жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еүҚиЁҖ
еңЁи®Ўз®—жңә科еӯҰйўҶеҹҹпјҢеҲҶеёғејҸдёҖиҮҙжҖ§жҳҜдёҖдёӘзӣёеҪ“йҮҚиҰҒдё”иў«е№ҝжіӣжҺўзҙўдёҺи®әиҜҒй—®йўҳпјҢйҰ–е…ҲжқҘзңӢдёүз§ҚдёҡеҠЎеңәжҷҜгҖӮ

1гҖҒзҒ«иҪҰз«ҷе”®зҘЁ
еҒҮеҰӮиҜҙжҲ‘们зҡ„з»Ҳз«Ҝз”ЁжҲ·жҳҜдёҖдҪҚз»ҸеёёеқҗзҒ«иҪҰзҡ„ж—…иЎҢ家пјҢйҖҡеёёд»–жҳҜеҺ»иҪҰз«ҷзҡ„е”®зҘЁеӨ„иҙӯд№°иҪҰзҘЁпјҢ然еҗҺжӢҝзқҖиҪҰзҘЁеҺ»жЈҖзҘЁеҸЈпјҢеҶҚеқҗдёҠзҒ«иҪҰпјҢејҖе§ӢдёҖж®өзҫҺеҘҪзҡ„ж—…иЎҢ----дёҖеҲҮдјјд№ҺйғҪжҳҜйӮЈд№Ҳе’Ңи°җгҖӮ
жғіиұЎдёҖдёӢпјҢеҰӮжһңд»–йҖүжӢ©зҡ„зӣ®зҡ„ең°жҳҜжқӯе·һпјҢиҖҢжҹҗдёҖи¶ҹејҖеҫҖжқӯе·һзҡ„зҒ«иҪҰеҸӘеү©дёӢжңҖеҗҺдёҖеј иҪҰзҘЁпјҢеҸҜиғҪеңЁеҗҢдёҖж—¶еҲ»пјҢдёҚеҗҢе”®зҘЁзӘ—еҸЈзҡ„еҸҰдёҖдҪҚд№ҳе®ўд№ҹиҙӯд№°дәҶеҗҢдёҖеј иҪҰзҘЁгҖӮеҒҮеҰӮиҜҙе”®зҘЁзі»з»ҹжІЎжңүиҝӣиЎҢдёҖиҮҙжҖ§зҡ„дҝқйҡңпјҢдёӨдәәйғҪиҙӯзҘЁжҲҗеҠҹдәҶгҖӮиҖҢеңЁжЈҖзҘЁеҸЈжЈҖзҘЁзҡ„ж—¶еҖҷпјҢе…¶дёӯдёҖдҪҚд№ҳе®ўдјҡиў«е‘ҠзҹҘд»–зҡ„иҪҰзҘЁж— ж•ҲвҖҰвҖҰ
еҪ“然пјҢзҺ°д»Јзҡ„дёӯеӣҪй“Ғи·Ҝе”®зҘЁзі»з»ҹе·Із»ҸеҫҲе°‘еҮәзҺ°иҝҷж ·зҡ„й—®йўҳдәҶгҖӮдҪҶеңЁиҝҷдёӘдҫӢеӯҗдёӯжҲ‘们еҸҜд»ҘзңӢеҮәпјҢз»Ҳз«Ҝз”ЁжҲ·еҜ№дәҺзі»з»ҹзҡ„йңҖжұӮйқһеёёз®ҖеҚ•пјҡ
"иҜ·е”®зҘЁз»ҷжҲ‘пјҢеҰӮжһңжІЎжңүдҪҷзҘЁдәҶпјҢиҜ·еңЁе”®зҘЁзҡ„ж—¶еҖҷе°ұе‘ҠиҜүжҲ‘зҘЁжҳҜж— ж•Ҳзҡ„"
иҝҷе°ұеҜ№иҙӯзҘЁзі»з»ҹжҸҗеҮәдәҶдёҘж јзҡ„дёҖиҮҙжҖ§иҰҒжұӮ----зі»з»ҹзҡ„ж•°жҚ®пјҲжң¬дҫӢдёӯжҢҮзҡ„е°ұжҳҜйӮЈи¶ҹејҖеҫҖжқӯе·һзҡ„зҒ«иҪҰзҡ„дҪҷзҘЁж•°пјүж— и®әеңЁе“ӘдёӘе”®зҘЁзӘ—еҸЈпјҢжҜҸж—¶жҜҸеҲ»йғҪеҝ…йЎ»жҳҜеҮҶзЎ®ж— иҜҜзҡ„пјҒ
2гҖҒ银иЎҢиҪ¬иҙҰ
еҒҮеҰӮжҲ‘们зҡ„з»Ҳз«Ҝз”ЁжҲ·жҳҜдёҖдҪҚеҲҡжҜ•дёҡзҡ„еӨ§еӯҰз”ҹпјҢйҖҡеёёеңЁжӢҝеҲ°з¬¬дёҖдёӘжңҲе·Ҙиө„зҡ„ж—¶еҖҷпјҢйғҪдјҡйҖүжӢ©еҗ‘家йҮҢжұҮж¬ҫгҖӮеҪ“д»–жқҘеҲ°й“¶иЎҢжҹңеҸ°пјҢе®ҢжҲҗиҪ¬иҙҰж“ҚдҪңеҗҺпјҢ银иЎҢзҡ„жҹңеҸ°жңҚеҠЎе‘ҳдјҡеҸӢе–„ең°жҸҗйҶ’д»–пјҡ"жӮЁзҡ„иҪ¬иҙҰе°ҶеңЁNдёӘе·ҘдҪңж—ҘеҗҺеҲ°иҙҰпјҒ"гҖӮ
жӯӨж—¶иҝҷеҗҚжҜ•дёҡз”ҹжңүдёҖе®ҡзҡ„жІ®дё§пјҢдјҡеҜ№йӮЈеҗҚжҹңеҸ°жңҚеҠЎе‘ҳеҸ®еҳұпјҡ"еҘҪеҗ§пјҢеӨҡд№…жІЎе…ізі»пјҢй’ұдёҚиҰҒе°‘е°ұеҘҪдәҶпјҒ"вҖҰвҖҰ
иҝҷд№ҹжҲҗдёәдәҶеҮ д№ҺжүҖжңүз”ЁжҲ·еҜ№дәҺзҺ°д»Јй“¶иЎҢзі»з»ҹжңҖеҹәжң¬зҡ„йңҖжұӮ
3гҖҒзҪ‘дёҠиҙӯзү©
еҒҮеҰӮиҜҙжҲ‘们зҡ„з»Ҳз«Ҝз”ЁжҲ·жҳҜдёҖдҪҚзҪ‘иҙӯиҫҫдәәпјҢеҪ“д»–зңӢи§ҒдёҖ件еә“еӯҳйҮҸдёә5зҡ„еҝғд»Әе•Ҷе“ҒпјҢдјҡиҝ…йҖҹең°зЎ®и®Өиҙӯд№°пјҢеҶҷдёӢ收иҙ§ең°еқҖпјҢ然еҗҺдёӢеҚ•вҖҰвҖҰ
然иҖҢпјҢеңЁдёӢеҚ•зҡ„йӮЈдёӘзһ¬й—ҙпјҢзі»з»ҹеҸҜиғҪдјҡе‘ҠзҹҘиҜҘз”ЁжҲ·пјҡ"еә“еӯҳйҮҸдёҚи¶іпјҒ"гҖӮжӯӨж—¶з»қеӨ§йғЁеҲҶж¶Ҳиҙ№иҖ…йғҪдјҡжҠұжҖЁиҮӘе·ұеҠЁдҪңеӨӘж…ўпјҢдҪҝеҫ—еҝғзҲұзҡ„е•Ҷе“Ғиў«е…¶д»–дәәжҠўиө°дәҶгҖӮ
