жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
applicationContextж–Ү件еҠ иҪҪе’ҢbeanжіЁеҶҢжөҒзЁӢ
вҖӢ SpringеҜ№дәҺд»ҺдәӢJavaејҖеҸ‘зҡ„boyжқҘиҜҙпјҢеҶҚзҶҹжӮүдёҚиҝҮдәҶпјҢеҜ№дәҺжҲ‘们иҝҷдёӘзүӣйҖјзҡ„жЎҶжһ¶зҡ„д»Ӣз»Қе°ұдёҚеңЁиҝҷйҮҢеӨҚиҝ°дәҶпјҢSpringиҝҷдёӘеӨ§жқӮзғ©пјҢжҖҺд№ҲеҺ»дҪҝз”ЁжҖҺд№ҲеҺ»й…ҚзҪ®пјҢеҗ„з§ҚзҷҫеәҰи°·жӯҢйғҪиғҪжҹҘеҲ°еҫҲеӨҡеӨ§зүӣж•ҷзЁӢпјҢдҪҶжҳҜпјҢеҪ“жҲ‘们жҢүзқҖж•ҷзЁӢдёҖжӯҘжӯҘзҡ„жҠҠspringзҡ„ејҖеҸ‘жЎҶжһ¶жҗӯе»әиө·жқҘзҡ„ж—¶еҖҷпјҢжңүжІЎжңүдёҖз§ҚжғіжҗһжҳҺзҷҪspringзҡ„еҶІеҠЁпјҢдёҮдәӢејҖеӨҙйҡҫпјҢе°ұиҰҒд»ҺејҖеӨҙејҖе§ӢпјҢиҖҢжҲ‘и®ӨдёәspringејҖеӨҙе°ұжҳҜеҰӮдҪ•еҠ иҪҪй…ҚзҪ®ж–Ү件пјҢ并еҲқе§ӢеҢ–й…ҚзҪ®ж–Ү件йҮҢйқўзҡ„beanеҪ“然д№ҹеҢ…жӢ¬дәҶжҲ‘们用注解ServiceгҖҒComponentзӯүжіЁи§ЈжіЁи§Јзҡ„beanпјҢspringеңЁе®№еҷЁеҗҜеҠЁзҡ„ж—¶еҖҷе°ұиҰҒеҺ»еҠ иҪҪиҝҷдәӣеҶ…е®№пјҢ然еҗҺз»ҹдёҖз®ЎзҗҶиҝҷдәӣbeanпјҲз»ҹдёҖз®ЎзҗҶзҡ„жҳҜ他们зҡ„bean definitionпјүпјҢиҝҷд№ҹе°ұжҳҜspringзҡ„дёҖдёӘйҮҚиҰҒжҰӮеҝөbeanзҡ„е®№еҷЁгҖӮ
вҖӢ applicationContext.xmlеҲ°еә•жҳҜеҰӮдҪ•еҠ иҪҪзҡ„е‘ўпјҹжҲ‘жҠҠд»–з®ҖеҢ–жҲҗд»ҘдёӢжөҒзЁӢпјҢеҪ“然дәҶжҜҸдёӘзҺҜиҠӮйҮҢSpringзҡ„е®һзҺ°йғҪжҳҜй”ҷз»јеӨҚжқӮзҡ„пјҢд№ҹжҳҜеҫҲдҪ©жңҚеҶҷSpringзҡ„еӨ§зҘһгҖӮ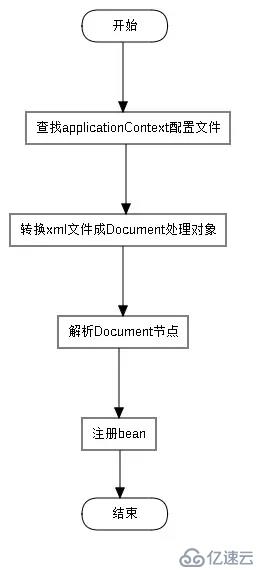
SpringеҲқе§ӢеҢ–
вҖӢ еҪ“жҲ‘们еҲқеӯҰSpringзҡ„ж•ҷзЁӢзҡ„ж—¶еҖҷпјҢж•ҷзЁӢйҮҢйқўиӮҜе®ҡдјҡжңүиҝҷж ·зҡ„дёҖжӯҘж“ҚдҪңпјҢе°ұжҳҜж–°е»әдёҖдёӘapplicationContext.xmlж–Ү件пјҢеҪ“然дәҶиҝҷжҳҜSpringйҮҢеҝ…йЎ»иҰҒжңүзҡ„дёҖдёӘж–Ү件пјҢеңЁиҝҷдёӘж–Ү件йҮҢйқўжҲ‘们еҸҜд»ҘиҝӣиЎҢbeanзҡ„й…ҚзҪ®зӯүзӯүе·ҘдҪңпјҢи®©SpringжқҘз®ЎзҗҶжҲ‘们зҡ„BeanгҖӮ然еҗҺпјҢиҝҷдёӘж–Ү件ж”ҫеңЁе“ӘйҮҢд№ҹжҳҜдёӘжҜ”иҫғ讲究зҡ„дәӢжғ…пјҢеҸҜиғҪеҜ№дәҺеҲқеӯҰиҖ…жқҘиҜҙеҸҜйўқиғҪдјҡеҫҖWEB-INFж–Ү件еӨ№дёҖж”ҫе°ұдәҶдәӢдәҶпјҢзЎ®е®һиҝҷж ·жҳҜеҸҜд»Ҙзҡ„пјҢеӣ дёәSpringй»ҳи®Өзҡ„дҪҚзҪ®е°ұжҳҜиҝҷдёӘпјҢдҪҶжҳҜжҲ‘们дёҖиҲ¬дёҚиҝҷд№ҲеҒҡпјҢдёҖиҲ¬дјҡжҠҠиҝҷдёӘж–Ү件ж”ҫеңЁresourceйҮҢйқўпјҢйӮЈиҝҷж ·еӯҗеҒҡзҡ„иҜқпјҢдҪ е°ұиҰҒжҢҮе®ҡдҪҚзҪ®пјҢи®©SpringзҹҘйҒ“дҪ иҝҷдёӘж–Ү件зҡ„дҪҚзҪ®пјҢиҝҷе°ұжңүдәҶдёӢйқўдёҖж®өд»Јз ҒпјҢжҲ‘们зҡ„SpringйЎ№зӣ®йғҪдјҡеңЁweb.xmlй…ҚзҪ®иҝҷж ·зҡ„д»Јз Ғпјҡ
