жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪҝз”ЁJavaдёӯжҲҗеһӢзҡ„жЎҶжһ¶жқҘеё®еҠ©жҲ‘们ејҖеҸ‘并еҸ‘еә”з”ЁеҚіеҸҜд»ҘиҠӮзңҒжһ„е»әйЎ№зӣ®зҡ„ж—¶й—ҙпјҢд№ҹеҸҜд»ҘжҸҗй«ҳеә”з”Ёзҡ„жҖ§иғҪгҖӮ
JavaеҜ№иұЎе®һдҫӢзҡ„й”ҒдёҖе…ұжңүеӣӣз§ҚзҠ¶жҖҒпјҡж— й”ҒпјҢеҒҸеҗ‘й”ҒпјҢиҪ»йҮҸй”Ғе’ҢйҮҚйҮҸй”ҒгҖӮеҺҹе§Ӣи„ұзҰ»жЎҶжһ¶зҡ„并еҸ‘еә”з”ЁеӨ§йғЁеҲҶйғҪйңҖиҰҒжүӢеҠЁе®ҢжҲҗеҠ й”ҒйҮҠж”ҫпјҢжңҖзӣҙжҺҘзҡ„е°ұжҳҜдҪҝз”Ёsynchronizedе’Ңvolatileе…ій”®еӯ—еҜ№жҹҗдёӘеҜ№иұЎжҲ–иҖ…д»Јз Ғеқ—еҠ й”Ғд»ҺиҖҢйҷҗеҲ¶жҜҸж¬Ўи®ҝй—®зҡ„ж¬Ўж•°пјҢд»ҺеҜ№иұЎд№Ӣй—ҙзҡ„з«һдәүд№ҹеҸҜд»Ҙе®һзҺ°еҲ°еҜ№иұЎд№Ӣй—ҙзҡ„еҚҸдҪңгҖӮдҪҶжҳҜиҝҷж ·жүӢеҠЁе®һзҺ°еҮәжқҘзҡ„еә”з”ЁдёҚд»…иҖ—иҙ№ж—¶й—ҙиҖҢдё”жҖ§иғҪиЎЁзҺ°еҫҖеҫҖеҸҲжңүеҫ…жҸҗеҚҮгҖӮйЎәеёҰдёҖжҸҗпјҢд№ӢеүҚеҶҷиҝҮдёҖзҜҮж–Үз« д»Ӣз»ҚжҲ‘еҹәдәҺQtе’ҢLinuxе®һзҺ°зҡ„дёҖдёӘеӨҡзәҝзЁӢдёӢиҪҪеҷЁпјҲеҲ°иҝҷйҮҢдёҚйңҖиҰҒжӣҙеӨҡдәҶи§ЈиҝҷдёӘдёӢиҪҪеҷЁпјҢиҜ·зӣҙжҺҘ继з»ӯйҳ…иҜ»пјүпјҢе°ұжӢҝиҝҷдёӘдёӢиҪҪеҷЁеҒҡдёҖж¬ЎеҸҚдҫӢпјҡ
йҰ–е…ҲпјҢдёҖдёӘдёӢиҪҪеҷЁжңҖж„ҡи ўзҡ„й—®йўҳд№ӢдёҖе°ұжҳҜжҠҠдёӢиҪҪзәҝзЁӢзҡ„дёӘж•°дәӨз”ұз»ҷз”ЁжҲ·еҺ»й…ҚзҪ®гҖӮжҜ”еҰӮдёҖдёӘз”ЁжҲ·дјҡи®ӨдёәиҙҹиҙЈдёӢиҪҪзҡ„зәҝзЁӢдёӘж•°жҳҜи¶ҠеӨҡи¶ҠеҘҪпјҢе№Іи„Ҷй…ҚзҪ®дәҶ50дёӘзәҝзЁӢеҺ»дёӢиҪҪдёҖд»Ҫд»»еҠЎпјҢйӮЈд№ҲиҝҷдёӘдёӢиҪҪеҷЁзҡ„жҖ§иғҪиЎЁзҺ°з”ҡиҮідјҡдёҚеҰӮдёҖдёӘеҚ•иҝӣзЁӢзҡ„дёӢиҪҪзЁӢеәҸгҖӮжңҖзӣҙжҺҘзҡ„еҺҹеӣ е°ұжҳҜJVMиҠұиҙ№дәҶеҫҲеӨҡи®Ўз®—иө„жәҗеңЁзәҝзЁӢд№Ӣй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўдёҠйқўпјҢеҜ№дәҺдёҖдёӘ并еҸ‘зҡ„еә”з”ЁпјҡеҰӮжһңжҳҜCPUеҜҶйӣҶеһӢзҡ„д»»еҠЎпјҢйӮЈд№ҲиүҜеҘҪзҡ„зәҝзЁӢдёӘж•°жҳҜе®һйҷ…CPUеӨ„зҗҶеҷЁзҡ„дёӘж•°зҡ„1еҖҚпјӣеҰӮжһңжҳҜI/OеҜҶйӣҶеһӢзҡ„д»»еҠЎпјҢйӮЈд№ҲиүҜеҘҪзҡ„зәҝзЁӢдёӘж•°жҳҜе®һйҷ…CPUеӨ„зҗҶеҷЁдёӘж•°зҡ„1.5еҖҚеҲ°2еҖҚпјҲе…·дҪ“и®°дёҚжё…иҝҷеҸҘиҜқжҳҜеҮәдәҺе“ӘйҮҢдәҶпјҢдҪҶиҝҳжҳҜеҸҜдҝЎзҡ„пјүгҖӮдёҚжҒ°еҪ“зҡ„жү§иЎҢзәҝзЁӢдёӘж•°дјҡз»ҷзәҝзЁӢжҠ–еҠЁпјҢCPUжҠ–еҠЁзӯүйҡҗжӮЈеҹӢдёӢдјҸ笔гҖӮеҰӮжһңпјҢйҮҚж–°ејҖеҸ‘йӮЈд№ҲжҲ‘дёҖе®ҡдјҡдҪҝз”Ёиҝҷз§ҚзәҝзЁӢжұ зҡ„ж–№жі•дҪҝз”Ёз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…зҡ„е…ізі»жЁЎејҸпјҢејӮжӯҘеӨ„зҗҶHTTPдј иҫ“иҝҮжқҘзҡ„жҠҘж–ҮгҖӮ
е…¶ж¬ЎпјҢз”ұдәҺHTTPжҠҘж–Үзҡ„жҺҘеҸ—зӯүеҫ…зҡ„ж—¶й—ҙеҸҜиғҪйңҖиҰҒзӯүеҫ…еҫҲд№…пјҢ然иҖҢеӨ„зҗҶжҠҘж–Үи§Јжһҗж јејҸзӯүзӯүж¶ҲиҖ—зҡ„и®Ўз®—иө„жәҗжҳҜзӣёеҪ“иҫғе°Ҹзҡ„гҖӮеҗҢжӯҘең°еӨ„зҗҶиҝҷдёӨ件дәӢжғ…еҝ…然дјҡдҪҝдёӢиҪҪиҝӣзЁӢеңЁдёҖж®өж—¶й—ҙеҶ…з©әиҪ¬жҲ–иҖ…йҳ»еЎһпјҢиҝҷж ·еӨ„зҗҶд№ҹжҳҜйқһеёёдёҚеҗҲзҗҶзҡ„гҖӮеҰӮжһңйҮҚж–°ејҖеҸ‘пјҢдёҖе®ҡиҰҒи§ЈиҖҰHTTPжҠҘж–Үзҡ„жҺҘ收е’ҢHTTPжҠҘж–Үзҡ„и§ЈжһҗпјҢиҝҷйҮҢе°Ҫз®Ўд№ҹеҸҜд»ҘдҪҝз”ЁзәҝзЁӢжұ еҺ»иҝӣиЎҢеӨ„зҗҶпјҢжҳҫиҖҢжҳ“и§Ғз”ұдәҺиҝҷж ·еҺ»еҒҡзҡ„жҖ§иғҪжҸҗеҚҮе…¶е®һжҳҜеҫҲе°Ҹзҡ„пјҢжүҖд»ҘжІЎжңүеҝ…иҰҒеҺ»е®һзҺ°пјҢеҚ•зәҝзЁӢд№ҹеҸҜд»Ҙеҝ«йҖҹе®ҢжҲҗжҠҘж–Үзҡ„и§ЈжһҗгҖӮ
