您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
SVM算法(Support Vector Machine,支持向量机)的核心思想有2点:1、如果数据线性可分,那么基于最大间隔的方式来确定超平面,以确保全局最优,使得分类器尽可能健壮;2、如果数据线性不可分,通过核函数将低维样本转化为高维样本使其线性可分。注意和AdaBoost类似,SVM只能解决二分类问题。
SVM的算法在数学上实在是太复杂了,没研究明白。建议还是直接使用现成的第三方组件吧,比如libsvm的C#版本,推荐这个:http://www.matthewajohnson.org/software/svm.html。
虽然没研究明白,不过这几天照着Python版本的代码试着用C#改写了一下,算是研究SVM过程中唯一的收获吧。此版本基于SMO(序列最小优化)算法求解,核函数使用的是比较常用的径向基函数(RBF)。别问我为什么没有注释,我只是从Python移植过来的,我也没看懂,等我看懂了再来补注释吧。
using System;
using System.Collections.Generic;
using System.Linq;
namespace MachineLearning
{
/// <summary>
/// 支持向量机(SMO算法,RBF核)
/// </summary>
public class SVM
{
private Random m_Rand;
private double[][] m_Kernel;
private double[] m_Alpha;
private double m_C = 1.0;
private double m_B = 0.0;
private double m_Toler = 0.0;
private double[][] m_Cache;
private double[][] m_Data;
private double m_Reach;
private int[] m_Label;
private int m_Count;
private int m_Dimension;
public SVM()
{
m_Rand = new Random();
}
/// <summary>
/// 训练
/// </summary>
/// <param name="trainingSet"></param>
/// <param name="C"></param>
/// <param name="toler"></param>
/// <param name="reach"></param>
/// <param name="iterateCount"></param>
public void Train(List<DataVector<double, int>> trainingSet, double C, double toler, double reach, int iterateCount = 10)
{
//初始化
m_Count = trainingSet.Count;
m_Dimension = trainingSet[0].Dimension;
m_Toler = toler;
m_C = C;
m_Reach = reach;
this.Init(trainingSet);
this.InitKernel();
int iter = 0;
int alphaChanged = 0;
bool entireSet = true;
while(iter < iterateCount && (alphaChanged > 0 || entireSet))
{
alphaChanged = 0;
if(entireSet)
{
for(int i = 0;i < m_Count;++i)
alphaChanged += InnerL(i);
iter++;
}
else
{
for(int i = 0;i < m_Count;++i)
{
if(m_Alpha[i] > 0 && m_Alpha[i] < m_C)
alphaChanged += InnerL(i);
}
iter += 1;
}
if(entireSet)
entireSet = false;
else if(alphaChanged == 0)
entireSet = true;
}
}
/// <summary>
/// 分类
/// </summary>
/// <param name="vector"></param>
/// <returns></returns>
public int Classify(DataVector<double, int> vector)
{
double predict = 0.0;
int svCnt = m_Alpha.Count(a => a > 0);
var supportVectors = new double[svCnt][];
var supportLabels = new int[svCnt];
var supportAlphas = new double[svCnt];
int index = 0;
for(int i = 0;i < m_Count;++i)
{
if(m_Alpha[i] > 0)
{
supportVectors[index] = m_Data[i];
supportLabels[index] = m_Label[i];
supportAlphas[index] = m_Alpha[i];
index++;
}
}
var kernelEval = KernelTrans(supportVectors, vector.Data);
for(int i = 0;i < svCnt;++i)
predict += kernelEval[i] * supportAlphas[i] * supportLabels[i];
predict += m_B;
return Math.Sign(predict);
}
/// <summary>
/// 将原始数据转化成方便使用的形式
/// </summary>
/// <param name="trainingSet"></param>
private void Init(List<DataVector<double, int>> trainingSet)
{
m_Data = new double[m_Count][];
m_Label = new int[m_Count];
m_Alpha = new double[m_Count];
m_Cache = new double[m_Count][];
for(int i = 0;i < m_Count;++i)
{
m_Label[i] = trainingSet[i].Label;
m_Alpha[i] = 0.0;
m_Cache[i] = new double[2];
m_Cache[i][0] = 0.0;
m_Cache[i][1] = 0.0;
m_Data[i] = new double[m_Dimension];
for(int j = 0;j < m_Dimension;++j)
m_Data[i][j] = trainingSet[i].Data[j];
}
}
/// <summary>
/// 初始化RBF核
/// </summary>
private void InitKernel()
{
m_Kernel = new double[m_Count][];
for(int i = 0;i < m_Count;++i)
{
m_Kernel[i] = new double[m_Count];
var kernels = KernelTrans(m_Data, m_Data[i]);
for(int k = 0;k < kernels.Length;++k)
m_Kernel[i][k] = kernels[k];
}
}
private double[] KernelTrans(double[][] X, double[] A)
{
var kernel = new double[X.Length];
for(int i = 0;i < X.Length;++i)
{
double delta = 0.0;