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>йӮЈй—®йўҳжқҘдәҶпјҢеҪ“йЎ№зӣ®еҗҜеҠЁзҡ„ж—¶еҖҷпјҢspringжҳҜжҖҺд№ҲеҺ»еҲқе§ӢеҢ–еә”з”Ёзҡ„дёҠдёӢж–Үзҡ„е‘ўпјҹзӯ”жЎҲе°ұеңЁзұ»ContextLoader.javaйҮҢйқўгҖӮеҪ“TomcatеҗҜеҠЁж—¶еҖҷдјҡи°ғз”ЁиҜҘзұ»йҮҢйқўзҡ„дёҖдёӘж–№жі•public WebApplicationContext initWebApplicationContext(ServletContext servletContext),иҝҷдёӘж–№жі•дё»иҰҒе®ҢжҲҗпјҢж №жҚ®жҲ‘们еңЁweb.xmlйҮҢйқўй…ҚзҪ®зҡ„contextConfigLocationеҲқе§ӢеҢ–springзҡ„webзҡ„еә”з”ЁдёҠдёӢж–ҮгҖӮе…·дҪ“зңӢдёӢж”№ж–№жі•зҡ„е®һзҺ°(йқһе®Ңж•ҙд»Јз ҒпјҢPS:з”ұдәҺеӨӘй•ҝдәҶ)пјҡ
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
......
this.context = createWebApplicationContext(servletContext);//дё»иҰҒд»Јз ҒпјҢеҲӣе»әwebеә”з”ЁдёҠдёӢж–Ү
......
configureAndRefreshWebApplicationContext(cwac, servletContext);//й…ҚзҪ®еҸӮ数并и°ғз”ЁеҲқе§ӢеҢ–ж–№жі•
......
}еңЁиҝҷдёӘж–№жі•йҮҢйқўжңүдёӨеҸҘйҮҚиҰҒд»Јз ҒпјҢ第дёҖеҸҘcreateWebApplicationContext(servletContext)пјҢиҝҷдёӘдјҡж №жҚ®дҪ й…ҚзҪ®зҡ„contextClassеҲӣе»әдёҖдёӘWebApplicationContextеҜ№иұЎпјҢдҪҶжҳҜжҲ‘们дёҖиҲ¬дёҚдјҡй…ҚзҪ®иҝҷдёӘеҸӮж•°пјҢжүҖд»ҘSpringй»ҳи®ӨдјҡеҲӣе»әдёҖдёӘXMLWebApplicationContextеҜ№иұЎпјҢиҖҢиҝҷдёӘе°ұжҳҜеҗҺз»ӯж“ҚдҪңзҡ„зҡ„йҮҚиҰҒеҜ№иұЎпјҢ然еҗҺжҺҘдёӢжқҘдёҖеҸҘйҮҚиҰҒд»Јз ҒconfigureAndRefreshWebApplicationContext(cwac, servletContext)иҝҷдёӘе°ұдјҡеҺ»иҜ»еҸ–жҲ‘们еңЁweb.xmlйҮҢйқўй…ҚзҪ®зҡ„еҸӮ数并setеҲ°еҸҳйҮҸйҮҢеӨҙеҺ»пјҢиҝҷж ·Springе°ұиғҪжүҫеҲ°жҲ‘们项зӣ®зҡ„applicationContext.xmlж–Ү件дәҶпјҢеҲ°еә•еҰӮдҪ•жүҫеҲ°дёӢйқўдјҡи®ІгҖӮжҺҘдёӢжқҘжҲ‘们жқҘзңӢдёӢconfigureAndRefreshWebApplicationContextж–№жі•зҡ„е®һзҺ°еҰӮдёӢпјҡ
protected void configureAndRefreshWebApplicationContext(ConfigurableWebApplicationContext wac, ServletContext sc) {
if (ObjectUtils.identityToString(wac).equals(wac.getId())) {
// The application context id is still set to its original default value
// -> assign a more useful id based on available information
String idParam = sc.getInitParameter(CONTEXT_ID_PARAM);
if (idParam != null) {
wac.setId(idParam);
}
else {
// Generate default id...
