жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
з”ұдәҺзј“еӯҳзҡ„иҜ»еҸ–йҖҹеәҰжҜ”йқһзј“еӯҳиҰҒеҝ«дёҠеҫҲеӨҡпјҢжүҖд»ҘеңЁй«ҳжҖ§иғҪеңәжҷҜдёӢпјҢзі»з»ҹеңЁиҜ»еҸ–ж•°жҚ®ж—¶пјҢжҳҜйҰ–е…Ҳд»Һзј“еӯҳдёӯжҹҘжүҫйңҖиҰҒзҡ„ж•°жҚ®пјҢеҰӮжһңжүҫеҲ°дәҶеҲҷзӣҙжҺҘиҜ»еҸ–з»“жһңпјҢеҰӮжһңжүҫдёҚеҲ°зҡ„иҜқпјҢеҲҷд»ҺеҶ…еӯҳжҲ–иҖ…зЎ¬зӣҳдёӯжҹҘжүҫпјҢеҶҚе°ҶжҹҘжүҫеҲ°зҡ„з»“жһңеӯҳе…Ҙзј“еӯҳпјҢд»ҘеӨҮдёӢж¬ЎдҪҝз”ЁгҖӮ
е®һйҷ…дёҠпјҢеҜ№дәҺдёҖдёӘзі»з»ҹжқҘиҜҙпјҢзј“еӯҳзҡ„з©әй—ҙжҳҜжңүйҷҗдё”е®қиҙөзҡ„пјҢжҲ‘们дёҚеҸҜиғҪе°ҶжүҖжңүзҡ„ж•°жҚ®йғҪж”ҫе…Ҙзј“еӯҳдёӯиҝӣиЎҢж“ҚдҪңпјҢеҚідҫҝеҸҜд»Ҙж•°жҚ®е®үе…ЁжҖ§д№ҹеҫ—дёҚеҲ°дҝқиҜҒпјҢиҖҢдё”пјҢеҰӮжһңзј“еӯҳзҡ„ж•°жҚ®йҮҸиҝҮеӨ§еӨ§пјҢе…¶йҖҹеәҰд№ҹдјҡеҸҳеҫ—и¶ҠжқҘи¶Ҡж…ўгҖӮ иҝҷдёӘж—¶еҖҷе°ұйңҖиҰҒиҖғиҷ‘зј“еӯҳзҡ„ж·ҳжұ°жңәеҲ¶пјҢдҪҶжҳҜж·ҳжұ°е“Әдәӣж•°жҚ®пјҢеҸҲдҝқз•ҷе“Әдәӣж•°жҚ®пјҢиҝҷжҳҜдёҖдёӘй—®йўҳгҖӮеҰӮжһңеӨ„зҗҶдёҚеҫ—еҪ“пјҢе°ұдјҡйҖ жҲҗвҖңзј“еӯҳжұЎжҹ“вҖқй—®йўҳгҖӮ
иҖҢзј“еӯҳжұЎжҹ“пјҢжҳҜжҢҮзі»з»ҹе°ҶдёҚеёёз”Ёзҡ„ж•°жҚ®д»ҺеҶ…еӯҳ移еҲ°зј“еӯҳпјҢйҖ жҲҗеёёз”Ёж•°жҚ®зҡ„жҢӨеҮәпјҢйҷҚдҪҺдәҶзј“еӯҳж•ҲзҺҮзҡ„зҺ°иұЎгҖӮ
LFUпјҢиӢұж–ҮеҗҚLeast Frequently UsedпјҢеӯ—йқўж„ҸжҖқе°ұжҳҜжңҖдёҚз»ҸеёёдҪҝз”Ёзҡ„ж·ҳжұ°жҺүз®—жі•пјҢжҳҜйҖҡиҝҮж•°жҚ®иў«и®ҝй—®зҡ„йў‘зҺҮжқҘеҲӨж–ӯдёҖдёӘж•°жҚ®зҡ„зғӯзӮ№жғ…еҶөгҖӮе…¶ж ёеҝғзҗҶеҝөжҳҜвҖңеҺҶеҸІдёҠиҝҷдёӘж•°жҚ®иў«и®ҝй—®ж¬Ўж•°и¶ҠеӨҡпјҢйӮЈд№Ҳе°ҶжқҘе…¶иў«и®ҝй—®зҡ„ж¬Ўж•°д№ҹеӨҡвҖқгҖӮ
LFUдёӯжҜҸдёӘж•°жҚ®еқ—йғҪжңүдёҖдёӘеј•з”Ёи®Ўж•°еҷЁпјҢжүҖжңүж•°жҚ®еқ—жҢүз…§еј•з”Ёж•°д»ҺеӨ§еҲ°е°Ҹзҡ„жҺ’еәҸгҖӮ
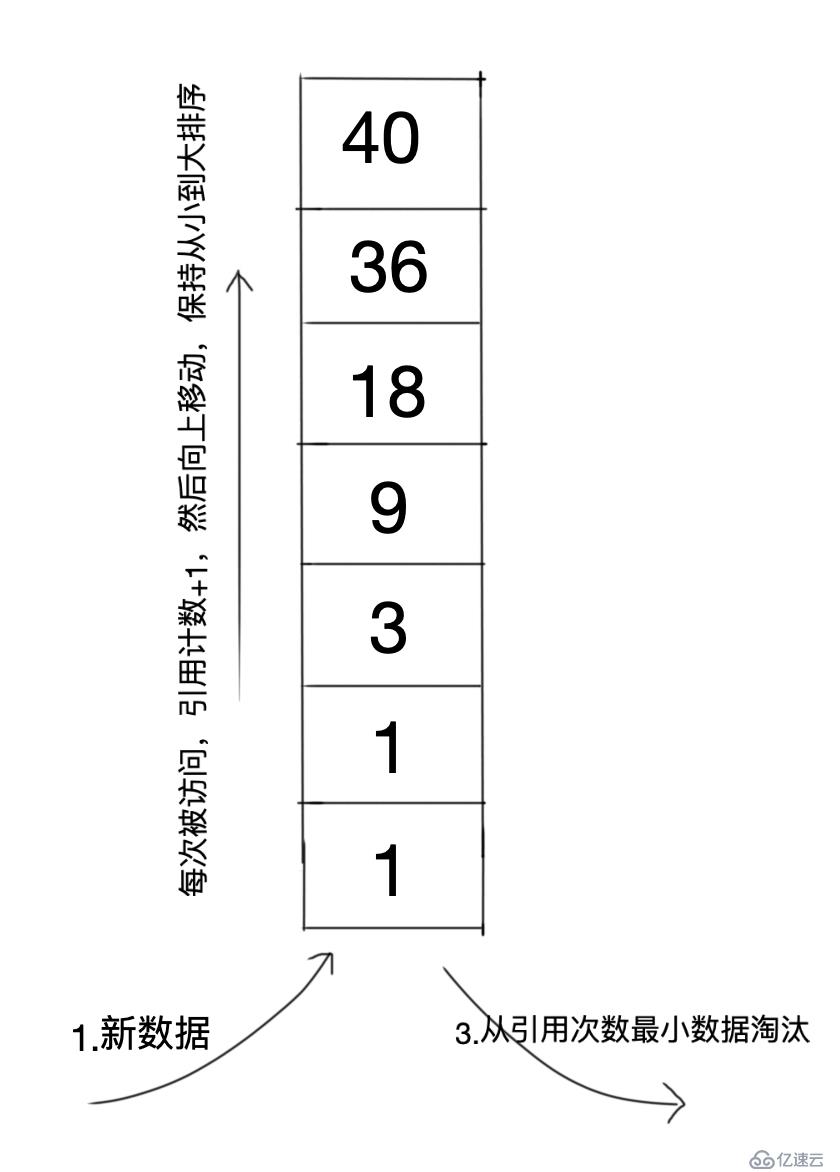
жӯҘйӘӨпјҡ
ж–°ж•°жҚ®жҸ’е…ҘеҲ°е°ҫйғЁпјҢ并е°Ҷи®Ўж•°и®ҫзҪ®дёә1пјӣ