дҪҶе…¶е®һжңүиҝҮзҪ‘иҙӯзі»з»ҹејҖеҸ‘з»ҸйӘҢзҡ„е·ҘзЁӢеёҲдёҖе®ҡжҳҺзҷҪпјҢеңЁе•Ҷе“ҒиҜҰжғ…йЎөдёҠжҳҫзӨәзҡ„йӮЈдёӘеә“еӯҳйҮҸпјҢйҖҡеёёдёҚжҳҜиҜҘе•Ҷе“Ғзҡ„зңҹе®һеә“еӯҳйҮҸпјҢеҸӘжңүеңЁзңҹжӯЈдёӢеҚ•иҙӯд№°зҡ„ж—¶еҖҷпјҢзі»з»ҹжүҚдјҡжЈҖжҹҘиҜҘе•Ҷе“Ғзҡ„зңҹе®һеә“еӯҳйҮҸгҖӮдҪҶжҳҜпјҢи°ҒеңЁж„Ҹе‘ўпјҹ

й—®йўҳзҡ„и§ЈиҜ»
еҜ№дәҺдёҠйқўдёүдёӘдҫӢеӯҗпјҢзӣёдҝЎеӨ§е®¶дёҖе®ҡзңӢеҮәжқҘдәҶпјҢжҲ‘们зҡ„з»Ҳз«Ҝз”ЁжҲ·еңЁдҪҝз”ЁдёҚеҗҢзҡ„и®Ўз®—жңәдә§е“Ғж—¶еҜ№дәҺж•°жҚ®дёҖиҮҙжҖ§зҡ„йңҖжұӮжҳҜдёҚдёҖж ·зҡ„пјҡ
1гҖҒжңүдәӣзі»з»ҹпјҢж—ўиҰҒеҝ«йҖҹең°е“Қеә”з”ЁжҲ·пјҢеҗҢж—¶иҝҳиҰҒдҝқиҜҒзі»з»ҹзҡ„ж•°жҚ®еҜ№дәҺд»»ж„Ҹе®ўжҲ·з«ҜйғҪжҳҜзңҹе®һеҸҜйқ зҡ„пјҢе°ұеғҸзҒ«иҪҰз«ҷе”®зҘЁзі»з»ҹ
2гҖҒжңүдәӣзі»з»ҹпјҢйңҖиҰҒдёәз”ЁжҲ·дҝқиҜҒз»қеҜ№еҸҜйқ зҡ„ж•°жҚ®е®үе…ЁпјҢиҷҪ然еңЁж•°жҚ®дёҖиҮҙжҖ§дёҠеӯҳеңЁе»¶ж—¶пјҢдҪҶжңҖз»ҲеҠЎеҝ…дҝқиҜҒдёҘж јзҡ„дёҖиҮҙжҖ§пјҢе°ұеғҸ银иЎҢзҡ„иҪ¬иҙҰзі»з»ҹ
3гҖҒжңүдәӣзі»з»ҹпјҢиҷҪ然еҗ‘з”ЁжҲ·еұ•зӨәдәҶдёҖдәӣеҸҜд»ҘиҜҙжҳҜ"й”ҷиҜҜ"зҡ„ж•°жҚ®пјҢдҪҶжҳҜеңЁж•ҙдёӘзі»з»ҹдҪҝз”ЁиҝҮзЁӢдёӯпјҢдёҖе®ҡдјҡеңЁжҹҗдёҖдёӘжөҒзЁӢдёҠеҜ№зі»з»ҹж•°жҚ®иҝӣиЎҢеҮҶзЎ®ж— иҜҜзҡ„жЈҖжҹҘпјҢд»ҺиҖҢйҒҝе…Қз”ЁжҲ·еҸ‘з”ҹдёҚеҝ…иҰҒзҡ„жҚҹеӨұпјҢе°ұеғҸзҪ‘иҙӯзі»з»ҹ
еҲҶеёғејҸдёҖиҮҙжҖ§зҡ„жҸҗеҮә
еңЁеҲҶеёғејҸзі»з»ҹдёӯиҰҒи§ЈеҶізҡ„дёҖдёӘйҮҚиҰҒй—®йўҳе°ұжҳҜж•°жҚ®зҡ„еӨҚеҲ¶гҖӮ
еңЁжҲ‘们зҡ„ж—ҘеёёејҖеҸ‘з»ҸйӘҢдёӯпјҢзӣёдҝЎеҫҲеӨҡејҖеҸ‘дәәе‘ҳйғҪйҒҮеҲ°иҝҮиҝҷж ·зҡ„й—®йўҳпјҡеҒҮи®ҫе®ўжҲ·з«ҜC1е°Ҷзі»з»ҹдёӯзҡ„дёҖдёӘеҖјKз”ұV1жӣҙж–°дёәV2пјҢдҪҶе®ўжҲ·з«ҜC2ж— жі•з«ӢеҚіиҜ»еҸ–еҲ°Kзҡ„жңҖж–°еҖјпјҢйңҖиҰҒеңЁдёҖж®өж—¶й—ҙд№ӢеҗҺжүҚиғҪиҜ»еҸ–еҲ°гҖӮ
иҝҷеҫҲжӯЈеёёпјҢеӣ дёәж•°жҚ®еә“еӨҚеҲ¶д№Ӣй—ҙеӯҳеңЁе»¶ж—¶гҖӮ
еҲҶеёғејҸзі»з»ҹеҜ№дәҺж•°жҚ®зҡ„еӨҚеҲ¶йңҖжұӮдёҖиҲ¬йғҪжқҘиҮӘдәҺд»ҘдёӢдёӨдёӘеҺҹеӣ пјҡ
1гҖҒдёәдәҶеўһеҠ зі»з»ҹзҡ„еҸҜз”ЁжҖ§пјҢд»ҘйҳІжӯўеҚ•зӮ№ж•…йҡңеј•иө·зҡ„зі»з»ҹдёҚеҸҜз”Ё
2гҖҒжҸҗй«ҳзі»з»ҹзҡ„ж•ҙдҪ“жҖ§иғҪпјҢйҖҡиҝҮиҙҹиҪҪеқҮиЎЎжҠҖжңҜпјҢиғҪеӨҹи®©еҲҶеёғеңЁдёҚеҗҢең°ж–№зҡ„ж•°жҚ®еүҜжң¬йғҪиғҪеӨҹдёәз”ЁжҲ·жҸҗдҫӣжңҚеҠЎ
ж•°жҚ®еӨҚеҲ¶еңЁеҸҜз”ЁжҖ§е’ҢжҖ§иғҪж–№йқўз»ҷеҲҶеёғејҸзі»з»ҹеёҰжқҘзҡ„е·ЁеӨ§еҘҪеӨ„жҳҜдёҚиЁҖиҖҢе–»зҡ„пјҢ然иҖҢж•°жҚ®еӨҚеҲ¶жүҖеёҰжқҘзҡ„дёҖиҮҙжҖ§жҢ‘жҲҳпјҢд№ҹжҳҜжҜҸдёҖдёӘзі»з»ҹз ”еҸ‘дәәе‘ҳдёҚеҫ—дёҚйқўеҜ№зҡ„гҖӮ