wac.setId(ConfigurableWebApplicationContext.APPLICATION_CONTEXT_ID_PREFIX +
ObjectUtils.getDisplayString(sc.getContextPath()));
}
}
wac.setServletContext(sc);
String configLocationParam = sc.getInitParameter(CONFIG_LOCATION_PARAM);
if (configLocationParam != null) {
wac.setConfigLocation(configLocationParam);
}
// The wac environment's #initPropertySources will be called in any case when the context
// is refreshed; do it eagerly here to ensure servlet property sources are in place for
// use in any post-processing or initialization that occurs below prior to #refresh
ConfigurableEnvironment env = wac.getEnvironment();
if (env instanceof ConfigurableWebEnvironment) {
((ConfigurableWebEnvironment) env).initPropertySources(sc, null);
}
customizeContext(sc, wac);
wac.refresh();
}еңЁиҝҷдёӘж–№жі•дёӯжҲ‘们еҸӘиҰҒе…іжіЁдёӨдёӘең°ж–№пјҢ第дёҖдёӘпјҡ
String configLocationParam = sc.getInitParameter(CONFIG_LOCATION_PARAM);
if (configLocationParam != null) {
wac.setConfigLocation(configLocationParam);
}иҝҷеқ—д»Јз Ғеқ—е°ұжҳҜпјҢи®ІжҲ‘们й…ҚзҪ®еңЁweb.xmlйҮҢйқўзҡ„еҸӮж•°setеҲ°жҲ‘们зҡ„еҸҳйҮҸдёӯеҺ»гҖӮ第дәҢдёӘең°ж–№е°ұжҳҜпјҡ
wac.refresh();и°ғз”ЁиҝҷдёӘжү§иЎҢеҗҺз»ӯзҡ„еҠ иҪҪж–Ү件ж“ҚдҪңзӯүеҗҺз»ӯж“ҚдҪңгҖӮ
SpringжҳҜеҰӮдҪ•жүҫеҲ°applicationContext.xmlж–Ү件
вҖӢ е…¶е®һпјҢд»ҺrefreshеҲ°SpringйҮҢеҺ»жҹҘжүҫй…ҚзҪ®ж–Ү件и·Ҝеҫ„д№Ӣй—ҙпјҢжңүеҫҲеӨҡжӯҘйӘӨпјҢиҝҷдәӣд№ҹйғҪиҰҒиҠұзӮ№ж—¶й—ҙеҺ»зҗҶи§Јзҡ„пјҢеңЁиҝҷйҮҢдёҚеұ•ејҖи®ІпјҢжҲ‘们еҸӘиҰҒзҹҘйҒ“пјҢXmlWebApplicationContextдјҡ委жүҳз»ҷXmlBeanDefinitionReaderзұ»еҺ»и§Јжһҗй…ҚзҪ®ж–Ү件пјҢеңЁXmlWebApplicationContextзұ»йҮҢйқўжңүдёӘж–№жі•loadBeanDefinitionsеҰӮдёӢпјҡ
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws IOException {
String[] configLocations = getConfigLocations();
if (configLocations != null) {
for (String configLocation : configLocations) {
reader.loadBeanDefinitions(configLocation);
}
}
}иҜҘж–№жі•е°ұжҳҜе°ҶдёҖдёӘдёӘзҡ„й…ҚзҪ®ж–Ү件委жүҳз»ҷXmlBeanDefinitionReaderеҺ»и§Јжһҗй…ҚзҪ®ж–Ү件пјҢдҪҶжҳҜи§Јжһҗд№ӢеүҚжңүеҸҘд»Јз ҒString[] configLocations = getConfigLocations();иҝҷдёӘе°ұжҳҜжҹҘжүҫжҲ‘们зҡ„й…ҚзҪ®зҡ„ж–Ү件зҡ„ж–№жі•пјҢ
protected String[] getConfigLocations() {
return (this.configLocations != null ? this.configLocations : getDefaultConfigLocations());