еҪ“йҳҹеҲ—дёӯзҡ„ж•°жҚ®иў«и®ҝй—®еҗҺпјҢеј•з”Ёи®Ўж•°+1пјҢ然еҗҺйҮҚж–°жҺ’еәҸпјҢдҝқжҢҒеј•з”Ёж¬Ўж•°д»ҺеӨ§еҲ°е°ҸжҺ’еәҸпјӣ
еҪ“з©әй—ҙдёҚи¶іпјҢйңҖиҰҒж·ҳжұ°ж•°жҚ®ж—¶пјҢе°Ҷе°ҫйғЁеј•з”Ёи®Ўж•°жңҖе°Ҹзҡ„ж•°жҚ®еқ—еҲ йҷӨгҖӮ
еҲҶжһҗпјҡз”ұдәҺжҳҜж №жҚ®йў‘ж•°иҝӣиЎҢзғӯзӮ№еҲӨж–ӯе’Ңж·ҳжұ°пјҢжүҖд»Ҙе…ҲеӨ©е…·еӨҮйҒҝе…ҚеҒ¶еҸ‘жҖ§гҖҒе‘ЁжңҹжҖ§жү№йҮҸж“ҚдҪңеҜјиҮҙдёҙж—¶йқһзғӯзӮ№ж•°жҚ®еӨ§йҮҸж¶Ңе…Ҙзј“еӯҳпјҢжҢӨеҮәзғӯзӮ№ж•°жҚ®зҡ„й—®йўҳгҖӮ иҷҪ然具еӨҮиҝҷз§Қе…ҲеӨ©дјҳеҠҝпјҢдҪҶдҫқж—§еӯҳеңЁеҸҰдёҖз§Қзј“еӯҳжұЎжҹ“й—®йўҳпјҢеҚіеҺҶеҸІзғӯзӮ№ж•°жҚ®жұЎжҹ“еҪ“еүҚзғӯзӮ№ж•°жҚ®пјҢеҰӮжһңзі»з»ҹи®ҝй—®жЁЎејҸеҸ‘з”ҹдәҶж”№еҸҳпјҢж–°зҡ„зғӯзӮ№ж•°жҚ®йңҖиҰҒи®Ўж•°зҙҜеҠ и¶…иҝҮж—§зғӯзӮ№ж•°жҚ®пјҢжүҚиғҪе°Ҷж—§зғӯзӮ№ж•°жҚ®иҝӣиЎҢж·ҳжұ°пјҢйҖ жҲҗзғӯзӮ№ж•Ҳеә”ж»һеҗҺзҡ„й—®йўҳгҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡжҜҸж¬Ўж“ҚдҪңйғҪйңҖиҰҒиҝӣиЎҢи®Ўж•°е’ҢжҺ’еәҸпјҢ并且йңҖиҰҒз»ҙжҠӨжҜҸдёӘж•°жҚ®еқ—и®Ўж•°жғ…еҶөпјҢдјҡеҚ з”Ёиҫғй«ҳзҡ„еҶ…еӯҳдёҺcpuгҖӮ
дёҖдёӘе°ҸжҖқиҖғпјҢж №жҚ®LFUз®—жі•пјҢеҰӮдҪ•д»ҘO(1)ж—¶й—ҙеӨҚжқӮеәҰе®һзҺ°getе’Ңputж“ҚдҪңзј“еӯҳпјҹ
LFU-AgingжҳҜеҹәдәҺLFUзҡ„ж”№иҝӣз®—жі•пјҢзӣ®зҡ„жҳҜи§ЈеҶіеҺҶеҸІзғӯзӮ№ж•°жҚ®еҜ№еҪ“еүҚзғӯзӮ№ж•°жҚ®зҡ„жұЎжҹ“й—®йўҳгҖӮжңүдәӣж•°жҚ®еңЁејҖе§Ӣж—¶дҪҝз”Ёж¬Ўж•°еҫҲеӨҡпјҢдҪҶд»ҘеҗҺе°ұдёҚеҶҚдҪҝз”ЁпјҢиҝҷзұ»ж•°жҚ®е°Ҷдјҡй•ҝж—¶й—ҙз•ҷеңЁзј“еӯҳдёӯпјҢжүҖд»ҘвҖңйҷӨдәҶи®ҝй—®ж¬Ўж•°еӨ–пјҢиҝҳиҰҒиҖғиҷ‘и®ҝй—®ж—¶й—ҙвҖқпјҢиҝҷд№ҹжҳҜLFU-Agingзҡ„ж ёеҝғзҗҶеҝөгҖӮ
иҷҪ然算法е°Ҷж—¶й—ҙзәіе…ҘдәҶиҖғйҮҸиҢғеӣҙпјҢдҪҶLFU-Aging并дёҚжҳҜзӣҙжҺҘи®°еҪ•ж•°жҚ®зҡ„и®ҝй—®ж—¶й—ҙпјҢиҖҢжҳҜеўһеҠ дәҶдёҖдёӘжңҖеӨ§е№іеқҮеј•з”Ёи®Ўж•°зҡ„йҳҲеҖјпјҢ然еҗҺйҖҡиҝҮеҪ“еүҚе№іеқҮеј•з”Ёи®Ўж•°жқҘж ҮиҜҶж—¶й—ҙпјҢжҚўеҸҘиҜқиҜҙпјҢе°ұжҳҜе°ҶеҪ“еүҚзј“еӯҳдёӯзҡ„е№іеқҮеј•з”Ёи®Ўж•°еҖјеҪ“дҪңеҪ“еүҚзҡ„з”ҹе‘Ҫе№ҙд»ЈпјҢеҪ“иҝҷдёӘз”ҹе‘Ҫе№ҙд»Ји¶…иҝҮдәҶйў„и®ҫзҡ„йҳҲеҖјпјҢе°ұдјҡе°ҶеҪ“еүҚжүҖжңүи®Ўж•°еҖјеҮҸеҚҠпјҢеҪўжҲҗжҢҮж•°иЎ°еҸҳзҡ„з”ҹе‘Ҫе№ҙд»ЈгҖӮ
