жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–ҮдёәеҺҹеҲӣдҪңе“ҒпјҢйҰ–еҸ‘дәҺеҫ®дҝЎе…¬дј—еҸ·пјҡгҖҗеқӮжң¬е…Ҳз”ҹгҖ‘пјҢеҰӮйңҖиҪ¬иҪҪиҜ·еңЁж–ҮйҰ–жҳҺжҳҫдҪҚзҪ®ж ҮжҳҺвҖңиҪ¬иҪҪдәҺеҫ®дҝЎе…¬дј—еҸ·пјҡгҖҗеқӮжң¬е…Ҳз”ҹгҖ‘вҖқпјҢеҗҰеҲҷиҝҪ究其法еҫӢиҙЈд»»гҖӮ
еҫ®дҝЎж–Үз« ең°еқҖпјҡе®һжҲҳз®—жі•вҖ”вҖ”еӨҡеҸүж ‘е…Ёи·Ҝеҫ„йҒҚеҺҶ
жң¬ж–Үз ”з©¶зҡ„жҳҜеҰӮдҪ•еҜ№дёҖдёӘеӨҡеҸүж ‘иҝӣиЎҢе…Ёи·Ҝеҫ„зҡ„йҒҚеҺҶпјҢ并иҫ“еҮәе…Ёи·Ҝеҫ„з»“жһңгҖӮиҜҘй—®йўҳзҡ„з ”з©¶еҸҜд»Ҙз”ЁеңЁпјҡTrieж ‘дёӯжҹҘзңӢжүҖжңүеӯ—е…ёеҖјиҝҷдёӘй—®йўҳдёҠгҖӮжң¬ж–Үе°ҶеҜ№иҜҘй—®йўҳиҝӣиЎҢиҜҰз»Ҷзҡ„жЁЎжӢҹеҸҠиҝӣиЎҢд»Јз Ғе®һзҺ°пјҢи®Ёи®әдәҶйҖ’еҪ’е’ҢйқһйҖ’еҪ’дёӨз§Қж–№жі•дјҳеҠЈе№¶еҲҶеҲ«иҝӣиЎҢе®һзҺ°пјҢеҰӮжһңиҜ»иҖ…еҜ№иҝҷдёӨз§Қж–№жі•зҡ„дјҳеҠЈдёҚж„ҹе…ҙи¶ЈеҸҜзӣҙжҺҘи·іеҲ°й—®йўҳжһ„е»әз« иҠӮиҝӣиЎҢйҳ…иҜ»гҖӮж–Үз« иҫғй•ҝпјҢжҺЁиҚҗеӨ§е®¶е…Ҳ收и—ҸеҶҚиҝӣиЎҢйҳ…иҜ»гҖӮ
иҝҷдёӘй—®йўҳзҹҘд№ҺдёҠе·Із»ҸжңүдәҶеҫҲеӨҡзӯ”жЎҲпјҢhttps://www.zhihu.com/question/20278387
еңЁе…¶еҹәзЎҖдёҠжҲ‘иҝӣиЎҢдәҶдёҖжіўжҖ»з»“пјҡ
е°ҶдёҖдёӘй—®йўҳеҲҶи§ЈдёәиӢҘе№ІзӣёеҜ№е°ҸдёҖзӮ№зҡ„й—®йўҳпјҢйҒҮеҲ°йҖ’еҪ’еҮәеҸЈеҶҚеҺҹи·Ҝиҝ”еӣһпјҢеӣ жӯӨеҝ…йЎ»дҝқеӯҳзӣёе…ізҡ„дёӯй—ҙеҖјпјҢиҝҷдәӣдёӯй—ҙеҖјеҺӢе…Ҙж ҲдҝқеӯҳпјҢй—®йўҳ规模иҫғеӨ§ж—¶дјҡеҚ з”ЁеӨ§йҮҸеҶ…еӯҳгҖӮ
жү§иЎҢж•ҲзҺҮй«ҳпјҢиҝҗиЎҢж—¶й—ҙеҸӘеӣ еҫӘзҺҜж¬Ўж•°еўһеҠ иҖҢеўһеҠ пјҢжІЎд»Җд№ҲйўқеӨ–ејҖй”ҖгҖӮз©әй—ҙдёҠжІЎжңүд»Җд№ҲеўһеҠ
йҖ’еҪ’е®№жҳ“дә§з”ҹ"ж ҲжәўеҮә"й”ҷиҜҜпјҲstack overflowпјүгҖӮеӣ дёәйңҖиҰҒеҗҢж—¶дҝқеӯҳжҲҗеҚғдёҠзҷҫдёӘи°ғз”Ёи®°еҪ•пјҢжүҖд»ҘйҖ’еҪ’йқһеёёиҖ—иҙ№еҶ…еӯҳгҖӮ
