您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
CharacterData类是一个抽象类,这个抽象类中定义了许多判断字符属性的抽象方法,这些方法的具体实现都在Character0X类中。其实Character类中有许多对应的方法,CharacterData子类实现抽象类的方法来实现字符属性的判断。我们并不关心这个字符由哪个具体类中的方法来判断,如果以后还增加了一些增补字符,那么只需要实现抽象类并且稍加修改of()方法即可。这就是使用策略模式的好处。
package java.lang;
abstract class CharacterData {
abstract int getProperties(int ch);
abstract int getType(int ch);
abstract boolean isWhitespace(int ch);
abstract boolean isMirrored(int ch);
abstract boolean isJavaIdentifierStart(int ch);
abstract boolean isJavaIdentifierPart(int ch);
abstract boolean isUnicodeIdentifierStart(int ch);
abstract boolean isUnicodeIdentifierPart(int ch);
abstract boolean isIdentifierIgnorable(int ch);
abstract int toLowerCase(int ch);
abstract int toUpperCase(int ch);
abstract int toTitleCase(int ch);
abstract int digit(int ch, int radix);
abstract int getNumericValue(int ch);
abstract byte getDirectionality(int ch);
//need to implement for JSR204
int toUpperCaseEx(int ch) {
return toUpperCase(ch);
}
char[] toUpperCaseCharArray(int ch) {
return null;
}
boolean isOtherLowercase(int ch) {
return false;
}
boolean isOtherUppercase(int ch) {
return false;
}
boolean isOtherAlphabetic(int ch) {
return false;
}
boolean isIdeographic(int ch) {
return false;
}
// Character <= 0xff (basic latin) is handled by internal fast-path
// to avoid initializing large tables.
// Note: performance of this "fast-path" code may be sub-optimal
// in negative cases for some accessors due to complicated ranges.
// Should revisit after optimization of table initialization.
static final CharacterData of(int ch) {
if (ch >>> 8 == 0) { // fast-path
return CharacterDataLatin1.instance;
} else {
switch(ch >>> 16) { //plane 00-16
case(0):
return CharacterData00.instance;
case(1):
return CharacterData01.instance;
case(2):
return CharacterData02.instance;
case(14):
return CharacterData0E.instance;
case(15): // Private Use
case(16): // Private Use
return CharacterDataPrivateUse.instance;
default:
return CharacterDataUndefined.instance;
}
}
}}
那么Java是怎么判断这些字符的属性的呢?其实每一个Java字符都用一个32位,也就是4个字节来表示这个属性。
举例说明:
当我们传入一个'0'字符时,实际上通过static final CharacterData of(int ch),'0'对应ASCII码为48,方法判断后,最终会调用CharacterDataLatin1类中对应的方法去处理。
CharacterDataLatin1源码:
package java.lang;
/* The CharacterData class encapsulates the large tables found in
Java.lang.Character. /
class CharacterDataLatin1 extends CharacterData {
/* The character properties are currently encoded into 32 bits in the following manner:
1 bit mirrored property
4 bits directionality property
9 bits signed offset used for converting case
1 bit if 1, adding the signed offset converts the character to lowercase
1 bit if 1, subtracting the signed offset converts the character to uppercase
1 bit if 1, this character has a titlecase equivalent (possibly itself)
3 bits 0 may not be part of an identifier
1 ignorable control; may continue a Unicode identifier or Java identifier
2 may continue a Java identifier but not a Unicode identifier (unused)
3 may continue a Unicode identifier or Java identifier
4 is a Java whitespace character
5 may start or continue a Java identifier;
may continue but not start a Unicode identifier (underscores)
6 may start or continue a Java identifier but not a Unicode identifier ($)
7 may start or continue a Unicode identifier or Java identifier
Thus:
5, 6, 7 may start a Java identifier
1, 2, 3, 5, 6, 7 may continue a Java identifier
7 may start a Unicode identifier
1, 3, 5, 7 may continue a Unicode identifier
1 is ignorable within an identifier
4 is Java whitespace
2 bits 0 this character has no numeric property
1 adding the digit offset to the character code and then
masking with 0x1F will produce the desired numeric value
2 this character has a "strange" numeric value
3 a Java supradecimal digit: adding the digit offset to the
character code, then masking with 0x1F, then adding 10
will produce the desired numeric value
5 bits digit offset
5 bits character type
The encoding of character properties is subject to change at any time.