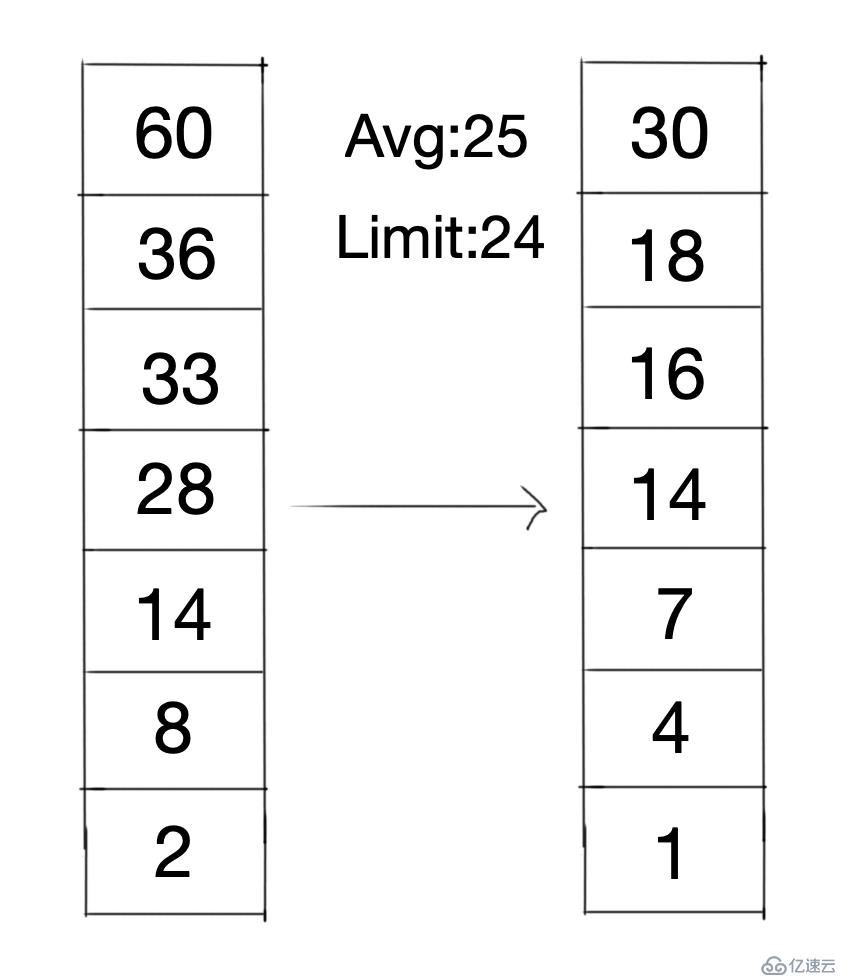
еҲҶжһҗпјҡдјҳзӮ№жҳҜеҪ“и®ҝй—®жЁЎејҸеҸ‘з”ҹж”№еҸҳзҡ„ж—¶еҖҷпјҢз”ҹе‘Ҫе№ҙд»Јзҡ„жҢҮж•°иЎ°еҸҳдјҡдҪҝLFU-AgingиғҪеӨҹжӣҙеҝ«зҡ„йҖӮз”Ёж–°зҡ„ж•°жҚ®и®ҝй—®жЁЎејҸпјҢж·ҳжұ°ж—§зҡ„зғӯзӮ№ж•°жҚ®гҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡеңЁLFUзҡ„еҹәзЎҖдёҠеҸҲеўһеҠ е№іеқҮеј•з”Ёж¬Ўж•°еҲӨж–ӯе’Ңз»ҹи®ЎеӨ„зҗҶпјҢеҜ№cpuзҡ„ж¶ҲиҖ—жӣҙй«ҳпјҢ并且еҪ“е№іеқҮеј•з”Ёж¬Ўж•°и¶…иҝҮжҢҮе®ҡйҳҲеҖјпјҲAgingпјүеҗҺпјҢиҝҳйңҖиҰҒйҒҚеҺҶжҜҸдёҖдёӘж•°жҚ®еқ—зҡ„еј•з”Ёи®Ўж•°пјҢиҝӣиЎҢжҢҮж•°иЎ°еҸҳгҖӮ
Window-LFUйЎҫеҗҚжҖқд№үеҸ«еҒҡзӘ—еҸЈжңҹLFUпјҢеҢәеҲ«дәҺеҺҹд№үLFUдёӯи®°еҪ•жүҖжңүж•°жҚ®зҡ„и®ҝй—®еҺҶеҸІпјҢWindow-LFUеҸӘи®°еҪ•иҝҮеҺ»дёҖж®өж—¶й—ҙеҶ…пјҲзӘ—еҸЈжңҹпјүзҡ„и®ҝй—®еҺҶеҸІпјҢзӣёеҪ“дәҺз»ҷзј“еӯҳи®ҫзҪ®дәҶжңүж•ҲжңҹйҷҗпјҢиҝҮжңҹж•°жҚ®дёҚеҶҚзј“еӯҳгҖӮеҪ“йңҖиҰҒж·ҳжұ°ж—¶пјҢе°ҶиҝҷдёӘзӘ—еҸЈжңҹеҶ…зҡ„ж•°жҚ®жҢүз…§LFUз®—жі•иҝӣиЎҢж·ҳжұ°гҖӮ
еҲҶжһҗпјҡз”ұдәҺжҳҜз»ҙжҠӨдёҖж®өзӘ—еҸЈжңҹзҡ„и®°еҪ•пјҢж•°жҚ®йҮҸдјҡжҜ”иҫғе°‘пјҢжүҖд»ҘеҶ…еӯҳеҚ з”Ёе’Ңcpuж¶ҲиҖ—йғҪжҜ”LFUиҰҒдҪҺгҖӮ并且иҝҷж®өзӘ—еҸЈжңҹзӣёеҪ“дәҺз»ҷзј“еӯҳи®ҫзҪ®дәҶжңүж•ҲжңҹпјҢиғҪеӨҹжӣҙеҝ«зҡ„йҖӮеә”ж–°зҡ„и®ҝй—®жЁЎејҸзҡ„еҸҳеҢ–пјҢзј“еӯҳжұЎжҹ“й—®йўҳеҹәжң¬дёҚдёҘйҮҚгҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡз»ҙжҠӨдёҖж®өж—¶жңҹеҶ…зҡ„ж•°жҚ®и®ҝй—®и®°еҪ•пјҢ并еҜ№е…¶жҺ’еәҸгҖӮ