}е®һзҺ°еҫҲз®ҖеҚ•пјҢе°ұжҳҜжҲ‘们жңүй…ҚзҪ®иҜҘдҪҚзҪ®ең°еқҖе°ұдјҡеҺ»иҜ»жҲ‘们й…ҚзҪ®зҡ„и·Ҝеҫ„пјҢеҗҰеҲҷе°ұдјҡеҺ»иҜ»й»ҳи®Өзҡ„й…ҚзҪ®ж–Ү件и·Ҝеҫ„пјҢиҝҷе°ұжҳҜејҖзҜҮиҜҙеҲ°зҡ„иҰҒжҳҜжІЎй…ҚзҪ®и·Ҝеҫ„д№ҹиғҪиҜ»еҸ–еҲ°й…ҚзҪ®ж–Ү件пјҢеүҚжҸҗе°ұжҳҜиҰҒи·ҹSpringй»ҳи®Өе®ҡд№үеҘҪзҡ„ж–Ү件и·Ҝеҫ„еҸҠж–Ү件еҗҚдҝқжҢҒдёҖиҮҙжүҚиЎҢгҖӮgetDefaultConfigLocationsеҮҪж•°зҡ„е®һзҺ°д№ҹеҫҲз®ҖеҚ•пјҡ
/** Default config location for the root context */
public static final String DEFAULT_CONFIG_LOCATION = "/WEB-INF/applicationContext.xml";
/** Default prefix for building a config location for a namespace */
public static final String DEFAULT_CONFIG_LOCATION_PREFIX = "/WEB-INF/";
/** Default suffix for building a config location for a namespace */
public static final String DEFAULT_CONFIG_LOCATION_SUFFIX = ".xml";
protected String[] getDefaultConfigLocations() {
if (getNamespace() != null) {
return new String[] {DEFAULT_CONFIG_LOCATION_PREFIX + getNamespace() + DEFAULT_CONFIG_LOCATION_SUFFIX};
}
else {
return new String[] {DEFAULT_CONFIG_LOCATION};
}
}еҰӮжһңй…ҚзҪ®дәҶnamespaceе°ұдјҡеҺ»жүҫиҝҷдёӘеҗҚеӯ—зҡ„xmlй…ҚзҪ®ж–Ү件пјҢеҰӮжһңжІЎжңүй…ҚзҪ®е°ұеҺ»жүҫй»ҳи®Өзҡ„й…ҚзҪ®ж–Ү件гҖӮжүҖд»ҘдёҚз®ЎеҰӮдҪ•пјҢиҝҷдёӘй…ҚзҪ®ж–Ү件жҳҜеҝ…йЎ»еңЁspringйЎ№зӣ®дёӯзҡ„гҖӮиҮіжӯӨпјҢй…ҚзҪ®ж–Ү件еҹәжң¬е°Ҷе®ҢпјҢжҺҘдёӢжқҘе°ұжҳҜйҮҚеӨҙжҲҸдәҶпјҢе°ұжҳҜи§Јжһҗxmlд»ҘеҸҠxmlйҮҢйқўзҡ„иҠӮзӮ№пјҢ并注еҶҢеҲ°springзҡ„beanе®№еҷЁдёӯеҺ»гҖӮ
е°Ҷxmlж–Ү件иҪ¬жҲҗDocumentеӨ„зҗҶеҜ№иұЎ
еҰӮдҪ•е°ҶxmlиҪ¬жҲҗDocumentеҜ№иұЎпјҢиҝҷдёӘд№ҹжҳҜеҫҲеӨҚжқӮзҡ„ж“ҚдҪңпјҢйҰ–е…Ҳе°ҶresourceиҜ»еҸ–InputStreamжөҒпјҢеңЁе°ҶInputStreamжөҒеҢ…иЈ…жҲҗInputSourceеҜ№иұЎпјҢеңЁеӨ„зҗҶжҲҗDocumentеҜ№иұЎпјҢзӣҙжҺҘдёҠд»Јз Ғпјҡ
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();//иҺ·еҸ–жөҒ
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}жҺҘдёӢжқҘеҸҲеҲ°doLoadBeanDefinitions(inputSource, encodedResource.getResource());ж–№жі•еҺ»дәҶпјҢиҜҘж–№жі•е°ұжҳҜз”ҹжҲҗDoucumentеҜ№иұЎзҡ„пјҢ然еҗҺе°ұжҳҜи§Јжһҗе…·дҪ“зҡ„иҠӮзӮ№дәҶпјҢйғЁеҲҶжәҗз ҒеҰӮдёӢпјҡ
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
Document doc = doLoadDocument(inputSource, resource);//иҝҷе°ұжҳҜи§ЈжһҗжҲҗDocumentеҜ№иұЎзҡ„ж“ҚдҪң
return registerBeanDefinitions(doc, resource);
......
