertx/vertx-web -->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web</artifactId>
<version>3.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.2</version>
</dependency>
</dependencies>
<!--下面这是maven打包scala的插件,一定要,否则直接忽略scala代码-->
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>2、源代码
目标mysql表的格式为:
id name
1 king
2 tao
3 ming
需要根据name查询到id代码:
package flinktest;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import io.vertx.core.Vertx;
import io.vertx.core.VertxOptions;
import io.vertx.core.json.JsonObject;
import io.vertx.ext.jdbc.JDBCClient;
import io.vertx.ext.sql.ResultSet;
import io.vertx.ext.sql.SQLClient;
import io.vertx.ext.sql.SQLConnection;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* flink 异步IO demo:使用异步IO和mysql交互
* 因为普通的jdbc客户端不支持异步方式,所以这里引入vertx
* 的异步jdbc client(异步IO要求客户端支持异步操作)
*
* 实现目标:根据数据源,使用异步IO从mysql查询对应的数据, 然后打印出来
*/
public class AsyncToMysql {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<String> sourceList = new ArrayList<>();
//构建数据源查询条件,后面用来作为sql查询中where的查询值
sourceList.add("king");
sourceList.add("tao");
DataStreamSource<String> source = env.fromCollection(sourceList);
//调用异步IO处理类
DataStream<JsonObject> result = AsyncDataStream.unorderedWait(
source,
new MysqlAsyncFunc(),
10, //这里超时时长如果在本地idea跑的话不要设置得太短,因为本地执行延迟比较大
TimeUnit.SECONDS,
20).setParallelism(1);
result.print();
try {
env.execute("TEST async");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 继承 RichAsyncFunction类,编写自定义的异步IO处理类
*/
private static class MysqlAsyncFunc extends RichAsyncFunction<String, JsonObject> {
private transient SQLClient mysqlClient;
private Cache<String, String> cache;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//构建mysql查询缓存,这里使用Caffeine这个高性能缓存库
cache = Caffeine
.newBuilder()
.maximumSize(1025)
.expireAfterAccess(10, TimeUnit.MINUTES) //设置缓存过期时间
.build();
//构建mysql jdbc连接
JsonObject mysqlClientConfig = new JsonObject();
//设置jdbc连接参数
mysqlClientConfig.put("url", "jdbc:mysql://192.168.50.121:3306/test?useSSL=false&serverTimezone=UTC&useUnicode=true")
.put("driver_class", "com.mysql.cj.jdbc.Driver")
.put("max_pool_size", 20)
.put("user", "root")
.put("password", "xxxxx");
//设置vertx的工作参数,比如线程池大小
VertxOptions vo = new VertxOptions();
vo.setEventLoopPoolSize(10);
vo.setWorkerPoolSize(20);
Vertx vertx = Vertx.vertx(vo);
mysqlClient = JDBCClient.createNonShared(vertx, mysqlClientConfig);
if (mysqlClient != null) {
System.out.println("连接mysql成功!!!");
}
}
//清理环境
@Override
public void close() throws Exception {
super.close();
//关闭mysql连接,清除缓存
if (mysqlClient != null) {
mysqlClient.close();
}
if (cache != null) {
cache.cleanUp();
}
}
@Override
public void asyncInvoke(String input, ResultFuture<JsonObject> resultFuture) throws Exception {
System.out.println("key is:" + input);
String key = input;
//先从缓存中查找,找到就直接返回
String cacheIfPresent = cache.getIfPresent(key);
JsonObject output = new JsonObject();
if (cacheIfPresent != null) {
output.put("name", key);
output.put("id-name", cacheIfPresent);
resultFuture.complete(Collections.singleton(output));
//return;
}
System.out.println("开始查询");
mysqlClient.getConnection(conn -> {
if (conn.failed()) {
resultFuture.completeExceptionally(conn.cause());
//return;
}
final SQLConnection sqlConnection = conn.result();
//拼接查询语句
String querySql = "select id,name from customer where name='" + key + "'";
System.out.println("执行的sql为:" + querySql);
//执行查询,并获取结果
sqlConnection.query(querySql, res -> {
if (res.failed()) {
resultFuture.completeExceptionally(null);
System.out.println("执行失败");
//return;
}
if (res.succeeded()) {
System.out.println("执行成功,获取结果");
ResultSet result = res.result();
List<JsonObject> rows = result.getRows();
System.out.println("结果个数:" + String.valueOf(rows.size()));
if (rows.size() <= 0) {
resultFuture.complete(null);
//return;
}
//结果返回,并更新到缓存中
for (JsonObject row : rows) {
String name = row.getString("name");
String id = row.getInteger("id").toString();
String desc = id + "-" + name;
System.out.println("结果:" + desc);
output.put("name", key);
output.put("id-name", desc);
cache.put(key, desc);
resultFuture.complete(Collections.singleton(output));
}
} else {
//执行失败,返回空
resultFuture.complete(null);
}
});
//连接关闭
sqlConnection.close(done -> {
if (done.failed()) {
throw new RuntimeException(done.cause());
}
});
});
}
}
}
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。