LRUз®—жі•пјҢиӢұж–ҮеҗҚLeast Recently UsedпјҢж„ҸжҖқжҳҜжңҖиҝ‘жңҖе°‘дҪҝз”Ёзҡ„ж·ҳжұ°з®—жі•пјҢж №жҚ®ж•°жҚ®зҡ„еҺҶеҸІи®ҝй—®и®°еҪ•жқҘиҝӣиЎҢж·ҳжұ°ж•°жҚ®пјҢж ёеҝғжҖқжғіжҳҜвҖңеҰӮжһңж•°жҚ®жңҖиҝ‘иў«и®ҝй—®иҝҮ1ж¬ЎпјҢйӮЈд№Ҳе°ҶжқҘиў«и®ҝй—®зҡ„жҰӮзҺҮдјҡжӣҙй«ҳвҖқпјҢзұ»дјјдәҺе°ұиҝ‘дјҳе…ҲеҺҹеҲҷгҖӮ
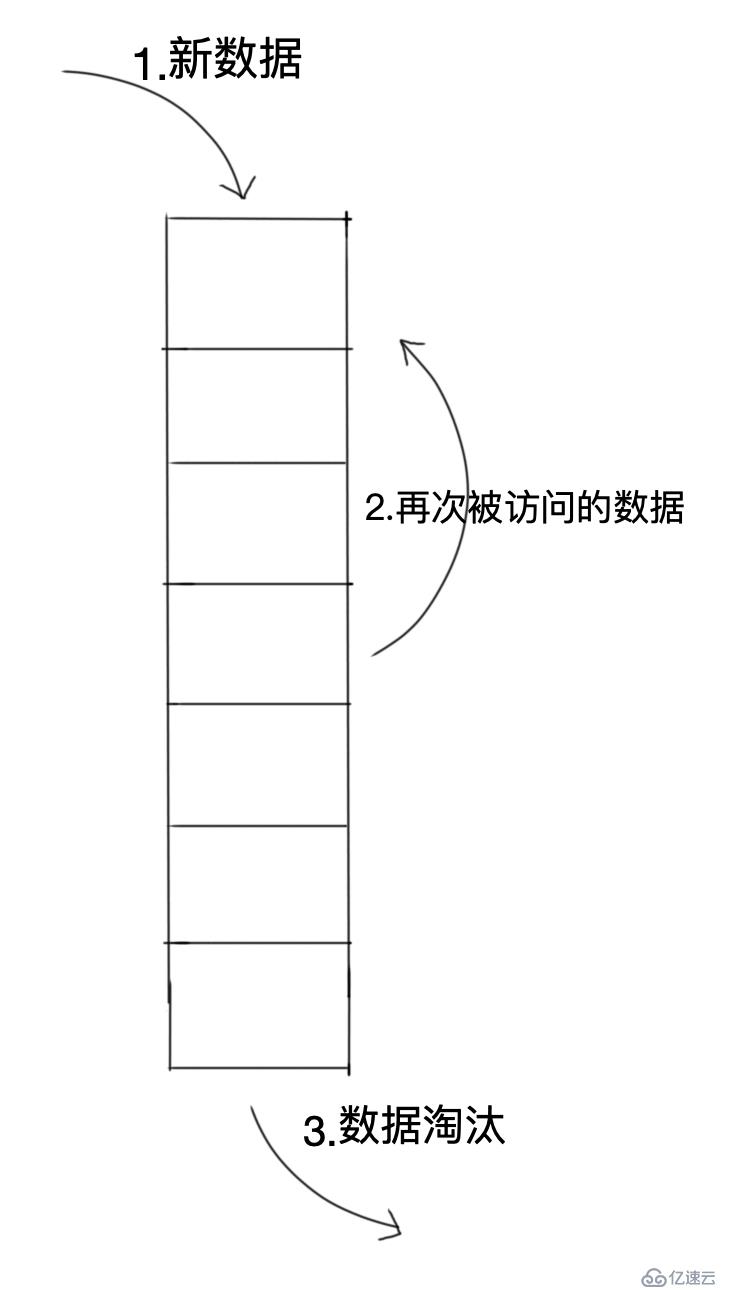
жӯҘйӘӨпјҡ
ж–°ж•°жҚ®жҸ’е…ҘеҲ°й“ҫиЎЁеӨҙйғЁпјӣ
жҜҸеҪ“е‘Ҫдёӯзј“еӯҳпјҢдҫҝе°Ҷе‘Ҫдёӯзҡ„зј“еӯҳж•°жҚ®з§»еҲ°й“ҫиЎЁеӨҙйғЁпјӣ
еҪ“й“ҫиЎЁж»Ўзҡ„ж—¶еҖҷпјҢе°Ҷй“ҫиЎЁе°ҫйғЁзҡ„ж•°жҚ®дёўејғгҖӮ
еҲҶжһҗпјҡеҒ¶еҸ‘жҖ§зҡ„гҖҒе‘ЁжңҹжҖ§зҡ„жү№йҮҸж“ҚдҪңдјҡдҪҝдёҙж—¶ж•°жҚ®ж¶Ңе…Ҙзј“еӯҳпјҢжҢӨеҮәзғӯзӮ№ж•°жҚ®пјҢеҜјиҮҙLRUзғӯзӮ№е‘ҪдёӯзҺҮжҖҘеү§дёӢйҷҚпјҢзј“еӯҳжұЎжҹ“жғ…еҶөжҜ”иҫғдёҘйҮҚгҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡж•°жҚ®з»“жһ„еӨҚжқӮеәҰиҫғдҪҺпјӣжҜҸж¬ЎйңҖиҰҒйҒҚеҺҶй“ҫиЎЁпјҢжүҫеҲ°е‘Ҫдёӯзҡ„ж•°жҚ®еқ—пјҢ然еҗҺе°Ҷж•°жҚ®з§»еҲ°еӨҙйғЁгҖӮ
LRU-KжҳҜеҹәдәҺLRUз®—жі•зҡ„дјҳеҢ–зүҲпјҢе…¶дёӯKд»ЈиЎЁжңҖиҝ‘и®ҝй—®зҡ„ж¬Ўж•°пјҢд»Һжҹҗз§Қж„Ҹд№үдёҠпјҢLRUеҸҜд»ҘзңӢдҪңжҳҜLRU-1з®—жі•пјҢеј•е…ҘKзҡ„ж„Ҹд№үжҳҜдёәдәҶи§ЈеҶідёҠйқўжүҖжҸҗеҲ°зҡ„зј“еӯҳжұЎжҹ“й—®йўҳгҖӮе…¶ж ёеҝғзҗҶеҝөжҳҜд»ҺвҖңж•°жҚ®жңҖиҝ‘иў«и®ҝй—®иҝҮ1ж¬ЎвҖқиң•еҸҳжҲҗвҖңж•°жҚ®жңҖиҝ‘иў«и®ҝй—®иҝҮKж¬ЎпјҢйӮЈд№Ҳе°ҶжқҘиў«и®ҝй—®зҡ„жҰӮзҺҮдјҡжӣҙй«ҳвҖқгҖӮ
LRU-KдёҺLRUеҢәеҲ«жҳҜпјҢLRU-KеӨҡдәҶдёҖдёӘж•°жҚ®и®ҝй—®еҺҶеҸІи®°еҪ•йҳҹеҲ—пјҲйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢи®ҝй—®еҺҶеҸІи®°еҪ•йҳҹеҲ—并дёҚжҳҜзј“еӯҳйҳҹеҲ—пјҢжүҖд»ҘжҳҜдёҚдҝқеӯҳж•°жҚ®жң¬иә«зҡ„пјҢеҸӘжҳҜдҝқеӯҳеҜ№ж•°жҚ®зҡ„и®ҝй—®и®°еҪ•пјҢж•°жҚ®жӯӨж—¶дҫқж—§еңЁеҺҹе§ӢеӯҳеӮЁдёӯпјүпјҢйҳҹеҲ—дёӯз»ҙжҠӨзқҖж•°жҚ®иў«и®ҝй—®зҡ„ж¬Ўж•°д»ҘеҸҠж—¶й—ҙжҲіпјҢеҸӘжңүеҪ“иҝҷдёӘж•°жҚ®иў«и®ҝй—®зҡ„ж¬Ўж•°еӨ§дәҺзӯүдәҺKеҖјж—¶пјҢжүҚдјҡд»ҺеҺҶеҸІи®°еҪ•йҳҹеҲ—дёӯеҲ йҷӨпјҢ然еҗҺжҠҠж•°жҚ®еҠ е…ҘеҲ°зј“еӯҳйҳҹеҲ—дёӯеҺ»гҖӮ