OkayпјҢеӣһеҲ°дё»йўҳпјҢжҖ»иҖҢиЁҖд№ӢжҳҜзәҝзЁӢд№Ӣй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўеҜјиҮҙдәҶжҖ§иғҪзҡ„йҷҚдҪҺгҖӮйӮЈд№Ҳе…·дҪ“еә”иҜҘжҖҺд№Ҳж ·еҺ»еҒҡжүҚеҸҜд»ҘеҮҸе°‘дёҠдёӢж–Үзҡ„еҲҮжҚўе‘ўпјҹ
1. ж— й”Ғ并еҸ‘зј–зЁӢ
еӨҡзәҝзЁӢз«һдәүй”Ғж—¶пјҢдјҡеј•иө·дёҠдёӢж–ҮеҲҮжҚўпјҢжүҖд»ҘеӨҡзәҝзЁӢеӨ„зҗҶж•°жҚ®ж—¶пјҢеҸҜд»Ҙз”ЁдёҖдәӣеҠһжі•жқҘйҒҝе…ҚдҪҝз”Ёй”ҒпјҢеҰӮе°Ҷж•°жҚ®зҡ„IDжҢүз…§Hashз®—жі•еҸ–жЁЎеҲҶж®өпјҢдёҚеҗҢзҡ„зәҝзЁӢеҺ»еӨ„зҗҶдёҚеҗҢж®өзҡ„ж•°жҚ®гҖӮ
2. CASз®—жі•
Javaзҡ„AtomicеҢ…еҶ…дҪҝз”ЁCASз®—жі•жқҘжӣҙж–°ж•°жҚ®пјҢиҖҢдёҚйңҖиҰҒеҠ й”ҒпјҲдҪҶжҳҜзәҝзЁӢзҡ„з©әиҪ¬иҝҳжҳҜеӯҳеңЁпјүгҖӮ
3. дҪҝз”ЁжңҖе°‘зәҝзЁӢ
йҒҝе…ҚеҲӣе»әдёҚйңҖиҰҒзҡ„зәҝзЁӢпјҢжҜ”еҰӮд»»еҠЎеҫҲе°‘пјҢдҪҶжҳҜеҲӣе»әеҫҲеӨҡзәҝзЁӢжқҘеӨ„зҗҶпјҢиҝҷж ·дјҡйҖ жҲҗеӨ§йҮҸзәҝзЁӢйғҪеӨ„дәҺзӯүеҫ…зҠ¶жҖҒгҖӮ
4. еҚҸзЁӢ
еңЁеҚ•зәҝзЁӢйҮҢе®һзҺ°еӨҡд»»еҠЎзҡ„и°ғеәҰпјҢ并еңЁеҚ•зәҝзЁӢйҮҢз»ҙжҢҒеӨҡдёӘд»»еҠЎй—ҙзҡ„еҲҮжҚўгҖӮ
жҖ»зҡ„жқҘиҜҙдҪҝз”ЁJavaзәҝзЁӢжұ дјҡеёҰжқҘд»ҘдёӢ3дёӘеҘҪеӨ„пјҡ
1. йҷҚдҪҺиө„жәҗж¶ҲиҖ—пјҡ йҖҡиҝҮйҮҚеӨҚеҲ©з”Ёе·ІеҲӣе»әзҡ„зәҝзЁӢйҷҚдҪҺзәҝзЁӢеҲӣе»әе’Ңй”ҖжҜҒйҖ жҲҗзҡ„ж¶ҲиҖ—гҖӮ
2. жҸҗй«ҳе“Қеә”йҖҹеәҰпјҡ еҪ“д»»еҠЎеҲ°иҫҫж—¶пјҢд»»еҠЎеҸҜд»ҘдёҚйңҖиҰҒзӯүеҲ°зәҝзЁӢеҲӣе»әе°ұиғҪз«ӢеҚіжү§иЎҢгҖӮ
3. жҸҗй«ҳзәҝзЁӢзҡ„еҸҜз®ЎзҗҶжҖ§пјҡ зәҝзЁӢжҳҜзЁҖзјәиө„жәҗпјҢеҰӮжһңж— йҷҗеҲ¶зҡ„еҲӣе»әгҖӮдёҚд»…д»…дјҡйҷҚдҪҺзі»з»ҹзҡ„зЁіе®ҡжҖ§пјҢдҪҝз”ЁзәҝзЁӢжұ еҸҜд»Ҙз»ҹдёҖеҲҶй…ҚпјҢи°ғдјҳе’Ңзӣ‘жҺ§гҖӮдҪҶжҳҜиҰҒеҒҡеҲ°еҗҲзҗҶзҡ„еҲ©з”ЁзәҝзЁӢжұ гҖӮеҝ…йЎ»еҜ№дәҺе…¶е®һзҺ°еҺҹзҗҶдәҶеҰӮжҢҮжҺҢгҖӮ
