жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
зәҝзЁӢжұ
вҖңзәҝзЁӢжұ вҖқпјҢйЎҫеҗҚжҖқд№үе°ұжҳҜдёҖдёӘзәҝзЁӢзј“еӯҳпјҢзәҝзЁӢжҳҜзЁҖзјәиө„жәҗпјҢеҰӮжһңиў«ж— йҷҗеҲ¶зҡ„еҲӣе»әпјҢдёҚд»…дјҡж¶ҲиҖ—зі»з»ҹиө„жәҗпјҢиҝҳдјҡйҷҚдҪҺзі»з»ҹзҡ„зЁіе®ҡжҖ§пјҢеӣ жӯӨJavaдёӯжҸҗдҫӣзәҝзЁӢжұ еҜ№зәҝзЁӢиҝӣиЎҢз»ҹдёҖеҲҶй…ҚгҖҒи°ғдјҳе’Ңзӣ‘жҺ§гҖӮ

зәҝзЁӢжұ д»Ӣз»Қ
еңЁwebејҖеҸ‘дёӯпјҢжңҚеҠЎеҷЁйңҖиҰҒжҺҘеҸ—并еӨ„зҗҶиҜ·жұӮпјҢжүҖд»ҘдјҡдёәдёҖдёӘиҜ·жұӮжқҘеҲҶй…ҚдёҖдёӘзәҝзЁӢжқҘиҝӣиЎҢеӨ„зҗҶгҖӮеҰӮжһңжҜҸж¬ЎиҜ·жұӮйғҪж–°еҲӣе»әдёҖдёӘзәҝзЁӢзҡ„иҜқе®һзҺ°иө·жқҘйқһеёёз®ҖдҫҝпјҢдҪҶжҳҜеӯҳеңЁдёҖдёӘй—®йўҳпјҡ
еҰӮжһң并еҸ‘зҡ„иҜ·жұӮж•°йҮҸйқһеёёеӨҡпјҢдҪҶжҜҸдёӘзәҝзЁӢжү§иЎҢзҡ„ж—¶й—ҙеҫҲзҹӯпјҢиҝҷж ·е°ұдјҡйў‘з№Ғзҡ„еҲӣе»әе’Ңй”ҖжҜҒзәҝзЁӢпјҢеҰӮжӯӨдёҖжқҘдјҡеӨ§еӨ§йҷҚдҪҺзі»з»ҹзҡ„ж•ҲзҺҮгҖӮеҸҜиғҪеҮәзҺ°жңҚеҠЎеҷЁеңЁдёәжҜҸдёӘиҜ·жұӮеҲӣе»әж–°зәҝзЁӢе’Ңй”ҖжҜҒзәҝзЁӢдёҠиҠұиҙ№зҡ„ж—¶й—ҙе’Ңж¶ҲиҖ—зҡ„зі»з»ҹиө„жәҗиҰҒжҜ”еӨ„зҗҶе®һйҷ…зҡ„з”ЁжҲ·иҜ·жұӮзҡ„ж—¶й—ҙе’Ңиө„жәҗжӣҙеӨҡгҖӮ
йӮЈд№ҲжңүжІЎжңүдёҖз§ҚеҠһжі•дҪҝжү§иЎҢе®ҢдёҖдёӘд»»еҠЎпјҢ并дёҚиў«й”ҖжҜҒпјҢиҖҢжҳҜеҸҜд»Ҙ继з»ӯжү§иЎҢе…¶д»–зҡ„д»»еҠЎе‘ўпјҹ
иҝҷе°ұжҳҜзәҝзЁӢжұ зҡ„зӣ®зҡ„дәҶгҖӮзәҝзЁӢжұ дёәзәҝзЁӢз”ҹе‘Ҫе‘Ёжңҹзҡ„ејҖй”Җе’Ңиө„жәҗдёҚи¶ій—®йўҳжҸҗдҫӣдәҶи§ЈеҶіж–№жЎҲгҖӮйҖҡиҝҮеҜ№еӨҡдёӘд»»еҠЎйҮҚз”ЁзәҝзЁӢпјҢзәҝзЁӢеҲӣе»әзҡ„ејҖй”Җиў«еҲҶж‘ҠеҲ°дәҶеӨҡдёӘд»»еҠЎдёҠгҖӮ
д»Җд№Ҳж—¶еҖҷдҪҝз”ЁзәҝзЁӢжұ пјҹ
еҚ•дёӘд»»еҠЎеӨ„зҗҶж—¶й—ҙжҜ”иҫғзҹӯ
йңҖиҰҒеӨ„зҗҶзҡ„д»»еҠЎж•°йҮҸеҫҲеӨ§
зәҝзЁӢжұ дјҳеҠҝ
йҮҚз”ЁеӯҳеңЁзҡ„зәҝзЁӢпјҢеҮҸе°‘зәҝзЁӢеҲӣе»әпјҢж¶ҲдәЎзҡ„ејҖй”ҖпјҢжҸҗй«ҳжҖ§иғҪ
жҸҗй«ҳе“Қеә”йҖҹеәҰгҖӮеҪ“д»»еҠЎеҲ°иҫҫж—¶пјҢд»»еҠЎеҸҜд»ҘдёҚйңҖиҰҒзҡ„зӯүеҲ°зәҝзЁӢеҲӣе»әе°ұиғҪз«ӢеҚіжү§иЎҢгҖӮ
жҸҗй«ҳзәҝзЁӢзҡ„еҸҜз®ЎзҗҶжҖ§гҖӮзәҝзЁӢжҳҜзЁҖзјәиө„жәҗпјҢеҰӮжһңж— йҷҗеҲ¶зҡ„еҲӣе»әпјҢдёҚд»…дјҡж¶ҲиҖ—зі»з»ҹиө„жәҗпјҢиҝҳдјҡйҷҚдҪҺзі»з»ҹзҡ„зЁіе®ҡжҖ§пјҢдҪҝз”ЁзәҝзЁӢжұ еҸҜд»ҘиҝӣиЎҢз»ҹдёҖзҡ„еҲҶй…ҚпјҢи°ғдјҳе’Ңзӣ‘жҺ§гҖӮ
зәҝзЁӢзҡ„е®һзҺ°ж–№ејҸ
Runnable,Thread,Callable
//В е®һзҺ°RunnableжҺҘеҸЈзҡ„зұ»е°Ҷиў«Threadжү§иЎҢпјҢиЎЁзӨәдёҖдёӘеҹәжң¬зҡ„д»»еҠЎ
publicВ interfaceВ RunnableВ {
//В runж–№жі•е°ұжҳҜе®ғжүҖжңүзҡ„еҶ…е®№пјҢе°ұжҳҜе®һйҷ…жү§иЎҢзҡ„д»»еҠЎ
publicВ abstractВ voidВ run();
}
//CallableеҗҢж ·жҳҜд»»еҠЎпјҢдёҺRunnableжҺҘеҸЈзҡ„еҢәеҲ«еңЁдәҺе®ғжҺҘ收жіӣеһӢпјҢеҗҢж—¶е®ғжү§иЎҢд»»еҠЎеҗҺеёҰжңүиҝ”еӣһеҶ…е®№
publicВ interfaceВ Callable<V>В {
//В зӣёеҜ№дәҺrunж–№жі•зҡ„еёҰжңүиҝ”еӣһеҖјзҡ„callж–№жі•
VВ call()В throwsВ Exception;
}ExecutorжЎҶжһ¶
ExecutorжҺҘеҸЈжҳҜзәҝзЁӢжұ жЎҶжһ¶дёӯжңҖеҹәзЎҖзҡ„йғЁеҲҶпјҢе®ҡд№үдәҶдёҖдёӘз”ЁдәҺжү§иЎҢRunnableзҡ„executeж–№жі•гҖӮ
дёӢеӣҫдёәе®ғзҡ„继жүҝдёҺе®һзҺ°
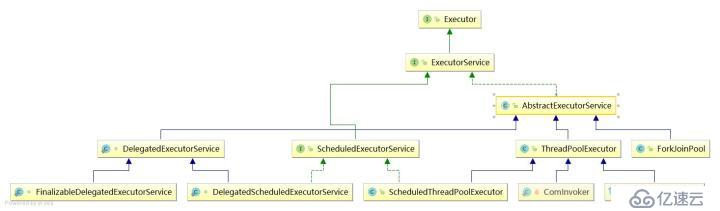
д»ҺеӣҫдёӯеҸҜд»ҘзңӢеҮәExecutorдёӢжңүдёҖдёӘйҮҚиҰҒеӯҗжҺҘеҸЈExecutorServiceпјҢе…¶дёӯе®ҡд№үдәҶзәҝзЁӢжұ зҡ„е…·дҪ“иЎҢдёә
1пјҢexecuteпјҲRunnable commandпјүпјҡеұҘиЎҢRuannableзұ»еһӢзҡ„д»»еҠЎ,
2пјҢsubmitпјҲtaskпјүпјҡеҸҜз”ЁжқҘжҸҗдәӨCallableжҲ–Runnableд»»еҠЎпјҢ并иҝ”еӣһд»ЈиЎЁжӯӨд»»еҠЎзҡ„FutureеҜ№иұЎ
3пјҢshutdownпјҲпјүпјҡеңЁе®ҢжҲҗе·ІжҸҗдәӨзҡ„д»»еҠЎеҗҺе°Ғй—ӯеҠһдәӢпјҢдёҚеҶҚжҺҘз®Ўж–°д»»еҠЎ,
4пјҢshutdownNowпјҲпјүпјҡеҒңжӯўжүҖжңүжӯЈеңЁеұҘиЎҢзҡ„д»»еҠЎе№¶е°Ғй—ӯеҠһдәӢгҖӮ
5пјҢisTerminatedпјҲпјүпјҡжөӢиҜ•жҳҜеҗҰжүҖжңүд»»еҠЎйғҪеұҘиЎҢе®ҢжҜ•дәҶгҖӮ
6пјҢisShutdownпјҲпјүпјҡжөӢиҜ•жҳҜеҗҰиҜҘExecutorServiceе·Іиў«е…ій—ӯгҖӮ

зәҝзЁӢжұ йҮҚзӮ№еұһжҖ§
privateВ finalВ AtomicIntegerВ ctlВ =В newВ AtomicInteger(ctlOf(RUNNING,В 0)); privateВ staticВ finalВ intВ COUNT_BITSВ =В Integer.SIZEВ -В 3; privateВ staticВ finalВ intВ CAPACITYВ =В (1В <<В COUNT_BITS)В -В 1;
ctl жҳҜеҜ№зәҝзЁӢжұ зҡ„иҝҗиЎҢзҠ¶жҖҒе’ҢзәҝзЁӢжұ дёӯжңүж•ҲзәҝзЁӢзҡ„ж•°йҮҸиҝӣиЎҢжҺ§еҲ¶зҡ„дёҖдёӘеӯ—ж®өпјҢ е®ғеҢ…еҗ«дёӨйғЁеҲҶзҡ„дҝЎжҒҜ: зәҝзЁӢжұ зҡ„иҝҗиЎҢзҠ¶жҖҒ (runState) е’ҢзәҝзЁӢжұ еҶ…жңүж•ҲзәҝзЁӢзҡ„ж•°йҮҸ (workerCount)пјҢиҝҷйҮҢеҸҜд»ҘзңӢеҲ°пјҢдҪҝз”ЁдәҶIntegerзұ»еһӢжқҘдҝқеӯҳпјҢй«ҳ3дҪҚдҝқеӯҳrunStateпјҢдҪҺ29дҪҚдҝқеӯҳworkerCountгҖӮCOUNT_BITS е°ұжҳҜ29пјҢCAPACITYе°ұжҳҜ1е·Ұ移29дҪҚеҮҸ1пјҲ29дёӘ1пјүпјҢиҝҷдёӘеёёйҮҸиЎЁзӨәworkerCountзҡ„дёҠйҷҗеҖјпјҢеӨ§зәҰжҳҜ5дәҝгҖӮ
ctlзӣёе…іж–№жі•
privateВ staticВ intВ runStateOf(intВ c)В {В returnВ cВ &В ~CAPACITY;В }
privateВ staticВ intВ workerCountOf(intВ c)В {В returnВ cВ &В CAPACITY;В }