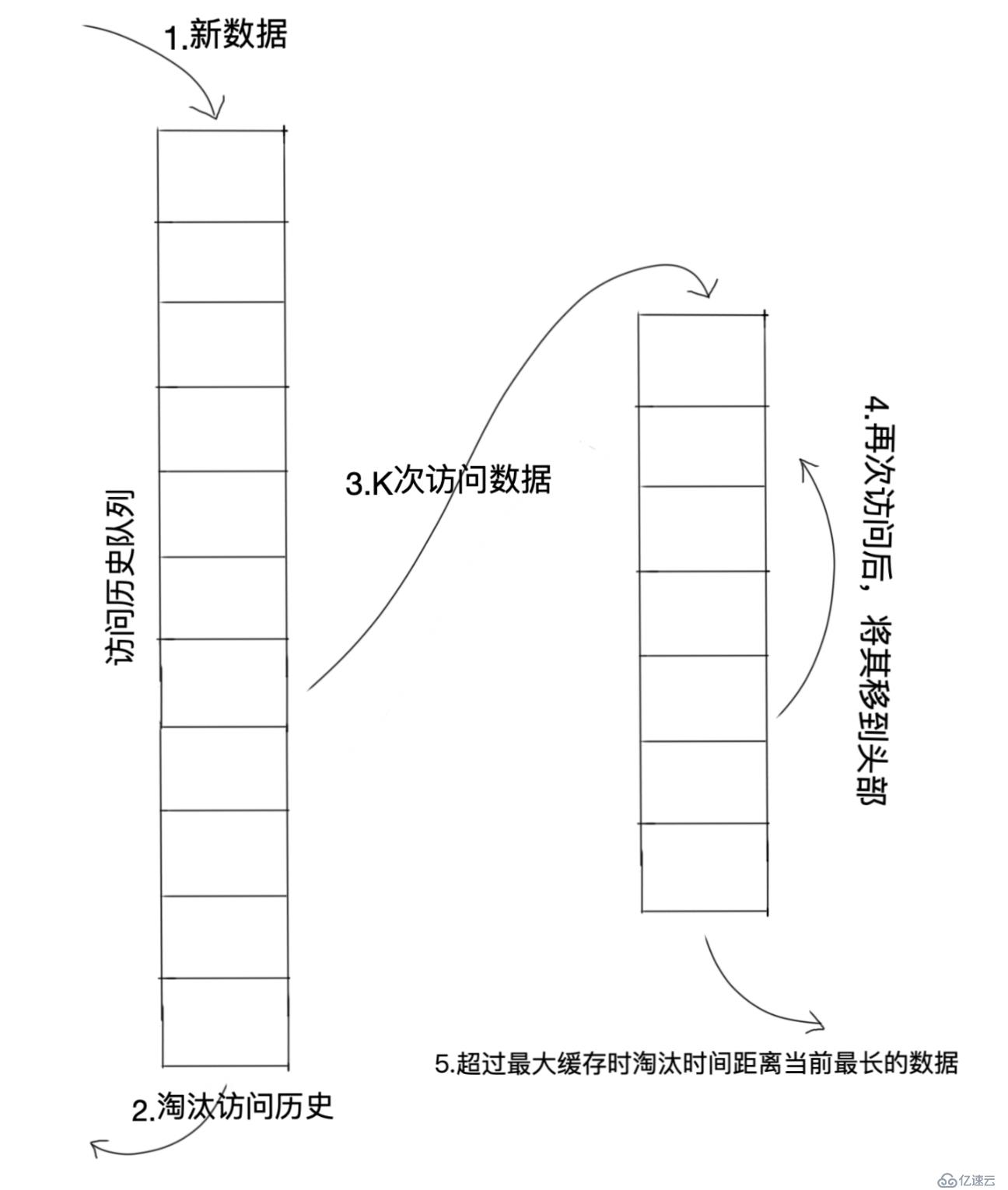
жӯҘйӘӨпјҡ
ж•°жҚ®з¬¬дёҖж¬Ўиў«и®ҝй—®ж—¶пјҢеҠ е…ҘеҲ°еҺҶеҸІи®ҝй—®и®°еҪ•йҳҹеҲ—дёӯпјҢи®ҝй—®ж¬Ўж•°дёә1пјҢеҲқе§ӢеҢ–и®ҝй—®ж—¶й—ҙжҲіпјӣ
еҰӮжһңж•°жҚ®и®ҝй—®ж¬Ўж•°жІЎжңүиҫҫеҲ°Kж¬ЎпјҢеҲҷи®ҝй—®ж¬Ўж•°+1пјҢжӣҙж–°ж—¶й—ҙжҲігҖӮеҪ“йҳҹеҲ—ж»ЎдәҶж—¶пјҢжҢүз…§жҹҗз§Қ规еҲҷпјҲLRUжҲ–иҖ…FIFOпјүе°ҶеҺҶеҸІи®°еҪ•ж·ҳжұ°гҖӮдёәдәҶйҒҝе…ҚеҺҶеҸІж•°жҚ®жұЎжҹ“жңӘжқҘж•°жҚ®зҡ„й—®йўҳпјҢиҝҳйңҖиҰҒеҠ дёҠдёҖдёӘжңүж•ҲжңҹйҷҗпјҢеҜ№и¶…иҝҮжңүж•Ҳжңҹзҡ„и®ҝй—®и®°еҪ•пјҢиҝӣиЎҢйҮҚж–°и®Ўж•°гҖӮпјҲеҸҜд»ҘдҪҝз”ЁжҮ’еӨ„зҗҶпјҢеҚіжҜҸж¬ЎеҜ№и®ҝй—®и®°еҪ•еҒҡеӨ„зҗҶж—¶пјҢе…Ҳе°Ҷи®°еҪ•дёӯзҡ„и®ҝй—®ж—¶й—ҙдёҺеҪ“еүҚж—¶й—ҙиҝӣиЎҢеҜ№жҜ”пјҢеҰӮжһңж—¶й—ҙй—ҙйҡ”и¶…иҝҮйў„и®ҫзҡ„еҖјпјҢеҲҷи®ҝй—®ж¬Ўж•°йҮҚзҪ®дёә1并жӣҙж–°ж—¶й—ҙжҲіпјҢиЎЁзӨәйҮҚж–°ејҖе§Ӣи®Ўж•°пјү
еҪ“ж•°жҚ®и®ҝй—®и®Ўж•°еӨ§дәҺзӯүдәҺKж¬ЎеҗҺпјҢе°Ҷж•°жҚ®д»ҺеҺҶеҸІи®ҝй—®йҳҹеҲ—дёӯеҲ йҷӨпјҢжӣҙж–°ж•°жҚ®ж—¶й—ҙжҲіпјҢдҝқеӯҳеҲ°зј“еӯҳйҳҹеҲ—еӨҙйғЁдёӯпјҲзј“еӯҳйҳҹеҲ—ж—¶й—ҙжҲійҖ’еҮҸжҺ’еәҸпјҢи¶ҠеҲ°е°ҫйғЁи·қзҰ»еҪ“еүҚж—¶й—ҙи¶Ҡй•ҝпјүпјӣ
зј“еӯҳйҳҹеҲ—дёӯж•°жҚ®иў«еҶҚж¬Ўи®ҝй—®еҗҺпјҢе°Ҷ其移еҲ°еӨҙйғЁпјҢ并жӣҙж–°ж—¶й—ҙжҲіпјӣ
зј“еӯҳйҳҹеҲ—йңҖиҰҒж·ҳжұ°ж•°жҚ®ж—¶пјҢж·ҳжұ°зј“еӯҳйҳҹеҲ—дёӯжҺ’еңЁжң«е°ҫзҡ„ж•°жҚ®пјҢеҚіпјҡж·ҳжұ°вҖңеҖ’数第Kж¬Ўи®ҝй—®зҰ»зҺ°еңЁжңҖд№…вҖқзҡ„ж•°жҚ®гҖӮ
еҲҶжһҗпјҡLRU-KйҷҚдҪҺдәҶвҖңзј“еӯҳжұЎжҹ“вҖқеёҰжқҘзҡ„й—®йўҳпјҢе‘ҪдёӯзҺҮжҜ”LRUиҰҒй«ҳгҖӮе®һйҷ…еә”з”ЁдёӯLRU-2жҳҜз»јеҗҲеҗ„з§Қеӣ зҙ еҗҺжңҖдјҳзҡ„йҖүжӢ©пјҢLRU-3жҲ–иҖ…жӣҙеӨ§зҡ„KеҖје‘ҪдёӯзҺҮдјҡй«ҳпјҢдҪҶйҖӮеә”жҖ§е·®пјҢдёҖж—Ұи®ҝй—®жЁЎејҸеҸ‘з”ҹеҸҳеҢ–пјҢйңҖиҰҒеӨ§йҮҸзҡ„ж–°ж•°жҚ®и®ҝй—®жүҚиғҪе°ҶеҺҶеҸІзғӯзӮ№и®ҝй—®и®°еҪ•жё…йҷӨжҺүгҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡLRU-KйҳҹеҲ—жҳҜдёҖдёӘдјҳе…Ҳзә§йҳҹеҲ—гҖӮз”ұдәҺLRU-KйңҖиҰҒи®°еҪ•йӮЈдәӣиў«и®ҝй—®иҝҮпјҢдҪҶиҝҳжІЎжңүж”ҫе…Ҙзј“еӯҳзҡ„еҜ№иұЎпјҢеҜјиҮҙеҶ…еӯҳж¶ҲиҖ—дјҡеҫҲеӨҡгҖӮ
URL-Two queuesз®—жі•зұ»дјјдәҺLRU-2пјҢдёҚеҗҢзӮ№еңЁдәҺURL-Two queuesе°ҶLRU-2з®—жі•дёӯзҡ„и®ҝй—®еҺҶеҸІйҳҹеҲ—пјҲжіЁж„ҸиҝҷдёҚжҳҜзј“еӯҳж•°жҚ®зҡ„пјүж”№дёәдёҖдёӘFIFOзј“еӯҳйҳҹеҲ—пјҢеҚіпјҡURL-Two queuesз®—жі•жңүдёӨдёӘзј“еӯҳйҳҹеҲ—пјҢдёҖдёӘжҳҜFIFOйҳҹеҲ—пјҲFirst in First outпјҢе…Ҳиҝӣе…ҲеҮәпјүпјҢдёҖдёӘжҳҜLRUйҳҹеҲ—гҖӮ
еҪ“ж•°жҚ®з¬¬дёҖж¬Ўи®ҝй—®ж—¶пјҢURL-Two queuesз®—жі•е°Ҷж•°жҚ®зј“еӯҳеңЁFIFOйҳҹеҲ—йҮҢйқўпјҢеҪ“ж•°жҚ®з¬¬дәҢж¬Ўиў«и®ҝй—®ж—¶пјҢеҲҷе°Ҷж•°жҚ®д»ҺFIFOйҳҹеҲ—移еҲ°LRUйҳҹеҲ—йҮҢйқўпјҢдёӨдёӘйҳҹеҲ—еҗ„иҮӘжҢүз…§иҮӘе·ұзҡ„ж–№жі•ж·ҳжұ°ж•°жҚ®гҖӮ
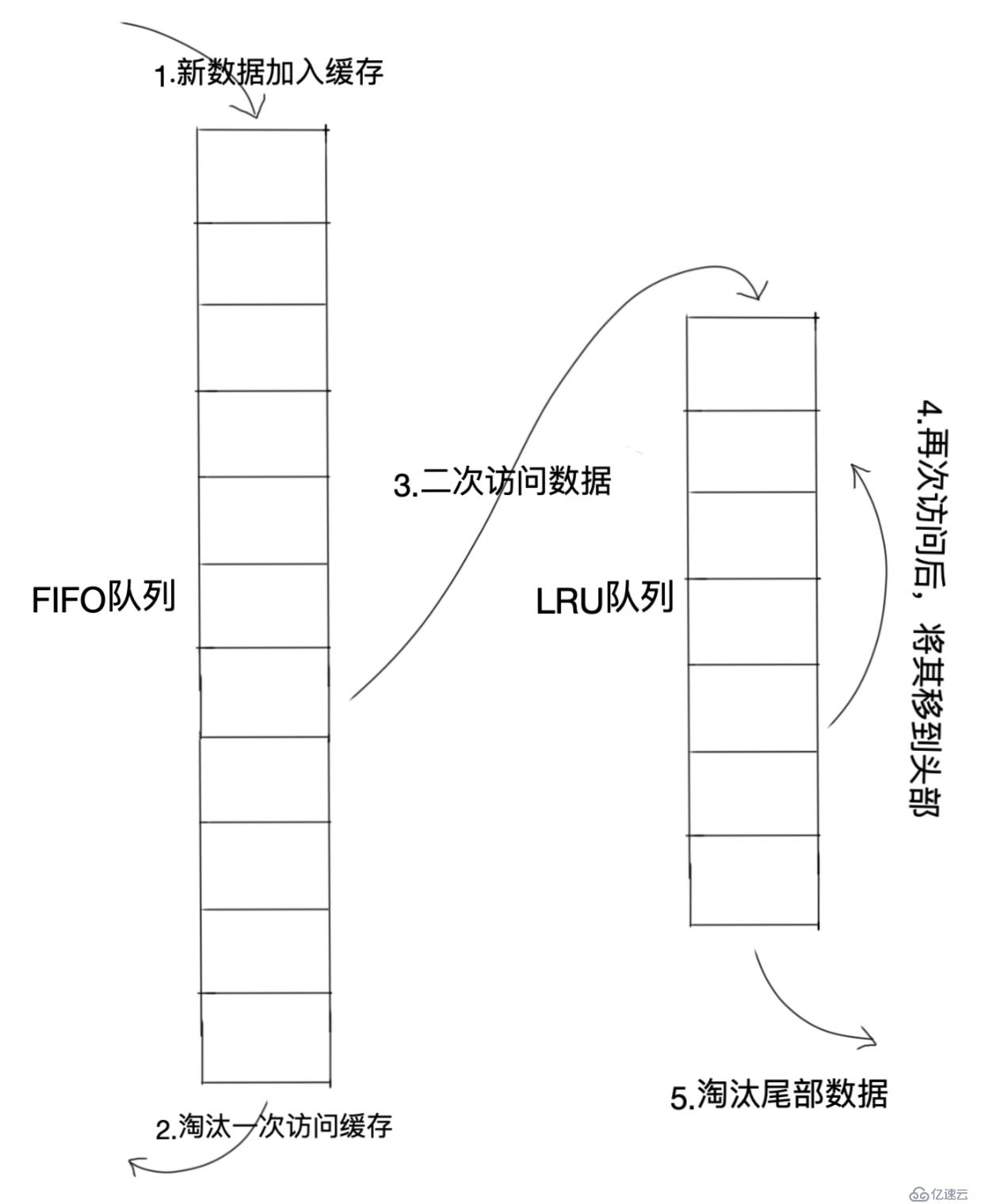
жӯҘйӘӨпјҡ
ж–°и®ҝй—®зҡ„ж•°жҚ®е…ҲжҸ’е…ҘеҲ°FIFOйҳҹеҲ—дёӯпјӣ
еҰӮжһңж•°жҚ®еңЁFIFOйҳҹеҲ—дёӯдёҖзӣҙжІЎжңүиў«еҶҚж¬Ўи®ҝй—®пјҢеҲҷжңҖз»ҲжҢүз…§FIFO规еҲҷж·ҳжұ°пјӣ
еҰӮжһңж•°жҚ®еңЁFIFOйҳҹеҲ—дёӯиў«еҶҚж¬Ўи®ҝй—®пјҢеҲҷе°Ҷж•°жҚ®д»ҺFIFOеҲ йҷӨпјҢеҠ е…ҘеҲ°LRUйҳҹеҲ—еӨҙйғЁпјӣ
еҰӮжһңж•°жҚ®еңЁLRUйҳҹеҲ—еҶҚж¬Ўиў«и®ҝй—®пјҢеҲҷе°Ҷж•°жҚ®з§»еҲ°LRUйҳҹеҲ—еӨҙйғЁпјӣ
LRUйҳҹеҲ—ж·ҳжұ°жң«е°ҫзҡ„ж•°жҚ®гҖӮ
еҲҶжһҗпјҡURL-Two queuesз®—жі•е’ҢLRU-2з®—жі•е‘ҪдёӯзҺҮзұ»дјјпјҢдҪҶжҳҜURL-Two queuesдјҡеҮҸе°‘дёҖж¬Ўд»ҺеҺҹе§ӢеӯҳеӮЁиҜ»еҸ–жҲ–и®Ўз®—ж•°жҚ®зҡ„ж“ҚдҪңгҖӮе‘ҪдёӯзҺҮиҰҒй«ҳдәҺLRUгҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡйңҖиҰҒз»ҙжҠӨдёӨдёӘйҳҹеҲ—пјҢд»Јд»·жҳҜFIFOе’ҢLRUд»Јд»·д№Ӣе’ҢгҖӮ
emmmm...