жүҖи°“еҲҶеёғдёҖиҮҙжҖ§й—®йўҳпјҢжҳҜжҢҮеңЁеҲҶеёғејҸзҺҜеўғдёӯеј•е…Ҙж•°жҚ®еӨҚеҲ¶жңәеҲ¶д№ӢеҗҺпјҢдёҚеҗҢж•°жҚ®иҠӮзӮ№д№Ӣй—ҙеҸҜиғҪеҮәзҺ°зҡ„пјҢе№¶ж— жі•дҫқйқ и®Ўз®—жңәеә”з”ЁзЁӢеәҸиҮӘиә«и§ЈеҶізҡ„ж•°жҚ®дёҚдёҖиҮҙзҡ„жғ…еҶөгҖӮз®ҖеҚ•и®ІпјҢж•°жҚ®дёҖиҮҙжҖ§е°ұжҳҜжҢҮеңЁеҜ№дёҖдёӘеүҜжң¬ж•°жҚ®иҝӣиЎҢжӣҙж–°зҡ„ж—¶еҖҷпјҢеҝ…йЎ»зЎ®дҝқд№ҹиғҪеӨҹжӣҙж–°е…¶д»–зҡ„еүҜжң¬пјҢеҗҰеҲҷдёҚеҗҢеүҜжң¬д№Ӣй—ҙзҡ„ж•°жҚ®е°ҶдёҚдёҖиҮҙгҖӮ
йӮЈд№ҲеҰӮдҪ•и§ЈеҶіиҝҷдёӘй—®йўҳпјҹдёҖз§ҚжҖқи·ҜжҳҜ"既然жҳҜз”ұдәҺ延时еҠЁдҪңеј•иө·зҡ„й—®йўҳпјҢйӮЈжҲ‘еҸҜд»Ҙе°ҶеҶҷе…Ҙзҡ„еҠЁдҪңйҳ»еЎһпјҢзӣҙеҲ°ж•°жҚ®еӨҚеҲ¶е®ҢжҲҗеҗҺпјҢжүҚе®ҢжҲҗеҶҷе…ҘеҠЁдҪң"гҖӮ
жІЎй”ҷпјҢиҝҷдјјд№ҺиғҪи§ЈеҶій—®йўҳпјҢиҖҢдё”жңүдёҖдәӣзі»з»ҹзҡ„жһ¶жһ„д№ҹзЎ®е®һзӣҙжҺҘдҪҝз”ЁдәҶиҝҷдёӘжҖқи·ҜгҖӮдҪҶиҝҷдёӘжҖқи·ҜеңЁи§ЈеҶідёҖиҮҙжҖ§й—®йўҳзҡ„еҗҢж—¶пјҢеҸҲеёҰжқҘдәҶж–°зҡ„й—®йўҳпјҡеҶҷе…Ҙзҡ„жҖ§иғҪгҖӮ
еҰӮжһңдҪ зҡ„еә”з”ЁеңәжҷҜжңүйқһеёёеӨҡзҡ„еҶҷиҜ·жұӮпјҢйӮЈд№ҲдҪҝз”ЁиҝҷдёӘжҖқи·Ҝд№ӢеҗҺпјҢеҗҺз»ӯзҡ„еҶҷиҜ·жұӮйғҪе°Ҷдјҡйҳ»еЎһеңЁеүҚдёҖдёӘиҜ·жұӮзҡ„еҶҷж“ҚдҪңдёҠпјҢеҜјиҮҙзі»з»ҹж•ҙдҪ“жҖ§иғҪжҖҘеү§дёӢйҷҚгҖӮ
жҖ»еҫ—жқҘиҜҙпјҢжҲ‘д»¬ж— жі•жүҫеҲ°дёҖз§ҚиғҪеӨҹж»Ўи¶іеҲҶеёғејҸзі»з»ҹжүҖжңүзі»з»ҹеұһжҖ§зҡ„еҲҶеёғејҸдёҖиҮҙжҖ§и§ЈеҶіж–№жЎҲгҖӮеӣ жӯӨпјҢеҰӮдҪ•ж—ўдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҢеҗҢж—¶еҸҲдёҚеҪұе“Қзі»з»ҹиҝҗиЎҢзҡ„жҖ§иғҪпјҢжҳҜжҜҸдёҖдёӘеҲҶеёғејҸзі»з»ҹйғҪйңҖиҰҒйҮҚзӮ№иҖғиҷ‘е’ҢжқғиЎЎзҡ„гҖӮдәҺжҳҜпјҢдёҖиҮҙжҖ§зә§еҲ«з”ұжӯӨиҜһз”ҹпјҡ
1гҖҒејәдёҖиҮҙжҖ§
иҝҷз§ҚдёҖиҮҙжҖ§зә§еҲ«жҳҜжңҖз¬ҰеҗҲз”ЁжҲ·зӣҙи§үзҡ„пјҢе®ғиҰҒжұӮзі»з»ҹеҶҷе…Ҙд»Җд№ҲпјҢиҜ»еҮәжқҘзҡ„д№ҹдјҡжҳҜд»Җд№ҲпјҢз”ЁжҲ·дҪ“йӘҢеҘҪпјҢдҪҶе®һзҺ°иө·жқҘеҫҖеҫҖеҜ№зі»з»ҹзҡ„жҖ§иғҪеҪұе“ҚеӨ§
2гҖҒејұдёҖиҮҙжҖ§
иҝҷз§ҚдёҖиҮҙжҖ§зә§еҲ«зәҰжқҹдәҶзі»з»ҹеңЁеҶҷе…ҘжҲҗеҠҹеҗҺпјҢдёҚжүҝиҜәз«ӢеҚіеҸҜд»ҘиҜ»еҲ°еҶҷе…Ҙзҡ„еҖјпјҢд№ҹдёҚд№…жүҝиҜәеӨҡд№…д№ӢеҗҺж•°жҚ®иғҪеӨҹиҫҫеҲ°дёҖиҮҙпјҢдҪҶдјҡе°ҪеҸҜиғҪең°дҝқиҜҒеҲ°жҹҗдёӘж—¶й—ҙзә§еҲ«пјҲжҜ”еҰӮз§’зә§еҲ«пјүеҗҺпјҢж•°жҚ®иғҪеӨҹиҫҫеҲ°дёҖиҮҙзҠ¶жҖҒ
3гҖҒжңҖз»ҲдёҖиҮҙжҖ§
жңҖз»ҲдёҖиҮҙжҖ§жҳҜејұдёҖиҮҙжҖ§зҡ„дёҖдёӘзү№дҫӢпјҢзі»з»ҹдјҡдҝқиҜҒеңЁдёҖе®ҡж—¶й—ҙеҶ…пјҢиғҪеӨҹиҫҫеҲ°дёҖдёӘж•°жҚ®дёҖиҮҙзҡ„зҠ¶жҖҒгҖӮиҝҷйҮҢд№ӢжүҖд»Ҙе°ҶжңҖз»ҲдёҖиҮҙжҖ§еҚ•зӢ¬жҸҗеҮәжқҘпјҢжҳҜеӣ дёәе®ғжҳҜејұдёҖиҮҙжҖ§дёӯйқһеёёжҺЁеҙҮзҡ„дёҖз§ҚдёҖиҮҙжҖ§жЁЎеһӢпјҢд№ҹжҳҜдёҡз•ҢеңЁеӨ§еһӢеҲҶеёғејҸзі»з»ҹзҡ„ж•°жҚ®дёҖиҮҙжҖ§дёҠжҜ”иҫғжҺЁеҙҮзҡ„жЁЎеһӢ
ж¬ўиҝҺеӨ§е®¶е…іжіЁжҲ‘зҡ„е…¬з§Қжө©гҖҗзЁӢеәҸе‘ҳиҝҪйЈҺгҖ‘пјҢж–Үз« йғҪдјҡеңЁйҮҢйқўжӣҙж–°пјҢж•ҙзҗҶзҡ„иө„ж–ҷд№ҹдјҡж”ҫеңЁйҮҢйқўгҖӮ