privateВ staticВ intВ ctlOf(intВ rs,В intВ wc)В {В returnВ rsВ |В wc;В }runStateOfпјҡиҺ·еҸ–иҝҗиЎҢзҠ¶жҖҒпјӣ
workerCountOfпјҡиҺ·еҸ–жҙ»еҠЁзәҝзЁӢж•°пјӣ
ctlOfпјҡиҺ·еҸ–иҝҗиЎҢзҠ¶жҖҒе’Ңжҙ»еҠЁзәҝзЁӢж•°зҡ„еҖјгҖӮ
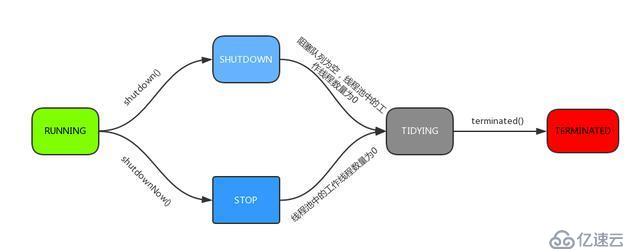
зәҝзЁӢжұ еӯҳеңЁ5з§ҚзҠ¶жҖҒ
RUNNINGВ =В -1В <<В COUNT_BITS;В //й«ҳ3дҪҚдёә111 SHUTDOWNВ =В 0В <<В COUNT_BITS;В //й«ҳ3дҪҚдёә000 STOPВ =В 1В <<В COUNT_BITS;В //й«ҳ3дҪҚдёә001 TIDYINGВ =В 2В <<В COUNT_BITS;В //й«ҳ3дҪҚдёә010 TERMINATEDВ =В 3В <<В COUNT_BITS;В //й«ҳ3дҪҚдёә011
1гҖҒRUNNING
(1) зҠ¶жҖҒиҜҙжҳҺпјҡзәҝзЁӢжұ еӨ„еңЁRUNNINGзҠ¶жҖҒж—¶пјҢиғҪеӨҹжҺҘ收新任еҠЎпјҢд»ҘеҸҠеҜ№е·Іж·»еҠ зҡ„д»»еҠЎиҝӣиЎҢеӨ„зҗҶгҖӮ
(02) зҠ¶жҖҒеҲҮжҚўпјҡзәҝзЁӢжұ зҡ„еҲқе§ӢеҢ–зҠ¶жҖҒжҳҜRUNNINGгҖӮжҚўеҸҘиҜқиҜҙпјҢзәҝзЁӢжұ иў«дёҖж—Ұиў«еҲӣе»әпјҢе°ұеӨ„дәҺRUNNINGзҠ¶жҖҒпјҢ并且зәҝзЁӢжұ дёӯзҡ„д»»еҠЎж•°дёә0пјҒ
2гҖҒ SHUTDOWN
(1) зҠ¶жҖҒиҜҙжҳҺпјҡзәҝзЁӢжұ еӨ„еңЁSHUTDOWNзҠ¶жҖҒж—¶пјҢдёҚжҺҘ收新任еҠЎпјҢдҪҶиғҪеӨ„зҗҶе·Іж·»еҠ зҡ„д»»еҠЎгҖӮ
(2) зҠ¶жҖҒеҲҮжҚўпјҡи°ғз”ЁзәҝзЁӢжұ зҡ„shutdown()жҺҘеҸЈж—¶пјҢзәҝзЁӢжұ з”ұRUNNING -> SHUTDOWNгҖӮ
3гҖҒSTOP
(1) зҠ¶жҖҒиҜҙжҳҺпјҡзәҝзЁӢжұ еӨ„еңЁSTOPзҠ¶жҖҒж—¶пјҢдёҚжҺҘ收新任еҠЎпјҢдёҚеӨ„зҗҶе·Іж·»еҠ зҡ„д»»еҠЎпјҢ并且дјҡдёӯж–ӯжӯЈеңЁеӨ„зҗҶзҡ„д»»еҠЎгҖӮ
(2) зҠ¶жҖҒеҲҮжҚўпјҡи°ғз”ЁзәҝзЁӢжұ зҡ„shutdownNow()жҺҘеҸЈж—¶пјҢзәҝзЁӢжұ з”ұ(RUNNING or SHUTDOWN ) -> STOPгҖӮ
4гҖҒTIDYING
(1) зҠ¶жҖҒиҜҙжҳҺпјҡеҪ“жүҖжңүзҡ„д»»еҠЎе·Із»ҲжӯўпјҢctlи®°еҪ•зҡ„вҖқд»»еҠЎж•°йҮҸвҖқдёә0пјҢзәҝзЁӢжұ дјҡеҸҳдёәTIDYINGзҠ¶жҖҒгҖӮеҪ“зәҝзЁӢжұ еҸҳдёәTIDYINGзҠ¶жҖҒж—¶пјҢдјҡжү§иЎҢй’©еӯҗеҮҪж•°terminated()гҖӮterminated()еңЁThreadPoolExecutorзұ»дёӯжҳҜз©әзҡ„пјҢиӢҘз”ЁжҲ·жғіеңЁзәҝзЁӢжұ еҸҳдёәTIDYINGж—¶пјҢиҝӣиЎҢзӣёеә”зҡ„еӨ„зҗҶпјӣеҸҜд»ҘйҖҡиҝҮйҮҚиҪҪterminated()еҮҪж•°жқҘе®һзҺ°гҖӮ
(2) зҠ¶жҖҒеҲҮжҚўпјҡеҪ“зәҝзЁӢжұ еңЁSHUTDOWNзҠ¶жҖҒдёӢпјҢйҳ»еЎһйҳҹеҲ—дёәз©ә并且зәҝзЁӢжұ дёӯжү§иЎҢзҡ„д»»еҠЎд№ҹдёәз©әж—¶пјҢе°ұдјҡз”ұ SHUTDOWN -> TIDYINGгҖӮ еҪ“зәҝзЁӢжұ еңЁSTOPзҠ¶жҖҒдёӢпјҢзәҝзЁӢжұ дёӯжү§иЎҢзҡ„д»»еҠЎдёәз©әж—¶пјҢе°ұдјҡз”ұSTOP -> TIDYINGгҖӮ
5гҖҒ TERMINATED
(1) зҠ¶жҖҒиҜҙжҳҺпјҡзәҝзЁӢжұ еҪ»еә•з»ҲжӯўпјҢе°ұеҸҳжҲҗTERMINATEDзҠ¶жҖҒгҖӮ
(2) зҠ¶жҖҒеҲҮжҚўпјҡзәҝзЁӢжұ еӨ„еңЁTIDYINGзҠ¶жҖҒж—¶пјҢжү§иЎҢе®Ңterminated()д№ӢеҗҺпјҢе°ұдјҡз”ұ TIDYING -> TERMINATEDгҖӮ
иҝӣе…ҘTERMINATEDзҡ„жқЎд»¶еҰӮдёӢпјҡ
зәҝзЁӢжұ дёҚжҳҜRUNNINGзҠ¶жҖҒпјӣ
зәҝзЁӢжұ зҠ¶жҖҒдёҚжҳҜTIDYINGзҠ¶жҖҒжҲ–TERMINATEDзҠ¶жҖҒпјӣ
еҰӮжһңзәҝзЁӢжұ зҠ¶жҖҒжҳҜSHUTDOWN并且workerQueueдёәз©әпјӣ
workerCountдёә0пјӣ
и®ҫзҪ®TIDYINGзҠ¶жҖҒжҲҗеҠҹгҖӮ
зәҝзЁӢжұ зҡ„е…·дҪ“е®һзҺ°
ThreadPoolExecutor й»ҳи®ӨзәҝзЁӢжұ
ScheduledThreadPoolExecutor е®ҡж—¶зәҝзЁӢжұ
ThreadPoolExecutorзәҝзЁӢжұ зҡ„еҲӣе»ә
publicВ ThreadPoolExecutor(intВ corePoolSize, В В В В В В В В В В В В В В В В В В В В В В В В В В intВ maximumPoolSize, В В В В В В В В В В В В В В В В В В В В В В В В В В longВ keepAliveTime, В В В В В В В В В В В В В В В В В В В В В В В В В В TimeUnitВ unit, В В В В В В В В В В В В В В В В В В В В В В В В В В BlockingQueue<Runnable>В workQueue, В В В В В В В В В В В В В В В В В В В В В В В В В В ThreadFactoryВ threadFactory, В В В В В В В В В В В В В В В В В В В В В В В В В В RejectedExecutionHandlerВ handler)
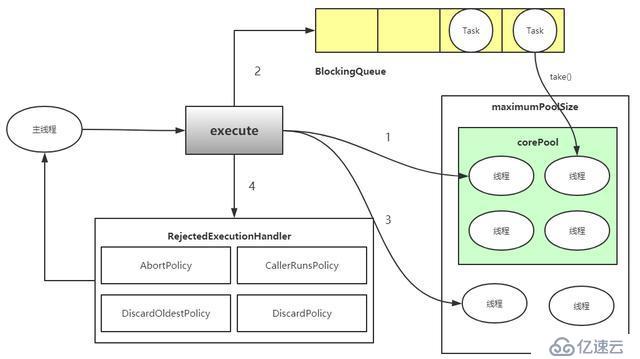
д»»еҠЎжҸҗдәӨ
1гҖҒpublicВ voidВ execute()В //жҸҗдәӨд»»еҠЎж— иҝ”еӣһеҖј 2гҖҒpublicВ Future<?>В submit()В //д»»еҠЎжү§иЎҢе®ҢжҲҗеҗҺжңүиҝ”еӣһеҖј
еҸӮж•°и§ЈйҮҠ
corePoolSize
зәҝзЁӢжұ дёӯзҡ„ж ёеҝғзәҝзЁӢж•°пјҢеҪ“жҸҗдәӨдёҖдёӘд»»еҠЎж—¶пјҢзәҝзЁӢжұ еҲӣе»әдёҖдёӘж–°зәҝзЁӢжү§иЎҢд»»еҠЎпјҢзӣҙеҲ°еҪ“еүҚзәҝзЁӢж•°зӯүдәҺcorePoolSizeпјӣеҰӮжһңеҪ“еүҚзәҝзЁӢж•°дёәcorePoolSizeпјҢ继з»ӯжҸҗдәӨзҡ„д»»еҠЎиў«дҝқеӯҳеҲ°йҳ»еЎһйҳҹеҲ—дёӯпјҢзӯүеҫ…иў«жү§иЎҢпјӣеҰӮжһңжү§иЎҢдәҶзәҝзЁӢжұ зҡ„prestartAllCoreThreads()ж–№жі•пјҢзәҝзЁӢжұ дјҡжҸҗеүҚеҲӣе»ә并еҗҜеҠЁжүҖжңүж ёеҝғзәҝзЁӢгҖӮ
maximumPoolSize
зәҝзЁӢжұ дёӯе…Ғи®ёзҡ„жңҖеӨ§зәҝзЁӢж•°гҖӮеҰӮжһңеҪ“еүҚйҳ»еЎһйҳҹеҲ—ж»ЎдәҶпјҢ且继з»ӯжҸҗдәӨд»»еҠЎпјҢеҲҷеҲӣе»әж–°зҡ„зәҝзЁӢжү§иЎҢд»»еҠЎпјҢеүҚжҸҗжҳҜеҪ“еүҚзәҝзЁӢж•°е°ҸдәҺmaximumPoolSizeпјӣ
keepAliveTime