иҝҷдёӘеҗҚеӯ—е…¶е®һжҳҜжҲ‘еҸ–зҡ„пјҢеӨ§жҰӮжҳҜиҝҷз§Қз®—жі•иҝҳжІЎжңүиў«е‘ҪеҗҚпјҹеҪ“然пјҢиҝҷжҳҜдёҖдёӘзҺ©з¬‘иҜқгҖӮ
жҲ‘жҳҜеңЁmysqlеә•еұӮе®һзҺ°йҮҢеҸ‘зҺ°иҝҷдёӘз®—жі•зҡ„пјҢmysqlеңЁеӨ„зҗҶзј“еӯҳж·ҳжұ°ж—¶жҳҜз”Ёзҡ„иҝҷдёӘж–№жі•пјҢжңүзӮ№еғҸURL-Two queuesзҡ„еҸҳдҪ“пјҢеҸӘжҳҜжҲ‘们еҸӘйңҖиҰҒз»ҙжҠӨдёҖдёӘйҳҹеҲ—пјҢ然еҗҺе°ҶйҳҹеҲ—жҢүз…§5:3зҡ„жҜ”дҫӢиҝӣиЎҢеҲҶеүІпјҢ5зҡ„йӮЈйғЁеҲҶеҸ«еҒҡyoungеҢәпјҢ3зҡ„йӮЈйғЁеҲҶеҸ«еҒҡoldеҢәгҖӮе…·дҪ“жҳҜжҖҺд№Ҳж ·зҡ„иҜ·е…ҲзңӢжҲ‘жҠҠеӣҫз”»еҮәжқҘпјҡ
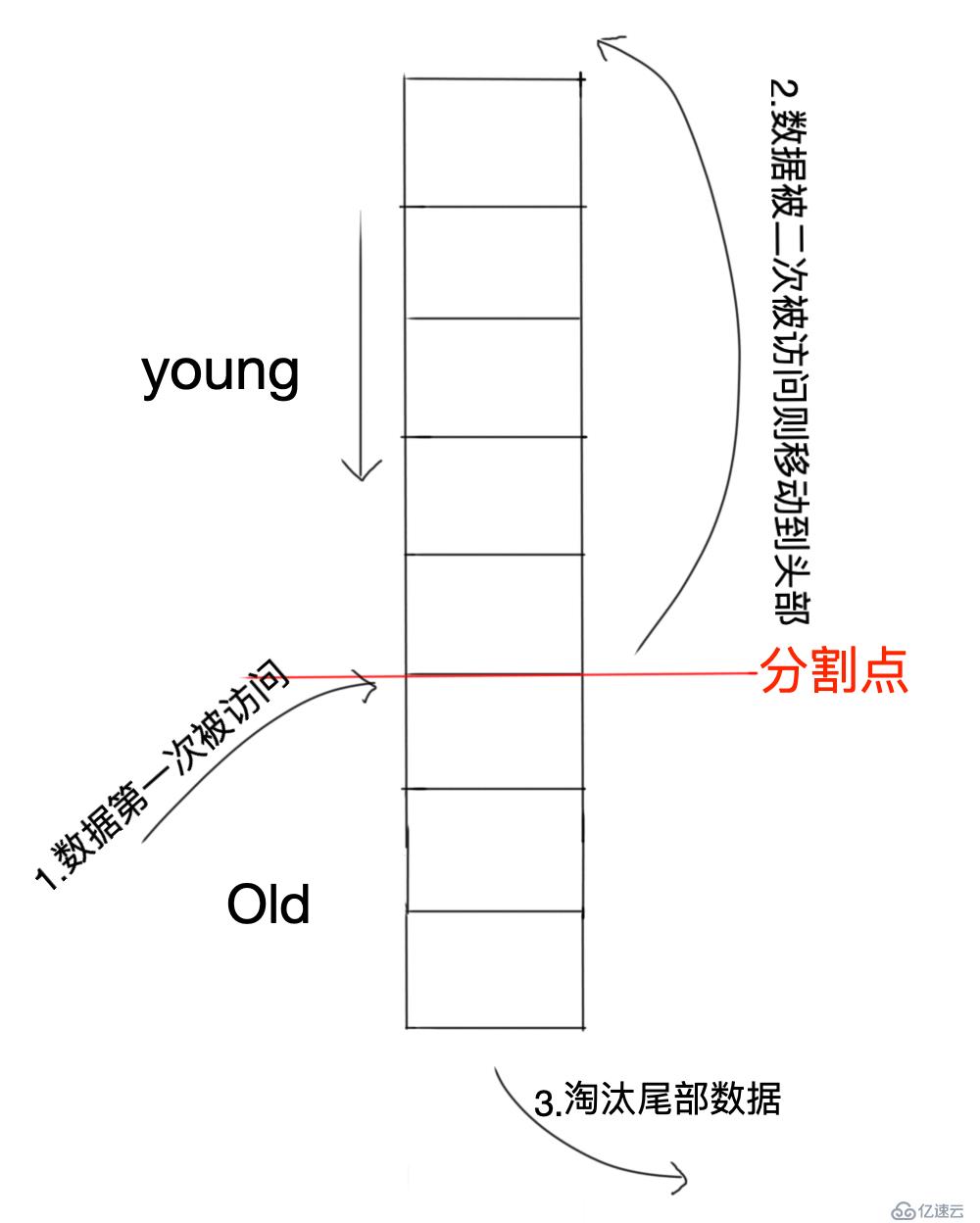
жӯҘйӘӨпјҡ
第дёҖж¬Ўи®ҝй—®зҡ„ж•°жҚ®д»ҺйҳҹеҲ—зҡ„3/8еӨ„дҪҚзҪ®жҸ’е…Ҙпјӣ
еҰӮжһңж•°жҚ®еҶҚж¬Ўиў«и®ҝй—®пјҢеҲҷ移еҠЁеҲ°йҳҹеҲ—еӨҙйғЁпјӣ
еҰӮжһңж•°жҚ®жІЎжңүиў«еҶҚи®ҝй—®пјҢдјҡйҖҗжӯҘиў«зғӯзӮ№ж•°жҚ®й©ұйҖҗеҗ‘дёӢ移пјӣ
ж·ҳжұ°е°ҫйғЁж•°жҚ®гҖӮ
еҲҶжһҗпјҡдә”дёүLRUз®—жі•з®—дҪңжҳҜURL-Two queuesз®—жі•зҡ„еҸҳз§ҚпјҢеҺҹзҗҶе…¶е®һжҳҜдёҖж ·зҡ„пјҢеҸӘжҳҜжҠҠдёӨдёӘйҳҹеҲ—еҗҲдәҢдёәдёҖдёӘйҳҹеҲ—иҝӣиЎҢж•°жҚ®зҡ„еӨ„зҗҶпјҢжүҖд»Ҙе‘ҪдёӯзҺҮе’ҢURL-Two queuesз®—жі•дёҖж ·гҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡз»ҙжҠӨдёҖдёӘйҳҹеҲ—пјҢд»Јд»·иҫғдҪҺпјҢдҪҶжҳҜеҶ…еӯҳеҚ з”ЁзҺҮе’ҢURL-Two queuesдёҖж ·гҖӮ
Multi Queueз®—жі•ж №жҚ®и®ҝй—®йў‘зҺҮе°Ҷж•°жҚ®еҲ’еҲҶдёәеӨҡдёӘйҳҹеҲ—пјҢдёҚеҗҢзҡ„йҳҹеҲ—е…·жңүдёҚеҗҢзҡ„и®ҝй—®дјҳе…Ҳзә§пјҢе…¶ж ёеҝғжҖқжғіжҳҜвҖңдјҳе…Ҳзј“еӯҳи®ҝй—®ж¬Ўж•°еӨҡзҡ„ж•°жҚ®вҖқгҖӮ
Multi Queueз®—жі•е°Ҷзј“еӯҳеҲ’еҲҶдёәеӨҡдёӘLRUйҳҹеҲ—пјҢжҜҸдёӘйҳҹеҲ—еҜ№еә”дёҚеҗҢзҡ„и®ҝй—®дјҳе…Ҳзә§гҖӮи®ҝй—®дјҳе…Ҳзә§жҳҜж №жҚ®и®ҝй—®ж¬Ўж•°и®Ўз®—еҮәжқҘзҡ„пјҢдҫӢеҰӮпјҡ Q0пјҢQ1....Qnд»ЈиЎЁдёҚеҗҢзҡ„дјҳе…Ҳзә§йҳҹеҲ—пјҢQ-historyд»ЈиЎЁд»Һзј“еӯҳдёӯж·ҳжұ°ж•°жҚ®пјҢдҪҶи®°еҪ•дәҶж•°жҚ®зҡ„зҙўеј•е’Ңеј•з”Ёж¬Ўж•°гҖӮ
