您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
最近主攻go的学习,在学完了基础语法,看完了无闻翻译的《The way to go》和ccmouse大神的慕课网课程后,感觉基础差不多了,继续深入挖掘ccmouse大神的爬虫项目,收获颇丰,感觉还是有一定的难度的,会继续啃下去,学习之余感觉自己实在是井底之蛙,无数光阴尽数浪费,无所建树,思维停留在最原始的层面,无法向前迈进;庆幸现在有所觉悟,人生匆匆几十载,时间是最宝贵的,不论哪个领域,选择一个自己认定的,低下头向前冲刺,丰富自己的头脑,提升自己的认知。好像扯得有点远了,下面是项目的总结。
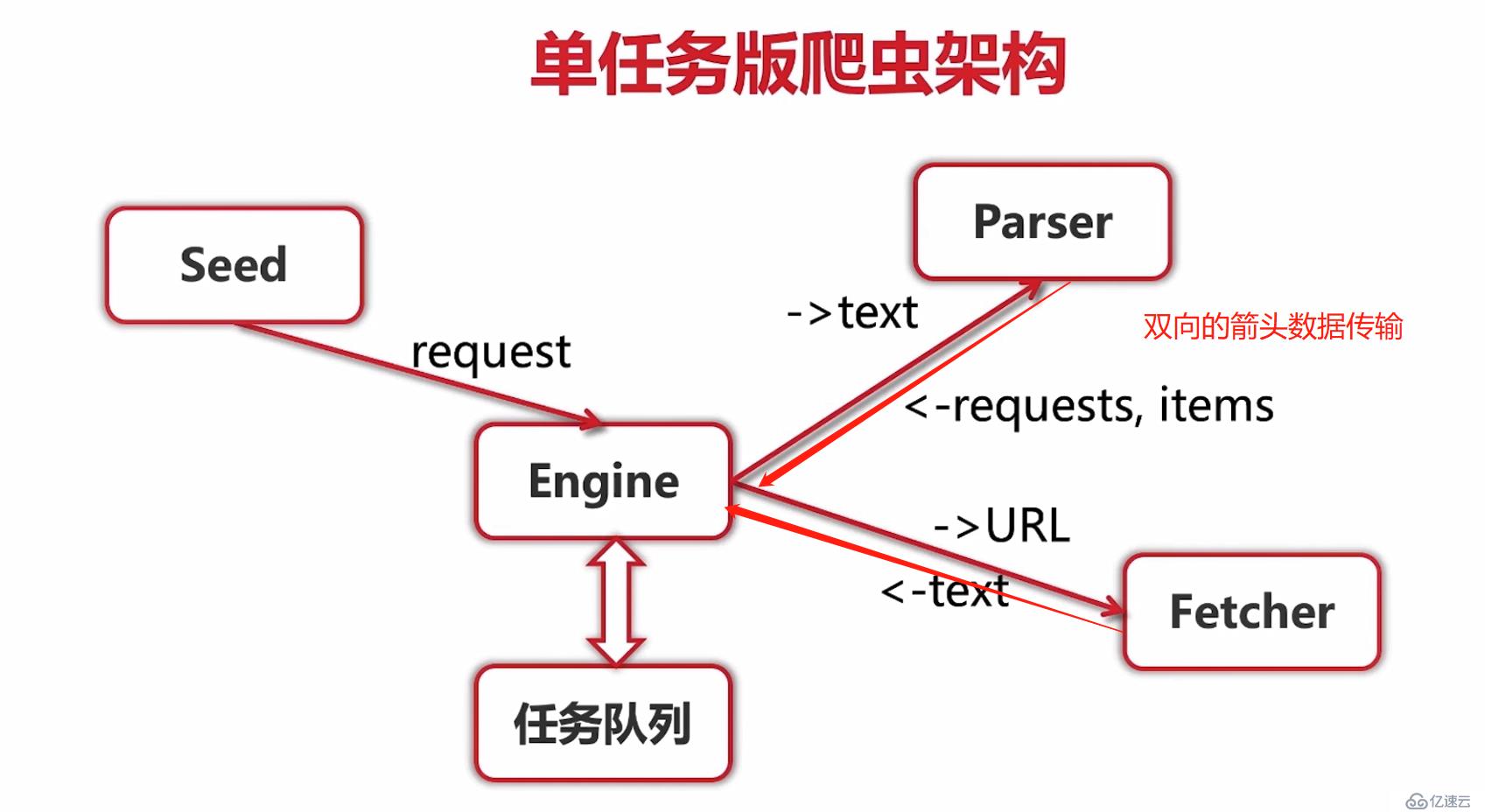
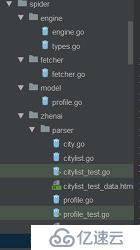 engine是总的控制文件,把请求和正则解析push到总的slice []request中,fetcher主要是通过http库去获取页面body信息,model是要保存的人的信息struct