йҖ’еҪ’жӢҘжңүиҫғеҘҪзҡ„д»Јз ҒеҸҜиҜ»жҖ§пјҢеҜ№дәҺж•°жҚ®йҮҸдёҚз®—еӨӘеӨ§зҡ„иҝҗз®—пјҢдҪҝз”ЁйҖ’еҪ’з®—жі•з»°з»°жңүдҪҷгҖӮ
зҺ°еңЁеӯҳеңЁдёҖдёӘеӨҡеҸүж ‘пјҢе…¶з»“зӮ№жғ…еҶөеҰӮдёӢеӣҫпјҢйңҖиҰҒз»ҷеҮәж–№жі•е°ҶеҸ¶еӯҗиҠӮзӮ№зҡ„жүҖжңүи·Ҝеҫ„иҝӣиЎҢиҫ“еҮәгҖӮ
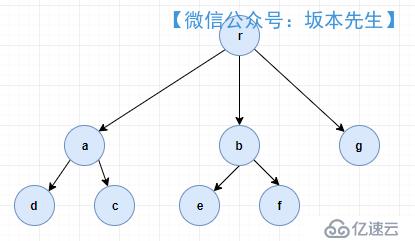
жңҖз»Ҳиҫ“еҮәз»“жһңеә”иҜҘжңү5дёӘпјҢеҚі[rad,rac,rbe,rbf,rg]
йҰ–е…ҲжҲ‘们еҜ№з»“зӮ№иҝӣиЎҢеҲҶжһҗпјҢжһ„е»әдёҖдёӘз»“зӮ№зұ»пјҲTreeNodeпјүпјҢ然еҗҺжҲ‘们йңҖиҰҒжңүдёҖдёӘж ‘зұ»пјҲMultiTreeпјүпјҢеҢ…еҗ«дәҶе…Ёи·Ҝеҫ„жү“еҚ°зҡ„ж–№жі•гҖӮжңҖеҗҺжҲ‘们йңҖиҰҒе»әз«ӢдёҖдёӘMainж–№жі•иҝӣиЎҢжөӢиҜ•гҖӮжңҖз»Ҳзҡ„йЎ№зӣ®з»“жһ„еҰӮдёӢпјҡ

жіЁж„Ҹпјҡжң¬ж–ҮдҪҝз”ЁдәҶlombokжіЁи§ЈпјҢзңҒеҺ»дәҶgetпјҢsetеҸҠзӣёе…іж–№жі•зҡ„е®һзҺ°гҖӮеҰӮжһңиҜ»иҖ…жІЎжңүдҪҝз”ЁиҝҮlombokд№ҹеҸҜд»ҘиҮӘе·ұзј–еҶҷеҜ№еә”зҡ„getпјҢsetж–№жі•пјҢеҗҺж–ҮдјҡеҜ№жҜҸдёӘзұ»иҝӣиЎҢиҜҙжҳҺйңҖиҰҒиҝӣиЎҢе®һзҺ°зҡ„ж–№жі•пјҢеҜ№ж ёеҝғд»Јз ҒжІЎжңүеҪұе“ҚгҖӮ
TreeNodeзұ»
иҠӮзӮ№зұ»пјҢдё»иҰҒеҢ…еҗ«дёӨдёӘеӯ—ж®өпјҡ
иҜҘзұ»дёӯеҢ…еҗ«дәҶеҝ…иҰҒзҡ„getпјҢsetж–№жі•пјҢдёҖдёӘж— еҸӮжһ„йҖ еҷЁпјҢдёҖдёӘе…ЁеҸӮжһ„йҖ еҷЁ
@Data
@RequiredArgsConstructor
@AllArgsConstructor
public class TreeNode {
private String content;
private HashMap<String,TreeNode> childs;
}MultiTreeзұ»
еҢ…еҗ«зҡ„еӯ—ж®өеҸӘжңүдёӨдёӘпјҡ
иҜҘзұ»дёӯзҡ„жһ„йҖ еҮҪж•°дёӯжҲ‘жүӢеҠЁеҲӣе»әй—®йўҳжһ„е»әдёӯзҡ„ж ‘пјҢзӣёе…ід»Јз ҒеҰӮдёӢпјҡ
public MultiTree(){
//еҲӣе»әж №иҠӮзӮ№
HashMap rootChilds = new HashMap();
this.root = new TreeNode("r",rootChilds);
