жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ

HashMapжҳҜJavaејҖеҸ‘еҪ“дёӯдҪҝз”Ёеҫ—йқһеёёеӨҡзҡ„дёҖз§Қж•°жҚ®з»“жһ„пјҢеӣ дёәе…¶еҸҜд»Ҙеҝ«йҖҹзҡ„е®ҡдҪҚеҲ°йңҖиҰҒжҹҘжүҫеҲ°ж•°жҚ®пјҢе…¶жңҖеҝ«зҡ„йҖҹеәҰеҸҜд»ҘиҫҫеҲ°O(1)пјҢжңҖе·®зҡ„ж—¶еҖҷд№ҹеҸҜд»ҘиҫҫеҲ°O(n)гҖӮжң¬ж–Үд»ҘJava8дёӯзҡ„HashMapеҒҡдёәеҲҶжһҗеҺҹеһӢпјҢеӣ дёәдёҚеҗҢзҡ„JDKзүҲжң¬дёӯзҡ„HashMapпјҢеҸҜиғҪеӯҳеңЁзқҖеә•еұӮе®һзҺ°дёҠзҡ„дёҚдёҖж ·гҖӮ
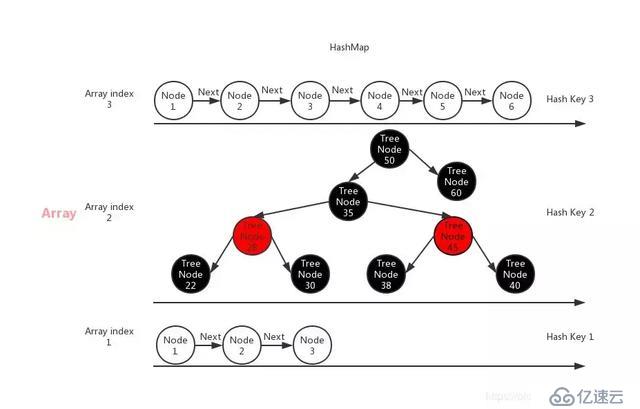
HashMapжҳҜйҖҡиҝҮж•°з»„еӯҳеӮЁжүҖжңүзҡ„ж•°жҚ®пјҢжҜҸдёӘе…ғзҙ жүҖеӯҳж”ҫж•°з»„зҡ„дёӢж ҮпјҢжҳҜж №жҚ®иҜҘеӯҳеӮЁе…ғзҙ зҡ„keyзҡ„HashеҖјдёҺиҜҘж•°з»„зҡ„й•ҝеәҰеҮҸеҺ»1еҒҡдёҺиҝҗз®—пјҢеҰӮдёӢжүҖзӨәпјҡ
indexВ =В (length_of_arrayВ -В 1)В &В hash_of_the_key;
ж•°з»„дёӯеӯҳж”ҫе…ғзҙ зҡ„ж•°жҚ®з»“жһ„дҪҝз”ЁдәҶNodeе’ҢTreeNodeдёӨз§Қж•°жҚ®з»“жһ„пјҢеңЁеҚ•дёӘHashеҖјеҜ№еә”зҡ„еӯҳеӮЁе…ғзҙ е°ҸдәҺ8дёӘж—¶пјҢй»ҳи®ӨеҖјдёәNodeзҡ„еҚ•еҗ‘й“ҫиЎЁеҪўејҸеӯҳеӮЁпјҢеҪ“еҚ•дёӘHashеҖјеӯҳеӮЁзҡ„е…ғзҙ еӨ§дәҺ8дёӘж—¶пјҢе…¶дјҡдҪҝз”ЁTreeNodeзҡ„ж•°жҚ®з»“жһ„еӯҳеӮЁгҖӮ
еӣ дёәеңЁеҚ•дёӘHashеҖјеҜ№еә”зҡ„е…ғзҙ е°ҸдәҺзӯүдәҺ8дёӘж—¶пјҢе…¶жҹҘиҜўж—¶й—ҙжңҖе·®дёәO(8)пјҢдҪҶжҳҜеҪ“еҚ•дёӘHashеҖјеҜ№еә”зҡ„е…ғзҙ еӨ§дәҺ8дёӘж—¶пјҢеҶҚйҖҡиҝҮNodeзҡ„еҚ•еҗ‘й“ҫиЎЁзҡ„ж–№ејҸиҝӣиЎҢжҹҘиҜўпјҢйҖҹеәҰдёҠе°ұдјҡеҸҳеҫ—жӣҙж…ўдәҶпјӣиҝҷдёӘж—¶еҖҷHashMapе°ұдјҡе°ҶNodeзҡ„жҷ®йҖҡиҠӮзӮ№иҪ¬дёәTreeNodeпјҲзәўй»‘ж ‘пјүиҝӣиЎҢеӯҳеӮЁпјҢиҝҷжҳҜз”ұдәҺTreeNodeеҚ з”Ёзҡ„з©әй—ҙеӨ§е°ҸзәҰдёә常规иҠӮзӮ№зҡ„дёӨеҖҚпјҢдҪҶжҳҜе…¶жҹҘиҜўйҖҹеәҰеҸҜд»Ҙеҫ—еҲ°дҝқиҜҒпјҢиҝҷдёӘжҳҜйҖҡиҝҮз©әй—ҙжҚўж—¶й—ҙдәҶгҖӮеҪ“TreeNodeдёӯеҢ…жӢ¬зҡ„е…ғзҙ еҸҳеҫ—жҜ”иҫғе°‘ж—¶пјҢдёәдәҶеӯҳеӮЁз©әй—ҙзҡ„еҚ з”ЁпјҢд№ҹдјҡиҪ¬жҚўдёәNodeиҠӮзӮ№еҚ•еҗ‘й“ҫиЎЁзҡ„ж–№ејҸе®һзҺ°пјҢе®ғ们д№Ӣй—ҙеҸҜд»Ҙдә’зӣёиҪ¬жҚўзҡ„гҖӮ
Nodeпјҡ
staticВ classВ Node<K,V>В implementsВ Map.Entry<K,V>В {
В finalВ intВ hash;
В finalВ KВ key;
В VВ value;В Node<K,V>В next;В Node(intВ hash,В KВ key,В VВ value,В Node<K,V>В next)В {
В this.hashВ =В hash;
В this.keyВ =В key;
В this.valueВ =В value;
В this.nextВ =В next;
В }
В ......
}еҸҜд»ҘзңӢеҲ°жҜҸдёӘNodeдёӯеҢ…жӢ¬дәҶ4дёӘеұһжҖ§пјҢеҲҶеҲ«дёәпјҡ
hashеҖјпјҡеҪ“еүҚNodeзҡ„HashеҖј keyпјҡеҪ“еүҚNodeзҡ„keyvalue:еҪ“еүҚNodeзҡ„valuenext:иЎЁзӨәжҢҮеҗ‘дёӢдёҖдёӘNodeзҡ„жҢҮй’ҲпјҢзӣёеҗҢhashеҖјзҡ„NodeпјҢйҖҡиҝҮnextиҝӣиЎҢйҒҚеҺҶжҹҘжүҫ
TreeNodeпјҡ
staticВ finalВ classВ TreeNode<K,V>В extendsВ LinkedHashMap.Entry<K,V>В {В TreeNode<K,V>В parent;В //В red-blackВ treeВ links
В TreeNode<K,V>В left;В TreeNode<K,V>В right;В TreeNode<K,V>В prev;В //В neededВ toВ unlinkВ nextВ uponВ deletion
В booleanВ red;В TreeNode(intВ hash,В KВ key,В VВ val,В Node<K,V>В next)В {В super(hash,В key,В val,В next);
В }
В ......
