жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
йҡҸзқҖдҝЎжҒҜеҢ–ж°ҙе№ізҡ„дёҚж–ӯжҸҗй«ҳпјҢдјҒдёҡзә§еә”з”Ёзі»з»ҹеҸҳеҫ—и¶ҠжқҘи¶ҠеәһеӨ§пјҢжҖ§иғҪйҡҸд№ӢдёӢйҷҚпјҢз”ЁжҲ·жҠұжҖЁйў‘йў‘гҖӮжӢҶеҲҶзі»з»ҹжҳҜзӣ®еүҚжҲ‘们еҸҜйҖүжӢ©зҡ„и§ЈеҶізі»з»ҹеҸҜдјёзј©жҖ§е’ҢжҖ§иғҪй—®йўҳзҡ„е”ҜдёҖиЎҢд№Ӣжңүж•Ҳзҡ„ж–№жі•гҖӮдҪҶжҳҜжӢҶеҲҶзі»з»ҹеҗҢж—¶д№ҹеёҰжқҘдәҶзі»з»ҹзҡ„еӨҚжқӮжҖ§вҖ”вҖ”еҗ„еӯҗзі»з»ҹдёҚжҳҜеӯӨз«ӢеӯҳеңЁзҡ„пјҢе®ғ们еҪјжӯӨд№Ӣй—ҙйңҖиҰҒеҚҸдҪңе’ҢдәӨдә’пјҲеҲҶеёғејҸзі»з»ҹпјүгҖӮеҗ„дёӘеӯҗзі»з»ҹе°ұеҘҪжҜ”еҠЁзү©еӣӯйҮҢзҡ„еҠЁзү©пјҢдёәдәҶдҪҝеҗ„дёӘеӯҗзі»з»ҹиғҪжӯЈеёёдёәз”ЁжҲ·жҸҗдҫӣз»ҹдёҖзҡ„жңҚеҠЎпјҢеҝ…йЎ»йңҖиҰҒдёҖз§ҚжңәеҲ¶жқҘиҝӣиЎҢеҚҸи°ғвҖ”вҖ”иҝҷе°ұжҳҜZooKeeperпјҲеҠЁзү©еӣӯз®ЎзҗҶе‘ҳпјүгҖӮдёӢйқўиҜҰи§Јпјҡ
д»Җд№ҲжҳҜ Zookeeper
Zookeeper еҲҶеёғејҸжңҚеҠЎжЎҶжһ¶жҳҜApache Hadoop зҡ„дёҖдёӘеӯҗйЎ№зӣ®пјҢе®ғдё»иҰҒжҳҜз”ЁжқҘи§ЈеҶіеҲҶеёғејҸеә”з”Ёдёӯз»ҸеёёйҒҮеҲ°зҡ„дёҖдәӣж•°жҚ®з®ЎзҗҶй—®йўҳпјҢеҰӮпјҡ
з»ҹдёҖе‘ҪеҗҚжңҚеҠЎпјӣ
зҠ¶жҖҒеҗҢжӯҘжңҚеҠЎ;
йӣҶзҫӨз®ЎзҗҶ;
еҲҶеёғејҸеә”з”Ёй…ҚзҪ®йЎ№зҡ„з®ЎзҗҶзӯүгҖӮ
Zookeeperе·Із»ҸжҲҗдёәHadoopз”ҹжҖҒзі»з»ҹдёӯзҡ„еҹәзЎҖ组件гҖӮ
Zookeeperзҡ„еҹәжң¬еҺҹзҗҶе’Ңжһ¶жһ„
1гҖҒZookeeperзҡ„и§’иүІ
йўҶеҜјиҖ…пјҲleaderпјүпјҡиҙҹиҙЈиҝӣиЎҢжҠ•зҘЁзҡ„еҸ‘иө·е’ҢеҶіи®®пјҢжӣҙж–°зі»з»ҹзҠ¶жҖҒпјӣ
еӯҰд№ иҖ…пјҲlearnerпјүпјҡеҢ…жӢ¬и·ҹйҡҸиҖ…пјҲfollowerпјүе’Ңи§ӮеҜҹиҖ…пјҲobserverпјүпјҢfollowerз”ЁдәҺжҺҘеҸ—е®ўжҲ·з«ҜиҜ·жұӮ并жғіе®ўжҲ·з«Ҝиҝ”еӣһз»“жһңпјҢеңЁйҖүдё»иҝҮзЁӢдёӯеҸӮдёҺжҠ•зҘЁпјӣ
