жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҲҶйЎөеә”иҜҘжҳҜжһҒдёәеёёи§Ғзҡ„ж•°жҚ®еұ•зҺ°ж–№ејҸдәҶпјҢдёҖиҲ¬еңЁж•°жҚ®йӣҶиҫғеӨ§иҖҢж— жі•еңЁеҚ•дёӘйЎөйқўдёӯе‘ҲзҺ°ж—¶дјҡйҮҮз”ЁеҲҶйЎөзҡ„ж–№жі•гҖӮ
еҗ„з§ҚеүҚз«ҜUI组件еңЁе®һзҺ°дёҠд№ҹйғҪдјҡж”ҜжҢҒеҲҶйЎөзҡ„еҠҹиғҪпјҢиҖҢж•°жҚ®дәӨдә’е‘ҲзҺ°жүҖзӣёеә”зҡ„еҗҺз«Ҝзі»з»ҹгҖҒж•°жҚ®еә“йғҪеҜ№ж•°жҚ®жҹҘиҜўзҡ„еҲҶйЎөжҸҗдҫӣдәҶиүҜеҘҪзҡ„ж”ҜжҢҒгҖӮ
д»ҘеҮ дёӘжөҒиЎҢзҡ„ж•°жҚ®еә“дёәдҫӢпјҡ
жҹҘиҜўиЎЁ t_data 第 2 йЎөзҡ„ж•°жҚ®(еҒҮе®ҡжҜҸйЎө 5 жқЎ)
MySQL зҡ„еҒҡжі•пјҡ
select * from t_data limit 5,5PostGreSQL зҡ„еҒҡжі•пјҡ
select * from t_data limit 5 offset 5db.t_data.find().limit(5).skip(5);е°Ҫз®ЎжҜҸз§Қж•°жҚ®еә“зҡ„иҜӯжі•дёҚе°ҪзӣёеҗҢпјҢйҖҡиҝҮдёҖдәӣејҖеҸ‘жЎҶжһ¶е°ҒиЈ…зҡ„жҺҘеҸЈпјҢжҲ‘们еҸҜд»ҘдёҚйңҖиҰҒзҶҹжӮүиҝҷдәӣе·®ејӮгҖӮеҰӮ SpringData жҸҗдҫӣзҡ„еҲҶйЎөжҺҘеҸЈпјҡ
public interface PagingAndSortingRepository<T, ID extends Serializable>
extends CrudRepository<T, ID> {
Page<T> findAll(Pageable pageable);
}иҝҷж ·зңӢжқҘпјҢејҖеҸ‘дёҖдёӘеҲҶйЎөзҡ„жҹҘиҜўеҠҹиғҪжҳҜйқһеёёз®ҖеҚ•зҡ„гҖӮ
然иҖҢдёҮдәӢзҡҶдёҚеҸҜиғҪе°Ҫе…Ёе°ҪзҫҺпјҢе°Ҫз®ЎдёҠиҝ°зҡ„ж•°жҚ®еә“гҖҒејҖеҸ‘жЎҶжһ¶жҸҗдҫӣдәҶеҹәзЎҖзҡ„еҲҶйЎөиғҪеҠӣпјҢеңЁйқўеҜ№ж—ҘзӣҠеўһй•ҝзҡ„жө·йҮҸж•°жҚ®ж—¶еҚҙйҡҫд»Ҙеә”еҜ№пјҢдёҖдёӘжҳҺжҳҫзҡ„й—®йўҳе°ұжҳҜжҹҘиҜўжҖ§иғҪдҪҺдёӢпјҒ
йӮЈд№ҲпјҢйқўеҜ№еҚғдёҮзә§гҖҒдәҝзә§з”ҡиҮіжӣҙеӨҡзҡ„ж•°жҚ®йӣҶж—¶пјҢеҲҶйЎөеҠҹиғҪиҜҘжҖҺд№Ҳе®һзҺ°пјҹ
дёӢйқўпјҢжҲ‘д»Ҙ MongoDB дҪңдёәиғҢжҷҜжқҘжҺўи®ЁеҮ з§ҚдёҚеҗҢзҡ„еҒҡжі•гҖӮ