еҲҶеёғејҸзҺҜеўғзҡ„еҗ„з§Қй—®йўҳ
еҲҶеёғејҸзі»з»ҹдҪ“зі»з»“жһ„д»Һе…¶еҮәзҺ°д№ӢеҲқе°ұдјҙйҡҸзқҖиҜёеӨҡзҡ„йҡҫйўҳе’ҢжҢ‘жҲҳпјҡ
1гҖҒйҖҡдҝЎејӮеёё
д»ҺйӣҶдёӯејҸеҗ‘еҲҶеёғејҸжј”еҸҳзҡ„иҝҮзЁӢдёӯпјҢеҝ…然引е…ҘзҪ‘з»ңеӣ зҙ пјҢз”ұдәҺзҪ‘з»ңжң¬иә«зҡ„дёҚеҸҜйқ жҖ§пјҢеӣ жӯӨд№ҹеј•е…ҘдәҶйўқеӨ–зҡ„й—®йўҳгҖӮ
еҲҶеёғејҸзі»з»ҹйңҖиҰҒеңЁеҗ„дёӘиҠӮзӮ№д№Ӣй—ҙиҝӣиЎҢзҪ‘з»ңйҖҡдҝЎпјҢеӣ жӯӨжҜҸж¬ЎзҪ‘з»ңйҖҡдҝЎйғҪдјҡдјҙйҡҸзқҖзҪ‘з»ңдёҚеҸҜз”Ёзҡ„йЈҺйҷ©пјҢзҪ‘з»ңе…үзәӨгҖҒи·Ҝз”ұеҷЁжҲ–жҳҜDNSзӯү硬件и®ҫеӨҮжҲ–жҳҜзі»з»ҹдёҚеҸҜз”ЁйғҪдјҡеҜјиҮҙжңҖз»ҲеҲҶеёғејҸзі»з»ҹж— жі•йЎәеҲ©е®ҢжҲҗдёҖж¬ЎзҪ‘з»ңйҖҡдҝЎгҖӮ
еҸҰеӨ–пјҢеҚідҪҝеҲҶеёғејҸзі»з»ҹеҗ„дёӘиҠӮзӮ№д№Ӣй—ҙзҡ„зҪ‘з»ңйҖҡдҝЎиғҪеӨҹжӯЈеёёиҝӣиЎҢпјҢ其延时д№ҹдјҡеӨ§дәҺеҚ•жңәж“ҚдҪңгҖӮ
йҖҡеёёжҲ‘们и®ӨдёәзҺ°д»Ји®Ўз®—жңәдҪ“зі»з»“жһ„дёӯпјҢеҚ•жңәеҶ…еӯҳи®ҝй—®зҡ„延时еңЁзәіз§’ж•°йҮҸзә§пјҲйҖҡеёёжҳҜ10nsпјүпјҢиҖҢжӯЈеёёзҡ„дёҖж¬ЎзҪ‘з»ңйҖҡдҝЎзҡ„延иҝҹеңЁ0.1~1msе·ҰеҸіпјҲзӣёеҪ“дәҺеҶ…еӯҳи®ҝ问延时зҡ„105еҖҚпјүпјҢеҰӮжӯӨе·ЁеӨ§зҡ„延时差еҲ«пјҢд№ҹдјҡеҪұе“ҚеҲ°ж¶ҲжҒҜзҡ„收еҸ‘иҝҮзЁӢпјҢеӣ жӯӨж¶ҲжҒҜдёўеӨұе’Ңж¶ҲжҒҜ延иҝҹеҸҳеҫ—йқһеёёжҷ®йҒҚгҖӮ
2гҖҒзҪ‘з»ңеҲҶеҢә
еҪ“зҪ‘з»ңз”ұдәҺеҸ‘з”ҹејӮеёёжғ…еҶөпјҢеҜјиҮҙеҲҶеёғејҸзі»з»ҹдёӯйғЁеҲҶиҠӮзӮ№д№Ӣй—ҙзҡ„зҪ‘з»ң延时дёҚж–ӯеўһеӨ§пјҢжңҖз»ҲеҜјиҮҙз»„жҲҗеҲҶеёғејҸзі»з»ҹзҡ„жүҖжңүиҠӮзӮ№дёӯпјҢеҸӘжңүйғЁеҲҶиҠӮзӮ№д№Ӣй—ҙиғҪеӨҹжӯЈеёёйҖҡдҝЎпјҢиҖҢеҸҰдёҖдәӣиҠӮзӮ№еҲҷдёҚиғҪ----жҲ‘们е°ҶиҝҷдёӘзҺ°иұЎз§°дёәзҪ‘з»ңеҲҶеҢәгҖӮ
еҪ“зҪ‘з»ңеҲҶеҢәеҮәзҺ°ж—¶пјҢеҲҶеёғејҸзі»з»ҹдјҡеҮәзҺ°еұҖйғЁе°ҸйӣҶзҫӨпјҢеңЁжһҒз«Ҝжғ…еҶөдёӢпјҢиҝҷдәӣеұҖйғЁе°ҸйӣҶзҫӨдјҡзӢ¬з«Ӣе®ҢжҲҗеҺҹжң¬йңҖиҰҒж•ҙдёӘеҲҶеёғејҸзі»з»ҹжүҚиғҪе®ҢжҲҗзҡ„еҠҹиғҪпјҢеҢ…жӢ¬еҜ№ж•°жҚ®зҡ„дәӢзү©еӨ„зҗҶпјҢиҝҷе°ұеҜ№еҲҶеёғејҸдёҖиҮҙжҖ§жҸҗеҮәдәҶйқһеёёеӨ§зҡ„жҢ‘жҲҳгҖӮ
3гҖҒдёүжҖҒ
дёҠйқўдёӨзӮ№пјҢжҲ‘们已з»ҸдәҶи§ЈеҲ°еңЁеҲҶеёғејҸзҺҜеўғдёӢпјҢзҪ‘з»ңеҸҜиғҪдјҡеҮәзҺ°еҗ„ејҸеҗ„ж ·зҡ„й—®йўҳпјҢеӣ жӯӨеҲҶеёғејҸзі»з»ҹзҡ„жҜҸдёҖж¬ЎиҜ·жұӮдёҺе“Қеә”пјҢеӯҳеңЁзү№жңүзҡ„дёүжҖҒжҰӮеҝөпјҢеҚіжҲҗеҠҹгҖҒеӨұиҙҘгҖҒи¶…ж—¶гҖӮ
еңЁдј з»ҹзҡ„еҚ•жңәзі»з»ҹдёӯпјҢеә”з”ЁзЁӢеәҸеңЁи°ғз”ЁдёҖдёӘеҮҪж•°д№ӢеҗҺпјҢиғҪеӨҹеҫ—еҲ°дёҖдёӘйқһеёёжҳҺзЎ®зҡ„е“Қеә”пјҡжҲҗеҠҹжҲ–еӨұиҙҘгҖӮиҖҢеңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢз”ұдәҺзҪ‘з»ңжҳҜдёҚеҸҜйқ зҡ„пјҢиҷҪ然еңЁз»қеӨ§йғЁеҲҶжғ…еҶөдёӢпјҢзҪ‘з»ңйҖҡдҝЎд№ҹиғҪеӨҹжҺҘеҸ—еҲ°жҲҗеҠҹжҲ–еӨұиҙҘзҡ„е“Қеә”пјҢеҪ“ж—¶еҪ“зҪ‘з»ңеҮәзҺ°ејӮеёёзҡ„жғ…еҶөдёӢпјҢе°ұеҸҜиғҪдјҡеҮәзҺ°и¶…ж—¶зҺ°иұЎпјҢйҖҡеёёжңүд»ҘдёӢдёӨз§Қжғ…еҶөпјҡ