ObserverпјҡеҸҜд»ҘжҺҘеҸ—е®ўжҲ·з«ҜиҝһжҺҘпјҢе°ҶеҶҷиҜ·жұӮиҪ¬еҸ‘з»ҷleaderпјҢдҪҶobserverдёҚеҸӮеҠ жҠ•зҘЁиҝҮзЁӢпјҢеҸӘеҗҢжӯҘleaderзҡ„зҠ¶жҖҒпјҢobserverзҡ„зӣ®зҡ„жҳҜдёәдәҶжү©еұ•зі»з»ҹпјҢжҸҗй«ҳиҜ»еҸ–йҖҹеәҰпјӣ
е®ўжҲ·з«ҜпјҲclientпјүпјҡиҜ·жұӮеҸ‘иө·ж–№гҖӮ
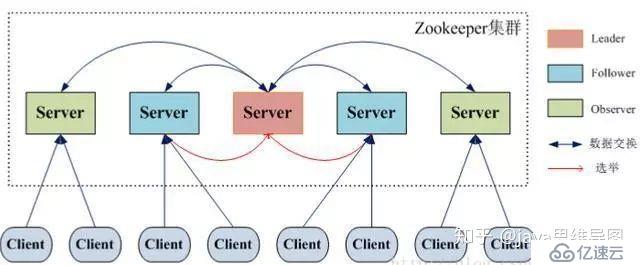

вҖў Zookeeperзҡ„ж ёеҝғжҳҜеҺҹеӯҗе№ҝж’ӯпјҢиҝҷдёӘжңәеҲ¶дҝқиҜҒдәҶеҗ„дёӘServerд№Ӣй—ҙзҡ„еҗҢжӯҘгҖӮе®һзҺ°иҝҷдёӘжңәеҲ¶зҡ„еҚҸи®®еҸ«еҒҡZabеҚҸи®®гҖӮZabеҚҸи®®жңүдёӨз§ҚжЁЎејҸпјҢе®ғ们еҲҶеҲ«жҳҜжҒўеӨҚжЁЎејҸпјҲйҖүдё»пјүе’Ңе№ҝж’ӯжЁЎејҸпјҲеҗҢжӯҘпјүгҖӮеҪ“жңҚеҠЎеҗҜеҠЁжҲ–иҖ…еңЁйўҶеҜјиҖ…еҙ©жәғеҗҺпјҢZabе°ұиҝӣе…ҘдәҶжҒўеӨҚжЁЎејҸпјҢеҪ“йўҶеҜјиҖ…иў«йҖүдёҫеҮәжқҘпјҢдё”еӨ§еӨҡж•°Serverе®ҢжҲҗдәҶе’Ңleaderзҡ„зҠ¶жҖҒеҗҢжӯҘд»ҘеҗҺпјҢжҒўеӨҚжЁЎејҸе°ұз»“жқҹдәҶгҖӮзҠ¶жҖҒеҗҢжӯҘдҝқиҜҒдәҶleaderе’ҢServerе…·жңүзӣёеҗҢзҡ„зі»з»ҹзҠ¶жҖҒгҖӮ
вҖў дёәдәҶдҝқиҜҒдәӢеҠЎзҡ„йЎәеәҸдёҖиҮҙжҖ§пјҢzookeeperйҮҮз”ЁдәҶйҖ’еўһзҡ„дәӢеҠЎidеҸ·пјҲzxidпјүжқҘж ҮиҜҶдәӢеҠЎгҖӮжүҖжңүзҡ„жҸҗи®®пјҲproposalпјүйғҪеңЁиў«жҸҗеҮәзҡ„ж—¶еҖҷеҠ дёҠдәҶzxidгҖӮе®һзҺ°дёӯzxidжҳҜдёҖдёӘ64дҪҚзҡ„ж•°еӯ—пјҢе®ғй«ҳ32дҪҚжҳҜepochз”ЁжқҘж ҮиҜҶleaderе…ізі»жҳҜеҗҰж”№еҸҳпјҢжҜҸж¬ЎдёҖдёӘleaderиў«йҖүеҮәжқҘпјҢе®ғйғҪдјҡжңүдёҖдёӘж–°зҡ„epochпјҢж ҮиҜҶеҪ“еүҚеұһдәҺйӮЈдёӘleaderзҡ„з»ҹжІ»ж—¶жңҹгҖӮдҪҺ32дҪҚз”ЁдәҺйҖ’еўһи®Ўж•°гҖӮ
вҖў жҜҸдёӘServerеңЁе·ҘдҪңиҝҮзЁӢдёӯжңүдёүз§ҚзҠ¶жҖҒпјҡ
LOOKINGпјҡеҪ“еүҚServerдёҚзҹҘйҒ“leaderжҳҜи°ҒпјҢжӯЈеңЁжҗңеҜ»пјӣ
LEADINGпјҡеҪ“еүҚServerеҚідёәйҖүдёҫеҮәжқҘзҡ„leaderпјӣ