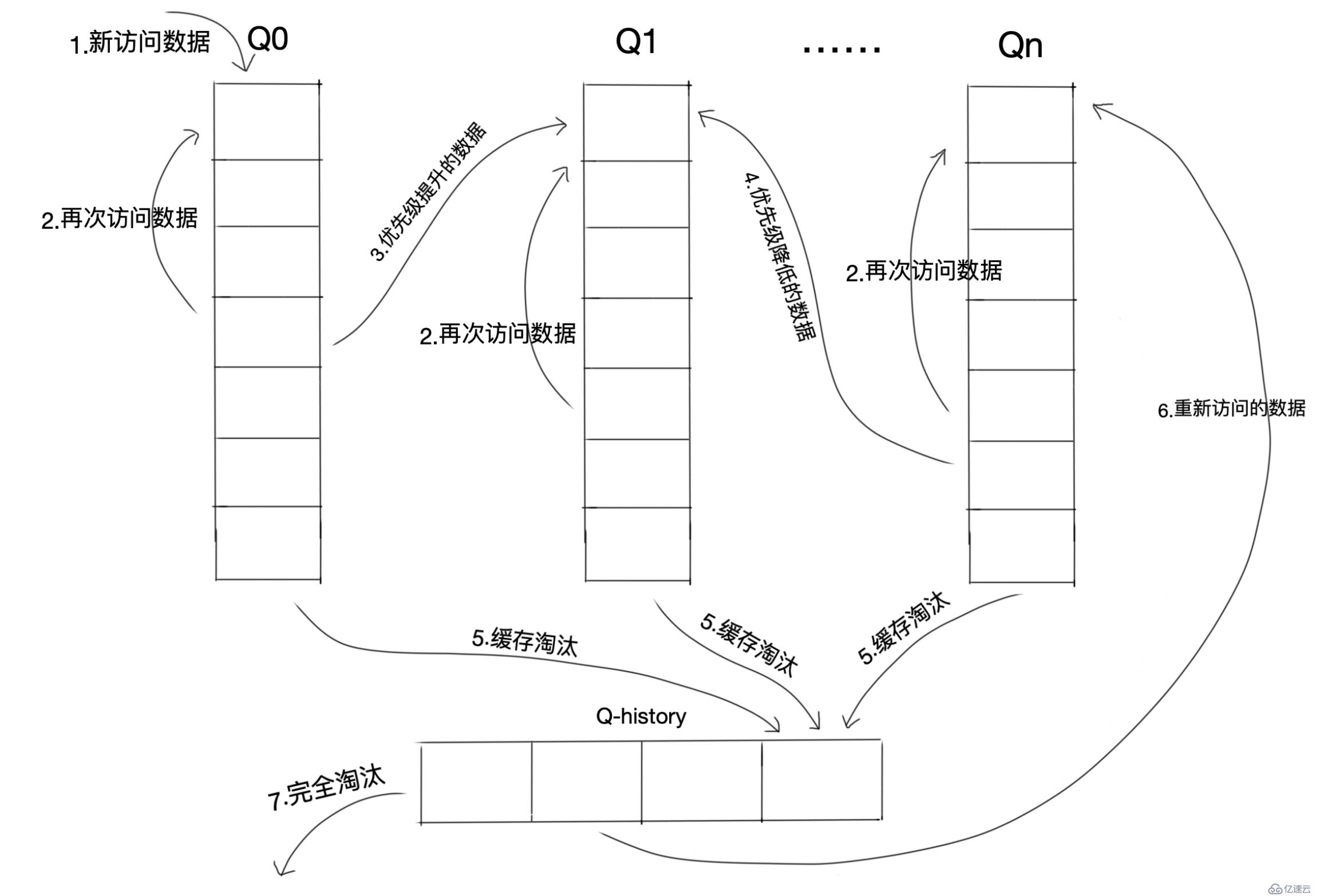
жӯҘйӘӨпјҡ
ж–°жҸ’е…Ҙзҡ„ж•°жҚ®ж”ҫе…ҘQ0пјӣ
жҜҸдёӘйҳҹеҲ—жҢүз…§LRUз®ЎзҗҶж•°жҚ®пјҢеҶҚж¬Ўи®ҝй—®зҡ„ж•°жҚ®з§»еҠЁеҲ°еӨҙйғЁпјӣ
еҪ“ж•°жҚ®зҡ„и®ҝй—®ж¬Ўж•°иҫҫеҲ°дёҖе®ҡж¬Ўж•°пјҢйңҖиҰҒжҸҗеҚҮдјҳе…Ҳзә§ж—¶пјҢе°Ҷж•°жҚ®д»ҺеҪ“еүҚйҳҹеҲ—еҲ йҷӨпјҢеҠ е…ҘеҲ°й«ҳдёҖзә§йҳҹеҲ—зҡ„еӨҙйғЁпјӣ
дёәдәҶйҳІжӯўй«ҳдјҳе…Ҳзә§ж•°жҚ®ж°ёиҝңдёҚиў«ж·ҳжұ°пјҢеҪ“ж•°жҚ®еңЁжҢҮе®ҡзҡ„ж—¶й—ҙйҮҢи®ҝй—®жІЎжңүиў«и®ҝй—®ж—¶пјҢйңҖиҰҒйҷҚдҪҺдјҳе…Ҳзә§пјҢе°Ҷж•°жҚ®д»ҺеҪ“еүҚйҳҹеҲ—еҲ йҷӨпјҢеҠ е…ҘеҲ°дҪҺдёҖзә§зҡ„йҳҹеҲ—еӨҙйғЁпјӣ
йңҖиҰҒж·ҳжұ°ж•°жҚ®ж—¶пјҢд»ҺжңҖдҪҺдёҖзә§йҳҹеҲ—ејҖе§ӢжҢүз…§LRUж·ҳжұ°пјӣжҜҸдёӘйҳҹеҲ—ж·ҳжұ°ж•°жҚ®ж—¶пјҢе°Ҷж•°жҚ®д»Һзј“еӯҳдёӯеҲ йҷӨпјҢе°Ҷж•°жҚ®зҙўеј•еҠ е…ҘQ-historyеӨҙйғЁпјӣ
еҰӮжһңж•°жҚ®еңЁQ-historyдёӯиў«йҮҚж–°и®ҝй—®пјҢеҲҷйҮҚж–°и®Ўз®—е…¶дјҳе…Ҳзә§пјҢ移еҲ°зӣ®ж ҮйҳҹеҲ—зҡ„еӨҙйғЁпјӣ
Q-historyжҢүз…§LRUж·ҳжұ°ж•°жҚ®зҡ„зҙўеј•гҖӮ
еҲҶжһҗпјҡMulti QueueйҷҚдҪҺдәҶвҖңзј“еӯҳжұЎжҹ“вҖқеёҰжқҘзҡ„й—®йўҳпјҢе‘ҪдёӯзҺҮжҜ”LRUиҰҒй«ҳгҖӮ
еӨҚжқӮеәҰдёҺд»Јд»·пјҡMulti QueueйңҖиҰҒз»ҙжҠӨеӨҡдёӘйҳҹеҲ—пјҢдё”йңҖиҰҒз»ҙжҠӨжҜҸдёӘж•°жҚ®зҡ„и®ҝй—®ж—¶й—ҙпјҢеӨҚжқӮеәҰжҜ”LRUй«ҳгҖӮMulti QueueйңҖиҰҒи®°еҪ•жҜҸдёӘж•°жҚ®зҡ„и®ҝй—®ж—¶й—ҙпјҢйңҖиҰҒе®ҡж—¶жү«жҸҸжүҖжңүйҳҹеҲ—пјҢд»Јд»·жҜ”LRUиҰҒй«ҳгҖӮиҷҪ然Multi Queueзҡ„йҳҹеҲ—зңӢиө·жқҘж•°йҮҸжҜ”иҫғеӨҡпјҢдҪҶз”ұдәҺжүҖжңүйҳҹеҲ—д№Ӣе’ҢеҸ—йҷҗдәҺзј“еӯҳе®№йҮҸзҡ„еӨ§е°ҸпјҢеӣ жӯӨиҝҷйҮҢеӨҡдёӘйҳҹеҲ—й•ҝеәҰд№Ӣе’Ңе’ҢдёҖдёӘLRUйҳҹеҲ—жҳҜдёҖж ·зҡ„пјҢеӣ жӯӨйҳҹеҲ—жү«жҸҸжҖ§иғҪд№ҹзӣёиҝ‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