зәҝзЁӢжұ зҡ„е®һзҺ°еҺҹзҗҶеҰӮдёӢеӣҫжүҖзӨәпјҡ
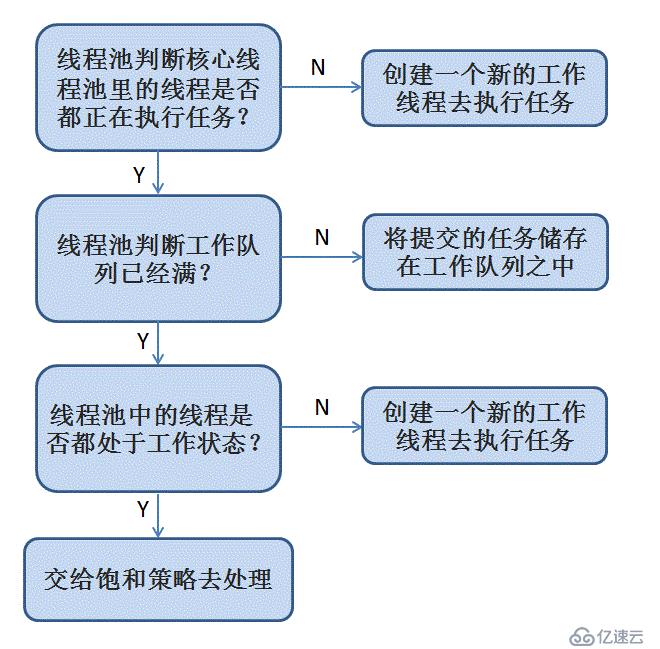
ExecutorжЎҶжһ¶зҡ„дёӨзә§и°ғеәҰжЁЎеһӢпјҡ
еңЁHotSpot VMзәҝзЁӢжЁЎеһӢдёӯпјҢJavaзәҝзЁӢиў«дёҖеҜ№дёҖзҡ„жҳ е°„дёәжң¬ең°ж“ҚдҪңзі»з»ҹзәҝзЁӢпјҢJavaзәҝзЁӢеҗҜеҠЁж—¶дјҡеҲӣе»әдёҖдёӘжң¬ең°ж“ҚдҪңзі»з»ҹзәҝзЁӢпјҢеҪ“иҜҘJavaзәҝзЁӢз»Ҳжӯўж—¶пјҢиҝҷдёӘж“ҚдҪңзі»з»ҹд№ҹдјҡиў«еӣһ收гҖӮж“ҚдҪңзі»з»ҹдјҡи°ғеәҰ并е°Ҷе®ғ们еҲҶй…Қз»ҷеҸҜз”Ёзҡ„CPUгҖӮ
еңЁдёҠеұӮпјҢJavaеӨҡзәҝзЁӢзЁӢеәҸйҖҡеёёжҠҠеә”з”ЁеҲҶи§ЈдёәиӢҘе№ІдёӘд»»еҠЎпјҢ然еҗҺжҠҠз”ЁжҲ·зә§зҡ„и°ғеәҰеҷЁпјҲExecutorжЎҶжһ¶пјүе°Ҷиҝҷдәӣжҳ е°„дёәеӣәе®ҡж•°йҮҸзҡ„зәҝзЁӢпјӣеңЁеә•еұӮпјҢж“ҚдҪңзі»з»ҹеҶ…ж ёе°ҶиҝҷдәӣзәҝзЁӢжҳ е°„еҲ°зЎ¬д»¶еӨ„зҗҶеҷЁдёҠгҖӮиҝҷз§ҚдёӨзә§и°ғеәҰжЁЎеһӢе®һиҙЁжҳҜдёҖз§Қе·ҘдҪңеҚ•е…ғе’Ңжү§иЎҢжңәеҲ¶зҡ„и§ЈеҒ¶гҖӮ
Fork/JoinжЎҶжһ¶зҡ„йҖ’еҪ’и°ғеәҰжЁЎеһӢпјҡ
иҰҒжҸҗй«ҳеә”з”ЁзЁӢеәҸеңЁеӨҡж ёеӨ„зҗҶеҷЁдёҠзҡ„жү§иЎҢж•ҲзҺҮпјҢеҸӘиғҪжғіеҠһжі•жҸҗй«ҳеә”з”ЁзЁӢеәҸзҡ„жң¬иә«зҡ„并иЎҢиғҪеҠӣгҖӮ常规зҡ„еҒҡжі•е°ұжҳҜдҪҝз”ЁеӨҡзәҝзЁӢпјҢи®©жӣҙеӨҡзҡ„д»»еҠЎеҗҢж—¶еӨ„зҗҶпјҢжҲ–иҖ…и®©дёҖйғЁеҲҶж“ҚдҪңејӮжӯҘжү§иЎҢпјҢиҝҷз§Қз®ҖеҚ•зҡ„еӨҡзәҝзЁӢеӨ„зҗҶж–№ејҸеңЁеӨ„зҗҶеҷЁж ёеҝғж•°жҜ”иҫғе°‘зҡ„жғ…еҶөдёӢиғҪеӨҹжңүж•Ҳең°еҲ©з”ЁеӨ„зҗҶиө„жәҗпјҢеӣ дёәеңЁеӨ„зҗҶеҷЁж ёеҝғжҜ”иҫғе°‘зҡ„жғ…еҶөдёӢпјҢи®©дёҚеӨҡзҡ„еҮ дёӘд»»еҠЎе№¶иЎҢжү§иЎҢеҚіеҸҜгҖӮдҪҶжҳҜеҪ“еӨ„зҗҶеҷЁж