您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
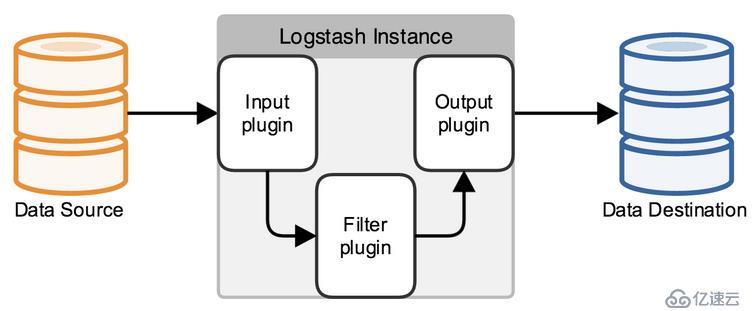
图1.1 logstash架构
logstash工作时,主要设置3个部分的工作属性。
input:设置数据来源
filter:可以对数据进行一定的加工处理过滤,但是不建议做复杂的处理逻辑。这个步骤不是必须的
output:设置输出目标
可以直接到 https://www.elastic.co/downloads/logstash 下载想要的版本,这里使用的是6.6.2 版本。部署其实很简单,现在下来直接解压就可以使用了,类似于flume,关键在于采集配置文件的编写。
一般就是使用如下方式启动logstash
调试方式:直接启动前台进程
bin/logstash -f /path/to/configfile
生产环境中一般后台启动:
nohup bin/logstash -f /path/to/configfile >标准日志 2>错误日志 &
启动前,可以使用 -t 选项测试配置文件是否有语法错误,如:
bin/logstash -f /path/to/configfile -t例子:监控文件内容输出到console
input {
file {
path => ["/var/log/*.log", "/var/log/message"]
type => "system"
start_position => "beginning"
}
}
output{stdout{codec=>rubydebug}}
有一些比较有用的配置项,可以用来指定 FileWatch 库的行为:
discover_interval
logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。
exclude
不想被监听的文件可以排除出去,这里跟 path 一样支持 glob 展开。
close_older
一个已经监听中的文件,如果超过这个值的时间内没有更新内容,就关闭监听它的文件句柄。默认是 3600 秒,即一小时。
ignore_older
在每次检查文件列表的时候,如果一个文件的最后修改时间超过这个值,就忽略这个文件。默认是 86400 秒,即一天。
sincedb_path
如果你不想用默认的 $HOME/.sincedb(Windows 平台上在 C:\Windows\System32\config\systemprofile\.sincedb),可以通过这个配置定义 sincedb 文件到其他位置。
sincedb_write_interval
logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。
stat_interval
logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。
start_position
logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,类似 less +F 的形式运行。stdin模块是用于标准输入,简单来说就是从标准输入读取数据。例子:
input {
stdin {
add_field => {"key" => "value"}
codec => "plain"
tags => ["add"]
type => "std"
}
}
output{stdout{codec=>rubydebug}}
输入hello,可以看到打印以下信息:
hello
{
"message" => "hello",
"tags" => [
[0] "[add]"
],
"@version" => "1",
"host" => "bigdata121",
"@timestamp" => 2019-09-07T03:20:35.569Z,
"type" => "std",
"key" => "value"
}
type 和 tags 是 logstash 事件中两个特殊的字段。通常来说我们会在输入区段中通过 type 来标记事件类型。而 tags 则是在数据处理过程中,由具体的插件来添加或者删除的。 默认情况下,logstash只支持纯文本形式的输入,然后在过滤器filter中将数据加工成指定格式。但现在,我们可以在输入期处理不同类型的数据,这全是因为有了 codec 设置。所以,这里需要纠正之前的一个概念。Logstash 不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。
例子,输入json格式数据
input {
stdin {
add_field => {"key" => "value"}
codec => "json"
type => "std"
}
}
output {
stdout {codec => rubydebug}
}
当输入json数据时,会自动解析出来
输入:{"name":"king"}
输出:
{
"name" => "king",
"host" => "bigdata121",
"@timestamp" => 2019-09-07T04:05:42.550Z,
"@version" => "1",
"type" => "std",
"key" => "value"
}logstash拥有丰富的filter插件,它们扩展了进入过滤器的原始数据,进行复杂的逻辑处理,甚至可以无中生有的添加新的 logstash 事件到后续的流程中去!Grok 是 Logstash 最重要的插件之一。也是迄今为止使蹩脚的、无结构的日志结构化和可查询的最好方式。Grok在解析 syslog logs、apache and other webserver logs、mysql logs等任意格式的文件上表现完美。
这个工具非常适用于系统日志,Apache和其他网络服务器日志,MySQL日志等。
配置:
input {
stdin {
type => "std"
}
}
filter {
grok {
match=>{"message"=> "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output{stdout{codec=>rubydebug}}
输入:55.3.244.1 GET /index.html 15824 0.043
输出:
{
"@version" => "1",
"host" => "zzc-203",
"request" => "/index.html",
"bytes" => "15824",
"duration" => "0.043",
"method" => "GET",
"@timestamp" => 2019-03-19T05:09:55.777Z,
"message" => "55.3.244.1 GET /index.html 15824 0.043",
"type" => "std",
"client" => "55.3.244.1"
}
grok模式的语法如下:
%{SYNTAX:SEMANTIC}
SYNTAX:代表匹配值的类型,例如3.44可以用NUMBER类型所匹配,127.0.0.1可以使用IP类型匹配。
SEMANTIC:代表存储该值的一个变量名称,例如 3.44 可能是一个事件的持续时间,127.0.0.1可能是请求的client地址。所以这两个值可以用 %{NUMBER:duration} %{IP:client} 来匹配。
你也可以选择将数据类型转换添加到Grok模式。默认情况下,所有语义都保存为字符串。如果您希望转换语义的数据类型,例如将字符串更改为整数,则将其后缀为目标数据类型。例如%{NUMBER:num:int}将num语义从一个字符串转换为一个整数。目前唯一支持的转换是int和float。
Logstash附带约120个模式。你可以在这里找到它们https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
自定义类型
更多时候logstash grok没办法提供你所需要的匹配类型,这个时候我们可以使用自定义。
创建自定义 patterns 文件。
①创建一个名为patterns其中创建一个文件postfix (文件名无关紧要,随便起),在该文件中,将需要的模式写为模式名称,空格,然后是该模式的正则表达式。例如:
POSTFIX_QUEUEID [0-9A-F]{10,11}
②然后使用这个插件中的patterns_dir设置告诉logstash目录是你的自定义模式。
配置:
input {
stdin {
type => "std"
}
}
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
output{stdout{codec=>rubydebug}}
输入:
Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver1
输出:
{
"queue_id" => "BEF25A72965",
"message" => "Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver1",
"pid" => "21403",
"program" => "postfix/cleanup",
"@version" => "1",
"type" => "std",
"logsource" => "mailserver14",
"host" => "zzc-203",
"timestamp" => "Jan 1 06:25:43",
"syslog_message" => "message-id=<20130101142543.5828399CCAF@mailserver1",
"@timestamp" => 2019-03-19T05:31:37.405Z
}
GeoIP 是最常见的免费 IP 地址归类查询库,同时也有收费版可以采购。GeoIP 库可以根据 IP 地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化地图和区域统计非常有用。
配置:
input {
stdin {
type => "std"
}
}
filter {
geoip {
source => "message"
}
}
output{stdout{codec=>rubydebug}}
输入:183.60.92.253
输出:
{
"type" => "std",
"@version" => "1",
"@timestamp" => 2019-03-19T05:39:26.714Z,
"host" => "zzc-203",
"message" => "183.60.92.253",
"geoip" => {
"country_code3" => "CN",
"latitude" => 23.1167,
"region_code" => "44",
"region_name" => "Guangdong",
"location" => {
"lon" => 113.25,
"lat" => 23.1167
},
"city_name" => "Guangzhou",
"country_name" => "China",
"continent_code" => "AS",
"country_code2" => "CN",
"timezone" => "Asia/Shanghai",
"ip" => "183.60.92.253",
"longitude" => 113.25
}
}前面已经说到了,通常用于测试,如:
input {
stdin {
type => "std"
}
}
output{stdout{codec=>rubydebug}} 通过日志收集系统将分散在数百台服务器上的数据集中存储在某中心服务器上,这是运维最原始的需求。Logstash 当然也能做到这点。例子
input {
stdin {
type => "std"
}
}
output {
file {