}и§ЈжһҗDocumentдёҚеұ•ејҖи®ІдәҶпјҢдёҚжҳҜжң¬зҜҮзҡ„йҮҚзӮ№пјҢйҮҚзӮ№жҳҜдёӢйқўзҡ„пјҢspringеҰӮдҪ•и§Јжһҗxmlж–Ү件зҡ„beanеҸҠжіЁи§Јзҡ„bean然еҗҺжіЁеҶҢеҲ°е®№еҷЁдёӯеҺ»пјҢregisterBeanDefinitions(doc, resource)жҳҜдёӢйқўзҡ„йҮҚзӮ№гҖӮ
и§ЈжһҗDocumentйҮҢйқўзҡ„иҠӮзӮ№
XmlBeanDfinitionReaderжң¬иә«еҸҲдёҚжҳҜзӣҙжҺҘеҸ–и§Јжһҗdocumentзҡ„пјҢд»–жҳҜ委жүҳз»ҷдәҶDefaultBeanDefinitionDocumentReaderзұ»еҺ»е®һзҺ°пјҢжәҗд»Јз ҒдёӯпјҢдјҡеҺ»еҲӣе»әDefaultBeanDefinitionDocumentReaderеҜ№иұЎе®һдҫӢпјҢ然еҗҺи°ғз”Ёе®һдҫӢзҡ„жіЁеҶҢж–№жі•пјҢд»Јз ҒеҰӮдёӢпјҡ
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}йҰ–е…ҲпјҢжҲ‘们еҝ…йЎ»зҹҘйҒ“пјҢspringзҡ„xmlж–Ү件йҮҢйқўжңүдёӨз§Қзұ»еһӢзҡ„иҠӮзӮ№пјҢдёҖз§ҚжҳҜй»ҳи®ӨиҠӮзӮ№пјҢзӣёеҜ№дәҺй»ҳи®ӨиҠӮзӮ№д№ӢеӨ–зҡ„иҠӮзӮ№з»ҹз§°иҮӘе®ҡд№үиҠӮзӮ№пјҢиҝҷеҸҜд»Ҙд»Һжәҗз ҒйҮҢйқўзҹҘйҒ“пјҢиҖҢй»ҳи®ӨиҠӮзӮ№жңүд»ҘдёӢеҮ дёӘпјҡbeansгҖҒimportгҖҒaliasгҖҒbeanиҝҷеҮ дёӘиҠӮзӮ№жҳҜй»ҳи®ӨиҠӮзӮ№пјҢиҖҢзӣёеҜ№дәҺиҝҷеҮ дёӘиҠӮзӮ№д№ӢеӨ–зҡ„йғҪжҳҜй»ҳи®ӨиҠӮзӮ№пјҢapplicationContextйҮҢйқўжңүеҮ дёӘиҮӘе®ҡд№үиҠӮзӮ№пјҢеҰӮдёӢпјҡproperty-placeholderгҖҒproperty-overrideгҖҒannotation-configгҖҒcomponent-scanгҖҒload-time-weaverгҖҒspring-configuredгҖҒmbean-exportгҖҒmbean-serverпјҢиҝҷйҮҢйқўеёёи§Ғзҡ„жңүcomponent-scanзӯүпјҢдёәд»Җд№ҲspringиҰҒеҲҶжҲҗй»ҳи®Өе’ҢиҮӘе®ҡд№үиҠӮзӮ№е‘ўпјҢжҳҜеӣ дёәиҮӘе®ҡд№үиҠӮзӮ№йғҪжңүзү№е®ҡзҡ„дёҡеҠЎпјҢжҜ”еҰӮcomponent-scanпјҢд»–жҳҜеҺ»жү«жҸҸзЁӢеәҸеҢ…пјҢеҠ иҪҪз”ЁжіЁи§Је®ҡд№үзҡ„beanпјҢдҫӢеҰӮејҖеҸ‘дёӯзҡ„serviceзӯүbeanпјҢжүҖд»ҘиҝҷдәӣиҮӘе®ҡд№үиҠӮзӮ№йғҪй…ҚеӨҮдәҶи§ЈжһҗеҷЁпјҢиҝҷдәӣи§ЈжһҗеҷЁйў„е…ҲеҲқе§ӢеҢ–еҘҪзҡ„пјҢи§ЈжһҗеҲ°д»Җд№ҲиҠӮзӮ№е°ұеҺ»иҺ·еҸ–зӣёеә”зҡ„и§ЈжһҗеҷЁеҺ»еӨ„зҗҶзӣёеә”зҡ„дёҡеҠЎпјҢиҮӘе®ҡд№үиҠӮзӮ№и§ЈжһҗеҷЁй…ҚзҪ®еҰӮдёӢпјҡ
@Override
public void init() {
registerBeanDefinitionParser("property-placeholder", new PropertyPlaceholderBeanDefinitionParser());
registerBeanDefinitionParser("property-override", new PropertyOverrideBeanDefinitionParser());
registerBeanDefinitionParser("annotation-config", new AnnotationConfigBeanDefinitionParser());
registerBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());
registerBeanDefinitionParser("load-time-weaver", new LoadTimeWeaverBeanDefinitionParser());