//第дёҖеұӮеӯҗиҠӮзӮ№
HashMap aChilds = new HashMap();
TreeNode aNode = new TreeNode("a",aChilds);
HashMap bChilds = new HashMap();
TreeNode bNode = new TreeNode("b",bChilds);
HashMap gChilds = new HashMap();
TreeNode gNode = new TreeNode("g",gChilds);
//第дәҢеұӮз»“зӮ№
HashMap dChilds = new HashMap();
TreeNode dNode = new TreeNode("d",dChilds);
HashMap cChilds = new HashMap();
TreeNode cNode = new TreeNode("c",cChilds);
HashMap eChilds = new HashMap();
TreeNode eNode = new TreeNode("e",eChilds);
HashMap fChilds = new HashMap();
TreeNode fNode = new TreeNode("f",fChilds);
//е»әз«Ӣз»“зӮ№иҒ”зі»
rootChilds.put("a",aNode);
rootChilds.put("b",bNode);
rootChilds.put("g",gNode);
aChilds.put("d",dNode);
aChilds.put("c",cNode);
bChilds.put("e",eNode);
bChilds.put("f",fNode);
}еңЁиҝҷдёӘж ‘дёӯпјҢжҜҸдёӘиҠӮзӮ№йғҪжңүchildsпјҢеҰӮжһңжҳҜеҸ¶еӯҗиҠӮзӮ№пјҢеҲҷchildsдёӯзҡ„sizeдёә0пјҢиҝҷжҳҜдёӢйқўеҲӨж–ӯдёҖдёӘиҠӮзӮ№жҳҜеҗҰдёәеҸ¶еӯҗиҠӮзӮ№зҡ„йҮҚиҰҒдҫқжҚ®жҺҘдёӢжқҘжҲ‘们дјҡеҜ№ж ёеҝғз®—жі•д»Јз ҒиҝӣиЎҢе®һзҺ°гҖӮ
Mainзұ»
public class Main {
public static void main(String[] args) {
MultiTree tree = new MultiTree();
List<String> path2 = tree.listAllPathByRecursion();
System.out.println(path2);
List<String> path3 = tree.listAllPathByNotRecursion();
System.out.println(path3);
}
}йңҖиҰҒе®Ңе–„MultiTreeзұ»дёӯзҡ„listAllPathByRecursionж–№жі•е’ҢlistPathж–№жі•
йҖ’еҪ’иҝҮзЁӢж–№жі•пјҡlistAllPathByRecursion