зәҝзЁӢжұ з»ҙжҠӨзәҝзЁӢжүҖе…Ғи®ёзҡ„з©әй—Іж—¶й—ҙгҖӮеҪ“зәҝзЁӢжұ дёӯзҡ„зәҝзЁӢж•°йҮҸеӨ§дәҺcorePoolSizeзҡ„ж—¶еҖҷпјҢеҰӮжһңиҝҷж—¶жІЎжңүж–°зҡ„д»»еҠЎжҸҗдәӨпјҢж ёеҝғзәҝзЁӢеӨ–зҡ„зәҝзЁӢдёҚдјҡз«ӢеҚій”ҖжҜҒпјҢиҖҢжҳҜдјҡзӯүеҫ…пјҢзӣҙеҲ°зӯүеҫ…зҡ„ж—¶й—ҙи¶…иҝҮдәҶkeepAliveTimeпјӣ
unit
keepAliveTimeзҡ„еҚ•дҪҚпјӣ
workQueue
з”ЁжқҘдҝқеӯҳзӯүеҫ…иў«жү§иЎҢзҡ„д»»еҠЎзҡ„йҳ»еЎһйҳҹеҲ—пјҢдё”д»»еҠЎеҝ…йЎ»е®һзҺ°RunableжҺҘеҸЈпјҢеңЁJDKдёӯжҸҗдҫӣдәҶеҰӮдёӢйҳ»еЎһйҳҹеҲ—пјҡ
1гҖҒArrayBlockingQueueпјҡеҹәдәҺж•°з»„з»“жһ„зҡ„жңүз•Ңйҳ»еЎһйҳҹеҲ—пјҢжҢүFIFOжҺ’еәҸд»»еҠЎпјӣ
2гҖҒLinkedBlockingQueneпјҡеҹәдәҺй“ҫиЎЁз»“жһ„зҡ„йҳ»еЎһйҳҹеҲ—пјҢжҢүFIFOжҺ’еәҸд»»еҠЎпјҢеҗһеҗҗйҮҸйҖҡеёёиҰҒй«ҳдәҺArrayBlockingQueneпјӣ
3гҖҒSynchronousQueneпјҡдёҖдёӘдёҚеӯҳеӮЁе…ғзҙ зҡ„йҳ»еЎһйҳҹеҲ—пјҢжҜҸдёӘжҸ’е…Ҙж“ҚдҪңеҝ…йЎ»зӯүеҲ°еҸҰдёҖдёӘзәҝзЁӢи°ғ用移йҷӨж“ҚдҪңпјҢеҗҰеҲҷжҸ’е…Ҙж“ҚдҪңдёҖзӣҙеӨ„дәҺйҳ»еЎһзҠ¶жҖҒпјҢеҗһеҗҗйҮҸйҖҡеёёиҰҒй«ҳдәҺLinkedBlockingQueneпјӣ
4гҖҒpriorityBlockingQueneпјҡе…·жңүдјҳе…Ҳзә§зҡ„***йҳ»еЎһйҳҹеҲ—пјӣ
threadFactory
е®ғжҳҜThreadFactoryзұ»еһӢзҡ„еҸҳйҮҸпјҢз”ЁжқҘеҲӣе»әж–°зәҝзЁӢгҖӮй»ҳи®ӨдҪҝз”ЁExecutors.defaultThreadFactory() жқҘеҲӣе»әзәҝзЁӢгҖӮдҪҝз”Ёй»ҳи®Өзҡ„ThreadFactoryжқҘеҲӣе»әзәҝзЁӢж—¶пјҢдјҡдҪҝж–°еҲӣе»әзҡ„зәҝзЁӢе…·жңүзӣёеҗҢзҡ„NORM_PRIORITYдјҳе…Ҳзә§е№¶дё”жҳҜйқһе®ҲжҠӨзәҝзЁӢпјҢеҗҢж—¶д№ҹи®ҫзҪ®дәҶзәҝзЁӢзҡ„еҗҚз§°гҖӮж¬ўиҝҺеӨ§е®¶е…іжіЁжҲ‘зҡ„е…¬з§Қжө©гҖҗзЁӢеәҸе‘ҳиҝҪйЈҺгҖ‘пјҢж•ҙзҗҶдәҶ2019е№ҙеӨҡ家公еҸёjavaйқўиҜ•йўҳиө„ж–ҷ100еӨҡйЎөpdfж–ҮжЎЈпјҢж–Үз« йғҪдјҡеңЁйҮҢйқўжӣҙж–°пјҢж•ҙзҗҶзҡ„иө„ж–ҷд№ҹдјҡж”ҫеңЁйҮҢйқўгҖӮ
handler
зәҝзЁӢжұ зҡ„йҘұе’Ңзӯ–з•ҘпјҢеҪ“йҳ»еЎһйҳҹеҲ—ж»ЎдәҶпјҢдё”жІЎжңүз©әй—Ізҡ„е·ҘдҪңзәҝзЁӢпјҢеҰӮжһң继з»ӯжҸҗдәӨд»»еҠЎпјҢеҝ…йЎ»йҮҮеҸ–дёҖз§Қзӯ–з•ҘеӨ„зҗҶиҜҘд»»еҠЎпјҢзәҝзЁӢжұ жҸҗдҫӣдәҶ4з§Қзӯ–з•Ҙпјҡ
1гҖҒAbortPolicyпјҡзӣҙжҺҘжҠӣеҮәејӮеёёпјҢй»ҳи®Өзӯ–з•Ҙпјӣ
2гҖҒCallerRunsPolicyпјҡз”Ёи°ғз”ЁиҖ…жүҖеңЁзҡ„зәҝзЁӢжқҘжү§иЎҢд»»еҠЎпјӣ
3гҖҒDiscardOldestPolicyпјҡдёўејғйҳ»еЎһйҳҹеҲ—дёӯйқ жңҖеүҚзҡ„д»»еҠЎпјҢ并жү§иЎҢеҪ“еүҚд»»еҠЎпјӣ
4гҖҒDiscardPolicyпјҡзӣҙжҺҘдёўејғд»»еҠЎпјӣ
дёҠйқўзҡ„4з§Қзӯ–з•ҘйғҪжҳҜThreadPoolExecutorзҡ„еҶ…йғЁзұ»гҖӮ
еҪ“然д№ҹеҸҜд»Ҙж №жҚ®еә”з”ЁеңәжҷҜе®һзҺ°RejectedExecutionHandlerжҺҘеҸЈпјҢиҮӘе®ҡд№үйҘұе’Ңзӯ–з•ҘпјҢеҰӮи®°еҪ•ж—Ҙеҝ—жҲ–жҢҒд№…еҢ–еӯҳеӮЁдёҚиғҪеӨ„зҗҶзҡ„д»»еҠЎгҖӮ

зәҝзЁӢжұ зӣ‘жҺ§
publicВ longВ getTaskCount()В //зәҝзЁӢжұ е·Іжү§иЎҢдёҺжңӘжү§иЎҢзҡ„д»»еҠЎжҖ»ж•° publicВ longВ getCompletedTaskCount()В //е·Іе®ҢжҲҗзҡ„д»»еҠЎж•° publicВ intВ getPoolSize()В //зәҝзЁӢжұ еҪ“еүҚзҡ„зәҝзЁӢж•° publicВ intВ getActiveCount()В //зәҝзЁӢжұ дёӯжӯЈеңЁжү§иЎҢд»»еҠЎзҡ„зәҝзЁӢж•°йҮҸ
зәҝзЁӢжұ еҺҹзҗҶ
жәҗз ҒеҲҶжһҗ
executeж–№жі•
publicВ voidВ execute(RunnableВ command)В {
В В В В ifВ (commandВ ==В null)
В В В В В В В В throwВ newВ NullPointerException();
/*
В *В cltи®°еҪ•зқҖrunStateе’ҢworkerCount
В */
В В В В intВ cВ =В ctl.get();
/*
В *В workerCountOfж–№жі•еҸ–еҮәдҪҺ29дҪҚзҡ„еҖјпјҢиЎЁзӨәеҪ“еүҚжҙ»еҠЁзҡ„зәҝзЁӢж•°пјӣ
В *В еҰӮжһңеҪ“еүҚжҙ»еҠЁзәҝзЁӢж•°е°ҸдәҺcorePoolSizeпјҢеҲҷж–°е»әдёҖдёӘзәҝзЁӢж”ҫе…ҘзәҝзЁӢжұ дёӯпјӣ
В * 并жҠҠд»»еҠЎж·»еҠ еҲ°иҜҘзәҝзЁӢдёӯгҖӮ
В */
В В В В ifВ (workerCountOf(c)В <В corePoolSize)В {
В В В В В В В В /*
В В В В В В В В В *В addWorkerдёӯзҡ„第дәҢдёӘеҸӮж•°иЎЁзӨәйҷҗеҲ¶ж·»еҠ зәҝзЁӢзҡ„ж•°йҮҸжҳҜж №жҚ®corePoolSizeжқҘеҲӨж–ӯиҝҳжҳҜmaximumPoolSizeжқҘеҲӨж–ӯпјӣ
В В В В В В В В В *В еҰӮжһңдёәtrueпјҢж №жҚ®corePoolSizeжқҘеҲӨж–ӯпјӣ
В В В В В В В В В *В еҰӮжһңдёәfalseпјҢеҲҷж №жҚ®maximumPoolSizeжқҘеҲӨж–ӯ
В В В В В В В В В */
В В В В В В В В ifВ (addWorker(command,В true))
В В В В В В В В В В В В return;
/*
В *В еҰӮжһңж·»еҠ еӨұиҙҘпјҢеҲҷйҮҚж–°иҺ·еҸ–ctlеҖј
В */
В В В В В В В В cВ =В ctl.get();
В В В В }
/*
В *В еҰӮжһңеҪ“еүҚзәҝзЁӢжұ жҳҜиҝҗиЎҢзҠ¶жҖҒ并且任еҠЎж·»еҠ еҲ°йҳҹеҲ—жҲҗеҠҹ
В */
В В В В ifВ (isRunning(c)В &&В workQueue.offer(command))В {
В В В В В В В В //В йҮҚж–°иҺ·еҸ–ctlеҖј
В В В В В В В В intВ recheckВ =В ctl.get();
В В В В В В В В В //В еҶҚж¬ЎеҲӨж–ӯзәҝзЁӢжұ зҡ„иҝҗиЎҢзҠ¶жҖҒпјҢеҰӮжһңдёҚжҳҜиҝҗиЎҢзҠ¶жҖҒпјҢз”ұдәҺд№ӢеүҚе·Із»ҸжҠҠcommandж·»еҠ еҲ°workQueueдёӯдәҶпјҢ
В В В В В В В В //В иҝҷж—¶йңҖиҰҒ移йҷӨиҜҘcommand
В В В В В В В В //В жү§иЎҢиҝҮеҗҺйҖҡиҝҮhandlerдҪҝз”ЁжӢ’з»қзӯ–з•ҘеҜ№иҜҘд»»еҠЎиҝӣиЎҢеӨ„зҗҶпјҢж•ҙдёӘж–№жі•иҝ”еӣһ
В В В В В В В В ifВ (!В isRunning(recheck)В &&В remove(command))
В В В В В В В В В В В В reject(command);
В В В В В В В В /*
В В В В В В В В В *В иҺ·еҸ–зәҝзЁӢжұ дёӯзҡ„жңүж•ҲзәҝзЁӢж•°пјҢеҰӮжһңж•°йҮҸжҳҜ0пјҢеҲҷжү§иЎҢaddWorkerж–№жі•
В В В В В В В В В *В иҝҷйҮҢдј е…Ҙзҡ„еҸӮж•°иЎЁзӨәпјҡ
В В В В В В В В В *В 1. 第дёҖдёӘеҸӮж•°дёәnullпјҢиЎЁзӨәеңЁзәҝзЁӢжұ дёӯеҲӣе»әдёҖдёӘзәҝзЁӢпјҢдҪҶдёҚеҺ»еҗҜеҠЁпјӣ
В В В В В В В В В *В 2. 第дәҢдёӘеҸӮж•°дёәfalseпјҢе°ҶзәҝзЁӢжұ зҡ„жңүйҷҗзәҝзЁӢж•°йҮҸзҡ„дёҠйҷҗи®ҫзҪ®дёәmaximumPoolSizeпјҢж·»еҠ зәҝзЁӢж—¶ж №жҚ®maximumPoolSizeжқҘеҲӨж–ӯпјӣ
В В В В В В В В В *В еҰӮжһңеҲӨж–ӯworkerCountеӨ§дәҺ0пјҢеҲҷзӣҙжҺҘиҝ”еӣһпјҢеңЁworkQueueдёӯж–°еўһзҡ„commandдјҡеңЁе°ҶжқҘзҡ„жҹҗдёӘж—¶еҲ»иў«жү§иЎҢгҖӮ
В В В В В В В В В */
В В В В В В В В elseВ ifВ (workerCountOf(recheck)В ==В 0)
В В В В В В В В В В В В addWorker(null,В false);
В В В В }
/*
В *В еҰӮжһңжү§иЎҢеҲ°иҝҷйҮҢпјҢжңүдёӨз§Қжғ…еҶөпјҡ
В *В 1.В зәҝзЁӢжұ е·Із»ҸдёҚжҳҜRUNNINGзҠ¶жҖҒпјӣ
В *В 2.В зәҝзЁӢжұ жҳҜRUNNINGзҠ¶жҖҒпјҢдҪҶworkerCountВ >=В corePoolSize并且workQueueе·Іж»ЎгҖӮ
В *В иҝҷж—¶пјҢеҶҚж¬Ўи°ғз”ЁaddWorkerж–№жі•пјҢдҪҶ第дәҢдёӘеҸӮж•°дј е…ҘдёәfalseпјҢе°ҶзәҝзЁӢжұ зҡ„жңүйҷҗзәҝзЁӢж•°йҮҸзҡ„дёҠйҷҗи®ҫзҪ®дёәmaximumPoolSizeпјӣ
В *В еҰӮжһңеӨұиҙҘеҲҷжӢ’з»қиҜҘд»»еҠЎ
В */
В В В В elseВ ifВ (!addWorker(command,В false))
В В В В В В В В reject(command);
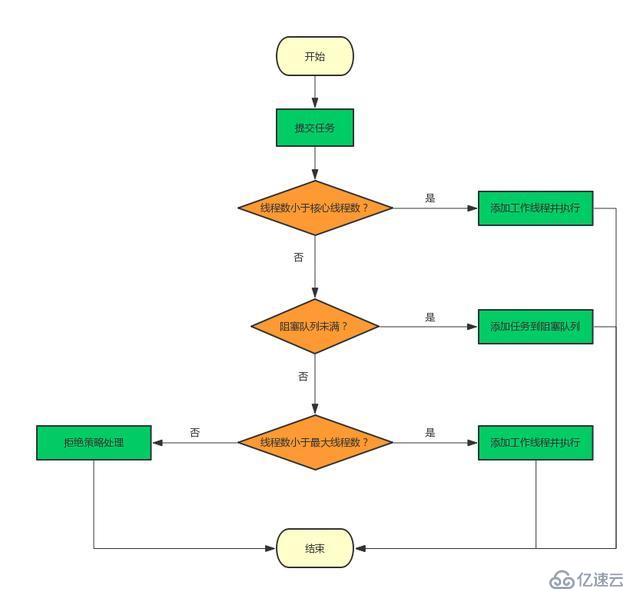
}з®ҖеҚ•жқҘиҜҙпјҢеңЁжү§иЎҢexecute()ж–№жі•ж—¶еҰӮжһңзҠ¶жҖҒдёҖзӣҙжҳҜRUNNINGж—¶пјҢзҡ„жү§иЎҢиҝҮзЁӢеҰӮдёӢпјҡ
еҰӮжһңworkerCount < corePoolSizeпјҢеҲҷеҲӣе»ә并еҗҜеҠЁдёҖдёӘзәҝзЁӢжқҘжү§иЎҢж–°жҸҗдәӨзҡ„д»»еҠЎпјӣ
еҰӮжһңworkerCount >= corePoolSizeпјҢдё”зәҝзЁӢжұ еҶ…зҡ„йҳ»еЎһйҳҹеҲ—жңӘж»ЎпјҢеҲҷе°Ҷд»»еҠЎж·»еҠ еҲ°иҜҘйҳ»еЎһйҳҹеҲ—дёӯпјӣ
еҰӮжһңworkerCount >= corePoolSize && workerCount < maximumPoolSizeпјҢдё”зәҝзЁӢжұ еҶ…зҡ„йҳ»еЎһйҳҹеҲ—е·Іж»ЎпјҢеҲҷеҲӣе»ә并еҗҜеҠЁдёҖдёӘзәҝзЁӢжқҘжү§иЎҢж–°жҸҗдәӨзҡ„д»»еҠЎпјӣ
еҰӮжһңworkerCount >= maximumPoolSizeпјҢ并且зәҝзЁӢжұ еҶ…зҡ„йҳ»еЎһйҳҹеҲ—е·Іж»Ў, еҲҷж №жҚ®жӢ’з»қзӯ–з•ҘжқҘеӨ„зҗҶиҜҘд»»еҠЎ, й»ҳи®Өзҡ„еӨ„зҗҶж–№ејҸжҳҜзӣҙжҺҘжҠӣејӮеёёгҖӮ
иҝҷйҮҢиҰҒжіЁж„ҸдёҖдёӢaddWorker(null, false);пјҢд№ҹе°ұжҳҜеҲӣе»әдёҖдёӘзәҝзЁӢпјҢдҪҶ并没жңүдј е…Ҙд»»еҠЎпјҢеӣ дёәд»»еҠЎе·Із»Ҹиў«ж·»еҠ еҲ°workQueueдёӯдәҶпјҢжүҖд»ҘworkerеңЁжү§иЎҢзҡ„ж—¶еҖҷпјҢдјҡзӣҙжҺҘд»ҺworkQueueдёӯиҺ·еҸ–д»»еҠЎгҖӮжүҖд»ҘпјҢеңЁworkerCountOf(recheck) == 0ж—¶жү§иЎҢaddWorker(null, false);д№ҹжҳҜдёәдәҶдҝқиҜҒзәҝзЁӢжұ еңЁRUNNINGзҠ¶жҖҒдёӢеҝ…йЎ»иҰҒжңүдёҖдёӘзәҝзЁӢжқҘжү§иЎҢд»»еҠЎгҖӮ
executeж–№жі•жү§иЎҢжөҒзЁӢеҰӮдёӢпјҡ
addWorkerж–№жі•
addWorkerж–№жі•зҡ„дё»иҰҒе·ҘдҪңжҳҜеңЁзәҝзЁӢжұ дёӯеҲӣе»әдёҖдёӘж–°зҡ„зәҝзЁӢ并жү§иЎҢпјҢfirstTaskеҸӮж•° з”ЁдәҺжҢҮе®ҡж–°еўһзҡ„зәҝзЁӢжү§иЎҢзҡ„第дёҖдёӘд»»еҠЎпјҢcoreеҸӮж•°дёәtrueиЎЁзӨәеңЁж–°еўһзәҝзЁӢж—¶дјҡеҲӨж–ӯеҪ“еүҚжҙ»еҠЁзәҝзЁӢж•°жҳҜеҗҰе°‘дәҺcorePoolSizeпјҢfalseиЎЁзӨәж–°еўһзәҝзЁӢеүҚйңҖиҰҒеҲӨж–ӯеҪ“еүҚжҙ»еҠЁзәҝзЁӢж•°жҳҜеҗҰе°‘дәҺmaximumPoolSizeпјҢд»Јз ҒеҰӮдёӢпјҡ
privateВ booleanВ addWorker(RunnableВ firstTask,В booleanВ core)В {
В В В В retry:
В В В В forВ (;;)В {
В В В В В В В В intВ cВ =В ctl.get();
В В В В //В иҺ·еҸ–иҝҗиЎҢзҠ¶жҖҒ
В В В В В В В В intВ rsВ =В runStateOf(c);
В В В В /*
В В В В В *В иҝҷдёӘifеҲӨж–ӯ
В В В В В *В еҰӮжһңrsВ >=В SHUTDOWNпјҢеҲҷиЎЁзӨәжӯӨж—¶дёҚеҶҚжҺҘ收新任еҠЎпјӣ
В В В В В *В жҺҘзқҖеҲӨж–ӯд»ҘдёӢ3дёӘжқЎд»¶пјҢеҸӘиҰҒжңү1дёӘдёҚж»Ўи¶іпјҢеҲҷиҝ”еӣһfalseпјҡ
В В В В В *В 1.В rsВ ==В SHUTDOWNпјҢиҝҷж—¶иЎЁзӨәе…ій—ӯзҠ¶жҖҒпјҢдёҚеҶҚжҺҘеҸ—ж–°жҸҗдәӨзҡ„д»»еҠЎпјҢдҪҶеҚҙеҸҜд»Ҙ继з»ӯеӨ„зҗҶйҳ»еЎһйҳҹеҲ—дёӯе·Ідҝқеӯҳзҡ„д»»еҠЎ
В В В В В *В 2.В firsTaskдёәз©ә
В В В В В *В 3.В йҳ»еЎһйҳҹеҲ—дёҚдёәз©ә
В В В В В *В
В В В В В *В йҰ–е…ҲиҖғиҷ‘rsВ ==В SHUTDOWNзҡ„жғ…еҶө
В В В В В *В иҝҷз§Қжғ…еҶөдёӢдёҚдјҡжҺҘеҸ—ж–°жҸҗдәӨзҡ„д»»еҠЎпјҢжүҖд»ҘеңЁfirstTaskдёҚдёәз©әзҡ„ж—¶еҖҷдјҡиҝ”еӣһfalseпјӣ
В В В В В * 然еҗҺпјҢеҰӮжһңfirstTaskдёәз©әпјҢ并且workQueueд№ҹдёәз©әпјҢеҲҷиҝ”еӣһfalseпјҢ
В В В В В *В еӣ дёәйҳҹеҲ—дёӯе·Із»ҸжІЎжңүд»»еҠЎдәҶпјҢдёҚйңҖиҰҒеҶҚж·»еҠ зәҝзЁӢдәҶ
В В В В В */
В В В В В //В CheckВ ifВ queueВ emptyВ onlyВ ifВ necessary.