FOLLOWINGпјҡleaderе·Із»ҸйҖүдёҫеҮәжқҘпјҢеҪ“еүҚServerдёҺд№ӢеҗҢжӯҘгҖӮ
2гҖҒZookeeper зҡ„иҜ»еҶҷжңәеҲ¶
ZookeeperжҳҜдёҖдёӘз”ұеӨҡдёӘserverз»„жҲҗзҡ„йӣҶзҫӨпјӣ
дёҖдёӘleaderпјҢеӨҡдёӘfollowerпјӣ
жҜҸдёӘserverдҝқеӯҳдёҖд»Ҫж•°жҚ®еүҜжң¬пјӣ
е…ЁеұҖж•°жҚ®дёҖиҮҙпјӣ
еҲҶеёғејҸиҜ»еҶҷпјӣ
жӣҙж–°иҜ·жұӮиҪ¬еҸ‘пјҢз”ұleaderе®һж–ҪгҖӮ
3гҖҒZookeeper зҡ„дҝқиҜҒ
жӣҙж–°иҜ·жұӮйЎәеәҸиҝӣиЎҢпјҢжқҘиҮӘеҗҢдёҖдёӘclientзҡ„жӣҙж–°иҜ·жұӮжҢүе…¶еҸ‘йҖҒйЎәеәҸдҫқж¬Ўжү§иЎҢпјӣ
ж•°жҚ®жӣҙж–°еҺҹеӯҗжҖ§пјҢдёҖж¬Ўж•°жҚ®жӣҙж–°иҰҒд№ҲжҲҗеҠҹпјҢиҰҒд№ҲеӨұиҙҘпјӣ
е…ЁеұҖе”ҜдёҖж•°жҚ®и§ҶеӣҫпјҢclientж— и®әиҝһжҺҘеҲ°е“ӘдёӘserverпјҢж•°жҚ®и§ҶеӣҫйғҪжҳҜдёҖиҮҙзҡ„пјӣ
е®һж—¶жҖ§пјҢеңЁдёҖе®ҡдәӢ件иҢғеӣҙеҶ…пјҢclientиғҪиҜ»еҲ°жңҖж–°ж•°жҚ®гҖӮ
4гҖҒZookeeperиҠӮзӮ№ж•°жҚ®ж“ҚдҪңжөҒзЁӢ
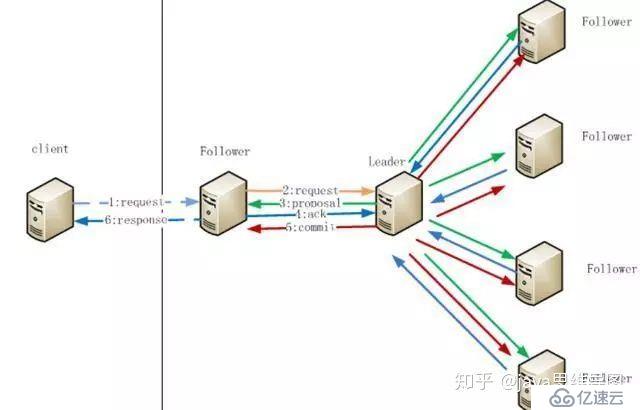
еңЁClientеҗ‘FollwerеҸ‘еҮәдёҖдёӘеҶҷзҡ„иҜ·жұӮпјӣ
FollwerжҠҠиҜ·жұӮеҸ‘йҖҒз»ҷLeaderпјӣ
LeaderжҺҘ收еҲ°д»ҘеҗҺејҖе§ӢеҸ‘иө·жҠ•зҘЁе№¶йҖҡзҹҘFollwerиҝӣиЎҢжҠ•зҘЁпјӣ
FollwerжҠҠжҠ•зҘЁз»“жһңеҸ‘йҖҒз»ҷLeaderпјӣ
Leaderе°Ҷз»“жһңжұҮжҖ»еҗҺеҰӮжһңйңҖиҰҒеҶҷе…ҘпјҢеҲҷејҖе§ӢеҶҷе…ҘеҗҢж—¶жҠҠеҶҷе…Ҙж“ҚдҪңйҖҡзҹҘз»ҷLeaderпјҢ然еҗҺcommit;
FollwerжҠҠиҜ·жұӮз»“жһңиҝ”еӣһз»ҷClientгҖӮ
5гҖҒZookeeperе·ҘдҪңеҺҹзҗҶ
Zookeeperзҡ„ж ёеҝғжҳҜеҺҹеӯҗе№ҝж’ӯпјҢиҝҷдёӘжңәеҲ¶дҝқиҜҒдәҶеҗ„дёӘserverд№Ӣй—ҙзҡ„еҗҢжӯҘгҖӮе®һзҺ°иҝҷдёӘжңәеҲ¶зҡ„еҚҸи®®еҸ«еҒҡZabеҚҸи®®гҖӮZabеҚҸи®®жңүдёӨз§ҚжЁЎејҸпјҢе®ғ们еҲҶеҲ«жҳҜпјҡжҒўеӨҚжЁЎејҸе’Ңе№ҝж’ӯжЁЎејҸгҖӮеҪ“жңҚеҠЎеҗҜеҠЁжҲ–иҖ…еңЁйўҶеҜјиҖ…еҙ©жәғеҗҺпјҢZabе°ұиҝӣе…ҘдәҶжҒўеӨҚжЁЎејҸпјҢеҪ“йўҶеҜјиҖ…иў«йҖүдёҫеҮәжқҘпјҢдё”еӨ§еӨҡж•°serverзҡ„е®ҢжҲҗдәҶе’Ңleaderзҡ„зҠ¶жҖҒеҗҢжӯҘд»ҘеҗҺпјҢжҒўеӨҚжЁЎејҸе°ұз»“жқҹдәҶгҖӮ