з®—жі•жөҒзЁӢеӣҫеҰӮдёӢпјҡ
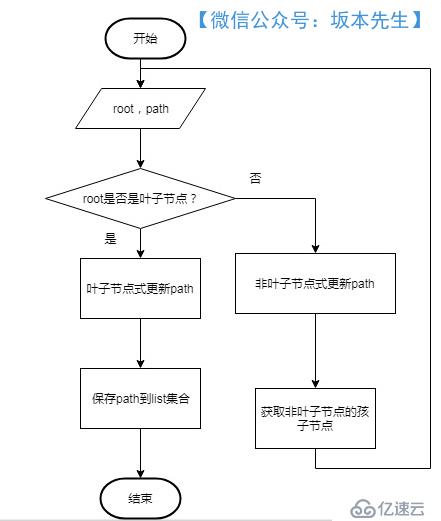
д»Јз Ғе®һзҺ°еҰӮдёӢпјҡ
public void listPath(TreeNode root,String path){
if(root.getChilds().isEmpty()){//еҸ¶еӯҗиҠӮзӮ№
path = path + root.getContent();
pathList.add(path); //е°Ҷз»“жһңдҝқеӯҳеңЁlistдёӯ
return;
}else{ //йқһеҸ¶еӯҗиҠӮзӮ№
path = path + root.getContent() + "->";
//иҝӣиЎҢеӯҗиҠӮзӮ№зҡ„йҖ’еҪ’
HashMap<String, TreeNode> childs = root.getChilds();
Iterator iterator = childs.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry entry = (Map.Entry)iterator.next();
TreeNode childNode = (TreeNode) entry.getValue();
listPath(childNode,path);
}
}
}йҖ’еҪ’и°ғз”Ёж–№жі•пјҡlistAllPathByRecursion
public List<String> listAllPathByRecursion(){
//жё…з©әи·Ҝеҫ„е®№еҷЁ
this.pathList.clear();
listPath(this.root,"");
return this.pathList;
}йқһйҖ’еҪ’ж–№жі•зҡ„д»Јз ҒйҮҸе’ҢйҖ’еҪ’ж–№жі•дёҖжҜ”пјҢз®ҖзӣҙжҳҜеӨӘеӨҡдәҶпјҢиҖҢдё”еҶ…е®№дёҚеҘҪзҗҶи§ЈпјҢдёҚзҹҘйҒ“еӨ§е®¶иғҪдёҚиғҪзңӢжҮӮжҲ‘еҶҷзҡ„д»Јз ҒпјҢжҲ‘е·Із»Ҹе°ҪеҠӣеҶҷдёҠзӣёе…іжіЁйҮҠдәҶгҖӮ
йҰ–е…Ҳе»әз«ӢдәҶдёӨдёӘж ҲпјҢзӨәж„ҸеӣҫеҰӮдёӢпјҢж Ҳзҡ„е®һзҺ°дҪҝз”ЁDequeпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜд»Јз Ғдёӯзҡ„з©әжҢҮй’Ҳжғ…еҶөгҖӮ
дё»ж Ҳпјҡз”ЁдәҺеӨ„зҗҶиҠӮзӮ№е’Ңдёҙж—¶и·Ҝеҫ„зҡ„еӯҳеӮЁпјҢдё»ж Ҳдёәз©әж—¶иҜҙжҳҺпјҢиҠӮзӮ№еӨ„зҗҶе®ҢжҜ•
еүҜж Ҳпјҡз”ЁдәҺеӯҳж”ҫеҫ…еӨ„зҗҶиҠӮзӮ№пјҢеүҜж Ҳдёәз©әж—¶иҜҙжҳҺпјҢиҠӮзӮ№йҒҚеҺҶе®ҢжҜ•
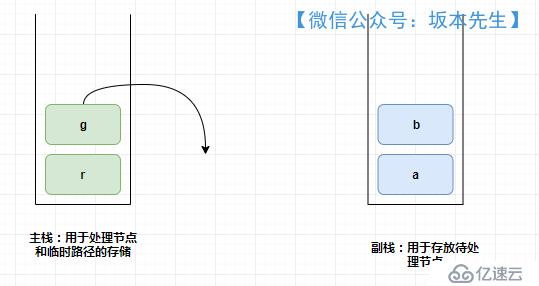