ёеҝғж•°еҸ‘еұ•еҫҲеӨ§зҡ„ж•°зӣ®пјҢдёҠзҷҫдёҠеҚғзҡ„ж—¶еҖҷпјҢиҝҷз§ҚжҢүд»»еҠЎзҡ„并еҸ‘еӨ„зҗҶж–№жі•д№ҹдёҚиғҪе……еҲҶеҲ©з”ЁеӨ„зҗҶиө„жәҗпјҢеӣ дёәдёҖиҲ¬зҡ„еә”з”ЁзЁӢеәҸжІЎжңүйӮЈд№ҲеӨҡзҡ„并еҸ‘еӨ„зҗҶд»»еҠЎпјҲжңҚеҠЎеҷЁзЁӢеәҸжҳҜдёӘдҫӢеӨ–пјүгҖӮжүҖд»ҘпјҢеҸӘиғҪиҖғиҷ‘жҠҠдёҖдёӘд»»еҠЎжӢҶеҲҶдёәеӨҡдёӘеҚ•е…ғпјҢжҜҸдёӘеҚ•е…ғеҲҶеҲ«еҫ—жү§иЎҢжңҖеҗҺеҗҲ并жҜҸдёӘеҚ•е…ғзҡ„з»“жһңгҖӮдёҖдёӘд»»еҠЎзҡ„并иЎҢжӢҶеҲҶпјҢдёҖз§Қж–№жі•е°ұжҳҜеҜ„еёҢжңӣдәҺ硬件平еҸ°жҲ–иҖ…ж“ҚдҪңзі»з»ҹпјҢдҪҶжҳҜзӣ®еүҚиҝҷдёӘйўҶеҹҹиҝҳжІЎжңүеҫҲеҘҪзҡ„з»“жһңгҖӮеҸҰдёҖз§Қж–№жЎҲе°ұжҳҜиҝҳжҳҜеҸӘжңүдҫқйқ еә”з”ЁзЁӢеәҸжң¬иә«еҜ№д»»еҠЎз»ҸиЎҢжӢҶе°Ғжү§иЎҢгҖӮ
Fork/JoinжЁЎеһӢд№ҚзңӢиө·жқҘеҫҲеғҸеҖҹйүҙдәҶMapReduceпјҢдҪҶжҳҜе…·дҪ“дёҚж•ўиӮҜе®ҡжҳҜд»Җд№ҲеҺҹеӣ пјҢе®һйҷ…з”Ёиө·жқҘзҡ„жҖ§иғҪжҸҗеҚҮжҳҜиҝңдёҚеҰӮExecutorзҡ„гҖӮз”ҡиҮіеңЁйҖ’еҪ’ж ҲеҲ°дәҶеҚҒеұӮд»ҘдёҠзҡ„ж—¶еҖҷпјҢJVMдјҡеҚЎжӯ»жҲ–иҖ…еҙ©жәғпјҢд»Һи®Ўз®—жңәзҡ„зү©зҗҶеҺҹзҗҶжқҘзңӢпјҢFork/JoinжЎҶжһ¶е®һйҷ…ж•ҲиғҪд№ҹжІЎжңүжғіиұЎдёӯзҡ„йӮЈд№ҲзҫҺеҘҪпјҢжүҖд»ҘиҝҷзҜҮеҸӘзЁҚеҫ®и°ҲдёҖдёӢпјҢдёҚеҶҚж·ұ究гҖӮ
ExecutorжЎҶжһ¶дё»иҰҒз”ұдёүдёӘйғЁеҲҶз»„жҲҗпјҡд»»еҠЎпјҢд»»еҠЎзҡ„жү§иЎҢпјҢејӮжӯҘи®Ўз®—зҡ„з»“жһңгҖӮ
дё»иҰҒзҡ„зұ»е’ҢжҺҘеҸЈз®Җд»ӢеҰӮдёӢпјҡ
1. ExecutorжҳҜдёҖдёӘжҺҘеҸЈпјҢе®ғе°Ҷд»»еҠЎзҡ„жҸҗдәӨе’Ңд»»еҠЎзҡ„жү§иЎҢеҲҶзҰ»гҖӮ
2. ThreadPoolExecutorжҳҜзәҝзЁӢжұ зҡ„ж ёеҝғпјҢз”ЁжқҘжү§иЎҢиў«жҸҗдәӨзҡ„зұ»гҖӮ