пјҲ1пјүз”ұдәҺзҪ‘з»ңеҺҹеӣ пјҢиҜҘиҜ·жұӮ并没жңүиў«жҲҗеҠҹең°еҸ‘йҖҒеҲ°жҺҘ收方пјҢиҖҢжҳҜеңЁеҸ‘йҖҒиҝҮзЁӢдёӯе°ұеҸ‘з”ҹдәҶж¶ҲжҒҜдёўеӨұзҺ°иұЎ
пјҲ2пјүиҜҘиҜ·жұӮжҲҗеҠҹең°иў«жҺҘ收方жҺҘ收еҗҺпјҢиҝӣиЎҢдәҶеӨ„зҗҶпјҢдҪҶжҳҜеңЁе°Ҷе“Қеә”еҸҚйҰҲз»ҷеҸ‘йҖҒж–№зҡ„иҝҮзЁӢдёӯпјҢеҸ‘з”ҹдәҶж¶ҲжҒҜдёўеӨұзҺ°иұЎ
еҪ“еҮәзҺ°иҝҷж ·зҡ„и¶…ж—¶зҺ°иұЎж—¶пјҢзҪ‘з»ңйҖҡдҝЎзҡ„еҸ‘иө·ж–№жҳҜж— жі•зЎ®е®ҡеҪ“еүҚиҜ·жұӮжҳҜеҗҰиў«жҲҗеҠҹеӨ„зҗҶзҡ„
4гҖҒиҠӮзӮ№ж•…йҡң
иҠӮзӮ№ж•…йҡңеҲҷжҳҜеҲҶеёғејҸзҺҜеўғдёӢеҸҰдёҖдёӘжҜ”иҫғеёёи§Ғзҡ„й—®йўҳпјҢжҢҮзҡ„жҳҜз»„жҲҗеҲҶеёғејҸзі»з»ҹзҡ„жңҚеҠЎеҷЁиҠӮзӮ№еҮәзҺ°зҡ„е®•жңәжҲ–"еғөжӯ»"зҺ°иұЎпјҢйҖҡеёёж №жҚ®з»ҸйӘҢжқҘиҜҙпјҢжҜҸдёӘиҠӮзӮ№йғҪжңүеҸҜиғҪеҮәзҺ°ж•…йҡңпјҢ并且жҜҸеӨ©йғҪеңЁеҸ‘з”ҹ

еҲҶеёғејҸдәӢеҠЎ
йҡҸзқҖеҲҶеёғејҸи®Ўз®—зҡ„еҸ‘еұ•пјҢдәӢзү©еңЁеҲҶеёғејҸи®Ўз®—йўҶеҹҹд№ҹеҫ—еҲ°дәҶе№ҝжіӣзҡ„еә”з”ЁгҖӮ
еңЁеҚ•жңәж•°жҚ®еә“дёӯпјҢжҲ‘们еҫҲе®№жҳ“иғҪеӨҹе®һзҺ°дёҖеҘ—ж»Ўи¶іACIDзү№жҖ§зҡ„дәӢзү©еӨ„зҗҶзі»з»ҹпјҢдҪҶеңЁеҲҶеёғејҸж•°жҚ®еә“дёӯпјҢж•°жҚ®еҲҶж•ЈеңЁеҗ„еҸ°дёҚеҗҢзҡ„жңәеҷЁдёҠпјҢеҰӮдҪ•еҜ№иҝҷдәӣж•°жҚ®иҝӣиЎҢеҲҶеёғејҸзҡ„дәӢзү©еӨ„зҗҶе…·жңүйқһеёёеӨ§зҡ„жҢ‘жҲҳгҖӮ
еҲҶеёғејҸдәӢзү©жҳҜжҢҮдәӢзү©зҡ„еҸӮдёҺиҖ…гҖҒж”ҜжҢҒдәӢзү©зҡ„жңҚеҠЎеҷЁгҖҒиө„жәҗжңҚеҠЎеҷЁд»ҘеҸҠдәӢзү©з®ЎзҗҶеҷЁеҲҶеҲ«дҪҚдәҺеҲҶеёғејҸзі»з»ҹзҡ„дёҚеҗҢиҠӮзӮ№дёҠпјҢйҖҡеёёдёҖдёӘеҲҶеёғејҸдәӢзү©дёӯдјҡж¶үеҸҠеҜ№еӨҡдёӘж•°жҚ®жәҗжҲ–дёҡеҠЎзі»з»ҹзҡ„ж“ҚдҪңгҖӮ
еҸҜд»Ҙи®ҫжғідёҖдёӘжңҖе…ёеһӢзҡ„еҲҶеёғејҸдәӢзү©еңәжҷҜпјҡдёҖдёӘ跨银иЎҢзҡ„иҪ¬иҙҰж“ҚдҪңж¶үеҸҠи°ғз”ЁдёӨдёӘејӮең°зҡ„银иЎҢжңҚеҠЎпјҢе…¶дёӯдёҖдёӘжҳҜжң¬ең°й“¶иЎҢжҸҗдҫӣзҡ„еҸ–ж¬ҫжңҚеҠЎпјҢеҸҰдёҖдёӘеҲҷжҳҜзӣ®ж Ү银иЎҢжҸҗдҫӣзҡ„еӯҳж¬ҫжңҚеҠЎпјҢиҝҷдёӨдёӘжңҚеҠЎжң¬иә«жҳҜж— зҠ¶жҖҒ并且зӣёдә’зӢ¬з«Ӣзҡ„пјҢе…ұеҗҢжһ„жҲҗдәҶдёҖдёӘе®Ңж•ҙзҡ„еҲҶеёғејҸдәӢзү©гҖӮ
еҰӮжһңд»Һжң¬ең°й“¶иЎҢеҸ–ж¬ҫжҲҗеҠҹпјҢдҪҶжҳҜеӣ дёәжҹҗз§ҚеҺҹеӣ еӯҳж¬ҫжңҚеҠЎеӨұиҙҘдәҶпјҢйӮЈд№Ҳе°ұеҝ…йЎ»еӣһж»ҡеҲ°еҸ–ж¬ҫд№ӢеүҚзҡ„зҠ¶жҖҒпјҢеҗҰеҲҷз”ЁжҲ·еҸҜиғҪдјҡеҸ‘зҺ°иҮӘе·ұзҡ„й’ұдёҚзҝјиҖҢйЈһдәҶгҖӮ
д»ҺиҝҷдёӘдҫӢеӯҗеҸҜд»ҘзңӢеҲ°пјҢдёҖдёӘеҲҶеёғејҸдәӢеҠЎеҸҜд»ҘзңӢеҒҡжҳҜеӨҡдёӘеҲҶеёғејҸзҡ„ж“ҚдҪңеәҸеҲ—з»„жҲҗзҡ„пјҢдҫӢеҰӮдёҠйқўдҫӢеӯҗзҡ„еҸ–ж¬ҫжңҚеҠЎе’Ңеӯҳж¬ҫжңҚеҠЎпјҢйҖҡеёёеҸҜд»ҘжҠҠиҝҷдёҖзі»еҲ—еҲҶеёғејҸзҡ„ж“ҚдҪңеәҸеҲ—з§°дёәеӯҗдәӢзү©гҖӮ
