您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Apache Kafka 是 LinkedIn 基础设施的核心组件,最初是作为内部流式处理平台而诞生的,后来被开源出来,并得到了外部的广泛采用。虽然有很多公司和项目在使用 Kafka,但他们的数据规模很少能够达到 LinkedIn 这样。Kafka 被广泛地应用在 LinkedIn 的软件栈中,用于活动追踪、消息交换、指标收集,等等。LinkedIn 有 100 多个 Kafka 集群,其中包含了 4000 多个 broker,总共有 10 万多个 topic 和 700 万个分区。截止到目前,LinkedIn 的 Kafka 集群每天处理的消息数量超过了 7 万亿条。
如此大规模的处理容量不断给 LinkedIn 的 Kafka 生态系统带来伸缩性和运维方面的挑战。为了解决这方面的问题,LinkedIn 定制了一个 Kafka 版本。现在,这个分支也正式开源,并托管在 GitHub 上。这个分支的版本号与 Apache Kafka 的区别是后面加了 -li 后缀。
在这篇文章里,作者将介绍 LinkedIn 定制的 Kafka 版本的更多细节、补丁的开发流程、如何将变更传回上游,并介绍了一些补丁的大概情况和他们如何发布新版本。
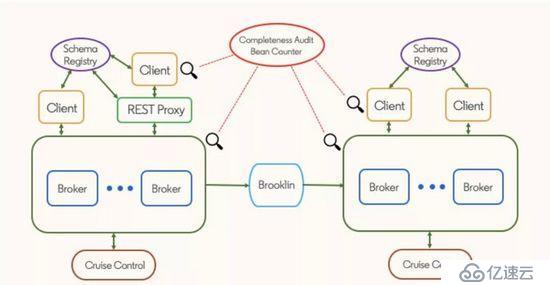
LinkedIn 的 Kafka 生态系统
基于 Apache Kafka 的流式处理生态系统是 LinkedIn 技术栈的一个关键组成部分。这个生态系统包含以下这些组件:
Kafka 集群;
使用了 Kafka 客户端的应用程序;
为非 Java 客户端提供服务的 REST 代理;
用于维护 Avro schema 的 schema 注册表;
用于镜像集群的 Brooklin
用于维护 Apache Kafka 集群的 Cruise Control
LinkedIn 的 Kafka 版本分支
正如之前所述,LinkedIn 内部的版本分支用于创建被部署在 LinkedIn 生产环境的 Kafka 版本。每一个版本分支都是从对应的 Apache Kafka 上游分支拉取出来的。毕竟,LinkedIn 并不是要对 Apache Kafka 进行 fork,只是要维护一个尽量与上游保持接近的版本。
因此,LinkedIn 通过两种方式提交补丁。
上游优先
LinkedIn 优先(也就是紧急修复)
先提交到 LinkedIn 的版本分支;
尝试提交到上游,但需要注意的是,提交到上游有可能因为各种原因不被接受;
除了自己创建的补丁,有时候 LinkedIn 也需要从上游择优挑选一些补丁。因此,LinkedIn 的版本分支包含了以下几种补丁:
Apache Kafka 补丁:提交到上游的补丁;
择优挑选的补丁:提交到上游之后再加入当前发布版本,它们可能是内部提交到上游的,也可能是来自外部的补丁;
紧急修复补丁:先是在内部创建,然后提交到上游;
换句话说,在过了分支点之后,每个 LinkedIn 的发布版本都会有两种补丁:优选补丁和紧急修复补丁。紧急修复补丁又包含只在 LinkedIn 内部使用和尝试提交到上游的补丁。从下图可以看出,尽管每一个提交补丁都会创建一个内部版本,但发布版本是按需创建的,而且可能包含多个补丁。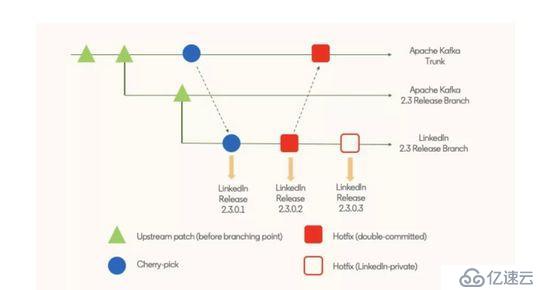
开发流程
LinkedIn 的 Kafka 补丁开发流程如下图所示。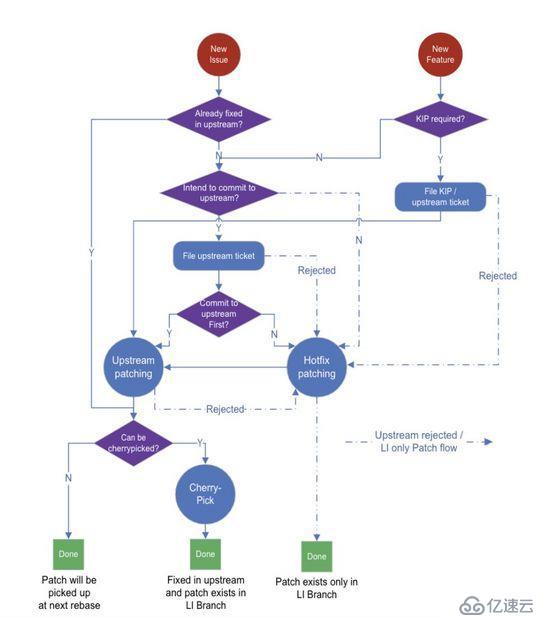
这里最关键的地方在于是选择“上游优先”还是“LinkedIn 优先”(也就是图中的“Commit to upstream first?”)。补丁开发者应该根据紧急程度慎重地做出决定。通常,用于解决生产环境问题的补丁先是作为紧急修复补丁,除非可以被快速提交到上游(比如在一周内)。有 KIP 的功能补丁应该先提交到上游。