В В В В В В В В ifВ (rsВ >=В SHUTDOWNВ &&
В В В В В В В В В В В В В В В В !В (rsВ ==В SHUTDOWNВ &&
В В В В В В В В В В В В В В В В В В В В В В В В firstTaskВ ==В nullВ &&
В В В В В В В В В В В В В В В В В В В В В В В В !В workQueue.isEmpty()))
В В В В В В В В В В В В returnВ false;
В В В В В В В В forВ (;;)В {
В В В В В В В В В В В В //В иҺ·еҸ–зәҝзЁӢж•°
В В В В В В В В В В В В intВ wcВ =В workerCountOf(c);
В В В В В В В В В В В В //В еҰӮжһңwcи¶…иҝҮCAPACITYпјҢд№ҹе°ұжҳҜctlзҡ„дҪҺ29дҪҚзҡ„жңҖеӨ§еҖјпјҲдәҢиҝӣеҲ¶жҳҜ29дёӘ1пјүпјҢиҝ”еӣһfalseпјӣ
В В В В В В В В В В В В //В иҝҷйҮҢзҡ„coreжҳҜaddWorkerж–№жі•зҡ„第дәҢдёӘеҸӮж•°пјҢеҰӮжһңдёәtrueиЎЁзӨәж №жҚ®corePoolSizeжқҘжҜ”иҫғпјҢ
В В В В В В В В В В В В //В еҰӮжһңдёәfalseеҲҷж №жҚ®maximumPoolSizeжқҘжҜ”иҫғгҖӮ
В В В В В В В В В В В В //В
В В В В В В В В В В В В ifВ (wcВ >=В CAPACITYВ ||
В В В В В В В В В В В В В В В В В В В В wcВ >=В (coreВ ?В corePoolSizeВ :В maximumPoolSize))
В В В В В В В В В В В В В В В В returnВ false;
В В В В В В В В В В В В //В е°қиҜ•еўһеҠ workerCountпјҢеҰӮжһңжҲҗеҠҹпјҢеҲҷи·іеҮә第дёҖдёӘforеҫӘзҺҜ
В В В В В В В В В В В В ifВ (compareAndIncrementWorkerCount(c))
В В В В В В В В В В В В В В В В breakВ retry;
В В В В В В В В В В В В //В еҰӮжһңеўһеҠ workerCountеӨұиҙҘпјҢеҲҷйҮҚж–°иҺ·еҸ–ctlзҡ„еҖј
В В В В В В В В В В В В cВ =В ctl.get();В В //В Re-readВ ctl
В В В В В В В В В В В В //В еҰӮжһңеҪ“еүҚзҡ„иҝҗиЎҢзҠ¶жҖҒдёҚзӯүдәҺrsпјҢиҜҙжҳҺзҠ¶жҖҒе·Іиў«ж”№еҸҳпјҢиҝ”еӣһ第дёҖдёӘforеҫӘзҺҜ继з»ӯжү§иЎҢ
В В В В В В В В В В В В ifВ (runStateOf(c)В !=В rs)
В В В В В В В В В В В В В В В В continueВ retry;
В В В В В В В В В В В В //В elseВ CASВ failedВ dueВ toВ workerCountВ change;В retryВ innerВ loop
В В В В В В В В }
В В В В }
В В В В booleanВ workerStartedВ =В false;
В В В В booleanВ workerAddedВ =В false;
В В В В WorkerВ wВ =В null;
В В В В tryВ {
В В В В В //В ж №жҚ®firstTaskжқҘеҲӣе»әWorkerеҜ№иұЎ
В В В В В В В В wВ =В newВ Worker(firstTask);
В В В В В //В жҜҸдёҖдёӘWorkerеҜ№иұЎйғҪдјҡеҲӣе»әдёҖдёӘзәҝзЁӢ
В В В В В В В В finalВ ThreadВ tВ =В w.thread;
В В В В В В В В ifВ (tВ !=В null)В {
В В В В В В В В В В В В finalВ ReentrantLockВ mainLockВ =В this.mainLock;
В В В В В В В В В В В В mainLock.lock();
В В В В В В В В В В В В tryВ {
В В В В В В В В В В В В В В В В intВ rsВ =В runStateOf(ctl.get());
В В В В В В В В В В В В В В В В //В rsВ <В SHUTDOWNиЎЁзӨәжҳҜRUNNINGзҠ¶жҖҒпјӣ
В В В В В В В В В В В В В В В В //В еҰӮжһңrsжҳҜRUNNINGзҠ¶жҖҒжҲ–иҖ…rsжҳҜSHUTDOWNзҠ¶жҖҒ并且firstTaskдёәnullпјҢеҗ‘зәҝзЁӢжұ дёӯж·»еҠ зәҝзЁӢгҖӮ
В В В В В В В В В В В В В В В В //В еӣ дёәеңЁSHUTDOWNж—¶дёҚдјҡеңЁж·»еҠ ж–°зҡ„д»»еҠЎпјҢдҪҶиҝҳжҳҜдјҡжү§иЎҢworkQueueдёӯзҡ„д»»еҠЎ
В В В В В В В В В В В В В В В В ifВ (rsВ <В SHUTDOWNВ ||
В В В В В В В В В В В В В В В В В В В В В В В В (rsВ ==В SHUTDOWNВ &&В firstTaskВ ==В null))В {
В В В В В В В В В В В В В В В В В В В В ifВ (t.isAlive())В //В precheckВ thatВ tВ isВ startable
В В В В В В В В В В В В В В В В В В В В В В В В throwВ newВ IllegalThreadStateException();
В В В В В В В В В В В В В В В В В В В В //В workersжҳҜдёҖдёӘHashSet
В В В В В В В В В В В В В В В В В В В В workers.add(w);
В В В В В В В В В В В В В В В В В В В В intВ sВ =В workers.size();
В В В В В В В В В В В В В В В В В В В В //В largestPoolSizeи®°еҪ•зқҖзәҝзЁӢжұ дёӯеҮәзҺ°иҝҮзҡ„жңҖеӨ§зәҝзЁӢж•°йҮҸ
В В В В В В В В В В В В В В В В В В В В ifВ (sВ >В largestPoolSize)
В В В В В В В В В В В В В В В В В В В В В В В В largestPoolSizeВ =В s;
В В В В В В В В В В В В В В В В В В В В workerAddedВ =В true;
В В В В В В В В В В В В В В В В }
В В В В В В В В В В В В }В finallyВ {
В В В В В В В В В В В В В В В В mainLock.unlock();
В В В В В В В В В В В В }
В В В В В В В В В В В В ifВ (workerAdded)В {
В В В В В В В В В В В В В В В В //В еҗҜеҠЁзәҝзЁӢ
В В В В В В В В В В В В В В В В t.start();
В В В В В В В В В В В В В В В В workerStartedВ =В true;
В В В В В В В В В В В В }
В В В В В В В В }
В В В В }В finallyВ {
В В В В В В В В ifВ (!В workerStarted)
В В В В В В В В В В В В addWorkerFailed(w);
В В В В }
В В В В returnВ workerStarted;
}Workerзұ»
зәҝзЁӢжұ дёӯзҡ„жҜҸдёҖдёӘзәҝзЁӢиў«е°ҒиЈ…жҲҗдёҖдёӘWorkerеҜ№иұЎпјҢThreadPoolз»ҙжҠӨзҡ„е…¶е®һе°ұжҳҜдёҖз»„WorkerеҜ№иұЎпјҢиҜ·еҸӮи§ҒJDKжәҗз ҒгҖӮ
Workerзұ»з»§жүҝдәҶAQSпјҢ并е®һзҺ°дәҶRunnableжҺҘеҸЈпјҢжіЁж„Ҹе…¶дёӯзҡ„firstTaskе’ҢthreadеұһжҖ§пјҡfirstTaskз”Ёе®ғжқҘдҝқеӯҳдј е…Ҙзҡ„д»»еҠЎпјӣthreadжҳҜеңЁи°ғз”Ёжһ„йҖ ж–№жі•ж—¶йҖҡиҝҮThreadFactoryжқҘеҲӣе»әзҡ„зәҝзЁӢпјҢжҳҜз”ЁжқҘеӨ„зҗҶд»»еҠЎзҡ„зәҝзЁӢгҖӮ