еӣ жӯӨпјҢеҲҶеёғејҸдәӢеҠЎд№ҹеҸҜд»Ҙиў«е®ҡд№үдёәдёҖз§ҚеөҢеҘ—еһӢзҡ„дәӢзү©пјҢеҗҢж—¶д№ҹе°ұе…·жңүдәҶACIDдәӢзү©зү№жҖ§гҖӮдҪҶз”ұдәҺеңЁеҲҶеёғејҸдәӢеҠЎдёӯпјҢеҗ„дёӘеӯҗдәӢзү©зҡ„жү§иЎҢжҳҜеҲҶеёғејҸзҡ„пјҢеӣ жӯӨиҰҒе®һзҺ°дёҖз§ҚиғҪеӨҹдҝқиҜҒACIDзү№жҖ§зҡ„еҲҶеёғејҸдәӢзү©еӨ„зҗҶзі»з»ҹе°ұжҳҫеҫ—ж јеӨ–еӨҚжқӮгҖӮ
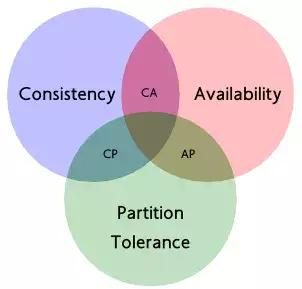
CAPзҗҶи®ә
дёҖдёӘз»Ҹе…ёзҡ„еҲҶеёғејҸзі»з»ҹзҗҶи®әгҖӮCAPзҗҶи®әе‘ҠиҜүжҲ‘们пјҡдёҖдёӘеҲҶеёғејҸзі»з»ҹдёҚеҸҜиғҪеҗҢж—¶ж»Ўи¶ідёҖиҮҙжҖ§пјҲCпјҡConsistencyпјүгҖҒеҸҜз”ЁжҖ§пјҲAпјҡAvailabilityпјүе’ҢеҲҶеҢәе®№й”ҷжҖ§пјҲPпјҡPartition toleranceпјүиҝҷдёүдёӘеҹәжң¬йңҖжұӮпјҢжңҖеӨҡеҸӘиғҪеҗҢж—¶ж»Ўи¶іе…¶дёӯдёӨйЎ№гҖӮ
1гҖҒдёҖиҮҙжҖ§
еңЁеҲҶеёғејҸзҺҜеўғдёӢпјҢдёҖиҮҙжҖ§жҳҜжҢҮж•°жҚ®еңЁеӨҡдёӘеүҜжң¬д№Ӣй—ҙиғҪеҗҰдҝқжҢҒдёҖиҮҙзҡ„зү№жҖ§гҖӮеңЁдёҖиҮҙжҖ§зҡ„йңҖжұӮдёӢпјҢеҪ“дёҖдёӘзі»з»ҹеңЁж•°жҚ®дёҖиҮҙзҡ„зҠ¶жҖҒдёӢжү§иЎҢжӣҙж–°ж“ҚдҪңеҗҺпјҢеә”иҜҘдҝқиҜҒзі»з»ҹзҡ„ж•°жҚ®д»Қ然еӨ„дәҺдёҖзӣҙзҡ„зҠ¶жҖҒгҖӮ
еҜ№дәҺдёҖдёӘе°Ҷж•°жҚ®еүҜжң¬еҲҶеёғеңЁдёҚеҗҢеҲҶеёғејҸиҠӮзӮ№дёҠзҡ„зі»з»ҹжқҘиҜҙпјҢеҰӮжһңеҜ№з¬¬дёҖдёӘиҠӮзӮ№зҡ„ж•°жҚ®иҝӣиЎҢдәҶжӣҙж–°ж“ҚдҪң并且жӣҙж–°жҲҗеҠҹеҗҺпјҢеҚҙжІЎжңүдҪҝеҫ—第дәҢдёӘиҠӮзӮ№дёҠзҡ„ж•°жҚ®еҫ—еҲ°зӣёеә”зҡ„жӣҙж–°пјҢдәҺжҳҜеңЁеҜ№з¬¬дәҢдёӘиҠӮзӮ№зҡ„ж•°жҚ®иҝӣиЎҢиҜ»еҸ–ж“ҚдҪңж—¶пјҢиҺ·еҸ–зҡ„дҫқ然жҳҜиҖҒж•°жҚ®пјҲжҲ–з§°дёәи„Ҹж•°жҚ®пјүпјҢиҝҷе°ұжҳҜе…ёеһӢзҡ„еҲҶеёғејҸж•°жҚ®дёҚдёҖиҮҙзҡ„жғ…еҶөгҖӮ
еңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢеҰӮжһңиғҪеӨҹеҒҡеҲ°й’ҲеҜ№дёҖдёӘж•°жҚ®йЎ№зҡ„жӣҙж–°ж“ҚдҪңжү§иЎҢжҲҗеҠҹеҗҺпјҢжүҖжңүзҡ„з”ЁжҲ·йғҪеҸҜд»ҘиҜ»еҸ–еҲ°е…¶жңҖж–°зҡ„еҖјпјҢйӮЈд№Ҳиҝҷж ·зҡ„зі»з»ҹе°ұиў«и®Өдёәе…·жңүејәдёҖиҮҙжҖ§
2гҖҒеҸҜз”ЁжҖ§
еҸҜз”ЁжҖ§жҳҜжҢҮзі»з»ҹжҸҗдҫӣзҡ„жңҚеҠЎеҝ…йЎ»дёҖзӣҙеӨ„дәҺеҸҜз”Ёзҡ„зҠ¶жҖҒпјҢеҜ№дәҺз”ЁжҲ·зҡ„жҜҸдёҖдёӘж“ҚдҪңиҜ·жұӮжҖ»жҳҜиғҪеӨҹеңЁжңүйҷҗзҡ„ж—¶й—ҙеҶ…иҝ”еӣһз»“жһңгҖӮиҝҷйҮҢзҡ„йҮҚзӮ№жҳҜ"жңүйҷҗж—¶й—ҙеҶ…"е’Ң"иҝ”еӣһз»“жһң"гҖӮ
"жңүйҷҗж—¶й—ҙеҶ…"жҳҜжҢҮпјҢеҜ№дәҺз”ЁжҲ·зҡ„дёҖдёӘж“ҚдҪңиҜ·жұӮпјҢзі»з»ҹеҝ…йЎ»иғҪеӨҹеңЁжҢҮе®ҡзҡ„ж—¶й—ҙеҶ…иҝ”еӣһеҜ№еә”зҡ„еӨ„зҗҶз»“жһңпјҢеҰӮжһңи¶…иҝҮдәҶиҝҷдёӘж—¶й—ҙиҢғеӣҙпјҢйӮЈд№Ҳзі»з»ҹе°ұиў«и®ӨдёәжҳҜдёҚеҸҜз”Ёзҡ„гҖӮ
еҸҰеӨ–пјҢ"жңүйҷҗзҡ„ж—¶й—ҙеҶ…"жҳҜжҢҮзі»з»ҹи®ҫи®Ўд№ӢеҲқе°ұи®ҫи®ЎеҘҪзҡ„иҝҗиЎҢжҢҮж ҮпјҢйҖҡеёёдёҚеҗҢзі»з»ҹд№Ӣй—ҙжңүеҫҲеӨ§зҡ„дёҚеҗҢпјҢж— и®әеҰӮдҪ•пјҢеҜ№дәҺз”ЁжҲ·иҜ·жұӮпјҢзі»з»ҹеҝ…йЎ»еӯҳеңЁдёҖдёӘеҗҲзҗҶзҡ„е“Қеә”ж—¶й—ҙпјҢеҗҰеҲҷз”ЁжҲ·дҫҝдјҡеҜ№зі»з»ҹж„ҹеҲ°еӨұжңӣгҖӮ