е°ұжҳҜжңҖ常规зҡ„ж–№жЎҲпјҢеҒҮи®ҫ жҲ‘们йңҖиҰҒеҜ№ж–Үз« articles иҝҷдёӘиЎЁ(йӣҶеҗҲ) иҝӣиЎҢеҲҶйЎөеұ•зӨәпјҢдёҖиҲ¬еүҚз«ҜдјҡйңҖиҰҒдј йҖ’дёӨдёӘеҸӮж•°пјҡ
жҢүз…§иҝҷдёӘеҒҡжі•зҡ„жҹҘиҜўж–№ејҸпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
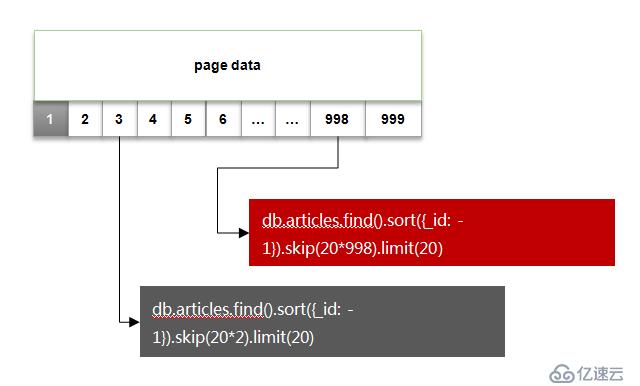
еӣ дёәжҳҜеёҢжңӣжңҖеҗҺеҲӣе»әзҡ„ж–Үз« жҳҫзӨәеңЁеүҚйқўпјҢиҝҷйҮҢдҪҝз”ЁдәҶ_id еҒҡйҷҚеәҸжҺ’еәҸгҖӮ
е…¶дёӯзәўиүІйғЁеҲҶиҜӯеҸҘзҡ„жү§иЎҢи®ЎеҲ’еҰӮдёӢпјҡ
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : []
},
"winningPlan" : {
"stage" : "SKIP",
"skipAmount" : 19960,
"inputStage" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"[MaxKey, MinKey]"
]
...
}еҸҜд»ҘзңӢеҲ°йҡҸзқҖйЎөз Ғзҡ„еўһеӨ§пјҢskip и·іиҝҮзҡ„жқЎзӣ®д№ҹдјҡйҡҸд№ӢеҸҳеӨ§пјҢиҖҢиҝҷдёӘж“ҚдҪңжҳҜйҖҡиҝҮ cursor зҡ„иҝӯд»ЈеҷЁжқҘе®һзҺ°зҡ„пјҢеҜ№дәҺcpuзҡ„ж¶ҲиҖ—дјҡжҜ”иҫғжҳҺжҳҫгҖӮ
иҖҢеҪ“йңҖиҰҒжҹҘиҜўзҡ„ж•°жҚ®иҫҫеҲ°еҚғдёҮзә§еҸҠд»ҘдёҠж—¶пјҢдјҡеҸ‘зҺ°е“Қеә”ж—¶й—ҙйқһеёёзҡ„й•ҝпјҢеҸҜиғҪдјҡи®©дҪ еҮ д№Һж— жі•жҺҘеҸ—пјҒ
жҲ–и®ёпјҢеҒҮеҰӮдҪ зҡ„жңәеҷЁжҖ§иғҪеҫҲе·®пјҢеңЁж•°еҚҒдёҮгҖҒзҷҫдёҮж•°жҚ®йҮҸж—¶е·Із»ҸдјҡеҮәзҺ°з“¶йўҲ
ж—ўз„¶дј з»ҹзҡ„еҲҶйЎөж–№жЎҲдјҡдә§з”ҹ skip еӨ§йҮҸж•°жҚ®зҡ„й—®йўҳпјҢйӮЈд№ҲиғҪеҗҰйҒҝе…Қе‘ўпјҹзӯ”жЎҲжҳҜеҸҜд»Ҙзҡ„гҖӮ
ж”№иүҜзҡ„еҒҡжі•дёәпјҡ
еҰӮдёӢеӣҫжүҖзӨәпјҡ
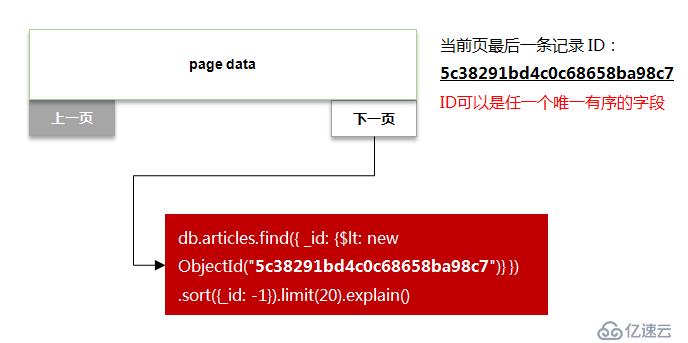
дҝ®ж”№еҗҺзҡ„иҜӯеҸҘжү§иЎҢи®ЎеҲ’еҰӮдёӢпјҡ
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"_id" : {
"$lt" : ObjectId("5c38291bd4c0c68658ba98c7")
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"(ObjectId('5c38291bd4c0c68658ba98c7'), ObjectId('000000000000000000000000')]"
]
...