еңЁи°ғз”Ёжһ„йҖ ж–№жі•ж—¶пјҢйңҖиҰҒжҠҠд»»еҠЎдј е…ҘпјҢиҝҷйҮҢйҖҡиҝҮgetThreadFactory().newThread(this);жқҘж–°е»әдёҖдёӘзәҝзЁӢпјҢnewThreadж–№жі•дј е…Ҙзҡ„еҸӮж•°жҳҜthisпјҢеӣ дёәWorkerжң¬иә«з»§жүҝдәҶRunnableжҺҘеҸЈпјҢд№ҹе°ұжҳҜдёҖдёӘзәҝзЁӢпјҢжүҖд»ҘдёҖдёӘWorkerеҜ№иұЎеңЁеҗҜеҠЁзҡ„ж—¶еҖҷдјҡи°ғз”ЁWorkerзұ»дёӯзҡ„runж–№жі•гҖӮ
Worker继жүҝдәҶAQSпјҢдҪҝз”ЁAQSжқҘе®һзҺ°зӢ¬еҚ й”Ғзҡ„еҠҹиғҪгҖӮдёәд»Җд№ҲдёҚдҪҝз”ЁReentrantLockжқҘе®һзҺ°е‘ўпјҹеҸҜд»ҘзңӢеҲ°tryAcquireж–№жі•пјҢе®ғжҳҜдёҚе…Ғи®ёйҮҚе…Ҙзҡ„пјҢиҖҢReentrantLockжҳҜе…Ғи®ёйҮҚе…Ҙзҡ„пјҡ
lockж–№жі•дёҖж—ҰиҺ·еҸ–дәҶзӢ¬еҚ й”ҒпјҢиЎЁзӨәеҪ“еүҚзәҝзЁӢжӯЈеңЁжү§иЎҢд»»еҠЎдёӯпјӣ
еҰӮжһңжӯЈеңЁжү§иЎҢд»»еҠЎпјҢеҲҷдёҚеә”иҜҘдёӯж–ӯзәҝзЁӢпјӣ
еҰӮжһңиҜҘзәҝзЁӢзҺ°еңЁдёҚжҳҜзӢ¬еҚ й”Ғзҡ„зҠ¶жҖҒпјҢд№ҹе°ұжҳҜз©әй—Ізҡ„зҠ¶жҖҒпјҢиҜҙжҳҺе®ғжІЎжңүеңЁеӨ„зҗҶд»»еҠЎпјҢиҝҷж—¶еҸҜд»ҘеҜ№иҜҘзәҝзЁӢиҝӣиЎҢдёӯж–ӯпјӣ
зәҝзЁӢжұ еңЁжү§иЎҢshutdownж–№жі•жҲ–tryTerminateж–№жі•ж—¶дјҡи°ғз”ЁinterruptIdleWorkersж–№жі•жқҘдёӯж–ӯз©әй—Ізҡ„зәҝзЁӢпјҢinterruptIdleWorkersж–№жі•дјҡдҪҝз”ЁtryLockж–№жі•жқҘеҲӨж–ӯзәҝзЁӢжұ дёӯзҡ„зәҝзЁӢжҳҜеҗҰжҳҜз©әй—ІзҠ¶жҖҒпјӣ
д№ӢжүҖд»Ҙи®ҫзҪ®дёәдёҚеҸҜйҮҚе…ҘпјҢжҳҜеӣ дёәжҲ‘们дёҚеёҢжңӣд»»еҠЎеңЁи°ғз”ЁеғҸsetCorePoolSizeиҝҷж ·зҡ„зәҝзЁӢжұ жҺ§еҲ¶ж–№жі•ж—¶йҮҚж–°иҺ·еҸ–й”ҒгҖӮеҰӮжһңдҪҝз”ЁReentrantLockпјҢе®ғжҳҜеҸҜйҮҚе…Ҙзҡ„пјҢиҝҷж ·еҰӮжһңеңЁд»»еҠЎдёӯи°ғз”ЁдәҶеҰӮsetCorePoolSizeиҝҷзұ»зәҝзЁӢжұ жҺ§еҲ¶зҡ„ж–№жі•пјҢдјҡдёӯж–ӯжӯЈеңЁиҝҗиЎҢзҡ„зәҝзЁӢгҖӮ
жүҖд»ҘпјҢWorker继жүҝиҮӘAQSпјҢз”ЁдәҺеҲӨж–ӯзәҝзЁӢжҳҜеҗҰз©әй—Ід»ҘеҸҠжҳҜеҗҰеҸҜд»Ҙиў«дёӯж–ӯгҖӮ
жӯӨеӨ–пјҢеңЁжһ„йҖ ж–№жі•дёӯжү§иЎҢдәҶsetState(-1);пјҢжҠҠstateеҸҳйҮҸи®ҫзҪ®дёә-1пјҢдёәд»Җд№Ҳиҝҷд№ҲеҒҡе‘ўпјҹжҳҜеӣ дёәAQSдёӯй»ҳи®Өзҡ„stateжҳҜ0пјҢеҰӮжһңеҲҡеҲӣе»әдәҶдёҖдёӘWorkerеҜ№иұЎпјҢиҝҳжІЎжңүжү§иЎҢд»»еҠЎж—¶пјҢиҝҷж—¶е°ұдёҚеә”иҜҘиў«дёӯж–ӯпјҢзңӢдёҖдёӢtryAquireж–№жі•пјҡ
protectedВ booleanВ tryAcquire(intВ unused)В {
В В В В //casдҝ®ж”№stateпјҢдёҚеҸҜйҮҚе…Ҙ
В В В В ifВ (compareAndSetState(0,В 1))В {В
В В В В В В В В setExclusiveOwnerThread(Thread.currentThread());
В В В В В В В В returnВ true;
В В В В }
В В В В returnВ false;
}tryAcquireж–№жі•жҳҜж №жҚ®stateжҳҜеҗҰжҳҜ0жқҘеҲӨж–ӯзҡ„пјҢжүҖд»ҘпјҢsetState(-1);е°Ҷstateи®ҫзҪ®дёә-1жҳҜдёәдәҶзҰҒжӯўеңЁжү§иЎҢд»»еҠЎеүҚеҜ№зәҝзЁӢиҝӣиЎҢдёӯж–ӯгҖӮ
жӯЈеӣ дёәеҰӮжӯӨпјҢеңЁrunWorkerж–№жі•дёӯдјҡе…Ҳи°ғз”ЁWorkerеҜ№иұЎзҡ„unlockж–№жі•е°Ҷstateи®ҫзҪ®дёә0гҖӮ
runWorkerж–№жі•
еңЁWorkerзұ»дёӯзҡ„runж–№жі•и°ғз”ЁдәҶrunWorkerж–№жі•жқҘжү§иЎҢд»»еҠЎпјҢrunWorkerж–№жі•зҡ„д»Јз ҒеҰӮдёӢпјҡ
finalВ voidВ runWorker(WorkerВ w)В {
В В В В ThreadВ wtВ =В Thread.currentThread();
В В В В //В иҺ·еҸ–第дёҖдёӘд»»еҠЎ
В В В В RunnableВ taskВ =В w.firstTask;
В В В В w.firstTaskВ =В null;
В В В В //В е…Ғи®ёдёӯж–ӯ
В В В В w.unlock();В //В allowВ interrupts
В В В В //В жҳҜеҗҰеӣ дёәејӮеёёйҖҖеҮәеҫӘзҺҜ
В В В В booleanВ completedAbruptlyВ =В true;
В В В В tryВ {
В В В В В В В В //В еҰӮжһңtaskдёәз©әпјҢеҲҷйҖҡиҝҮgetTaskжқҘиҺ·еҸ–д»»еҠЎ
В В В В В В В В whileВ (taskВ !=В nullВ ||В (taskВ =В getTask())В !=В null)В {
В В В В В В В В В В В В w.lock();
В В В В В В В В В В В В ifВ ((runStateAtLeast(ctl.get(),В STOP)В ||
В В В В В В В В В В В В В В В В В В В В (Thread.interrupted()В &&
В В В В В В В В В В В В В В В В В В В В В В В В В В В В runStateAtLeast(ctl.get(),В STOP)))В &&
В В В В В В В В В В В В В В В В В В В В !wt.isInterrupted())
В В В В В В В В В В В В В В В В wt.interrupt();
В В В В В В В В В В В В tryВ {
В В В В В В В В В В В В В В В В beforeExecute(wt,В task);
В В В В В В В В В В В В В В В В ThrowableВ thrownВ =В null;
В В В В В В В В В В В В В В В В tryВ {
В В В В В В В В В В В В В В В В В В В В task.run();
В В В В В В В В В В В В В В В В }В catchВ (RuntimeExceptionВ x)В {
В В В В В В В В В В В В В В В В В В В В thrownВ =В x;В throwВ x;
В В В В В В В В В В В В В В В В }В catchВ (ErrorВ x)В {
В В В В В В В В В В В В В В В В В В В В thrownВ =В x;В throwВ x;
В В В В В В В В В В В В В В В В }В catchВ (ThrowableВ x)В {
В В В В В В В В В В В В В В В В В В В В thrownВ =В x;В throwВ newВ Error(x);
В В В В В В В В В В В В В В В В }В finallyВ {
В В В В В В В В В В В В В В В В В В В В afterExecute(task,В thrown);
В В В В В В В В В В В В В В В В }
В В В В В В В В В В В В }В finallyВ {
В В В В В В В В В В В В В В В В taskВ =В null;
В В В В В В В В В В В В В В В В w.completedTasks++;
В В В В В В В В В В В В В В В В w.unlock();
В В В В В В В В В В В В }
В В В В В В В В }
В В В В В В В В completedAbruptlyВ =В false;
В В В В }В finallyВ {
В В В В В В В В processWorkerExit(w,В completedAbruptly);
В В В В }
}иҝҷйҮҢиҜҙжҳҺдёҖдёӢ第дёҖдёӘifеҲӨж–ӯпјҢзӣ®зҡ„жҳҜпјҡ
еҰӮжһңзәҝзЁӢжұ жӯЈеңЁеҒңжӯўпјҢйӮЈд№ҲиҰҒдҝқиҜҒеҪ“еүҚзәҝзЁӢжҳҜдёӯж–ӯзҠ¶жҖҒпјӣ