*/
int getProperties(int ch) {
char offset = (char)ch;
int props = A[offset];
return props;
}
int getPropertiesEx(int ch) {
char offset = (char)ch;
int props = B[offset];
return props;
}
boolean isOtherLowercase(int ch) {
int props = getPropertiesEx(ch);
return (props & 0x0001) != 0;
}
boolean isOtherUppercase(int ch) {
int props = getPropertiesEx(ch);
return (props & 0x0002) != 0;
}
boolean isOtherAlphabetic(int ch) {
int props = getPropertiesEx(ch);
return (props & 0x0004) != 0;
}
boolean isIdeographic(int ch) {
int props = getPropertiesEx(ch);
return (props & 0x0010) != 0;
}
int getType(int ch) {
int props = getProperties(ch);
return (props & 0x1F);
}
boolean isJavaIdentifierStart(int ch) {
int props = getProperties(ch);
return ((props & 0x00007000) >= 0x00005000);
}
boolean isJavaIdentifierPart(int ch) {
int props = getProperties(ch);
return ((props & 0x00003000) != 0);
}
boolean isUnicodeIdentifierStart(int ch) {
int props = getProperties(ch);
return ((props & 0x00007000) == 0x00007000);
}
boolean isUnicodeIdentifierPart(int ch) {
int props = getProperties(ch);
return ((props & 0x00001000) != 0);
}
boolean isIdentifierIgnorable(int ch) {
int props = getProperties(ch);
return ((props & 0x00007000) == 0x00001000);
}
int toLowerCase(int ch) {
int mapChar = ch;
int val = getProperties(ch);
if (((val & 0x00020000) != 0) &&
((val & 0x07FC0000) != 0x07FC0000)) {
int offset = val << 5 >> (5+18);
mapChar = ch + offset;
}
return mapChar;
}
int toUpperCase(int ch) {
int mapChar = ch;
int val = getProperties(ch);
if ((val & 0x00010000) != 0) {
if ((val & 0x07FC0000) != 0x07FC0000) {
int offset = val << 5 >> (5+18);
mapChar = ch - offset;
} else if (ch == 0x00B5) {
mapChar = 0x039C;
}
}
return mapChar;
}
int toTitleCase(int ch) {
return toUpperCase(ch);
}
int digit(int ch, int radix) {
int value = -1;
if (radix >= Character.MIN_RADIX && radix <= Character.MAX_RADIX) {
int val = getProperties(ch);
int kind = val & 0x1F;
if (kind == Character.DECIMAL_DIGIT_NUMBER) {
value = ch + ((val & 0x3E0) >> 5) & 0x1F;
}
else if ((val & 0xC00) == 0x00000C00) {
// Java supradecimal digit
value = (ch + ((val & 0x3E0) >> 5) & 0x1F) + 10;
}
}
return (value < radix) ? value : -1;
}
int getNumericValue(int ch) {
int val = getProperties(ch);
int retval = -1;
switch (val & 0xC00) {
default: // cannot occur
case (0x00000000): // not numeric
retval = -1;
break;
case (0x00000400): // simple numeric
retval = ch + ((val & 0x3E0) >> 5) & 0x1F;
break;
case (0x00000800) : // "strange" numeric
retval = -2;
break;
case (0x00000C00): // Java supradecimal
retval = (ch + ((val & 0x3E0) >> 5) & 0x1F) + 10;
break;
}
return retval;
}
boolean isWhitespace(int ch) {
int props = getProperties(ch);
return ((props & 0x00007000) == 0x00004000);
}
byte getDirectionality(int ch) {
int val = getProperties(ch);
byte directionality = (byte)((val & 0x78000000) >> 27);
if (directionality == 0xF ) {
directionality = -1;
}
return directionality;
}
boolean isMirrored(int ch) {
int props = getProperties(ch);
return ((props & 0x80000000) != 0);
}
int toUpperCaseEx(int ch) {
int mapChar = ch;
int val = getProperties(ch);
if ((val & 0x00010000) != 0) {
if ((val & 0x07FC0000) != 0x07FC0000) {
int offset = val << 5 >> (5+18);
mapChar = ch - offset;
}
else {
switch(ch) {
// map overflow characters
case 0x00B5 : mapChar = 0x039C; break;
default : mapChar = Character.ERROR; break;
}
}
}
return mapChar;
}
static char[] sharpsMap = new char[] {'S', 'S'};
char[] toUpperCaseCharArray(int ch) {
char[] upperMap = {(char)ch};
if (ch == 0x00DF) {