6гҖҒж•°жҚ®дёҖиҮҙжҖ§дёҺpaxos з®—жі•
вҖў жҚ®иҜҙPaxosз®—жі•зҡ„йҡҫзҗҶи§ЈдёҺз®—жі•зҡ„зҹҘеҗҚеәҰдёҖж ·д»Өдәә敬仰пјҢжүҖд»ҘжҲ‘们е…ҲзңӢеҰӮдҪ•дҝқжҢҒж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҢиҝҷйҮҢжңүдёӘеҺҹеҲҷе°ұжҳҜпјҡ
вҖў еңЁдёҖдёӘеҲҶеёғејҸж•°жҚ®еә“зі»з»ҹдёӯпјҢеҰӮжһңеҗ„иҠӮзӮ№зҡ„еҲқе§ӢзҠ¶жҖҒдёҖиҮҙпјҢжҜҸдёӘиҠӮзӮ№йғҪжү§иЎҢзӣёеҗҢзҡ„ж“ҚдҪңеәҸеҲ—пјҢйӮЈд№Ҳ他们жңҖеҗҺиғҪеҫ—еҲ°дёҖдёӘдёҖиҮҙзҡ„зҠ¶жҖҒгҖӮ
вҖў Paxosз®—жі•и§ЈеҶізҡ„д»Җд№Ҳй—®йўҳе‘ўпјҢи§ЈеҶізҡ„е°ұжҳҜдҝқиҜҒжҜҸдёӘиҠӮзӮ№жү§иЎҢзӣёеҗҢзҡ„ж“ҚдҪңеәҸеҲ—гҖӮеҘҪеҗ§пјҢиҝҷиҝҳдёҚз®ҖеҚ•пјҢmasterз»ҙжҠӨдёҖдёӘе…ЁеұҖеҶҷйҳҹеҲ—пјҢжүҖжңүеҶҷж“ҚдҪңйғҪеҝ…йЎ» ж”ҫе…ҘиҝҷдёӘйҳҹеҲ—зј–еҸ·пјҢйӮЈд№Ҳж— и®әжҲ‘们еҶҷеӨҡе°‘дёӘиҠӮзӮ№пјҢеҸӘиҰҒеҶҷж“ҚдҪңжҳҜжҢүзј–еҸ·жқҘзҡ„пјҢе°ұиғҪдҝқиҜҒдёҖиҮҙжҖ§гҖӮжІЎй”ҷпјҢе°ұжҳҜиҝҷж ·пјҢеҸҜжҳҜеҰӮжһңmasterжҢӮдәҶе‘ўгҖӮ
вҖў Paxosз®—жі•йҖҡиҝҮжҠ•зҘЁжқҘеҜ№еҶҷж“ҚдҪңиҝӣиЎҢе…ЁеұҖзј–еҸ·пјҢеҗҢдёҖж—¶еҲ»пјҢеҸӘжңүдёҖдёӘеҶҷж“ҚдҪңиў«жү№еҮҶпјҢеҗҢ时并еҸ‘зҡ„еҶҷж“ҚдҪңиҰҒеҺ»дәүеҸ–йҖүзҘЁпјҢеҸӘжңүиҺ·еҫ—иҝҮеҚҠж•°йҖүзҘЁзҡ„еҶҷж“ҚдҪңжүҚдјҡиў« жү№еҮҶпјҲжүҖд»Ҙж°ёиҝңеҸӘдјҡжңүдёҖдёӘеҶҷж“ҚдҪңеҫ—еҲ°жү№еҮҶпјүпјҢе…¶д»–зҡ„еҶҷж“ҚдҪңз«һдәүеӨұиҙҘеҸӘеҘҪеҶҚеҸ‘иө·дёҖиҪ®жҠ•зҘЁпјҢе°ұиҝҷж ·пјҢеңЁж—ҘеӨҚдёҖж—Ҙе№ҙеӨҚдёҖе№ҙзҡ„жҠ•зҘЁдёӯпјҢжүҖжңүеҶҷж“ҚдҪңйғҪиў«дёҘж јзј–еҸ·жҺ’ еәҸгҖӮзј–еҸ·дёҘж