}еҸҜд»ҘзңӢеҲ°TreeNodeдҪҝз”Ёзҡ„жҳҜзәўй»‘ж ‘пјҲRed Black Treeпјүзҡ„ж•°жҚ®з»“жһ„пјҢзәўй»‘ж ‘жҳҜдёҖз§ҚиҮӘе№іиЎЎдәҢеҸүжҹҘжүҫж ‘пјҢеңЁиҝӣиЎҢжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңж—¶йҖҡиҝҮзү№е®ҡж“ҚдҪңдҝқжҢҒдәҢеҸүжҹҘжүҫж ‘зҡ„е№іиЎЎпјҢд»ҺиҖҢиҺ·еҫ—иҫғй«ҳзҡ„жҹҘжүҫжҖ§иғҪпјҢеҚідҪҝеңЁжңҖеқҸжғ…еҶөиҝҗиЎҢж—¶й—ҙд№ҹжҳҜйқһеёёиүҜеҘҪзҡ„пјҢ并且еңЁе®һи·өдёӯжҳҜйқһеёёй«ҳж•Ҳзҡ„пјҢе®ғеҸҜд»ҘеңЁO(log n)ж—¶й—ҙеҶ…еҒҡжҹҘжүҫгҖҒжҸ’е…Ҙе’ҢеҲ йҷӨзӯүж“ҚдҪңпјҢиҝҷйҮҢзҡ„n жҳҜж ‘дёӯе…ғзҙ зҡ„ж•°зӣ®гҖӮ
д»ҘдёӢжҳҜдёҖеј е…ідәҺHashMapеӯҳеӮЁз»“жһ„зҡ„зӨәж„Ҹеӣҫпјҡ
еҶҷе…Ҙж•°жҚ®пјҲдёҖеҲҮзҡҶеңЁжіЁйҮҠдёӯпјү
е…¶ж–№жі•еҰӮдёӢпјҡ
//еҶҷе…Ҙж•°жҚ®publicВ VВ put(KВ key,В VВ value)В {В //йҰ–е…Ҳж №жҚ®hashж–№жі•пјҢиҺ·еҸ–еҜ№еә”keyзҡ„hashеҖјпјҢи®Ўз®—ж–№жі•и§ҒеҗҺйқў
В returnВ putVal(hash(key),В key,В value,В false,В true);
}finalВ VВ putVal(intВ hash,В KВ key,В VВ value,В booleanВ onlyIfAbsent,booleanВ evict)В {
В Node<K,V>[]В tab;В Node<K,V>В p;В intВ n,В i;В //еҲӨж–ӯз”ЁжҲ·еӯҳж”ҫе…ғзҙ зҡ„ж•°з»„жҳҜеҗҰдёәз©ә
В ifВ ((tabВ =В table)В ==В nullВ ||В (nВ =В tab.length)В ==В 0)В //дёәз©әеҲҷиҝӣиЎҢеҲқдҪҝеҢ–пјҢ并е°ҶеҲқдҪҝеҢ–еҗҺзҡ„ж•°з»„иөӢеҖјз»ҷеҸҳйҮҸtabпјҢж•°з»„зҡ„й•ҝеҖјиөӢеҖјз»ҷеҸҳйҮҸn
В nВ =В (tabВ =В resize()).length;В //еҲӨж–ӯж №жҚ®hashеҖјдёҺж•°з»„й•ҝеәҰеҮҸ1жұӮдёҺеҫ—еҲ°зҡ„дёӢж ҮпјҢ
В //д»Һж•°з»„дёӯиҺ·еҸ–е…ғзҙ 并е°Ҷе…¶иөӢеҖјз»ҷеҸҳйҮҸp(еҗҺз»ӯиҜҘеҸҳйҮҸpеҸҜд»Ҙ继з»ӯдҪҝз”Ё)пјҢ并еҲӨж–ӯиҜҘе…ғзҙ жҳҜеҗҰеӯҳеңЁ
В ifВ ((pВ =В tab[iВ =В (nВ -В 1)В &В hash])В ==В null)В //еҰӮжһңдёҚеӯҳеңЁеҲҷеҲӣе»әдёҖдёӘж–°зҡ„иҠӮзӮ№пјҢ并е°Ҷе…¶ж”ҫеҲ°ж•°з»„еҜ№еә”зҡ„дёӢж Үдёӯ
В tab[i]В =В newNode(hash,В key,В value,В null);В elseВ {//ж №жҚ®ж•°з»„зҡ„дёӢж ҮеҸ–еҲ°дәҶе…ғзҙ пјҢ并且иҜҘе…ғзҙ pдё”дёҚдёәз©әпјҢдёӢйқўиҰҒеҲӨж–ӯpе…ғзҙ зҡ„зұ»еһӢжҳҜNodeиҝҳжҳҜTreeNode