}еҸҜд»ҘзңӢеҲ°пјҢж”№иүҜеҗҺзҡ„жҹҘиҜўж“ҚдҪңзӣҙжҺҘйҒҝе…ҚдәҶжҳӮиҙөзҡ„ skip йҳ¶ж®өпјҢзҙўеј•е‘ҪдёӯеҸҠжү«жҸҸиҢғеӣҙд№ҹжҳҜйқһеёёеҗҲзҗҶзҡ„пјҒ
дёәдәҶеҜ№жҜ”иҝҷдёӨз§Қж–№жЎҲзҡ„жҖ§иғҪе·®ејӮпјҢдёӢйқўеҮҶеӨҮдәҶдёҖз»„жөӢиҜ•ж•°жҚ®гҖӮ
жөӢиҜ•ж–№жЎҲ
еҮҶеӨҮ10WжқЎж•°жҚ®пјҢд»ҘжҜҸйЎө20жқЎзҡ„еҸӮж•°д»ҺеүҚеҫҖеҗҺзҝ»йЎөпјҢеҜ№жҜ”жҖ»дҪ“зҝ»йЎөзҡ„ж—¶й—ҙж¶ҲиҖ—
db.articles.remove({});
var count = 100000;
var items = [];
for(var i=1; i<=count; i++){
var item = {
"title" : "и®әе№ҙиҪ»дәәжҖқжғіе»әи®ҫзҡ„йҮҚиҰҒжҖ§-" + i,
"author" : "зҺӢе°Ҹе…ө-" + Math.round(Math.random() * 50),
"type" : "жқӮж–Ү-" + Math.round(Math.random() * 10) ,
"publishDate" : new Date(),
} ;
items.push(item);
if(i%1000==0){
db.test.insertMany(items);
print("insert", i);
items = [];
}
}дј з»ҹзҝ»йЎөи„ҡжң¬
function turnPages(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentPage = 0;
//иҪ®иҜўзҝ»йЎө
while(currentPage < pageTotal){
var list = db.articles.find({}, {_id:1}).sort({_id: -1}).skip(currentPage*pageSize).limit(pageSize);
dl = list.toArray();
//жІЎжңүжӣҙеӨҡи®°еҪ•
if(dl.length == 0){
break;
}
currentPage ++;
//printjson(dl)
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/1000).toFixed(2)
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}ж”№иүҜзҝ»йЎөи„ҡжң¬
function turnPageById(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentId = 0;
var currentPage = 0;
while(currentPage ++ < pageTotal){
//д»ҘдёҠдёҖйЎөзҡ„IDеҖјдҪңдёәиө·е§ӢеҖј
var condition = currentId? {_id: {$lt: currentId}}: {};
var list = db.articles.find(condition, {_id:1}).sort({_id: -1}).limit(pageSize);
dl = list.toArray();
//жІЎжңүжӣҙеӨҡи®°еҪ•
if(dl.length == 0){
break;
}
//и®°еҪ•жңҖеҗҺдёҖжқЎж•°жҚ®зҡ„ID
currentId = dl[dl.length-1]._id;
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/1000).toFixed(2)