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
registerBeanDefinitionParser("mbean-export", new MBeanExportBeanDefinitionParser());
registerBeanDefinitionParser("mbean-server", new MBeanServerBeanDefinitionParser());
}д»Һд»ҘдёҠжәҗз ҒеҲҶжһҗпјҢжҲ‘们еҸҜд»Ҙеҫ—еҲ°дёҖдёӘжҺЁи®әпјҡ
жҲ‘们иҮӘе·ұеҸҜд»ҘиҮӘе®ҡд№үxmlзҡ„иҠӮзӮ№пјҢspringеҸҜд»ҘеҺ»и§ЈжһҗжҲ‘们иҮӘе®ҡд№үзҡ„xmlиҠӮзӮ№гҖӮ
е…¶е®һиҝҷдёӘжҺЁи®әжҳҺжҳҫжҲҗз«ӢпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°springйҮҢйқўеҲ°еӨ„йғҪжҳҜиҝҷз§ҚиҮӘе®ҡд№үзҡ„иҠӮзӮ№зҡ„гҖӮ
иҝҷйҮҢеҸҲеј•з”іеҮәдёҖдёӘй—®йўҳпјҡspringжҖҺд№ҲеҺ»еҢәеҲҶй»ҳи®ӨиҠӮзӮ№е’ҢиҮӘе®ҡд№үиҠӮзӮ№зҡ„е‘ўпјҹзӯ”жЎҲжҳҜйҖҡиҝҮиҠӮзӮ№зҡ„namespaceUriеұһжҖ§еҺ»еҲӨж–ӯпјҢnamespaceUriжҳҜд»Җд№ҲдёңдёңпјҹжҲ‘们жқҘзңӢдёӢпјҢй»ҳи®ӨиҠӮзӮ№зҡ„namespaceUriжҳҜжҖҺд№Ҳж ·зҡ„пјҢжәҗз ҒжҳҜиҝҷж ·е®ҡд№үзҡ„пјҡ
public static final String BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";жҳҜдёҚжҳҜеҫҲзҶҹжӮүпјҢиҝҷиҙ§е°ұжҳҜжҲ‘们й…ҚзҪ®ж–Ү件йҮҢйқўзҡ„beansж №иҠӮзӮ№дјҡеҶҷзҡ„дёңиҘҝпјҢеҰӮдёӢпјҡ
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
</beans>дҪҶжҳҜй—®йўҳеҸҲжқҘдәҶпјҢеӯҗиҠӮзӮ№дёҠжҲ‘д»¬ж №жң¬жІЎй…ҚзҪ®иҝҷиҙ§пјҢдҪҶжҳҜд№ҹиғҪиҜ»еҸ–еҲ°пјҢд»ҘдёӢжҳҜдёӘдәәжҺЁи®әпјҡ
еӯҗиҠӮзӮ№дјҡ继жүҝзҲ¶иҠӮзӮ№зҡ„еұһжҖ§пјҢиҝҷе°ұиҜҙзҡ„йҖҡпјҢеӯҗиҠӮзӮ№еҚідҪҝжІЎй…ҚзҪ®йӮЈдёҖе ҶдёңиҘҝд№ҹиғҪеҲӨж–ӯдёәй»ҳи®ӨиҠӮзӮ№гҖӮ
жҺҘдёӢжқҘпјҢе°ұжҳҜи§ЈжһҗDocumentзҡ„е…ғзҙ пјҢд»Һrootе…ғзҙ ејҖе§Ӣи§ЈжһҗпјҢиҝҷж—¶еҖҷspringжҳҜеҲӣе»әдәҶдёҖдёӘи§Јжһҗзұ»зҡ„д»ЈзҗҶзұ»пјҢжүҖжңүзҡ„жҜ”иҫғе’Ңи§Јжһҗж“ҚдҪңйғҪжңүиҜҘзұ»е®ҢжҲҗпјҢжҲ‘们жқҘзңӢдёӢspringзҡ„жәҗз Ғе®һзҺ°пјҡ
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}и§ЈжһҗиҠӮзӮ№зҡ„иҝҮзЁӢжҳҜдёӘйҖ’еҪ’зҡ„иҝҮзЁӢпјҢжҜҸж¬ЎйғҪиҰҒи®°еҪ•иҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№пјҢйҰ–е…ҲдјҡеҲӣе»әдёҖдёӘdelegateеҜ№иұЎпјҢ然еҗҺеҶҚеҺ»и§ЈжһҗиҠӮзӮ№пјҢи°ғз”ЁparseBeanDefinitions(root, this.delegate);иҝҷдёӘж–№жі•иҝӣиЎҢи§Јжһҗж“ҚдҪңпјӣ
继з»ӯжқҘзңӢдёӢparseBeanDefinitions(root, this.delegate);зҡ„е®һзҺ°пјҡ