е…¶д»–зӣёе…іеҸҳйҮҸд»Ӣз»Қпјҡ
зЁӢеәҸжөҒзЁӢеӣҫпјҡ
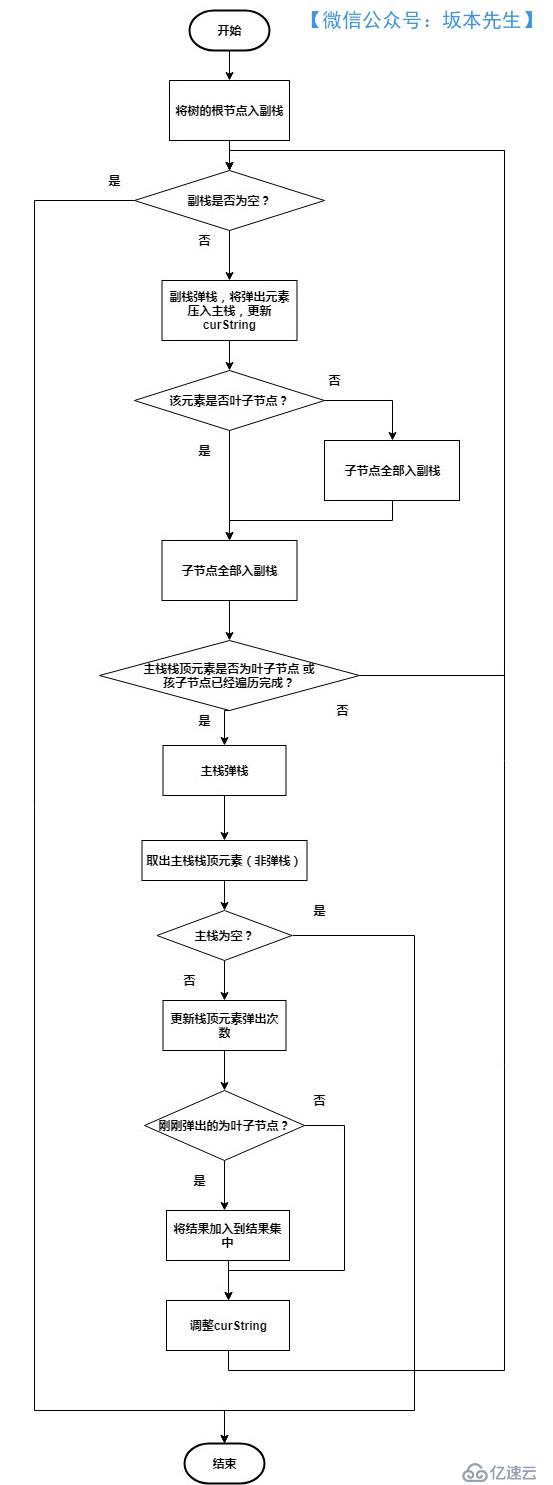
е…·дҪ“е®һзҺ°д»Јз ҒеҰӮдёӢпјҡ
/**
* йқһйҖ’еҪ’ж–№жі•иҫ“еҮәжүҖжңүи·Ҝеҫ„
*/
public List<String> listAllPathByNotRecursion(){
//жё…з©әи·Ҝеҫ„е®№еҷЁ
this.pathList.clear();
//дё»ж ҲпјҢз”ЁдәҺи®Ўз®—еӨ„зҗҶи·Ҝеҫ„
Deque<TreeNode> majorStack = new ArrayDeque();
//еүҜж ҲпјҢз”ЁдәҺеӯҳеӮЁеҫ…еӨ„зҗҶиҠӮзӮ№
Deque<TreeNode> minorStack = new ArrayDeque();
minorStack.addLast(this.root);
HashMap<String,Integer> popCount = new HashMap<>();
String curString = "";
while(!minorStack.isEmpty()){
//еҮәеүҜж ҲпјҢе…Ҙдё»ж Ҳ
TreeNode minLast = minorStack.pollLast();
majorStack.addLast(minLast);
curString+=minLast.getContent()+"->";
//е°ҶиҜҘиҠӮзӮ№зҡ„еӯҗиҠӮзӮ№е…ҘеүҜж Ҳ
if(!minLast.getChilds().isEmpty()){
HashMap<String, TreeNode> childs = minLast.getChilds();
Iterator iterator = childs.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry entry = (Map.Entry)iterator.next();
TreeNode childNode = (TreeNode) entry.getValue();
minorStack.addLast(childNode);
}
}
//еҮәдё»ж Ҳ
TreeNode majLast = majorStack.peekLast();
//еҫӘзҺҜжқЎд»¶пјҡж ҲйЎ¶дёәеҸ¶еӯҗиҠӮзӮ№ жҲ– ж ҲйЎ¶иҠӮзӮ№еӯ©еӯҗиҠӮзӮ№йҒҚеҺҶе®ҢдәҶпјҲйңҖиҰҒжіЁж„Ҹз©әжҢҮй’Ҳй—®йўҳпјү
while(majLast.getChilds().size() ==0 ||
(popCount.get(majLast.getContent())!=null && popCount.get(majLast.getContent()).equals(majLast.getChilds().size()))){
TreeNode last = majorStack.pollLast();