В Node<K,V>В e;В KВ k;В //еҲӨж–ӯиҜҘж•°з»„еҜ№еә”дёӢж ҮеҸ–еҲ°зҡ„第дёҖеҖјжҳҜдёҚжҳҜдёҺжӯЈеңЁеӯҳе…ҘеҖјзҡ„hashеҖјзӣёеҗҢгҖҒ
В //keyзӣёзӯүпјҲеҸҜиғҪжҳҜеҜ№иұЎпјҢд№ҹеҸҜиғҪжҳҜеӯ—з¬ҰдёІпјүпјҢеҰӮжһңзӣёзӯүпјҢеҲҷе°ҶеҸ–第дёҖдёӘеҖјиөӢеҖјз»ҷеҸҳйҮҸe
В ifВ (p.hashВ ==В hashВ &&
В ((kВ =В p.key)В ==В keyВ ||В (keyВ !=В nullВ &&В key.equals(k))))
В eВ =В p;В //еҲӨж–ӯеҸ–зҡ„еҜ№иұЎжҳҜдёҚжҳҜTreeNodeпјҢеҰӮжһңжҳҜеҲҷжү§иЎҢTreeNodeзҡ„putж–№жі•
В elseВ ifВ (pВ instanceofВ TreeNode)
В eВ =В ((TreeNode<K,V>)p).putTreeVal(this,В tab,В hash,В key,В value);В elseВ {//жҳҜжҷ®йҖҡзҡ„NodeиҠӮзӮ№пјҢ
В //ж №жҚ®nextеұһжҖ§еҜ№е…ғзҙ pжү§иЎҢеҚ•еҗ‘й“ҫиЎЁзҡ„йҒҚеҺҶ
В forВ (intВ binCountВ =В 0;В ;В ++binCount)В {В //еҰӮжһңиў«йҒҚеҺҶзҡ„е…ғзҙ жңҖеҗҺзҡ„nextдёәз©әпјҢиЎЁзӨәеҗҺйқўжІЎжңүиҠӮзӮ№дәҶпјҢеҲҷе°Ҷж–°иҠӮзӮ№дёҺеҪ“еүҚиҠӮзӮ№зҡ„nextеұһжҖ§е»әз«Ӣе…ізі»
В ifВ ((eВ =В p.next)В ==В null)В {В //еҒҡдёәеҪ“еүҚиҠӮзӮ№зҡ„еҗҺйқўзҡ„дёҖдёӘиҠӮзӮ№
В p.nextВ =В newNode(hash,В key,В value,В null);В //еҲӨж–ӯеҪ“еүҚиҠӮзӮ№зҡ„еҚ•еҗ‘й“ҫжҺҘзҡ„ж•°йҮҸпјҲ8дёӘпјүжҳҜдёҚжҳҜе·Із»ҸиҫҫеҲ°дәҶйңҖиҰҒе°Ҷе…¶иҪ¬жҚўдёәTreeNodeдәҶ
В ifВ (binCountВ >=В TREEIFY_THRESHOLDВ -В 1)В //В -1В forВ 1st
В //еҰӮжһңжҳҜеҲҷе°ҶеҪ“еүҚж•°з»„дёӢж ҮеҜ№еә”зҡ„е…ғзҙ иҪ¬жҚўдёәTreeNode
В treeifyBin(tab,В hash);В break;
В }В //еҲӨж–ӯеҫ…жҸ’е…Ҙзҡ„е…ғзҙ зҡ„hashеҖјдёҺkeyжҳҜеҗҰдёҺеҚ•еҗ‘й“ҫиЎЁдёӯзҡ„жҹҗдёӘе…ғзҙ зҡ„hashеҖјдёҺkeyжҳҜзӣёеҗҢзҡ„пјҢеҰӮжһңжҳҜеҲҷйҖҖеҮә
В ifВ (e.hashВ ==В hashВ &&
В ((kВ =В e.key)В ==В keyВ ||В (keyВ !=В nullВ &&В key.equals(k))))В break;
В pВ =В e;
В }
В }В //еҲӨж–ӯжҳҜеҗҰжүҫеҲ°дәҶдёҺеҫ…жҸ’е…Ҙе…ғзҙ зҡ„hashеҖјдёҺkeyеҖјйғҪзӣёеҗҢзҡ„е…ғзҙ
В ifВ (eВ !=В null)В {В //В existingВ mappingВ forВ key