"иҝ”еӣһз»“жһң"жҳҜеҸҜз”ЁжҖ§зҡ„еҸҰдёҖдёӘйқһеёёйҮҚиҰҒзҡ„жҢҮж ҮпјҢе®ғиҰҒжұӮзі»з»ҹеңЁе®ҢжҲҗеҜ№з”ЁжҲ·иҜ·жұӮзҡ„еӨ„зҗҶеҗҺпјҢиҝ”еӣһдёҖдёӘжӯЈеёёзҡ„е“Қеә”з»“жһңгҖӮжӯЈеёёзҡ„е“Қеә”з»“жһңйҖҡеёёиғҪеӨҹжҳҺзЎ®ең°еҸҚжҳ еҮәйҳҹиҜ·жұӮзҡ„еӨ„зҗҶз»“жһңпјҢеҚіжҲҗеҠҹжҲ–еӨұиҙҘпјҢиҖҢдёҚжҳҜдёҖдёӘи®©з”ЁжҲ·ж„ҹеҲ°еӣ°жғ‘зҡ„иҝ”еӣһз»“жһңгҖӮ
3гҖҒеҲҶеҢәе®№й”ҷжҖ§
еҲҶеҢәе®№й”ҷжҖ§зәҰжқҹдәҶдёҖдёӘеҲҶеёғејҸзі»з»ҹе…·жңүеҰӮдёӢзү№жҖ§пјҡеҲҶеёғејҸзі»з»ҹеңЁйҒҮеҲ°д»»дҪ•зҪ‘з»ңеҲҶеҢәж•…йҡңзҡ„ж—¶еҖҷпјҢд»Қ然йңҖиҰҒиғҪеӨҹдҝқиҜҒеҜ№еӨ–жҸҗдҫӣж»Ўи¶ідёҖиҮҙжҖ§е’ҢеҸҜз”ЁжҖ§зҡ„жңҚеҠЎпјҢйҷӨйқһжҳҜж•ҙдёӘзҪ‘з»ңзҺҜеўғйғҪеҸ‘з”ҹдәҶж•…йҡңгҖӮ
зҪ‘з»ңеҲҶеҢәжҳҜжҢҮеңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢдёҚеҗҢзҡ„иҠӮзӮ№еҲҶеёғеңЁдёҚеҗҢзҡ„еӯҗзҪ‘з»ңпјҲжңәжҲҝжҲ–ејӮең°зҪ‘з»ңпјүдёӯпјҢз”ұдәҺдёҖдәӣзү№ж®Ҡзҡ„еҺҹеӣ еҜјиҮҙиҝҷдәӣеӯҗзҪ‘з»ңеҮәзҺ°зҪ‘з»ңдёҚиҝһйҖҡзҡ„зҠ¶еҶөпјҢдҪҶеҗ„дёӘеӯҗзҪ‘з»ңзҡ„еҶ…йғЁзҪ‘з»ңжҳҜжӯЈеёёзҡ„пјҢд»ҺиҖҢеҜјиҮҙж•ҙдёӘзі»з»ҹзҡ„зҪ‘з»ңзҺҜеўғиў«еҲҮеҲҶжҲҗдәҶиӢҘе№ІдёӘеӯӨз«Ӣзҡ„еҢәеҹҹгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢз»„жҲҗдёҖдёӘеҲҶеёғејҸзі»з»ҹзҡ„жҜҸдёӘиҠӮзӮ№зҡ„еҠ е…ҘдёҺйҖҖеҮәйғҪеҸҜд»ҘзңӢдҪңжҳҜдёҖдёӘзү№ж®Ҡзҡ„зҪ‘з»ңеҲҶеҢәгҖӮ
既然дёҖдёӘеҲҶеёғејҸзі»з»ҹж— жі•еҗҢж—¶ж»Ўи¶ідёҖиҮҙжҖ§гҖҒеҸҜз”ЁжҖ§гҖҒеҲҶеҢәе®№й”ҷжҖ§дёүдёӘзү№зӮ№пјҢжүҖд»ҘжҲ‘们е°ұйңҖиҰҒжҠӣејғдёҖж ·пјҡ
з”ЁдёҖеј иЎЁж јиҜҙжҳҺдёҖдёӢпјҡ

йңҖиҰҒжҳҺзЎ®зҡ„дёҖзӮ№жҳҜпјҢеҜ№дәҺдёҖдёӘеҲҶеёғејҸзі»з»ҹиҖҢиЁҖпјҢеҲҶеҢәе®№й”ҷжҖ§жҳҜдёҖдёӘжңҖеҹәжң¬зҡ„иҰҒжұӮгҖӮеӣ дёә既然жҳҜдёҖдёӘеҲҶеёғејҸзі»з»ҹпјҢйӮЈд№ҲеҲҶеёғејҸзі»з»ҹдёӯзҡ„组件еҝ…然йңҖиҰҒиў«йғЁзҪІеҲ°дёҚеҗҢзҡ„иҠӮзӮ№пјҢеҗҰеҲҷд№ҹе°ұж— жүҖи°“еҲҶеёғејҸзі»з»ҹдәҶпјҢеӣ жӯӨеҝ…然еҮәзҺ°еӯҗзҪ‘з»ңгҖӮ
иҖҢеҜ№дәҺеҲҶеёғејҸзі»з»ҹиҖҢиЁҖпјҢзҪ‘з»ңй—®йўҳеҸҲжҳҜдёҖдёӘеҝ…е®ҡдјҡеҮәзҺ°зҡ„ејӮеёёжғ…еҶөпјҢеӣ жӯӨеҲҶеҢәе®№й”ҷжҖ§д№ҹе°ұжҲҗдёәдәҶдёҖдёӘеҲҶеёғејҸзі»з»ҹеҝ…然йңҖиҰҒйқўеҜ№е’Ңи§ЈеҶізҡ„й—®йўҳгҖӮеӣ жӯӨзі»з»ҹжһ¶жһ„еёҲеҫҖеҫҖйңҖиҰҒжҠҠзІҫеҠӣиҠұеңЁеҰӮдҪ•ж №жҚ®дёҡеҠЎзү№зӮ№еңЁCпјҲдёҖиҮҙжҖ§пјүе’ҢAпјҲеҸҜз”ЁжҖ§пјүд№Ӣй—ҙеҜ»жұӮе№іиЎЎгҖӮ
BASEзҗҶи®ә
BASEжҳҜBasically AvailableпјҲеҹәжң¬еҸҜз”ЁпјүгҖҒSoft stateпјҲиҪҜзҠ¶жҖҒпјүе’ҢEventually consistentпјҲжңҖз»ҲдёҖиҮҙжҖ§пјүдёүдёӘзҹӯиҜӯзҡ„зј©еҶҷгҖӮBASEзҗҶи®әжҳҜеҜ№CAPдёӯдёҖиҮҙжҖ§е’ҢеҸҜз”ЁжҖ§жқғиЎЎзҡ„з»“жһңпјҢе…¶жқҘжәҗдәҺеҜ№еӨ§и§„жЁЎдә’иҒ”зҪ‘зі»з»ҹеҲҶеёғејҸе®һи·өзҡ„жҖ»з»“пјҢжҳҜеҹәдәҺCAPе®ҡзҗҶйҖҗжӯҘжј”еҢ–иҖҢжқҘзҡ„гҖӮ