3. FutureжҺҘеҸЈе’Ңе®һзҺ°FutureжҺҘеҸЈзҡ„FutureTaskзұ»пјҢд»ЈиЎЁејӮжӯҘи®Ўз®—зҡ„з»“жһңгҖӮ
4. RunnableжҺҘеҸЈе’ҢCallableжҺҘеҸЈзҡ„е®һзҺ°зұ»пјҢйғҪеҸҜд»Ҙиў«ThreadPoolExecutorжҲ–е…¶д»–жү§иЎҢгҖӮ
е…ҲзңӢдёҖдёӘзӣҙжҺҘзҡ„дҫӢеӯҗпјҲз”ЁSingleThreadExecutorжқҘе®һзҺ°пјҢе…·дҪ“еҺҹзҗҶдёӢйқўдјҡйҳҗиҝ°пјүпјҡ
В 1В publicВ classВ ExecutorDemoВ {
В 2В
В 3В
В 4В publicВ staticВ voidВ main(String[]В args){
В 5В
В 6В //ExecutorServiceВ fixed=В Executors.newFixedThreadPool(4);
В 7В ExecutorServiceВ single=Executors.newSingleThreadExecutor();
В 8В //ExecutorServiceВ cached=Executors.newCachedThreadPool();
В 9В //ExecutorServiceВ sched=Executors.newScheduledThreadPool(4);
11В
12В Callable<String>В callable=Executors.callable(newВ Runnable()В {
13В @Override
14В publicВ voidВ run()В {
15В for(intВ i=0;i<100;i++){
16В try{
17В System.out.println(i);
18В }catch(ThrowableВ e){
19В e.printStackTrace();
20В }
21В }
22В }
23В },"success");
24В гҖҖгҖҖгҖҖгҖҖгҖҖ//иҝҷйҮҢжҠ–дәҶдёӘжңәзҒөпјҢз”ЁExecutorsе·Ҙе…·зұ»зҡ„callableж–№жі•е°ҶдёҖдёӘеҢҝеҗҚRunnableеҜ№иұЎиЈ…йҘ°дёәCallableеҜ№иұЎдҪңдёәеҸӮж•°
25В Future<String>В f=single.submit(callable);
26В tryВ {
27В System.out.println(f.get());
28В single.shutdown();
29В }catch(ThrowableВ e){
30В e.printStackTrace();
31В }
32В }