upperMap = sharpsMap;
}
return upperMap;
}
static final CharacterDataLatin1 instance = new CharacterDataLatin1();
private CharacterDataLatin1() {};
// The following tables and code generated using:// java GenerateCharacter -template ../../tools/GenerateCharacter/CharacterDataLatin1.java.template -spec ../../tools/UnicodeData/UnicodeData.txt -specialcasing ../../tools/UnicodeData/SpecialCasing.txt -proplist ../../tools/UnicodeData/PropList.txt -o C:/re/jdk7u80/2329/build/windows-amd64/gensrc/java/lang/CharacterDataLatin1.java -string -usecharforbyte -latin1 8
// The A table has 256 entries for a total of 1024 bytes.
static final int A[] = new int[256];
static final String A_DATA =
"\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800"+
"\u100F\u4800\u100F\u4800\u100F\u5800\u400F\u5000\u400F\u5800\u400F\u6000\u400F"+
"\u5000\u400F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800"+
"\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F"+
"\u4800\u100F\u4800\u100F\u5000\u400F\u5000\u400F\u5000\u400F\u5800\u400F\u6000"+
"\u400C\u6800\030\u6800\030\u2800\030\u2800\u601A\u2800\030\u6800\030\u6800"+
"\030\uE800\025\uE800\026\u6800\030\u2000\031\u3800\030\u2000\024\u3800\030"+
"\u3800\030\u1800\u3609\u1800\u3609\u1800\u3609\u1800\u3609\u1800\u3609\u1800"+
"\u3609\u1800\u3609\u1800\u3609\u1800\u3609\u1800\u3609\u3800\030\u6800\030"+
"\uE800\031\u6800\031\uE800\031\u6800\030\u6800\030\202\u7FE1\202\u7FE1\202"+
"\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1"+
"\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202"+
"\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1\202\u7FE1"+
"\202\u7FE1\uE800\025\u6800\030\uE800\026\u6800\033\u6800\u5017\u6800\033\201"+
"\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2"+
"\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201"+
"\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2\201\u7FE2"+
"\201\u7FE2\201\u7FE2\201\u7FE2\uE800\025\u6800\031\uE800\026\u6800\031\u4800"+
"\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u5000\u100F"+
"\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800"+
"\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F"+
"\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800"+
"\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F\u4800\u100F"+
"\u3800\014\u6800\030\u2800\u601A\u2800\u601A\u2800\u601A\u2800\u601A\u6800"+
"\034\u6800\034\u6800\033\u6800\034\000\u7002\uE800\035\u6800\031\u4800\u1010"+
"\u6800\034\u6800\033\u2800\034\u2800\031\u1800\u060B\u1800\u060B\u6800\033"+
"\u07FD\u7002\u6800\034\u6800\030\u6800\033\u1800\u050B\000\u7002\uE800\036"+
"\u6800\u080B\u6800\u080B\u6800\u080B\u6800\030\202\u7001\202\u7001\202\u7001"+
"\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001\202"+
"\u7001\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001"+
"\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001\u6800\031\202\u7001\202"+
"\u7001\202\u7001\202\u7001\202\u7001\202\u7001\202\u7001\u07FD\u7002\201\u7002"+
"\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201"+
"\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002"+
"\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\u6800"+
"\031\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002\201\u7002"+
"\u061D\u7002";
// The B table has 256 entries for a total of 512 bytes.
static final char B[] = (
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"+
"\000\000\000\000\000\000\000\000\000").toCharArray();
// In all, the character property tables require 1024 bytes.