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}д»Ҙ100гҖҒ500гҖҒ1000гҖҒ3000йЎөж•°зҡ„ж ·жң¬иҝӣиЎҢе®һжөӢпјҢз»“жһңеҰӮдёӢпјҡ

еҸҜи§ҒпјҢеҪ“йЎөж•°и¶ҠеӨ§(ж•°жҚ®йҮҸи¶ҠеӨ§)ж—¶пјҢж”№иүҜзҡ„зҝ»йЎөж•ҲжһңжҸҗеҚҮи¶ҠжҳҺжҳҫпјҒ
иҝҷз§ҚеҲҶйЎөж–№жЎҲе…¶е®һйҮҮз”Ёзҡ„е°ұжҳҜж—¶й—ҙиҪҙ(TImeLine)зҡ„жЁЎејҸпјҢе®һйҷ…еә”з”ЁеңәжҷҜд№ҹйқһеёёзҡ„е№ҝпјҢжҜ”еҰӮTwitterгҖҒеҫ®еҚҡгҖҒжңӢеҸӢеңҲеҠЁжҖҒйғҪеҸҜйҮҮз”Ёиҝҷж ·зҡ„ж–№ејҸгҖӮ
иҖҢеҗҢж—¶йҷӨдәҶдёҠиҝ°зҡ„ж•°жҚ®еә“д№ӢеӨ–пјҢHBaseгҖҒElastiSearch еңЁRange Queryзҡ„е®һзҺ°дёҠд№ҹж”ҜжҢҒиҝҷз§ҚжЁЎејҸгҖӮ
ж—¶й—ҙиҪҙ(TimeLine)зҡ„жЁЎејҸйҖҡеёёжҳҜеҒҡжҲҗвҖңеҠ иҪҪжӣҙеӨҡвҖқгҖҒдёҠдёӢзҝ»йЎөиҝҷж ·зҡ„еҪўејҸпјҢдҪҶж— жі•иҮӘз”ұзҡ„йҖүжӢ©жҹҗдёӘйЎөз ҒгҖӮ
йӮЈд№ҲдёәдәҶе®һзҺ°йЎөз ҒеҲҶйЎөпјҢеҗҢж—¶д№ҹйҒҝе…Қдј з»ҹж–№жЎҲеёҰжқҘзҡ„ skip жҖ§иғҪй—®йўҳпјҢжҲ‘们еҸҜд»ҘйҮҮеҸ–дёҖз§ҚжҠҳдёӯзҡ„ж–№жЎҲгҖӮ
иҝҷйҮҢеҸӮиҖғGoogleжҗңзҙўз»“жһңйЎөдҪңдёәиҜҙжҳҺпјҡ

йҖҡеёёеңЁж•°жҚ®йҮҸйқһеёёеӨ§зҡ„жғ…еҶөдёӢпјҢйЎөз Ғд№ҹдјҡжңүеҫҲеӨҡпјҢдәҺжҳҜеҸҜд»ҘйҮҮз”ЁйЎөз ҒеҲҶз»„зҡ„ж–№ејҸгҖӮ
д»ҘдёҖж®өйЎөз ҒдҪңдёәдёҖз»„пјҢжҜҸдёҖз»„еҶ…ж•°жҚ®зҡ„зҝ»йЎөйҮҮз”ЁID еҒҸ移йҮҸ + е°‘йҮҸзҡ„ skip ж“ҚдҪңе®һзҺ°
е…·дҪ“зҡ„ж“ҚдҪңеҰӮдёӢеӣҫжүҖзӨәпјҡ

е®һзҺ°жӯҘйӘӨ
еҜ№йЎөз ҒиҝӣиЎҢеҲҶз»„(groupSize=8, pageSize=20)пјҢжҜҸз»„дёә8дёӘйЎөз Ғпјӣ
жҸҗеүҚжҹҘиҜў end_offsetпјҢеҗҢж—¶иҺ·еҫ—жң¬з»„йЎөз Ғж•°йҮҸпјҡ
db.articles.find({ _id: { $lt: start_offset } }).sort({_id: -1}).skip(20*8).limit(1)йҡҸзқҖзү©иҒ”зҪ‘пјҢеӨ§ж•°жҚ®дёҡеҠЎзҡ„зҷҪзғӯеҢ–пјҢдёҖиҲ¬дјҒдёҡзә§зі»з»ҹзҡ„ж•°жҚ®йҮҸд№ҹдјҡе‘ҲзҺ°еҮәеҝ«йҖҹзҡ„еўһй•ҝгҖӮиҖҢдј з»ҹзҡ„ж•°жҚ®еә“еҲҶйЎөж–№жЎҲеңЁжө·йҮҸж•°жҚ®еңәжҷҜдёӢеҫҲйҡҫж»Ўи¶іжҖ§иғҪзҡ„иҰҒжұӮгҖӮ
еңЁжң¬ж–Үзҡ„жҺўи®ЁдёӯпјҢдё»иҰҒдёәжө·йҮҸж•°жҚ®зҡ„еҲҶйЎөжҸҗдҫӣдәҶеҮ з§Қеёёи§Ғзҡ„дјҳеҢ–ж–№жЎҲ(д»ҘMongoDBдҪңдёәе®һдҫӢ)пјҢ并еңЁжҖ§иғҪдёҠеҒҡдәҶдёҖдәӣеҜ№жҜ”пјҢж—ЁеңЁжҸҗдҫӣдёҖдәӣеҸӮиҖғгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