жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үе°Ҷд»Ӣз»ҚйҖҡиҝҮJavaзЁӢеәҸжқҘиҜ»еҸ–PDFж–ҮжЎЈдёӯзҡ„ж–Үжң¬е’ҢеӣҫзүҮзҡ„ж–№жі•гҖӮеҲҶеҲ«и°ғз”Ёж–№жі•extractText()е’ҢextractImages()жқҘиҜ»еҸ–гҖӮ
дҪҝз”Ёе·Ҙе…·пјҡFree Spire.PDF for JavaпјҲе…Қиҙ№зүҲпјү
Jarж–Ү件иҺ·еҸ–еҜје…Ҙпјҡ
ж–№жі•1пјҡйҖҡиҝҮе®ҳзҪ‘дёӢиҪҪjarж–Ү件еҢ…гҖӮдёӢиҪҪеҗҺпјҢи§ЈеҺӢж–Ү件пјҢ并е°Ҷlibж–Ү件еӨ№дёӢзҡ„Spire.Pdf.jarж–Ү件еҜје…ҘjavaзЁӢеәҸгҖӮеҜје…ҘеҗҺеҰӮдёӢеӣҫпјҡ
ж–№жі•2пјҡ еҸҜйҖҡиҝҮmavenд»“еә“е®үиЈ…еҜје…ҘпјҢеҸҜеҸӮиҖғеҜје…Ҙж–№жі•гҖӮ
Javaд»Јз ҒзӨәдҫӢ
гҖҗзӨәдҫӢ1гҖ‘иҜ»еҸ–PDFдёӯзҡ„ж–Үжң¬
import com.spire.pdf.*;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractText {
public static void main(String[]args) throws Exception {
//еҠ иҪҪжөӢиҜ•ж–ҮжЎЈ
PdfDocument pdf = new PdfDocument("sample.pdf");
//е®һдҫӢеҢ–StringBuilderзұ»
StringBuilder sb = new StringBuilder();
//е®ҡд№үдёҖдёӘintеһӢеҸҳйҮҸ
int index = 0;
//йҒҚеҺҶPDFж–ҮжЎЈдёӯжҜҸйЎө
PdfPageBase page;
for (int i= 0; i<pdf.getPages().getCount();i++) {
page = pdf.getPages().get(i);
//и°ғз”ЁextractText()ж–№жі•жҸҗеҸ–ж–Үжң¬
sb.append(page.extractText(true));
FileWriter writer;
try {
//е°ҶStringBuilderеҜ№иұЎдёӯзҡ„ж–Үжң¬еҶҷе…ҘеҲ°txt
writer = new FileWriter("ExtractText.txt");
writer.write(sb.toString());
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
pdf.close();
}
}
ж–Үжң¬иҜ»еҸ–з»“жһңпјҡ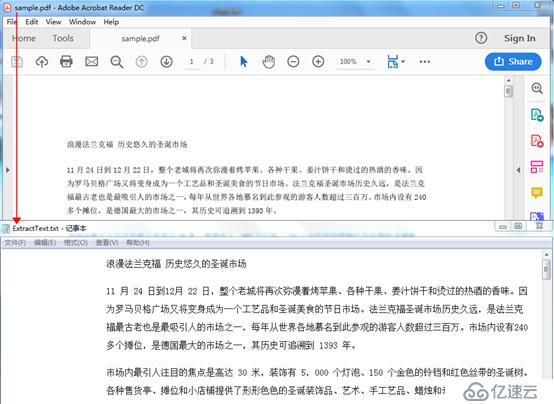
гҖҗзӨәдҫӢ2гҖ‘иҜ»еҸ–PDFдёӯзҡ„еӣҫзүҮ
import com.spire.pdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
public class ExtractImg {
public static void main(String[] args) throws Exception{
//еҠ иҪҪжөӢиҜ•ж–ҮжЎЈ
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("test.pdf");
//е®ҡд№үдёҖдёӘintеһӢеҸҳйҮҸ
int index = 0;
//йҒҚеҺҶPDFжҜҸдёҖйЎө
for (int i= 0;i< pdf.getPages().getCount(); i ++){
//иҺ·еҸ–PDFйЎөйқў
PdfPageBase page = pdf.getPages().get(i);
//дҪҝз”ЁextractImagesж–№жі•иҺ·еҸ–йЎөйқўдёҠеӣҫзүҮ
for (BufferedImage image : page.extractImages()) {
//жҢҮе®ҡиҫ“еҮәеӣҫзүҮеҗҚз§°
File output = new File( String.format("Image_%d.png", index++));
//е°ҶеӣҫзүҮдҝқеӯҳдёәPNGж јејҸж–Ү件
ImageIO.write(image, "PNG", output);
}
}
}
}
еӣҫзүҮиҜ»еҸ–з»“жһңпјҡ
пјҲжң¬ж–Үе®Ңпјү
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