static {
{ // THIS CODE WAS AUTOMATICALLY CREATED BY GenerateCharacter:
char[] data = A_DATA.toCharArray();
assert (data.length == (256 * 2));
int i = 0, j = 0;
while (i < (256 * 2)) {
int entry = data[i++] << 16;
A[j++] = entry | data[i++];
}
}
} }
说一下Latin1编码,Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。
ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在ISO-8859-1当中。
因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,MySQL数据库默认编码是Latin1就是利用了这个特性。ASCII编码是一个7位的容器,ISO-8859-1编码是一个8位的容器。
回到我们的源代码中,可以看到最终A[]中存储了256个整数,就是使用有4个字节,32bits来存储的数,但是不能将这256个数当作一个整数来看待,没有任何的意义,需要读取32个比特位中特定的位的值,因为他代表着字符的属性。举个例子:ASCII表中的49代表'0'字符,获取这个字符对应的属性值为A[49],转换后的二进制值如下:
0- 0011-000 000000-0-0 0-011-01-10 000-01001
1位:0表示没有mirrored property,如果是'(','[',这些字符,这个位置的值为1
4位:3
9位:无偏移
1位:无小写
1位:无大写
1位:无首字母大写属性
3位:3 表示是一个合法的Unicode标识符或Java标识符
2位:1 有数字的属性
5位:数字移位为0
5位:字符类型代表的值为9
既然能够得到每个字符的代表属性的整数,接下来当然就是编写方法取出特定二进制位上的值了。如要查看一个字符的类型,而这个类型由二进制位的最后5位表示,取出后5位的方法如下:
int getPropertiesEx(int ch) {
char offset = (char)ch;
int props = B[offset];
return props;
}
int getType(int ch) {
int props = getProperties(ch);
return (props & 0x1F);
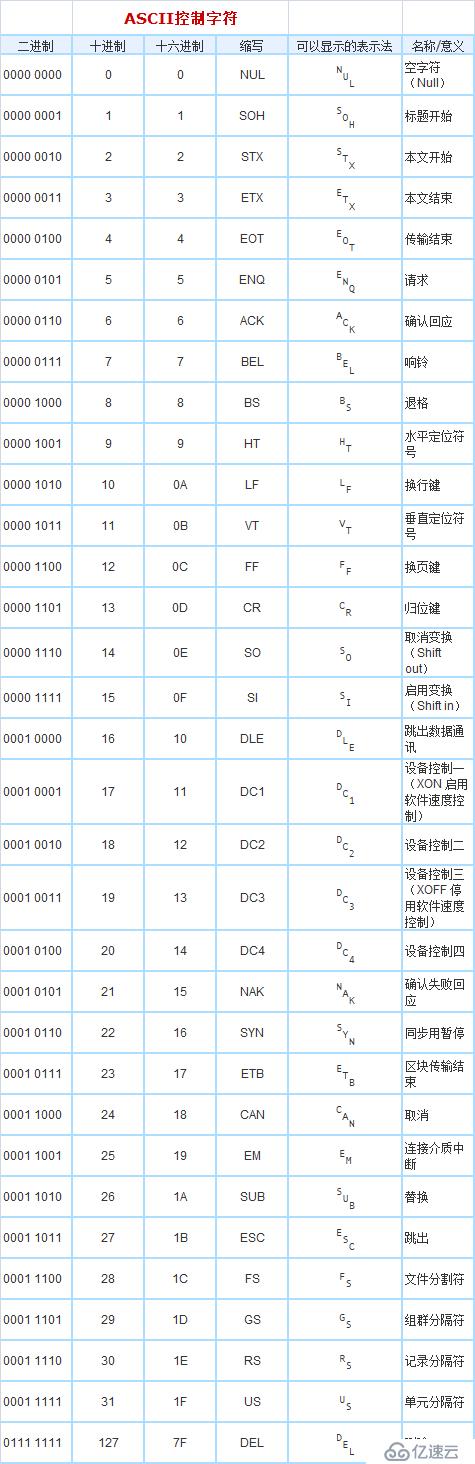
}附件:ASCII表

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。