еҰӮжһңдёҚжҳҜзҡ„иҜқпјҢеҲҷиҰҒдҝқиҜҒеҪ“еүҚзәҝзЁӢдёҚжҳҜдёӯж–ӯзҠ¶жҖҒпјӣ
иҝҷйҮҢиҰҒиҖғиҷ‘еңЁжү§иЎҢиҜҘifиҜӯеҸҘжңҹй—ҙеҸҜиғҪд№ҹжү§иЎҢдәҶshutdownNowж–№жі•пјҢshutdownNowж–№жі•дјҡжҠҠзҠ¶жҖҒи®ҫзҪ®дёәSTOPпјҢеӣһйЎҫдёҖдёӢSTOPзҠ¶жҖҒпјҡ
дёҚиғҪжҺҘеҸ—ж–°д»»еҠЎпјҢд№ҹдёҚеӨ„зҗҶйҳҹеҲ—дёӯзҡ„д»»еҠЎпјҢдјҡдёӯж–ӯжӯЈеңЁеӨ„зҗҶд»»еҠЎзҡ„зәҝзЁӢгҖӮеңЁзәҝзЁӢжұ еӨ„дәҺ RUNNING жҲ– SHUTDOWN зҠ¶жҖҒж—¶пјҢи°ғз”Ё shutdownNow() ж–№жі•дјҡдҪҝзәҝзЁӢжұ иҝӣе…ҘеҲ°иҜҘзҠ¶жҖҒгҖӮ
STOPзҠ¶жҖҒиҰҒдёӯж–ӯзәҝзЁӢжұ дёӯзҡ„жүҖжңүзәҝзЁӢпјҢиҖҢиҝҷйҮҢдҪҝз”ЁThread.interrupted()жқҘеҲӨж–ӯжҳҜеҗҰдёӯж–ӯжҳҜдёәдәҶзЎ®дҝқеңЁRUNNINGжҲ–иҖ…SHUTDOWNзҠ¶жҖҒж—¶зәҝзЁӢжҳҜйқһдёӯж–ӯзҠ¶жҖҒзҡ„пјҢеӣ дёәThread.interrupted()ж–№жі•дјҡеӨҚдҪҚдёӯж–ӯзҡ„зҠ¶жҖҒгҖӮ
жҖ»з»“дёҖдёӢrunWorkerж–№жі•зҡ„жү§иЎҢиҝҮзЁӢпјҡ
whileеҫӘзҺҜдёҚж–ӯең°йҖҡиҝҮgetTask()ж–№жі•иҺ·еҸ–д»»еҠЎпјӣ
getTask()ж–№жі•д»Һйҳ»еЎһйҳҹеҲ—дёӯеҸ–д»»еҠЎпјӣ
еҰӮжһңзәҝзЁӢжұ жӯЈеңЁеҒңжӯўпјҢйӮЈд№ҲиҰҒдҝқиҜҒеҪ“еүҚзәҝзЁӢжҳҜдёӯж–ӯзҠ¶жҖҒпјҢеҗҰеҲҷиҰҒдҝқиҜҒеҪ“еүҚзәҝзЁӢдёҚжҳҜдёӯж–ӯзҠ¶жҖҒпјӣ
и°ғз”Ёtask.run()жү§иЎҢд»»еҠЎпјӣ
еҰӮжһңtaskдёәnullеҲҷи·іеҮәеҫӘзҺҜпјҢжү§иЎҢprocessWorkerExit()ж–№жі•пјӣ
runWorkerж–№жі•жү§иЎҢе®ҢжҜ•пјҢд№ҹд»ЈиЎЁзқҖWorkerдёӯзҡ„runж–№жі•жү§иЎҢе®ҢжҜ•пјҢй”ҖжҜҒзәҝзЁӢгҖӮ
иҝҷйҮҢзҡ„beforeExecuteж–№жі•е’ҢafterExecuteж–№жі•еңЁThreadPoolExecutorзұ»дёӯжҳҜз©әзҡ„пјҢз•ҷз»ҷеӯҗзұ»жқҘе®һзҺ°гҖӮ
completedAbruptlyеҸҳйҮҸжқҘиЎЁзӨәеңЁжү§иЎҢд»»еҠЎиҝҮзЁӢдёӯжҳҜеҗҰеҮәзҺ°дәҶејӮеёёпјҢеңЁprocessWorkerExitж–№жі•дёӯдјҡеҜ№иҜҘеҸҳйҮҸзҡ„еҖјиҝӣиЎҢеҲӨж–ӯгҖӮ
getTaskж–№жі•
getTaskж–№жі•з”ЁжқҘд»Һйҳ»еЎһйҳҹеҲ—дёӯеҸ–д»»еҠЎпјҢд»Јз ҒеҰӮдёӢпјҡ
privateВ RunnableВ getTask()В {
В В В В //В timeOutеҸҳйҮҸзҡ„еҖјиЎЁзӨәдёҠж¬Ўд»Һйҳ»еЎһйҳҹеҲ—дёӯеҸ–д»»еҠЎж—¶жҳҜеҗҰи¶…ж—¶
В В В В booleanВ timedOutВ =В false;В //В DidВ theВ lastВ poll()В timeВ out?
В В В В forВ (;;)В {
В В В В В В В В intВ cВ =В ctl.get();
В В В В В В В В intВ rsВ =В runStateOf(c);
В В В В В В В В //В CheckВ ifВ queueВ emptyВ onlyВ ifВ necessary.
В В В В /*
В В В В В *В еҰӮжһңзәҝзЁӢжұ зҠ¶жҖҒrsВ >=В SHUTDOWNпјҢд№ҹе°ұжҳҜйқһRUNNINGзҠ¶жҖҒпјҢеҶҚиҝӣиЎҢд»ҘдёӢеҲӨж–ӯпјҡ
В В В В В *В 1.В rsВ >=В STOPпјҢзәҝзЁӢжұ жҳҜеҗҰжӯЈеңЁstopпјӣ
В В В В В *В 2.В йҳ»еЎһйҳҹеҲ—жҳҜеҗҰдёәз©әгҖӮ
В В В В В *В еҰӮжһңд»ҘдёҠжқЎд»¶ж»Ўи¶іпјҢеҲҷе°ҶworkerCountеҮҸ1并иҝ”еӣһnullгҖӮ
В В В В В *В еӣ дёәеҰӮжһңеҪ“еүҚзәҝзЁӢжұ зҠ¶жҖҒзҡ„еҖјжҳҜSHUTDOWNжҲ–д»ҘдёҠж—¶пјҢдёҚе…Ғи®ёеҶҚеҗ‘йҳ»еЎһйҳҹеҲ—дёӯж·»еҠ д»»еҠЎгҖӮ
В В В В В */
В В В В В В В В ifВ (rsВ >=В SHUTDOWNВ &&В (rsВ >=В STOPВ ||В workQueue.isEmpty()))В {
В В В В В В В В В В В В decrementWorkerCount();
В В В В В В В В В В В В returnВ null;
В В В В В В В В }
В В В В В В В В intВ wcВ =В workerCountOf(c);
В В В В В В В В //В AreВ workersВ subjectВ toВ culling?
В В В В В В В В //В timedеҸҳйҮҸз”ЁдәҺеҲӨж–ӯжҳҜеҗҰйңҖиҰҒиҝӣиЎҢи¶…ж—¶жҺ§еҲ¶гҖӮ
В В В В В В В В //В allowCoreThreadTimeOutй»ҳи®ӨжҳҜfalseпјҢд№ҹе°ұжҳҜж ёеҝғзәҝзЁӢдёҚе…Ғи®ёиҝӣиЎҢи¶…ж—¶пјӣ
В В В В В В В В //В wcВ >В corePoolSizeпјҢиЎЁзӨәеҪ“еүҚзәҝзЁӢжұ дёӯзҡ„зәҝзЁӢж•°йҮҸеӨ§дәҺж ёеҝғзәҝзЁӢж•°йҮҸпјӣ
В В В В В В В В //В еҜ№дәҺи¶…иҝҮж ёеҝғзәҝзЁӢж•°йҮҸзҡ„иҝҷдәӣзәҝзЁӢпјҢйңҖиҰҒиҝӣиЎҢи¶…ж—¶жҺ§еҲ¶
В В В В В В В В booleanВ timedВ =В allowCoreThreadTimeOutВ ||В wcВ >В corePoolSize;
В В В В /*
В В В В В *В wcВ >В maximumPoolSizeзҡ„жғ…еҶөжҳҜеӣ дёәеҸҜиғҪеңЁжӯӨж–№жі•жү§иЎҢйҳ¶ж®өеҗҢж—¶жү§иЎҢдәҶsetMaximumPoolSizeж–№жі•пјӣ
В В В В В *В timedВ &&В timedOutВ еҰӮжһңдёәtrueпјҢиЎЁзӨәеҪ“еүҚж“ҚдҪңйңҖиҰҒиҝӣиЎҢи¶…ж—¶жҺ§еҲ¶пјҢ并且дёҠж¬Ўд»Һйҳ»еЎһйҳҹеҲ—дёӯиҺ·еҸ–д»»еҠЎеҸ‘з”ҹдәҶи¶…ж—¶
В В В В В *В жҺҘдёӢжқҘеҲӨж–ӯпјҢеҰӮжһңжңүж•ҲзәҝзЁӢж•°йҮҸеӨ§дәҺ1пјҢжҲ–иҖ…йҳ»еЎһйҳҹеҲ—жҳҜз©әзҡ„пјҢйӮЈд№Ҳе°қиҜ•е°ҶworkerCountеҮҸ1пјӣ
В В В В В *В еҰӮжһңеҮҸ1еӨұиҙҘпјҢеҲҷиҝ”еӣһйҮҚиҜ•гҖӮ
В В В В В *В еҰӮжһңwcВ ==В 1ж—¶пјҢд№ҹе°ұиҜҙжҳҺеҪ“еүҚзәҝзЁӢжҳҜзәҝзЁӢжұ дёӯе”ҜдёҖзҡ„дёҖдёӘзәҝзЁӢдәҶгҖӮ
В В В В В */
В В В В В В В В ifВ ((wcВ >В maximumPoolSizeВ ||В (timedВ &&В timedOut))
В В В В В В В В В В В В В В В В &&В (wcВ >В 1В ||В workQueue.isEmpty()))В {
В В В В В В В В В В В В ifВ (compareAndDecrementWorkerCount(c))
В В В В В В В В В В В В В В В В returnВ null;
В В В В В В В В В В В В continue;
В В В В В В В В }
В В В В В В В В tryВ {
В В В В В В В В /*
В В В В В В В В В *В ж №жҚ®timedжқҘеҲӨж–ӯпјҢеҰӮжһңдёәtrueпјҢеҲҷйҖҡиҝҮйҳ»еЎһйҳҹеҲ—зҡ„pollж–№жі•иҝӣиЎҢи¶…ж—¶жҺ§еҲ¶пјҢеҰӮжһңеңЁkeepAliveTimeж—¶й—ҙеҶ…жІЎжңүиҺ·еҸ–еҲ°д»»еҠЎпјҢеҲҷиҝ”еӣһnullпјӣ
В В В В В В В В В *В еҗҰеҲҷйҖҡиҝҮtakeж–№жі•пјҢеҰӮжһңиҝҷж—¶йҳҹеҲ—дёәз©әпјҢеҲҷtakeж–№жі•дјҡйҳ»еЎһзӣҙеҲ°йҳҹеҲ—дёҚдёәз©әгҖӮ
В В В В В В В В В *
В В В В В В В В В */
В В В В В В В В В В В В RunnableВ rВ =В timedВ ?