јйҖ’еўһпјҢеҪ“дёҖдёӘиҠӮзӮ№жҺҘеҸ—дәҶдёҖдёӘзј–еҸ·дёә100зҡ„еҶҷж“ҚдҪңпјҢд№ӢеҗҺеҸҲжҺҘеҸ—еҲ°зј–еҸ·дёә99зҡ„еҶҷж“ҚдҪңпјҲеӣ дёәзҪ‘з»ң延иҝҹзӯүеҫҲеӨҡдёҚеҸҜйў„и§ҒеҺҹеӣ пјүпјҢе®ғ马дёҠиғҪж„ҸиҜҶеҲ°иҮӘе·ұ ж•°жҚ®дёҚдёҖиҮҙдәҶпјҢиҮӘеҠЁеҒңжӯўеҜ№еӨ–жңҚеҠЎе№¶йҮҚеҗҜеҗҢжӯҘиҝҮзЁӢгҖӮд»»дҪ•дёҖдёӘиҠӮзӮ№жҢӮжҺүйғҪдёҚдјҡеҪұе“Қж•ҙдёӘйӣҶзҫӨзҡ„ж•°жҚ®дёҖиҮҙжҖ§пјҲжҖ»2n+1еҸ°пјҢйҷӨйқһжҢӮжҺүеӨ§дәҺnеҸ°пјүгҖӮ
жҖ»з»“пјҡZookeeper дҪңдёә Hadoop йЎ№зӣ®дёӯзҡ„дёҖдёӘеӯҗйЎ№зӣ®пјҢжҳҜ Hadoop йӣҶзҫӨз®ЎзҗҶзҡ„дёҖдёӘеҝ…дёҚеҸҜе°‘зҡ„жЁЎеқ—пјҢе®ғдё»иҰҒз”ЁжқҘжҺ§еҲ¶йӣҶзҫӨдёӯзҡ„ж•°жҚ®пјҢеҰӮе®ғз®ЎзҗҶ Hadoop йӣҶзҫӨдёӯзҡ„ NameNodeпјҢиҝҳжңү Hbase дёӯ Master ElectionгҖҒServer д№Ӣй—ҙзҠ¶жҖҒеҗҢжӯҘзӯүгҖӮ
7гҖҒObserver
ZookeeperйңҖдҝқиҜҒй«ҳеҸҜз”Ёе’ҢејәдёҖиҮҙжҖ§пјӣ
дёәдәҶж”ҜжҢҒжӣҙеӨҡзҡ„е®ўжҲ·з«ҜпјҢйңҖиҰҒеўһеҠ жӣҙеӨҡServerпјӣ
ServerеўһеӨҡпјҢжҠ•зҘЁйҳ¶ж®ө延иҝҹеўһеӨ§пјҢеҪұе“ҚжҖ§иғҪпјӣ
жқғиЎЎдјёзј©жҖ§е’Ңй«ҳеҗһеҗҗзҺҮпјҢеј•е…ҘObserverпјӣ
ObserverдёҚеҸӮдёҺжҠ•зҘЁпјӣ
ObserversжҺҘеҸ—е®ўжҲ·з«Ҝзҡ„иҝһжҺҘпјҢ并е°ҶеҶҷиҜ·жұӮиҪ¬еҸ‘з»ҷleaderиҠӮзӮ№пјӣ
еҠ е…ҘжӣҙеӨҡObserverиҠӮзӮ№пјҢжҸҗй«ҳдјёзј©жҖ§пјҢеҗҢж—¶дёҚеҪұе“ҚеҗһеҗҗзҺҮгҖӮ
8гҖҒ дёәд»Җд№ҲzookeeperйӣҶзҫӨзҡ„ж•°зӣ®пјҢдёҖиҲ¬дёәеҘҮж•°дёӘпјҹ
LeaderйҖүдёҫз®—жі•йҮҮз”ЁдәҶPaxosеҚҸи®®пјӣ
Paxosж ёеҝғжҖқжғіпјҡеҪ“еӨҡж•°ServerеҶҷжҲҗеҠҹпјҢеҲҷд»»еҠЎж•°жҚ®еҶҷжҲҗеҠҹеҰӮжһңжңү3дёӘServerпјҢеҲҷдёӨдёӘеҶҷжҲҗеҠҹеҚіеҸҜпјӣеҰӮжһңжңү4жҲ–5дёӘServerпјҢеҲҷдёүдёӘеҶҷжҲҗеҠҹеҚіеҸҜпјӣ