engine是总的控制文件,把请求和正则解析push到总的slice []request中,fetcher主要是通过http库去获取页面body信息,model是要保存的人的信息struct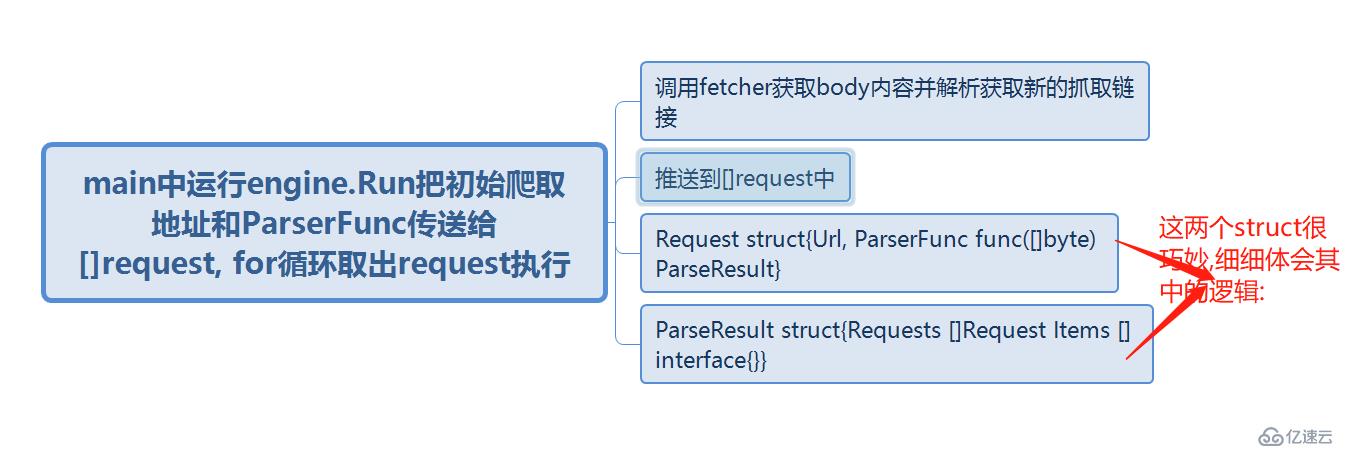
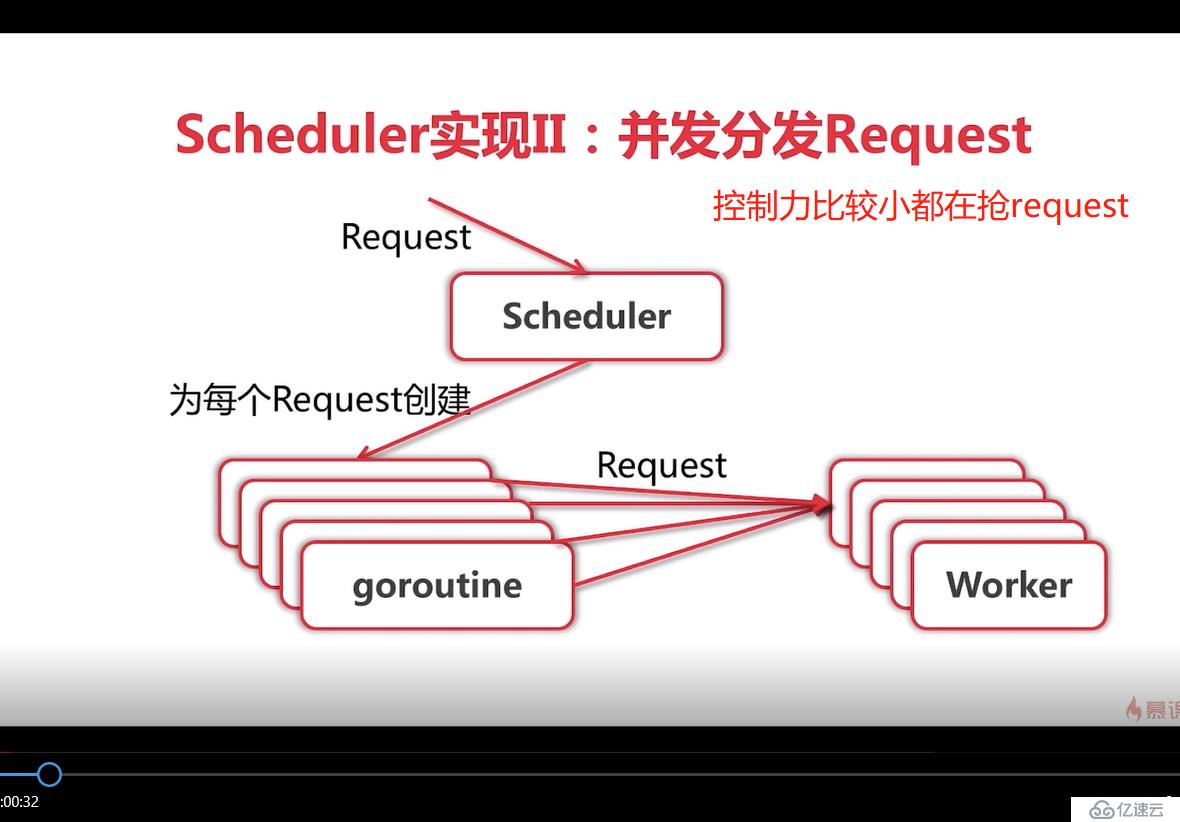