majLast = majorStack.peekLast();
if(majLast == null){ //жӯӨж—¶дё»ж Ҳдёәз©әпјҢиҝҗз®—е®ҢжҜ•
return this.pathList;
}
if(popCount.get(majLast.getContent())==null){//第дёҖж¬Ўеј№еҮәеӯ©еӯҗиҠӮзӮ№пјҢеј№еҮәж¬Ўж•°и®ҫдёә1
popCount.put(majLast.getContent(),1);
}else{ //йқһ第дёҖж¬Ўеј№еҮәеӯ©еӯҗиҠӮзӮ№пјҢеңЁеҺҹжңүеҹәзЎҖдёҠеҠ 1
popCount.put(majLast.getContent(),popCount.get(majLast.getContent())+1);
}
String lastContent = last.getContent();
if(last.getChilds().isEmpty()){//еҰӮжһңжҳҜеҸ¶еӯҗиҠӮзӮ№жүҚе°Ҷз»“жһңеҠ е…Ҙи·Ҝеҫ„йӣҶдёӯ
this.pathList.add(curString.substring(0,curString.length()-2));
}
//и°ғж•ҙеҪ“еүҚcurStringпјҢеҮҸеҺ»2жҳҜеҮҸзҡ„вҖң->вҖқиҝҷдёӘз¬ҰеҸ·
curString = curString.substring(0,curString.length()-lastContent.length()-2);
}
}
return this.pathList;
}и°ғз”ЁMainзұ»дёӯзҡ„mainж–№жі•пјҢеҫ—еҲ°жү§иЎҢз»“жһңпјҢе’Ңйў„жңҹз»“жһңзӣёеҗҢпјҢд»Јз ҒйҖҡиҝҮжөӢиҜ•
listAllPathByRecursion[r->a->c, r->a->d, r->b->e, r->b->f, r->g]
listAllPathByNotRecursion[r->g, r->b->f, r->b->e, r->a->d, r->a->c]е…¶е®һиҜҘж–Үз« жҳҜжҲ‘еңЁз ”究гҖҠеҹәдәҺTrieж ‘зҡ„ж•Ҹж„ҹиҜҚиҝҮж»Өз®—жі•е®һзҺ°гҖӢзҡ„дёҖдёӘдёӯй—ҙдә§зү©пјҢе…¶е®һеҺҹжқҘеә”иҜҘд№ҹе®һзҺ°иҝҮеӨҡеҸүж ‘зҡ„и·Ҝеҫ„йҒҚеҺҶй—®йўҳпјҢдҪҶжҳҜеӣ дёәж—¶й—ҙеҺҹеӣ еҠ д№ӢеҺҹжқҘжІЎжңүиҫғеҘҪзҡ„зҹҘиҜҶз®ЎзҗҶзі»з»ҹпјҢд»Јз Ғе’Ң笔记йғҪдёўдәҶпјҢд»ҠеӨ©и¶ҒжңәеҶҚиҝӣиЎҢдёҖжіўжҖ»з»“гҖӮеёҢжңӣиҜҘж–Үз« иғҪеӨҹеё®еҠ©еҲ°йңҖиҰҒзҡ„дәәгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