for(int k = 0;k < X[0].Length;++k)
delta += Math.Pow(X[i][k] - A[k], 2);
kernel[i] = Math.Exp(delta * -1.0 / Math.Pow(m_Reach, 2));
}
return kernel;
}
private double E(int k)
{
double x = 0.0;
for(int i = 0;i < m_Count;++i)
x += m_Alpha[i] * m_Label[i] * m_Kernel[i][k];
x += m_B;
return x - m_Label[k];
}
private void UpdateE(int k)
{
double Ek = E(k);
m_Cache[k][0] = 1.0;
m_Cache[k][1] = Ek;
}
private int InnerL(int i)
{
double Ei = E(i);
if((m_Label[i] * Ei < -m_Toler && m_Alpha[i] < m_C) || (m_Label[i] * Ei > m_Toler && m_Alpha[i] > 0))
{
double Ej = 0.0;
int j = SelectJ(i, Ei, out Ej);
double oldAi = m_Alpha[i];
double oldAj = m_Alpha[j];
double H, L;
if(m_Label[i] != m_Label[j])
{
L = Math.Max(0, m_Alpha[j] - m_Alpha[i]);
H = Math.Min(m_C, m_C + m_Alpha[j] - m_Alpha[i]);
}
else
{
L = Math.Max(0, m_Alpha[j] + m_Alpha[i] - m_C);
H = Math.Min(m_C, m_Alpha[j] + m_Alpha[i]);
}
if(L == H)
return 0;
double eta = 2.0 * m_Kernel[i][j] - m_Kernel[i][i] - m_Kernel[j][j];
if(eta >= 0)
return 0;
m_Alpha[j] -= m_Label[j] * (Ei - Ej) / eta;
m_Alpha[j] = ClipAlpha(m_Alpha[j], H, L);
UpdateE(j);
if(Math.Abs(m_Alpha[j] - oldAj) < 0.00001)
return 0;
m_Alpha[i] += m_Label[j] * m_Label[i] * (oldAj - m_Alpha[j]);
UpdateE(i);
double b1 = m_B - Ei - m_Label[i] * (m_Alpha[i] - oldAi) * m_Kernel[i][i] - m_Label[j] * (m_Alpha[j] - oldAj) * m_Kernel[i][j];
double b2 = m_B - Ej - m_Label[i] * (m_Alpha[i] - oldAi) * m_Kernel[i][j] - m_Label[j] * (m_Alpha[j] - oldAj) * m_Kernel[j][j];
if(m_Alpha[i] > 0 && m_Alpha[i] < m_C)
m_B = b1;
else if(m_Alpha[j] > 0 && m_Alpha[j] < m_C)
m_B = b2;
else
m_B = (b1 + b2) / 2.0;
return 1;
}
return 0;
}
private int SelectJ(int i, double Ei, out double Ej)
{
Ej = 0.0;
int j = 0;
int maxK = -1;
double maxDeltaE = 0.0;
m_Cache[i][0] = 1;
m_Cache[i][1] = Ei;
for(int k = 0;k < m_Count;++k)
{
if(k == i || m_Cache[k][0] == 0)
continue;
double Ek = E(k);
double deltaE = Math.Abs(Ei - Ek);
if(deltaE > maxDeltaE)
{
maxK = k;
maxDeltaE = deltaE;
Ej = Ek;
}
}
if(maxK >= 0)
{
j = maxK;
}
else
{
j = RandomSelect(i);
}
return j;
}
private int RandomSelect(int i)
{
int j = 0;
do
{
j = m_Rand.Next(0, m_Count);
}
while(j == i);
return j;
}
private double ClipAlpha(double alpha, double H, double L)
{
return alpha > H ? H : (alpha < L ? L : alpha);
}
}
}最后上测试,还是使用上次的breast-cancer-wisconsin.txt做测试,之前用kNN和AdaBoost测试的错误率分别是2.02%和1.01%,这回用SVM对比一下。上测试代码:
public void TestSvm()
{
var trainingSet = new List<DataVector<double, int>>();
var testSet = new List<DataVector<double, int>>();
//读取数据
var file = new StreamReader("breast-cancer-wisconsin.txt", Encoding.Default);
for(int i = 0;i < 699;++i)
{
string line = file.ReadLine();
var parts = line.Split(',');
var p = new DataVector<double, int>(9);
for(int j = 0;j < p.Dimension;++j)
{
if(parts[j + 1] == "?")
parts[j + 1] = "0";
p.Data[j] = Convert.ToDouble(parts[j + 1]);
}
p.Label = Convert.ToInt32(parts[10]) == 2 ? 1 : -1;
//和上次一样,600个做训练,99个做测试
if(i < 600)
trainingSet.Add(p);
else
testSet.Add(p);
}
file.Close();
//检验
var svm = new SVM();
svm.Train(trainingSet, 1, 0.01, 3.0, 10);
int error = 0;
foreach(var p in testSet)
{
var label = boost.Classify(p);
if(label != p.Label)
error++;
}
Console.WriteLine("Error = {0}/{1}, {2}%", error, testSet.Count, (error * 100.0 / testSet.Count));
}最终结果是99个测试样本猜错1个,错误率1.01%,和AdaBoost相当。
Train时使用不同的参数,错误率会变化,很可惜的是参数的选择往往没有固定的方法,需要在一定范围内尝试以得到最小错误率。
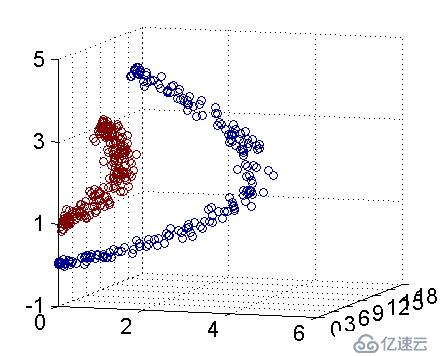
另外对于为什么核函数可以处理线性不可分数据,网上有2张图很能说明问题,转载一下:
以下数据明显是线性不可分的,在二维空间下找不到一条直线能将数据分开:

但在在二维空间下的线性不可分,到了三维空间,是可以找到一个平面来分隔数据的:
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。