Serverж•°зӣ®дёҖиҲ¬дёәеҘҮж•°пјҲ3гҖҒ5гҖҒ7пјүеҰӮжһңжңү3дёӘServerпјҢеҲҷжңҖеӨҡе…Ғи®ё1дёӘServerжҢӮжҺүпјӣеҰӮжһңжңү4дёӘServerпјҢеҲҷеҗҢж ·жңҖеӨҡе…Ғи®ё1дёӘServerжҢӮжҺүз”ұжӯӨпјҢжҲ‘们зңӢеҮә3еҸ°жңҚеҠЎеҷЁе’Ң4еҸ°жңҚеҠЎеҷЁзҡ„зҡ„е®№зҒҫиғҪеҠӣжҳҜдёҖж ·зҡ„пјҢжүҖд»ҘдёәдәҶиҠӮзңҒжңҚеҠЎеҷЁиө„жәҗпјҢдёҖиҲ¬жҲ‘们йҮҮз”ЁеҘҮж•°дёӘж•°пјҢдҪңдёәжңҚеҠЎеҷЁйғЁзҪІдёӘж•°гҖӮ
9гҖҒZookeeper зҡ„ж•°жҚ®жЁЎеһӢгҖҖ
еұӮж¬ЎеҢ–зҡ„зӣ®еҪ•з»“жһ„пјҢе‘ҪеҗҚз¬ҰеҗҲ常规ж–Ү件系з»ҹ规иҢғпјӣ
жҜҸдёӘиҠӮзӮ№еңЁzookeeperдёӯеҸ«еҒҡznode,并且其жңүдёҖдёӘе”ҜдёҖзҡ„и·Ҝеҫ„ж ҮиҜҶпјӣ
иҠӮзӮ№ZnodeеҸҜд»ҘеҢ…еҗ«ж•°жҚ®е’ҢеӯҗиҠӮзӮ№пјҢдҪҶжҳҜEPHEMERALзұ»еһӢзҡ„иҠӮзӮ№дёҚиғҪжңүеӯҗиҠӮзӮ№пјӣ
Znodeдёӯзҡ„ж•°жҚ®еҸҜд»ҘжңүеӨҡдёӘзүҲжң¬пјҢжҜ”еҰӮжҹҗдёҖдёӘи·Ҝеҫ„дёӢеӯҳжңүеӨҡдёӘж•°жҚ®зүҲжң¬пјҢйӮЈд№ҲжҹҘиҜўиҝҷдёӘи·Ҝеҫ„дёӢзҡ„ж•°жҚ®е°ұйңҖиҰҒеёҰдёҠзүҲжң¬пјӣ
е®ўжҲ·з«Ҝеә”з”ЁеҸҜд»ҘеңЁиҠӮзӮ№дёҠи®ҫзҪ®зӣ‘и§ҶеҷЁпјӣ
иҠӮзӮ№дёҚж”ҜжҢҒйғЁеҲҶиҜ»еҶҷпјҢиҖҢжҳҜдёҖж¬ЎжҖ§е®Ңж•ҙиҜ»еҶҷгҖӮ
10гҖҒZookeeper зҡ„иҠӮзӮ№
ZnodeжңүдёӨз§Қзұ»еһӢпјҢзҹӯжҡӮзҡ„пјҲephemeralпјүе’ҢжҢҒд№…зҡ„пјҲpersistentпјүпјӣ
Znodeзҡ„зұ»еһӢеңЁеҲӣе»әж—¶зЎ®е®ҡ并且д№ӢеҗҺдёҚиғҪеҶҚдҝ®ж”№пјӣ
зҹӯжҡӮznodeзҡ„е®ўжҲ·з«ҜдјҡиҜқз»“жқҹж—¶пјҢzookeeperдјҡе°ҶиҜҘзҹӯжҡӮznodeеҲ йҷӨпјҢзҹӯжҡӮznodeдёҚеҸҜд»ҘжңүеӯҗиҠӮзӮ№пјӣ
жҢҒд№…znodeдёҚдҫқиө–дәҺе®ўжҲ·з«ҜдјҡиҜқпјҢеҸӘжңүеҪ“е®ўжҲ·з«ҜжҳҺзЎ®иҰҒеҲ йҷӨиҜҘжҢҒд№…znodeж—¶жүҚдјҡиў«еҲ йҷӨпјӣ
Znodeжңүеӣӣз§ҚеҪўејҸзҡ„зӣ®еҪ•иҠӮзӮ№пјӣ
PERSISTENTпјҲжҢҒд№…зҡ„пјүпјӣ
EPHEMERAL(жҡӮж—¶зҡ„)пјӣ