33В }еҰӮд»Јз ҒдёӯжүҖзӨәпјҢеёёз”ЁдёҖе…ұжңүеӣӣз§ҚExectorе®һзҺ°зұ»йҖҡиҝҮExecutorsзҡ„е·ҘеҺӮж–№жі•жқҘеҲӣе»әExecutorзҡ„е®һдҫӢпјҢе…¶е…·дҪ“е·®еҲ«еҸҠзү№зӮ№еҰӮдёӢжүҖзӨәпјҡ
1. FixedThreadPool
иҝҷдёӘжҳҜжҲ‘дёӘдәәжңҖеёёз”Ёзҡ„е®һзҺ°зұ»пјҢеңЁJavaдёӯжңҖзӣҙжҺҘзҡ„дҪҝз”Ёж–№жі•е°ұжҳҜе’Ң Runtime.getRuntime().availableProcessors() дёҖиө·дҪҝз”ЁеҲҶй…ҚеӨ„зҗҶеҷЁдёӘж•°дёӘзҡ„ExecutorгҖӮеҶ…йғЁз»“жһ„еӨ§иҮҙеҰӮдёӢпјҡ
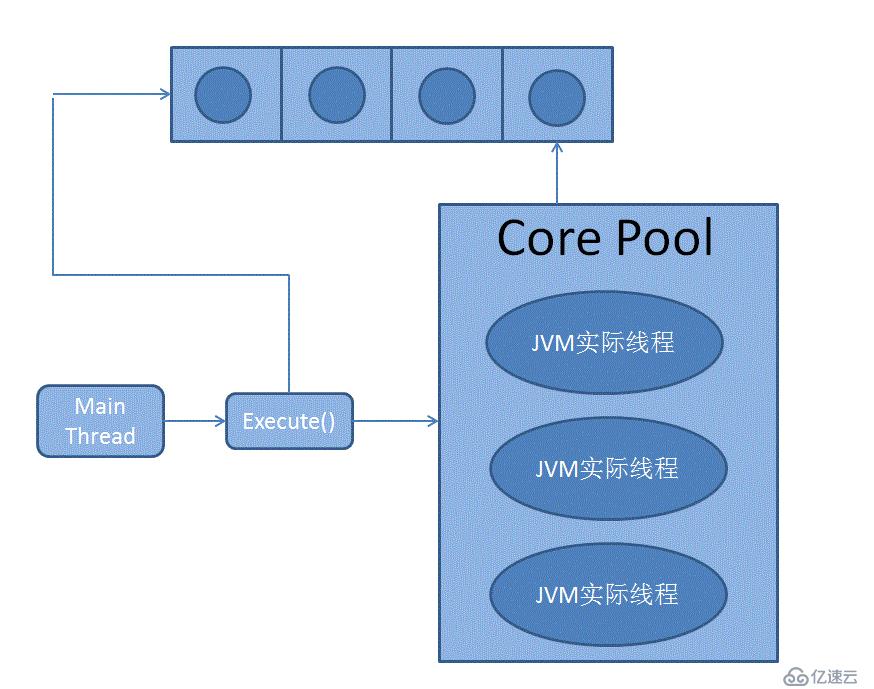
еҲӣйҖ е®һдҫӢзҡ„еҮҪж•°дёәпјҡ Executors.newFixedThreadPool(int nThread);
еңЁJDK1.7йҮҢjava.util.concurrentеҢ…дёӯзҡ„жәҗз ҒдёӯйҳҹеҲ—дҪҝз”Ёзҡ„жҳҜnew LinkedBlockingQueue<Runnable>пјҢиҝҷжҳҜдёҖдёӘГ—Г—Г—зҡ„йҳҹеҲ—пјҢд№ҹе°ұжҳҜиҜҙд»»еҠЎжңүеҸҜиғҪж— йҷҗең°з§ҜеҺӢеңЁиҝҷдёӘзӯүеҫ…йҳҹеҲ—д№ӢдёӯпјҢе®һйҷ…дҪҝз”ЁжҳҜеӯҳеңЁдёҖе®ҡзҡ„йҡҗжӮЈгҖӮдҪҶжҳҜжһ„йҖ иө·жқҘзӣёеҪ“жҜ”иҫғе®№жҳ“пјҢжҲ‘дёӘдәәе»әи®®еңЁдҪҝз”Ёзҡ„иҝҮзЁӢд№ӢдёӯдёҚж–ӯжҹҘиҜўsize()жқҘдҝқиҜҒиҜҘйҳ»еЎһйҳҹеҲ—дёҚдјҡж— йҷҗең°з”ҹй•ҝгҖӮ
2. SingleThreadExecutor
е’Ң Executors.newFixedThreadPool(1) е®Ңе…Ёзӯүд»·гҖӮ
3. CachedThreadPool
е’Ңд№ӢеүҚдёӨдёӘе®һзҺ°зұ»е®Ңе…ЁдёҚеҗҢзҡ„жҳҜпјҢиҝҷйҮҢдҪҝз”ЁSynchronousQueueжӣҝжҚўLinkedBlockingQueueгҖӮз®ҖеҚ•жҸҗдёҖдёӢSynchronousQueueжҳҜдёҖдёӘжІЎжңүе®№йҮҸзҡ„йҳҹеҲ—пјҢдёҖдёӘofferеҝ…йЎ»еҜ№еә”дёҖдёӘpollпјҢеҪ“然жүҖи°“pollж“ҚдҪңжҳҜз”ұе®һйҷ…JVMе·ҘдҪңзәҝзЁӢжқҘиҝӣиЎҢзҡ„пјҢжүҖд»ҘеҜ№дәҺдҪҝз”ЁејҖеҸ‘иҖ…жқҘи®ІпјҢиҝҷжҳҜдёҖдёӘдјҡеӣ дёәе·ҘдҪңзәҝзЁӢйҘұе’ҢиҖҢйҳ»еЎһзҡ„зәҝзЁӢжұ гҖӮпјҲиҝҷдёӘе’Ңjava.util.concurrent.Exchangerзҡ„дҪңз”ЁжңүдәӣзӣёдјјпјҢдҪҶжҳҜExchangerеҸӘжҳҜеҜ№дәҺдёӨдёӘJVMзәҝзЁӢзҡ„пјҢиҖҢSynchronousQueueзҡ„йҳ»еЎһжңәеҲ¶жҳҜеӨҡдёӘз”ҹдә§иҖ…е’ҢеӨҡдёӘж¶Ҳиҙ№иҖ…иҖҢиЁҖзҡ„гҖӮпјү
4. ScheduledThreadPoolExecutor
иҝҷдёӘе®һзҺ°зұ»еҶ…йғЁдҪҝз”Ёзҡ„жҳҜDelayQueueгҖӮDelayQueueе®һйҷ…дёҠжҳҜдёҖдёӘдјҳе…Ҳзә§йҳҹеҲ—зҡ„е°ҒиЈ…гҖӮж—¶й—ҙж—©зҡ„д»»еҠЎдјҡжӢҘжңүжӣҙй«ҳзҡ„дјҳе…Ҳзә§гҖӮе®ғдё»иҰҒз”ЁжқҘеңЁз»ҷе®ҡзҡ„延иҝҹд№ӢеҗҺиҝҗиЎҢд»»еҠЎпјҢжҲ–иҖ…е®ҡжңҹжү§иЎҢд»»еҠЎгҖӮScheduledThreadPoolExecutorзҡ„еҠҹиғҪдёҺTimerзұ»дјјпјҢдҪҶScheduledThreadPoolExecutorжҜ”TimerжӣҙеҠ зҒөжҙ»пјҢиҖҢдё”еҸҜд»ҘжңүеӨҡдёӘеҗҺеҸ°зәҝзЁӢеңЁжһ„йҖ еҮҪж•°д№ӢдёӯжҢҮе®ҡгҖӮ
FutureжҺҘеҸЈе’ҢListenableFurtureжҺҘеҸЈ
FutureжҺҘеҸЈдёәејӮжӯҘи®Ўз®—еҸ–еӣһз»“жһңжҸҗдҫӣдәҶдёҖдёӘеӯҳж №(stub)пјҢ然иҖҢиҝҷж ·жҜҸж¬Ўи°ғз”ЁFutureжҺҘеҸЈзҡ„getж–№жі•еҸ–еӣһи®Ўз®—з»“жһңеҫҖеҫҖжҳҜйңҖиҰҒйқўдёҙйҳ»еЎһзҡ„еҸҜиғҪжҖ§гҖӮиҝҷж ·еңЁжңҖеқҸзҡ„жғ…еҶөдёӢпјҢејӮжӯҘи®Ўз®—е’ҢеҗҢжӯҘи®Ўз®—зҡ„ж¶ҲиҖ—жҳҜдёҖиҮҙзҡ„гҖӮGuavaеә“дёӯеӣ жӯӨжҸҗдҫӣдёҖдёӘйқһеёёејәеӨ§зҡ„иЈ…йҘ°еҗҺзҡ„FutureжҺҘеҸЈпјҢдҪҝз”Ёи§ӮеҜҹиҖ…жЁЎејҸдёәеңЁејӮжӯҘи®Ўз®—е®ҢжҲҗд№ӢеҗҺ马дёҠжү§иЎҢaddListenerжҢҮе®ҡдёҖдёӘRunnableеҜ№иұЎпјҢд»Һе®һзҺ°вҖңе®ҢжҲҗз«ӢеҚійҖҡзҹҘвҖқгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