В VВ oldValueВ =В e.value;В //еҲӨж–ӯжҳҜеҗҰиҰҒе°Ҷж—§еҖјжӣҝжҚўдёәж–°еҖј
В ifВ (!onlyIfAbsentВ ||В oldValueВ ==В null)В //ж»Ўи¶ідәҺжңӘжҢҮе®ҡдёҚжӣҝжҚўжҲ–ж—§еҖјдёәз©әзҡ„жғ…еҶөпјҢжү§иЎҢе°Ҷж—§еҖјжӣҝжҚўдёәж–°еҖј
В e.valueВ =В value;
В afterNodeAccess(e);В returnВ oldValue;
В }
В }
В ++modCount;В ifВ (++sizeВ >В threshold)
В resize();
В afterNodeInsertion(evict);В returnВ null;
}HashеҖјзҡ„и®Ўз®—ж–№жі•пјҡ
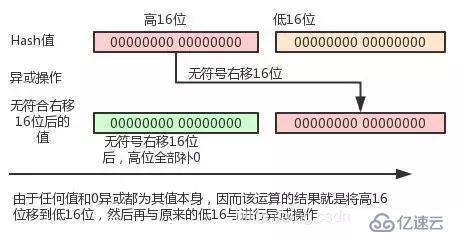
//В и®Ўз®—жҢҮе®ҡkeyзҡ„hashеҖјпјҢеҺҹзҗҶжҳҜе°Ҷkeyзҡ„hashВ codeдёҺhashВ codeж— з¬ҰеҸ·еҗ‘еҸіз§»16дҪҚзҡ„еҖјпјҢжү§иЎҢејӮжҲ–иҝҗз®—гҖӮ//В еңЁJavaдёӯж•ҙеһӢдёә4дёӘеӯ—иҠӮ32дҪҚпјҢж— з¬ҰеҸ·еҗ‘еҸіз§»16дҪҚпјҢиЎЁзӨәе°Ҷй«ҳ16дҪҚ移еҲ°дҪҺ16дҪҚдёҠпјҢ然еҗҺеҶҚжү§иЎҢејӮжҲ–иҝҗиЎҢпјҢд№ҹ//В е°ұжҳҜе°ҶhashВ codeзҡ„й«ҳ16дҪҚдёҺдҪҺ16дҪҚиҝӣиЎҢејӮжҲ–иҝҗиЎҢгҖӮ//В е°ҸдәҺзӯүдәҺ65535зҡ„ж•°пјҢе…¶й«ҳ16дҪҚе…ЁйғЁйғҪдёә0пјҢеӣ иҖҢе°Ҷе°ҸдәҺзӯүдәҺ65535зҡ„еҖјеҗ‘еҸіж— з¬ҰеҸ·з§»16дҪҚпјҢеҲҷиҜҘж•°е°ұеҸҳжҲҗдәҶ//В 32дҪҚйғҪжҳҜ0пјҢз”ұдәҺд»»дҪ•ж•°дёҺ0иҝӣиЎҢејӮжҲ–йғҪзӯүдәҺжң¬иә«пјҢеӣ иҖҢhashВ codeе°ҸдәҺзӯүдәҺ65535зҡ„keyпјҢе…¶еҫ—еҲ°зҡ„hashеҖј//В е°ұзӯүдәҺе…¶жң¬иә«зҡ„hashВ codeгҖӮstaticВ finalВ intВ hash(ObjectВ key)В {В intВ h;В returnВ (keyВ ==В null)В ?В 0В :В (hВ =В key.hashCode())В ^В (hВ >>>В 16);
}и®Ўз®—йҖ»иҫ‘еҰӮдёӢеӣҫжүҖзӨәпјҡ
иҜ»еҸ–ж•°жҚ®пјҲдёҖеҲҮзҡҶеңЁжіЁйҮҠдёӯпјү
В publicВ VВ get(ObjectВ key)В {
В Node<K,V>В e;В //ж №жҚ®KeyиҺ·еҸ–е…ғзҙ
В ifВ ((eВ =В getNode(hash(key),В key))В ==В null)В returnВ null;В ifВ (accessOrder)
В afterNodeAccess(e);В returnВ e.value;
В }В finalВ Node<K,V>В getNode(intВ hash,В ObjectВ key)В {
В Node<K,V>[]В tab;В Node<K,V>В first,В e;В intВ n;В KВ k;В //ifиҜӯеҸҘзҡ„第дёҖдёӘеҲӨж–ӯжқЎд»¶
В ifВ ((tabВ =В table)В !=В nullВ //е°Ҷж•°з»„иөӢеҖјз»ҷеҸҳйҮҸtabпјҢе°ҶеҲӨж–ӯжҳҜеҗҰдёәnull
В &&В (nВ =В tab.length)В >В 0В //е°Ҷж•°з»„зҡ„й•ҝеҖјиөӢеҖјз»ҷеҸҳйҮҸn
В &&В (firstВ =В tab[(nВ -В 1)В &В hash])В !=В null)В {//еҲӨж–ӯж №жҚ®hashе’Ңж•°з»„й•ҝеәҰеҮҸ1зҡ„дёҺиҝҗз®—пјҢи®Ўз®—еҮәжқҘзҡ„зҡ„ж•°з»„дёӢж Үзҡ„第дёҖдёӘе…ғзҙ жҳҜдёҚжҳҜдёәз©ә
В //еҲӨж–ӯ第дёҖдёӘе…ғзҙ жҳҜеҗҰиҰҒжүҫзҡ„е…ғзҙ пјҢеӨ§йғЁд»Ҫжғ…еҶөдёӢеҸӘиҰҒhashеҖјеӨӘйӣҶдёӯпјҢжҲ–иҖ…е…ғзҙ дёҚжҳҜеҫҲеӨҡпјҢ第дёҖдёӘе…ғзҙ еҫҖеҫҖйғҪжҳҜйңҖиҰҒзҡ„жңҖз»Ҳе…ғзҙ
В ifВ (first.hashВ ==В hashВ &&В //В alwaysВ checkВ firstВ node
В ((kВ =В first.key)В ==В keyВ ||В (keyВ !=В nullВ &&В key.equals(k))))В //第дёҖдёӘе…ғзҙ е°ұжҳҜиҰҒжүҫзҡ„е…ғзҙ пјҢеӣ дёәhashеҖје’ҢkeyйғҪзӣёзӯүпјҢзӣҙжҺҘиҝ”еӣһ
В returnВ first;В ifВ ((eВ =В first.next)В !=В null)В {//еҰӮжһң第дёҖе…ғзҙ дёҚжҳҜиҰҒжүҫеҲ°зҡ„е…ғпјҢеҲҷеҲӨж–ӯе…¶nextжҢҮеҗ‘жҳҜеҗҰиҝҳжңүе…ғзҙ
В //жңүе…ғзҙ пјҢеҲӨж–ӯе…¶жҳҜеҗҰжҳҜTreeNode
В ifВ (firstВ instanceofВ TreeNode)В //жҳҜTreeNodeеҲҷж №жҚ®TreeNodeзҡ„ж–№ејҸиҺ·еҸ–ж•°жҚ®
В returnВ ((TreeNode<K,V>)first).getTreeNode(hash,В key);
В doВ {//жҳҜNodeеҚ•еҗ‘й“ҫиЎЁпјҢеҲҷйҖҡиҝҮnextеҫӘзҺҜеҢ№й…ҚпјҢжүҫеҲ°е°ұйҖҖеҮәпјҢеҗҰеҲҷзӣҙеҲ°еҢ№й…Қе®ҢжңҖеҗҺдёҖдёӘе…ғзҙ жүҚйҖҖеҮә
В ifВ (e.hashВ ==В hashВ &&
В ((kВ =В e.key)В ==В keyВ ||В (keyВ !=В nullВ &&В key.equals(k))))В returnВ e;
В }В whileВ ((eВ =В e.next)В !=В null);
В }
В }В //жІЎжңүжүҫеҲ°еҲҷиҝ”еӣһnull
В returnВ null;
В }е–ңж¬ўиҝҷзҜҮж–Үз« зҡ„иҜқпјҢеҸҜд»Ҙз»ҷдҪңиҖ…зӮ№дёӘе–ңж¬ўпјҢзӮ№дёӢе…іжіЁпјҢжҜҸеӨ©йғҪдјҡеҲҶдә«Javaзӣёе…іж–Үз« пјҒ
и®°еҫ—дёҖе®ҡиҰҒе…іжіЁжҲ‘е“ҰпјҢдјҡдёҚе®ҡж—¶зҡ„зҰҸеҲ©иө йҖҒпјҢеҢ…жӢ¬ж•ҙзҗҶзҡ„йқўиҜ•йўҳпјҢеӯҰд№ иө„ж–ҷпјҢжәҗз Ғзӯү~~
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