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}еҫҲз®ҖеҚ•пјҢеҸҜд»ҘеҫҲжё…жҷ°зҡ„зңӢеҮәпјҢи§ЈжһҗжҳҜеҲҶй»ҳи®ӨиҠӮзӮ№е’ҢиҮӘе®ҡд№үиҠӮзӮ№еҲҶејҖи§Јжһҗзҡ„пјҢиҖҢиҮӘе®ҡд№үзҡ„иҠӮзӮ№зҡ„и§Јжһҗе…¶е®һе°ұжҳҜжүҫеҲ°еҜ№еә”зҡ„и§ЈжһҗеҷЁеҗ„иҮӘеӨ„зҗҶеҜ№еә”зҡ„дёҡеҠЎпјҢеҰӮcomponent-scanдјҡжүҫеҲ°ComponentScanBeanDefinitionParserзұ»жқҘеӨ„зҗҶеҜ№еә”зҡ„жү«жҸҸеҢ…жіЁеҶҢbeanзҡ„ж“ҚдҪңпјҢиҖҢй»ҳи®Өзҡ„иҠӮзӮ№зҡ„еӨ„зҗҶжңүеҰӮдёӢеҮ з§ҚпјҢд»Јз ҒеҰӮдёӢпјҡ
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
//еӨ„зҗҶimport
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
//еӨ„зҗҶalias
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
//еӨ„зҗҶbean
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
//еӨ„зҗҶbeans
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}importзҡ„еӨ„зҗҶзӣёеҜ№е…¶д»–еҮ з§ҚжҜ”иҫғеӨҚжқӮзӮ№пјҢдҪҶжңҖз»ҲиҝҳжҳҜеӨ„зҗҶеҸҳжҲҗе…¶д»–3з§Қзҡ„еӨ„зҗҶпјҢиҖҢbeansзҡ„еӨ„зҗҶе°ұйҮҚж–°йҖ’еҪ’дёҠйқўжҸҗеҲ°зҡ„ж–№жі•пјҢжңҖйҮҚиҰҒзҡ„жҳҜbeanзҡ„еӨ„зҗҶпјҢbeanзҡ„еӨ„зҗҶе…¶е®һе°ұжҳҜдёӢйқўиҰҒи®Ізҡ„еҶ…е®№пјҢи§Јжһҗbean并注еҶҢbean definitionзҡ„иҝҮзЁӢгҖӮ
жіЁеҶҢbean
з»ҲдәҺеҲ°дәҶжңҖеҗҺдёҖдёӘеҶ…е®№дәҶпјҢд№ҹжҳҜжңҖйҮҚиҰҒзҡ„дёҖдёӘеҶ…е®№пјҢдёҠйқўи®Ізҡ„жүҖжңүйғҪжҳҜдёәдәҶиҝҷдёӘиҖҢжңҚеҠЎзҡ„пјҢиҜ»еҸ–й…ҚзҪ®ж–Ү件д№ҹжҳҜдёәдәҶеҠ иҪҪbeanпјҢ然еҗҺжіЁеҶҢеҲ°springзҡ„е®№еҷЁйҮҢйқўпјҢи®©springз»ҹдёҖз®ЎзҗҶжҲ‘们е®ҡд№үзҡ„beanгҖӮеӨ§е®¶йғҪеҫҲжҳҺзҷҪпјҢspringзҡ„beanзҡ„е®№еҷЁпјҢдҪҶжҳҜеҰӮжһңжІЎжңүеҺ»зңӢжәҗз Ғзҡ„иҜқпјҢжҳҜдёҚжҳҜйғҪи®ӨдёәspringпјҢжҳҜжҠҠжҜҸдёӘе®һдҫӢеҜ№иұЎжіЁеҶҢеҲ°е®№еҷЁйҮҢйқўз„¶еҗҺз»ҹдёҖз®ЎзҗҶзҡ„пјҹе…¶е®һпјҢspringе…¶е®һдёҚжҳҜиҝҷж ·зҡ„еҒҡзҡ„пјҢspringжіЁеҶҢзҡ„beanжңҖз»ҲжҳҜдёӘbeanзҡ„е®ҡд№үпјҢеҚіBeanDefinitionиҝҷдёӘе®һдҫӢпјҢ并дёҚжҳҜдёҖдёӘдёӘзұ»зҡ„е…·дҪ“е®һдҫӢгҖӮжҲ‘们еҸҜд»Ҙз®ҖеҚ•зҗҶи§ЈиҝҷдәӣжіЁеҶҢзҡ„bean definitionжҳҜдёәдәҶж–№дҫҝеҗҺз»ӯзҡ„е®һдҫӢеҢ–beanиҝӣиЎҢзҡ„дёҖжӯҘеҮҶеӨҮж“ҚдҪңгҖӮжүҖи°“зҡ„жіЁеҶҢпјҢе…¶е®һе°ұжҳҜжҠҠеҗ„з§Қиҝҷдәӣе®һдҫӢз”ЁдёҖдёӘMapжқҘз®ЎзҗҶпјҢжүҖд»ҘпјҢspringзҡ„beanзҡ„е®№еҷЁзҡ„еә•еұӮеӯҳеӮЁе…¶е®һжҳҜз”ЁMapжқҘе®һзҺ°зҡ„пјҲиҝҷдёӘд№ӢеүҚйқўиҜ•иў«й—®иҝҮпјүгҖӮжҺҘдёӢжқҘпјҢзңӢзңӢжәҗз Ғзҡ„е®һзҺ°пјҡ
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
//иҝҷдёӘжҳҜеҜ№bean definitionиҝӣиЎҢдҝ®ж”№еҰӮжһңжңүеҝ…иҰҒпјҢеҰӮй…ҚзҪ®дәҶд»ЈзҗҶзҡ„beanзӯү
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}д»Һжәҗз ҒйҮҢеҸҜд»ҘзңӢеҮәпјҢbeanзҡ„и§Јжһҗзұ»д»ЈзҗҶдјҡеҺ»и§Јжһҗeleе…ғзҙ пјҢ并иҝ”еӣһдёҖдёӘBeanDefinitionHolderзҡ„е®һдҫӢпјҢиҖҢиҝҷдёӘBeanDefinitionHolderжҲ‘们еҸҜд»Ҙз®ҖеҚ•зҗҶи§ЈдёәBeanDefinitionеҜ№иұЎзҡ„жҢҒжңүеҜ№иұЎгҖӮ然еҗҺпјҢйҖҡиҝҮи°ғз”ЁBeanDefinitionReaderUtilsе·Ҙе…·зұ»еҺ»жү§иЎҢе…·дҪ“зҡ„жіЁеҶҢж“ҚдҪңгҖӮ继з»ӯзңӢBeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry())иҝҷдёӘзҡ„е®һзҺ°еҰӮдёӢпјҡ
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}д»ҺдёҠйқўд»Јз ҒдёӯпјҢspringжіЁеҶҢbeanе…¶е®һжіЁеҶҢзҡ„жҳҜBeanDfinitionпјҢжіЁеҶҢbeanе…¶е®һе°ұжҳҜз»‘е®ҡbeanзҡ„nameе’ҢBeanDfinitionзҡ„е…ізі»гҖӮйӮЈд№ҲпјҢжҲ‘们继з»ӯзңӢзңӢbeanзҡ„е…·дҪ“жіЁеҶҢиҝҮзЁӢпјҢд»Јз ҒеҰӮдёӢпјҡ
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition oldBeanDefinition;
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (this.logger.isWarnEnabled()) {
this.logger.warn("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(oldBeanDefinition)) {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<String>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<String>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
this.manualSingletonNames.remove(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (oldBeanDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
}иҝҷж®өд»Јз ҒиҝҳжҳҜжҜ”иҫғе®№жҳ“зҗҶи§Јзҡ„пјҢйҰ–е…Ҳе…ҲеҲӨж–ӯе®№еҷЁйҮҢйқўжңүжІЎиҝҷдёӘbeanпјҢжІЎжңүзҡ„иҜқеҲӨж–ӯжҳҜеҗҰеңЁеҲӣе»әиҝҮзЁӢпјҢеҰӮжһңдёҚжҳҜзӣҙжҺҘе°ҶиҜҘbeanжіЁеҶҢеҲ°е®№еҷЁйҮҢ并и®ҫзҪ®е…¶д»–дҝЎжҒҜгҖӮз®ҖеҚ•зҡ„иҜҙпјҢе…¶е®һе°ұжҳҜе°ҶдёҖдёӘдёӘзҡ„beanзҡ„е®ҡд№үи·ҹbeanзҡ„еҗҚз§°з»‘е®ҡиө·жқҘпјҢеӯҳж”ҫеҲ°mapйҮҢйқўгҖӮиҮіжӯӨпјҢspringеҠ иҪҪapplicationContext.xmlзҡ„еӨ§иҮҙжөҒзЁӢе·Із»ҸиҜҙжё…жҘҡдәҶпјҢдёҚиҝҮиҝҷйҮҢйқўж¶үеҸҠеҫҲеӨҡжҜ”иҫғз»ҶеҸҲйҡҫжҮӮзҡ„зұ»е№¶жІЎжңүдҪ“зҺ°еҮәжқҘпјҢжңҖз»ҲиҰҒзҡ„жҳҜжҗһжё…жҘҡspringеҠ иҪҪй…ҚзҪ®ж–Ү件зҡ„иҝҮзЁӢе’ҢжіЁеҶҢbeanзҡ„иҝҮзЁӢгҖӮиҰҒжғіж·ұе…ҘпјҢеҸҜд»Ҙ继з»ӯз ”иҜ»жәҗз ҒгҖӮ
и§үеҫ—дёҚй”ҷиҜ·зӮ№иөһж”ҜжҢҒпјҢж¬ўиҝҺз•ҷиЁҖжҲ–иҝӣжҲ‘зҡ„дёӘдәәзҫӨ855801563йўҶеҸ–гҖҗжһ¶жһ„иө„ж–ҷдё“йўҳзӣ®еҗҲйӣҶ90жңҹгҖ‘гҖҒгҖҗBATJTMDеӨ§еҺӮJAVAйқўиҜ•зңҹйўҳ1000+гҖ‘пјҢжң¬зҫӨдё“з”ЁдәҺеӯҰд№ дәӨжөҒжҠҖжңҜгҖҒеҲҶдә«йқўиҜ•жңәдјҡпјҢжӢ’з»қе№ҝе‘ҠпјҢжҲ‘д№ҹдјҡеңЁзҫӨеҶ…дёҚе®ҡжңҹзӯ”йўҳгҖҒжҺўи®ЁгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