BASEзҗҶи®әзҡ„ж ёеҝғжҖқжғіжҳҜпјҡеҚідҪҝж— жі•еҒҡеҲ°ејәдёҖиҮҙжҖ§пјҢдҪҶжҜҸдёӘеә”з”ЁйғҪеҸҜд»Ҙж №жҚ®иҮӘиә«дёҡеҠЎзү№зӮ№пјҢйҮҮз”ЁйҖӮеҪ“зҡ„ж–№ејҸжқҘдҪҝзі»з»ҹиҫҫеҲ°жңҖз»ҲдёҖиҮҙжҖ§гҖӮжҺҘдёӢжқҘзңӢдёҖдёӢBASEдёӯзҡ„дёүиҰҒзҙ пјҡ
1гҖҒеҹәжң¬еҸҜз”Ё
еҹәжң¬еҸҜз”ЁжҳҜжҢҮеҲҶеёғејҸзі»з»ҹеңЁеҮәзҺ°дёҚеҸҜйў„зҹҘж•…йҡңзҡ„ж—¶еҖҷпјҢе…Ғи®ёжҚҹеӨұйғЁеҲҶеҸҜз”ЁжҖ§----жіЁж„ҸпјҢиҝҷз»қдёҚзӯүд»·дәҺзі»з»ҹдёҚеҸҜз”ЁгҖӮжҜ”еҰӮпјҡ
пјҲ1пјүе“Қеә”ж—¶й—ҙдёҠзҡ„жҚҹеӨұгҖӮжӯЈеёёжғ…еҶөдёӢпјҢдёҖдёӘеңЁзәҝжҗңзҙўеј•ж“ҺйңҖиҰҒеңЁ0.5з§’д№ӢеҶ…иҝ”еӣһз»ҷз”ЁжҲ·зӣёеә”зҡ„жҹҘиҜўз»“жһңпјҢдҪҶз”ұдәҺеҮәзҺ°ж•…йҡңпјҢжҹҘиҜўз»“жһңзҡ„е“Қеә”ж—¶й—ҙеўһеҠ дәҶ1~2з§’
пјҲ2пјүзі»з»ҹеҠҹиғҪдёҠзҡ„жҚҹеӨұпјҡжӯЈеёёжғ…еҶөдёӢпјҢеңЁдёҖдёӘз”өеӯҗе•ҶеҠЎзҪ‘з«ҷдёҠиҝӣиЎҢиҙӯзү©зҡ„ж—¶еҖҷпјҢж¶Ҳиҙ№иҖ…еҮ д№ҺиғҪеӨҹйЎәеҲ©е®ҢжҲҗжҜҸдёҖ笔订еҚ•пјҢдҪҶжҳҜеңЁдёҖдәӣиҠӮж—ҘеӨ§дҝғиҙӯзү©й«ҳеі°зҡ„ж—¶еҖҷпјҢз”ұдәҺж¶Ҳиҙ№иҖ…зҡ„иҙӯзү©иЎҢдёәжҝҖеўһпјҢдёәдәҶдҝқжҠӨиҙӯзү©зі»з»ҹзҡ„зЁіе®ҡжҖ§пјҢйғЁеҲҶж¶Ҳиҙ№иҖ…еҸҜиғҪдјҡиў«еј•еҜјеҲ°дёҖдёӘйҷҚзә§йЎөйқў
2гҖҒиҪҜзҠ¶жҖҒ
иҪҜзҠ¶жҖҒжҢҮе…Ғи®ёзі»з»ҹдёӯзҡ„ж•°жҚ®еӯҳеңЁдёӯй—ҙзҠ¶жҖҒпјҢ并и®ӨдёәиҜҘдёӯй—ҙзҠ¶жҖҒзҡ„еӯҳеңЁдёҚдјҡеҪұе“Қзі»з»ҹзҡ„ж•ҙдҪ“еҸҜз”ЁжҖ§пјҢеҚіе…Ғи®ёзі»з»ҹеңЁдёҚеҗҢиҠӮзӮ№зҡ„ж•°жҚ®еүҜжң¬д№Ӣй—ҙиҝӣиЎҢж•°жҚ®еҗҢжӯҘзҡ„иҝҮзЁӢеӯҳеңЁе»¶ж—¶
3гҖҒжңҖз»ҲдёҖиҮҙжҖ§
жңҖз»ҲдёҖиҮҙжҖ§ејәи°ғзҡ„жҳҜжүҖжңүзҡ„ж•°жҚ®еүҜжң¬пјҢеңЁз»ҸиҝҮдёҖж®өж—¶й—ҙзҡ„еҗҢжӯҘд№ӢеҗҺпјҢжңҖз»ҲйғҪиғҪеӨҹиҫҫеҲ°дёҖдёӘдёҖиҮҙзҡ„зҠ¶жҖҒгҖӮеӣ жӯӨпјҢжңҖз»ҲдёҖиҮҙжҖ§зҡ„жң¬иҙЁжҳҜйңҖиҰҒзі»з»ҹдҝқиҜҒжңҖз»Ҳж•°жҚ®иғҪеӨҹиҫҫеҲ°дёҖиҮҙпјҢиҖҢдёҚйңҖиҰҒе®һж—¶дҝқиҜҒзі»з»ҹж•°жҚ®зҡ„ејәдёҖиҮҙжҖ§гҖӮ
жҖ»зҡ„жқҘиҜҙпјҢBASEзҗҶи®әйқўеҗ‘зҡ„жҳҜеӨ§еһӢй«ҳеҸҜз”ЁеҸҜжү©еұ•зҡ„еҲҶеёғејҸзі»з»ҹпјҢе’Ңдј з»ҹзҡ„дәӢзү©ACIDзү№жҖ§жҳҜзӣёеҸҚзҡ„пјҢе®ғе®Ңе…ЁдёҚеҗҢдәҺACIDзҡ„ејәдёҖиҮҙжҖ§жЁЎеһӢпјҢиҖҢжҳҜйҖҡиҝҮзүәзүІејәдёҖиҮҙжҖ§жқҘиҺ·еҫ—еҸҜз”ЁжҖ§пјҢ并е…Ғи®ёж•°жҚ®еңЁдёҖж®өж—¶й—ҙеҶ…жҳҜдёҚдёҖиҮҙзҡ„пјҢдҪҶжңҖз»ҲиҫҫеҲ°дёҖиҮҙзҠ¶жҖҒгҖӮ
дҪҶеҗҢж—¶пјҢеңЁе®һйҷ…зҡ„еҲҶеёғејҸеңәжҷҜдёӯпјҢдёҚеҗҢдёҡеҠЎеҚ•е…ғе’Ң组件еҜ№ж•°жҚ®дёҖиҮҙжҖ§зҡ„иҰҒжұӮжҳҜдёҚеҗҢзҡ„пјҢеӣ жӯӨеңЁе…·дҪ“зҡ„еҲҶеёғејҸзі»з»ҹжһ¶жһ„и®ҫи®ЎиҝҮзЁӢдёӯпјҢACIDзү№жҖ§е’ҢBASEзҗҶи®әеҫҖеҫҖеҸҲдјҡз»“еҗҲеңЁдёҖиө·гҖӮ
жңҖеҗҺ
ж¬ўиҝҺеӨ§е®¶дёҖиө·дәӨжөҒпјҢе–ңж¬ўж–Үз« и®°еҫ—зӮ№дёӘиөһе“ҹпјҢж„ҹи°ўж”ҜжҢҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