PERSISTENT_SEQUENTIALпјҲжҢҒд№…еҢ–йЎәеәҸзј–еҸ·зӣ®еҪ•иҠӮзӮ№пјүпјӣ
EPHEMERAL_SEQUENTIALпјҲжҡӮж—¶еҢ–йЎәеәҸзј–еҸ·зӣ®еҪ•иҠӮзӮ№пјүгҖӮ
Zookeeperзҡ„еә”з”ЁеңәжҷҜ
1. й…ҚзҪ®з®ЎзҗҶ
иҝҷдёӘеҘҪзҗҶи§ЈпјҢеҲҶеёғејҸзі»з»ҹйғҪжңүеҘҪеӨҡжңәеҷЁпјҢжҜ”еҰӮжҲ‘еңЁжҗӯе»әhadoopзҡ„HDFSзҡ„ж—¶еҖҷпјҢйңҖиҰҒеңЁдёҖдёӘдё»жңәеҷЁдёҠпјҲMasterиҠӮзӮ№пјүй…ҚзҪ®еҘҪHDFSйңҖиҰҒзҡ„еҗ„з§Қй…ҚзҪ®ж–Ү件пјҢ然еҗҺйҖҡиҝҮscpе‘Ҫд»ӨжҠҠиҝҷдәӣй…ҚзҪ®ж–Ү件жӢ·иҙқеҲ°е…¶д»–иҠӮзӮ№дёҠпјҢиҝҷж ·еҗ„дёӘжңәеҷЁжӢҝеҲ°зҡ„й…ҚзҪ®дҝЎжҒҜжҳҜдёҖиҮҙзҡ„пјҢжүҚиғҪжҲҗеҠҹиҝҗиЎҢиө·жқҘHDFSжңҚеҠЎгҖӮ
ZookeeperжҸҗдҫӣдәҶиҝҷж ·зҡ„дёҖз§ҚжңҚеҠЎпјҡдёҖз§ҚйӣҶдёӯз®ЎзҗҶй…ҚзҪ®зҡ„ж–№жі•пјҢжҲ‘们еңЁиҝҷдёӘйӣҶдёӯзҡ„ең°ж–№дҝ®ж”№дәҶй…ҚзҪ®пјҢжүҖжңүеҜ№иҝҷдёӘй…ҚзҪ®ж„ҹе…ҙи¶Јзҡ„йғҪеҸҜд»ҘиҺ·еҫ—еҸҳжӣҙгҖӮиҝҷж ·е°ұзңҒеҺ»жүӢеҠЁжӢ·иҙқй…ҚзҪ®дәҶпјҢиҝҳдҝқиҜҒдәҶеҸҜйқ е’ҢдёҖиҮҙжҖ§гҖӮ
2. еҗҚеӯ—жңҚеҠЎ
иҝҷдёӘеҸҜд»Ҙз®ҖеҚ•зҗҶи§ЈдёәдёҖдёӘз”өиҜқи–„пјҢз”өиҜқеҸ·з ҒдёҚеҘҪи®°пјҢдҪҶжҳҜдәәеҗҚеҘҪи®°пјҢиҰҒжү“и°Ғзҡ„з”өиҜқпјҢзӣҙжҺҘжҹҘдәәеҗҚе°ұеҘҪдәҶгҖӮеҲҶеёғејҸзҺҜеўғдёӢпјҢз»ҸеёёйңҖиҰҒеҜ№еә”з”Ё/жңҚеҠЎиҝӣиЎҢз»ҹдёҖе‘ҪеҗҚпјҢдҫҝдәҺиҜҶеҲ«дёҚеҗҢжңҚеҠЎпјӣ
зұ»дјјдәҺеҹҹеҗҚдёҺipд№Ӣй—ҙеҜ№еә”е…ізі»пјҢеҹҹеҗҚе®№жҳ“и®°дҪҸпјӣ
йҖҡиҝҮеҗҚз§°жқҘиҺ·еҸ–иө„жәҗжҲ–жңҚеҠЎзҡ„ең°еқҖпјҢжҸҗдҫӣиҖ…зӯүдҝЎжҒҜгҖӮ
3. еҲҶеёғејҸй”Ғ
зў°еҲ°еҲҶеёғдәҢеӯ—иІҢдјје°ұйҡҫзҗҶи§ЈдәҶпјҢе…¶е®һеҫҲз®ҖеҚ•гҖӮеҚ•жңәзЁӢеәҸзҡ„еҗ„дёӘиҝӣзЁӢйңҖиҰҒеҜ№дә’ж–Ҙиө„жәҗиҝӣиЎҢи®ҝй—®ж—¶йңҖиҰҒеҠ й”ҒпјҢйӮЈеҲҶеёғејҸзЁӢеәҸеҲҶеёғеңЁеҗ„дёӘдё»жңәдёҠзҡ„иҝӣзЁӢеҜ№дә’ж–Ҙиө„жәҗиҝӣиЎҢи®ҝй—®ж—¶д№ҹйңҖиҰҒеҠ й”ҒгҖӮеҫҲеӨҡеҲҶеёғејҸзі»з»ҹжңүеӨҡдёӘеҸҜжңҚеҠЎзҡ„зӘ—еҸЈпјҢдҪҶжҳҜеңЁжҹҗдёӘж—¶еҲ»еҸӘи®©дёҖдёӘжңҚеҠЎеҺ»е№Іжҙ»пјҢеҪ“иҝҷеҸ°жңҚеҠЎеҮәй—®йўҳзҡ„ж—¶еҖҷй”ҒйҮҠж”ҫпјҢз«ӢеҚіfail overеҲ°еҸҰеӨ–зҡ„жңҚеҠЎгҖӮиҝҷеңЁеҫҲеӨҡеҲҶеёғејҸзі»з»ҹдёӯйғҪжҳҜиҝҷд№ҲеҒҡпјҢиҝҷз§Қи®ҫи®ЎжңүдёҖдёӘжӣҙеҘҪеҗ¬зҡ„еҗҚеӯ—еҸ«Leader Election(leaderйҖүдёҫ)гҖӮдёҫдёӘйҖҡдҝ—зӮ№зҡ„дҫӢеӯҗпјҢжҜ”еҰӮ银иЎҢеҸ–й’ұпјҢжңүеӨҡдёӘзӘ—еҸЈпјҢдҪҶжҳҜе‘ўеҜ№дҪ жқҘиҜҙпјҢеҸӘиғҪжңүдёҖдёӘзӘ—еҸЈеҜ№дҪ жңҚеҠЎпјҢеҰӮжһңжӯЈеңЁеҜ№дҪ жңҚеҠЎзҡ„зӘ—еҸЈзҡ„жҹңе‘ҳзӘҒ然жңүжҖҘдәӢиө°дәҶпјҢйӮЈе’ӢеҠһпјҹжүҫеӨ§е Ӯз»ҸзҗҶпјҲzookeeperпјү!еӨ§е Ӯз»ҸзҗҶжҢҮе®ҡеҸҰеӨ–зҡ„дёҖдёӘзӘ—еҸЈз»§з»ӯдёәдҪ жңҚеҠЎпјҒ
4. йӣҶзҫӨз®ЎзҗҶ
еңЁеҲҶеёғејҸзҡ„йӣҶзҫӨдёӯпјҢз»Ҹеёёдјҡз”ұдәҺеҗ„з§ҚеҺҹеӣ пјҢжҜ”еҰӮ硬件故йҡңпјҢиҪҜ件故йҡңпјҢзҪ‘з»ңй—®йўҳпјҢжңүдәӣиҠӮзӮ№дјҡиҝӣиҝӣеҮәеҮәгҖӮжңүж–°зҡ„иҠӮзӮ№еҠ е…ҘиҝӣжқҘпјҢд№ҹжңүиҖҒзҡ„иҠӮзӮ№йҖҖеҮәйӣҶзҫӨгҖӮиҝҷдёӘж—¶еҖҷпјҢйӣҶзҫӨдёӯжңүдәӣжңәеҷЁпјҲжҜ”еҰӮMasterиҠӮзӮ№пјүйңҖиҰҒж„ҹзҹҘеҲ°иҝҷз§ҚеҸҳеҢ–пјҢ然еҗҺж №жҚ®иҝҷз§ҚеҸҳеҢ–еҒҡеҮәеҜ№еә”зҡ„еҶізӯ–гҖӮжҲ‘е·Із»ҸзҹҘйҒ“HDFSдёӯnamenodeжҳҜйҖҡиҝҮdatanodeзҡ„еҝғи·іжңәеҲ¶жқҘе®һзҺ°дёҠиҝ°ж„ҹзҹҘзҡ„пјҢйӮЈд№ҲжҲ‘们еҸҜд»Ҙе…ҲеҒҮи®ҫZookeeperе…¶е®һд№ҹжҳҜе®һзҺ°дәҶзұ»дјјеҝғи·іжңәеҲ¶зҡ„еҠҹиғҪеҗ§пјҒ
жӣҙеӨҡй«ҳ并еҸ‘жһ¶жһ„зі»еҲ—иҝһиҪҪпјҢеҶ…е®№еҢ…жӢ¬пјҡjavaй«ҳ并еҸ‘гҖҒSOAгҖҒеҲҶеёғејҸйӣҶзҫӨгҖҒеӨҡзәҝзЁӢгҖҒRedisгҖҒж•°жҚ®еә“еҲҶеә“еҲҶиЎЁгҖҒиҙҹиҪҪеқҮиЎЎзӯүгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