# 表示年 月 日 主机
path => "/tmp/%{+yyyy}-%{+MM}-%{+dd}-%{host}.log"
codec => line {format => "%{message}"}
}
}
输入:this is hello world
[2019-09-07T12:08:45,327][INFO ][logstash.outputs.file ] Opening file {:path=>"/tmp/2019-09-07-bigdata121.log"}
可以看到日志显示,将内容保存到 /tmp/2019-09-07-bigdata121.log 中
接着看看这个文件的内容,就是我们输入的内容接收日志服务器配置:
input {
tcp {
mode => "server"
port => 9600
ssl_enable => false
}
}
filter {
json {
source => "message"
}
}
output {
file {
path => "/home/hduser/app/logstash-6.6.2/data_test/%{+YYYY-MM-dd}/%{servip}-%{filename}"
codec => line { format => "%{message}"}
}
}
发送日志服务器配置:
input{
file {
path => ["/home/hduser/app/logstash-6.6.2/data_test/send.log"]
type => "ecolog"
start_position => "beginning"
}
}
filter {
if [type] =~ /^ecolog/ {
ruby {
code => "file_name = event.get('path').split('/')[-1]
event.set('file_name',file_name)
event.set('servip','接收方ip')"
}
mutate {
rename => {"file_name" => "filename"}
}
}
}
output {
tcp {
host => "接收方ip"
port => 9600
codec => json_lines
}
}
从发送方发送message,接收方可以看到写出文件。例子:将文件内容写入到es
input {
file {
path => ["/usr/local/logstash-6.6.2/data_test/run_error.log"]
# index和type名字中不能有大写
type => "error"
start_position => "beginning"
}
}
output {
elasticsearch {
# ES的serverip列表
hosts => ["192.168.109.133:9200"]
# 写入的index的名称
index => "logstash-%{type}-%{+YYYY.MM.dd}"
# type
document_type => "%{type}"
# 当上面的es节点无法使用,是否寻找其他es节点
sniffing => true
# 是否重写模板
template_overwrite => true
}
}有个小问题:
当日志中一行的内容过长时,在日志文件中会写成多行的形式。但是默认写入到es中时,是每一行就当做document来写入,而我们想要的是一条完整的日志作为一个document来写入。这时候就需要 codec的一个模块 multiline,例子
input {
file {
path =>"/the path/tmp.log"
#若日志为多行信息显示,需要codec配置
codec => multiline {
pattern => "^\[" 表示[ 开头的才是新的一条日志
negate => true
what => "previous"
}
start_position=>"beginning"
}
}
# filter为logstash的解析日志模块
filter {
# 解析日志生成相关的IP,访问地址,日志级别
grok {
match => {
"message" => "%{SYSLOG5424SD:time} %{IP:hostip} %{URIPATHPARAM:url}\s*%{LOGLEVEL:loglevel}"
}
}
#解析log生成的时间为时间戳
grok{
match => {
"message" => "%{TIMESTAMP_ISO8601:log_create_date}"
}
}
# 替换插入信息的时间戳为日志生成的时间戳
date {
match => ["log_create_date", "yyyy-MM-dd HH:mm:ss" ]
target => "@timestamp"
}
}
#定义日志输出的配置,此处为写入解析结果到es集群
output {
elasticsearch {
hosts => ["ip:9200"]
index => "system-log"
}
}
================================================
主要是input这一段的codec配置
input {
file {
path =>"/the path/tmp.log"
#若日志为多行信息显示,需要codec配置
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
start_position=>"beginning"
}
}
pattern => "^\["
默认是换行符分隔行,现在可以使用正则匹配来指定自定义的分隔符,作为一行
negate => true
如果前面的匹配成功了,true就表示取反,false表示维持原来的值,默认是false
what => "previous"或者“next”
匹配到的内容是属于上一个event还是下一个event免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。