В В В В В В В В В В В В В В В В В В В В workQueue.poll(keepAliveTime,В TimeUnit.NANOSECONDS)В :
В В В В В В В В В В В В В В В В В В В В workQueue.take();
В В В В В В В В В В В В ifВ (rВ !=В null)
В В В В В В В В В В В В В В В В returnВ r;
В В В В В В В В В В В В //В еҰӮжһңВ rВ ==В nullпјҢиҜҙжҳҺе·Із»Ҹи¶…ж—¶пјҢtimedOutи®ҫзҪ®дёәtrue
В В В В В В В В В В В В timedOutВ =В true;
В В В В В В В В }В catchВ (InterruptedExceptionВ retry)В {
В В В В В В В В В В В В //В еҰӮжһңиҺ·еҸ–д»»еҠЎж—¶еҪ“еүҚзәҝзЁӢеҸ‘з”ҹдәҶдёӯж–ӯпјҢеҲҷи®ҫзҪ®timedOutдёәfalse并иҝ”еӣһеҫӘзҺҜйҮҚиҜ•
В В В В В В В В В В В В timedOutВ =В false;
В В В В В В В В }
В В В В }
}иҝҷйҮҢйҮҚиҰҒзҡ„ең°ж–№жҳҜ第дәҢдёӘifеҲӨж–ӯпјҢзӣ®зҡ„жҳҜжҺ§еҲ¶зәҝзЁӢжұ зҡ„жңүж•ҲзәҝзЁӢж•°йҮҸгҖӮз”ұдёҠж–Үдёӯзҡ„еҲҶжһҗеҸҜд»ҘзҹҘйҒ“пјҢеңЁжү§иЎҢexecuteж–№жі•ж—¶пјҢеҰӮжһңеҪ“еүҚзәҝзЁӢжұ зҡ„зәҝзЁӢж•°йҮҸи¶…иҝҮдәҶcorePoolSizeдё”е°ҸдәҺmaximumPoolSizeпјҢ并且workQueueе·Іж»Ўж—¶пјҢеҲҷеҸҜд»ҘеўһеҠ е·ҘдҪңзәҝзЁӢпјҢдҪҶиҝҷж—¶еҰӮжһңи¶…ж—¶жІЎжңүиҺ·еҸ–еҲ°д»»еҠЎпјҢд№ҹе°ұжҳҜtimedOutдёәtrueзҡ„жғ…еҶөпјҢиҜҙжҳҺworkQueueе·Із»Ҹдёәз©әдәҶпјҢд№ҹе°ұиҜҙжҳҺдәҶеҪ“еүҚзәҝзЁӢжұ дёӯдёҚйңҖиҰҒйӮЈд№ҲеӨҡзәҝзЁӢжқҘжү§иЎҢд»»еҠЎдәҶпјҢеҸҜд»ҘжҠҠеӨҡдәҺcorePoolSizeж•°йҮҸзҡ„зәҝзЁӢй”ҖжҜҒжҺүпјҢдҝқжҢҒзәҝзЁӢж•°йҮҸеңЁcorePoolSizeеҚіеҸҜгҖӮ
д»Җд№Ҳж—¶еҖҷдјҡй”ҖжҜҒпјҹеҪ“然жҳҜrunWorkerж–№жі•жү§иЎҢе®Ңд№ӢеҗҺпјҢд№ҹе°ұжҳҜWorkerдёӯзҡ„runж–№жі•жү§иЎҢе®ҢпјҢз”ұJVMиҮӘеҠЁеӣһ收гҖӮ
getTaskж–№жі•иҝ”еӣһnullж—¶пјҢеңЁrunWorkerж–№жі•дёӯдјҡи·іеҮәwhileеҫӘзҺҜпјҢ然еҗҺдјҡжү§иЎҢprocessWorkerExitж–№жі•гҖӮ
processWorkerExitж–№жі•
privateВ voidВ processWorkerExit(WorkerВ w,В booleanВ completedAbruptly)В {
В В В В //В еҰӮжһңcompletedAbruptlyеҖјдёәtrueпјҢеҲҷиҜҙжҳҺзәҝзЁӢжү§иЎҢж—¶еҮәзҺ°дәҶејӮеёёпјҢйңҖиҰҒе°ҶworkerCountеҮҸ1пјӣ
В В В В //В еҰӮжһңзәҝзЁӢжү§иЎҢж—¶жІЎжңүеҮәзҺ°ејӮеёёпјҢиҜҙжҳҺеңЁgetTask()ж–№жі•дёӯе·Із»Ҹе·Із»ҸеҜ№workerCountиҝӣиЎҢдәҶеҮҸ1ж“ҚдҪңпјҢиҝҷйҮҢе°ұдёҚеҝ…еҶҚеҮҸдәҶгҖӮВ В
В В В В ifВ (completedAbruptly)В //В IfВ abrupt,В thenВ workerCountВ wasn'tВ adjusted
В В В В В В В В decrementWorkerCount();
В В В В finalВ ReentrantLockВ mainLockВ =В this.mainLock;
В В В В mainLock.lock();
В В В В tryВ {
В В В В В В В В //з»ҹи®Ўе®ҢжҲҗзҡ„д»»еҠЎж•°
В В В В В В В В completedTaskCountВ +=В w.completedTasks;
В В В В В В В В //В д»Һworkersдёӯ移йҷӨпјҢд№ҹе°ұиЎЁзӨәзқҖд»ҺзәҝзЁӢжұ дёӯ移йҷӨдәҶдёҖдёӘе·ҘдҪңзәҝзЁӢ
В В В В В В В В workers.remove(w);
В В В В }В finallyВ {
В В В В В В В В mainLock.unlock();
В В В В }
В В В В //В ж №жҚ®зәҝзЁӢжұ зҠ¶жҖҒиҝӣиЎҢеҲӨж–ӯжҳҜеҗҰз»“жқҹзәҝзЁӢжұ
В В В В tryTerminate();
В В В В intВ cВ =В ctl.get();
/*
В *В еҪ“зәҝзЁӢжұ жҳҜRUNNINGжҲ–SHUTDOWNзҠ¶жҖҒж—¶пјҢеҰӮжһңworkerжҳҜејӮеёёз»“жқҹпјҢйӮЈд№ҲдјҡзӣҙжҺҘaddWorkerпјӣ
В *В еҰӮжһңallowCoreThreadTimeOut=trueпјҢ并且зӯүеҫ…йҳҹеҲ—жңүд»»еҠЎпјҢиҮіе°‘дҝқз•ҷдёҖдёӘworkerпјӣ
В *В еҰӮжһңallowCoreThreadTimeOut=falseпјҢworkerCountдёҚе°‘дәҺcorePoolSizeгҖӮ
В */
В В В В ifВ (runStateLessThan(c,В STOP))В {
В В В В В В В В ifВ (!completedAbruptly)В {
В В В В В В В В В В В В intВ minВ =В allowCoreThreadTimeOutВ ?В 0В :В corePoolSize;
В В В В В В В В В В В В ifВ (minВ ==В 0В &&В !В workQueue.isEmpty())
В В В В В В В В В В В В В В В В minВ =В 1;
В В В В В В В В В В В В ifВ (workerCountOf(c)В >=В min)
В В В В В В В В В В В В В В В В return;В //В replacementВ notВ needed
В В В В В В В В }
В В В В В В В В addWorker(null,В false);
В В В В }
}иҮіжӯӨпјҢprocessWorkerExitжү§иЎҢе®Ңд№ӢеҗҺпјҢе·ҘдҪңзәҝзЁӢиў«й”ҖжҜҒпјҢд»ҘдёҠе°ұжҳҜж•ҙдёӘе·ҘдҪңзәҝзЁӢзҡ„з”ҹе‘Ҫе‘ЁжңҹпјҢд»Һexecuteж–№жі•ејҖе§ӢпјҢWorkerдҪҝз”ЁThreadFactoryеҲӣе»әж–°зҡ„е·ҘдҪңзәҝзЁӢпјҢrunWorkerйҖҡиҝҮgetTaskиҺ·еҸ–д»»еҠЎпјҢ然еҗҺжү§иЎҢд»»еҠЎпјҢеҰӮжһңgetTaskиҝ”еӣһnullпјҢиҝӣе…ҘprocessWorkerExitж–№жі•пјҢж•ҙдёӘзәҝзЁӢз»“жқҹпјҢеҰӮеӣҫжүҖзӨәпјҡ

жҖ»з»“
еҲҶжһҗдәҶзәҝзЁӢзҡ„еҲӣе»әпјҢд»»еҠЎзҡ„жҸҗдәӨпјҢзҠ¶жҖҒзҡ„иҪ¬жҚўд»ҘеҸҠзәҝзЁӢжұ зҡ„е…ій—ӯпјӣ
иҝҷйҮҢйҖҡиҝҮexecuteж–№жі•жқҘеұ•ејҖзәҝзЁӢжұ зҡ„е·ҘдҪңжөҒзЁӢпјҢexecuteж–№жі•йҖҡиҝҮcorePoolSizeпјҢmaximumPoolSizeд»ҘеҸҠйҳ»еЎһйҳҹеҲ—зҡ„еӨ§е°ҸжқҘеҲӨж–ӯеҶіе®ҡдј е…Ҙзҡ„д»»еҠЎеә”иҜҘиў«з«ӢеҚіжү§иЎҢпјҢиҝҳжҳҜеә”иҜҘж·»еҠ еҲ°йҳ»еЎһйҳҹеҲ—дёӯпјҢиҝҳжҳҜеә”иҜҘжӢ’з»қд»»еҠЎгҖӮ
д»Ӣз»ҚдәҶзәҝзЁӢжұ е…ій—ӯж—¶зҡ„иҝҮзЁӢпјҢд№ҹеҲҶжһҗдәҶshutdownж–№жі•дёҺgetTaskж–№жі•еӯҳеңЁз«һжҖҒжқЎд»¶пјӣ
еңЁиҺ·еҸ–д»»еҠЎж—¶пјҢиҰҒйҖҡиҝҮзәҝзЁӢжұ зҡ„зҠ¶жҖҒжқҘеҲӨж–ӯеә”иҜҘз»“жқҹе·ҘдҪңзәҝзЁӢиҝҳжҳҜйҳ»еЎһзәҝзЁӢзӯүеҫ…ж–°зҡ„д»»еҠЎпјҢд№ҹи§ЈйҮҠдәҶдёәд»Җд№Ҳе…ій—ӯзәҝзЁӢжұ ж—¶иҰҒдёӯж–ӯе·ҘдҪңзәҝзЁӢд»ҘеҸҠдёәд»Җд№ҲжҜҸдёҖдёӘworkerйғҪйңҖиҰҒlockгҖӮ
жңҖеҗҺ
ж¬ўиҝҺеӨ§е®¶дёҖиө·дәӨжөҒпјҢе–ңж¬ўж–Үз« и®°еҫ—зӮ№дёӘиөһе“ҹпјҢж„ҹи°ўж”ҜжҢҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