补丁示例
下面将给出一些有代表性的补丁示例,有些已经提交到上游,有些只在 LinkedIn 内部使用。
伸缩性方面的改进
LinkedIn 内部有一些大集群,单个集群可能包含 140 多 broker 和 1 百万个副本。因为集群规模太大,导致控制器速度变慢,或者因为内存压力导致控制器发生故障。这些问题对生产环境造成了严重影响,还可能导致控制器级联故障。LinkedIn 提供了一些紧急补丁来解决这些问题,例如,使用 UpdateMetadataRequest 对象减少控制器的内存使用,并避免打印过多的日志。
因为单个集群包含的 broker 数量比较多,单个 broker 启动和关闭时间变慢也会导致整个集群的部署延迟严重增加。因此,为了保证 Kafka 集群的可用性,在部署时每次只能关掉一个 broker。为了解决这个部署问题,LinkedIn 提供了一些补丁,用于减少 broker 的启动和关闭时间(例如,通过减少锁竞争来缩短关闭时间)。
运维方面的改进
这些补丁主要用来解决 Kafka 的部署问题。例如,SRE 经常需要移除发生故障的 broker(例如,有些 broker 磁盘坏掉了),并向集群中加入新的 broker。在移除 broker 时需要保持同样水准的数据冗余,以便确保数据不会丢失。SRE 需要先将副本从发生故障的 broker 中移出,但这样做其实是很困难的,因为集群一直在创建新的 topic,新的副本有可能会被分配给发生故障的 broker。为了解决这个问题,LinkedIn 引入了维护模式。一个 broker 在进入维护模式后就不会被分配新的 topic 分区或副本。有了这个特性,就可以很容易地将一个 broker 的所有副本迁移给另一个 broker,然后把发生故障的 broker 完全关闭掉。
直接提交到上游的新特性
最近提交到上游的新特性包括 KIP-219、KIP-380、KIP-291 和 KIP-354。
还有一些在原先的 Apache Kafka 中不存在的新特性:
支持生产和消费计数,用于计费。
在创建 topic 时强制要求设定最小的副本系数,避免因为 broker 发生故障而丢失数据。
创建新的版本分支
之前已经介绍了 LinkedIn 的 Kafka 版本分支包含了哪些补丁和特性,接下来将介绍如何创建新的版本分支。首先是从 Apache Kafka 版本分支创建新的分支(例如,从 Apache Kafka 的 2.3.0 分支创建 LinkedIn Kafka 的 2.3.0.x 分支),然后将还未提交到上游的紧急修复从之前的 LinkedIn 版本分支(例如 2.0.0.x)合并到新的分支上。下图显示了这一过程: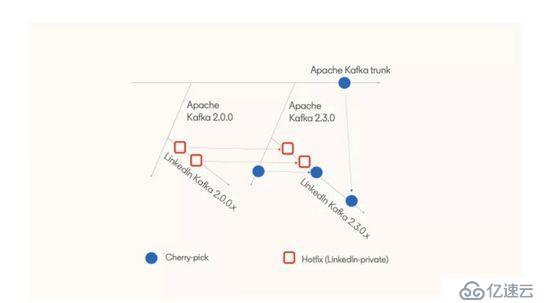
在这个过程中会在提交注释里指明一个紧急补丁是否需要被合并到新的分支上。例如,提交注释里可能会包含 Apache Kafka 的 ticket 号,通过这个 ticket 号就可以知道这个补丁是否已经被合并到 Apache Kafka 的分支上了。另外,Apache Kafka 分支上的补丁也会被定期择优合并到当前的 LinkedIn Kafka 分支上。
最后,新的版本分支会有一个验证过程。LinkedIn 使用了一个专门的验证框架,基于真实的生产流量针对新的版本进行各种测试。验证的项目包括再均衡、部署、回退、稳定性和降级。在通过验证之后,就可以发布新版本了。简单地说,LinkedIn 的每一个 Kafka 版本都会经过大规模的性能和正确性测试和验证。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。