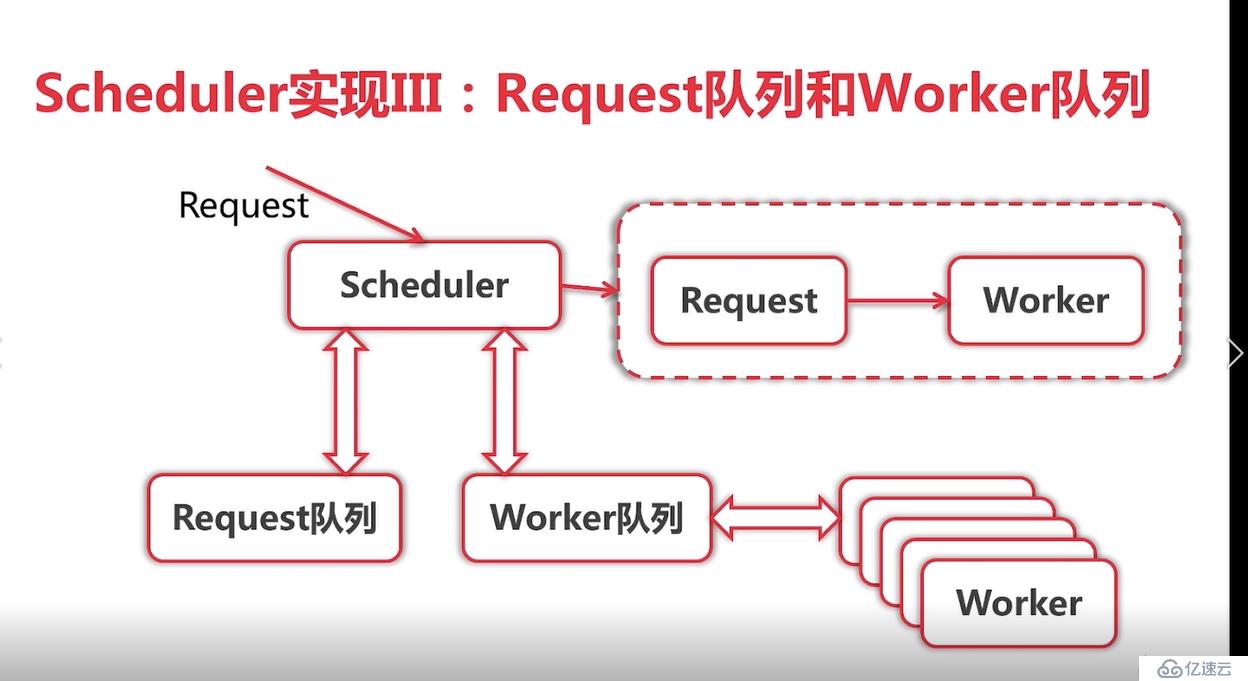
注意这里是两个chan), 在run方法中定义一个out chan ParseResult,和并发版相比而言,队列版多了workerChan 这个chan,主要用来实现队列的调度。试着描述下整个过程不一定清晰: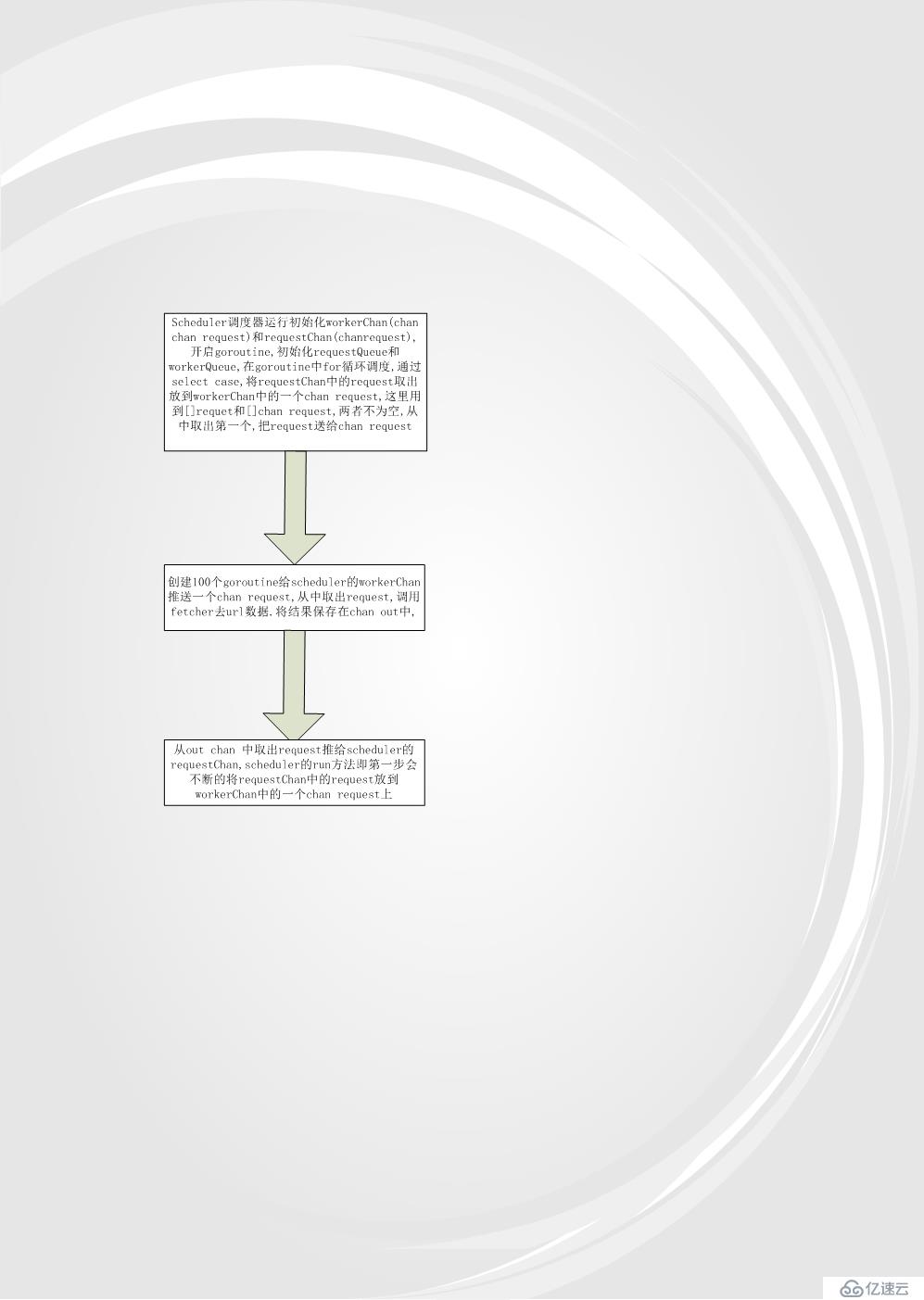
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。