您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编相信大家都知道in和exists的区别:
1、运用情况不同
sql中in适用于子查询得出的结果集记录较少,主查询中的表较大且又有索引的表,。sql中exist适用于外层的主查询记录较少,子查询中的表大,又有索引的时候。
2、驱动顺序不同
IN是先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。exists是以外层表为驱动表,先被访问。
3、底层原理不同
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
但是我昨天看到有位博主讲到还有一个区别就是对null值处理不同:IN不对NULL进行处理,exists会对NULL值进行处理。这个我没有听过,所以本着好奇心就去测试了一下,我发现没有什么不同,查询出来的数据也是一样。至于其他的小编就不在这里一一测试的,有兴趣的小伙伴自己私下测试一下。
先创建两张表stu存放学生的编号,姓名以及班级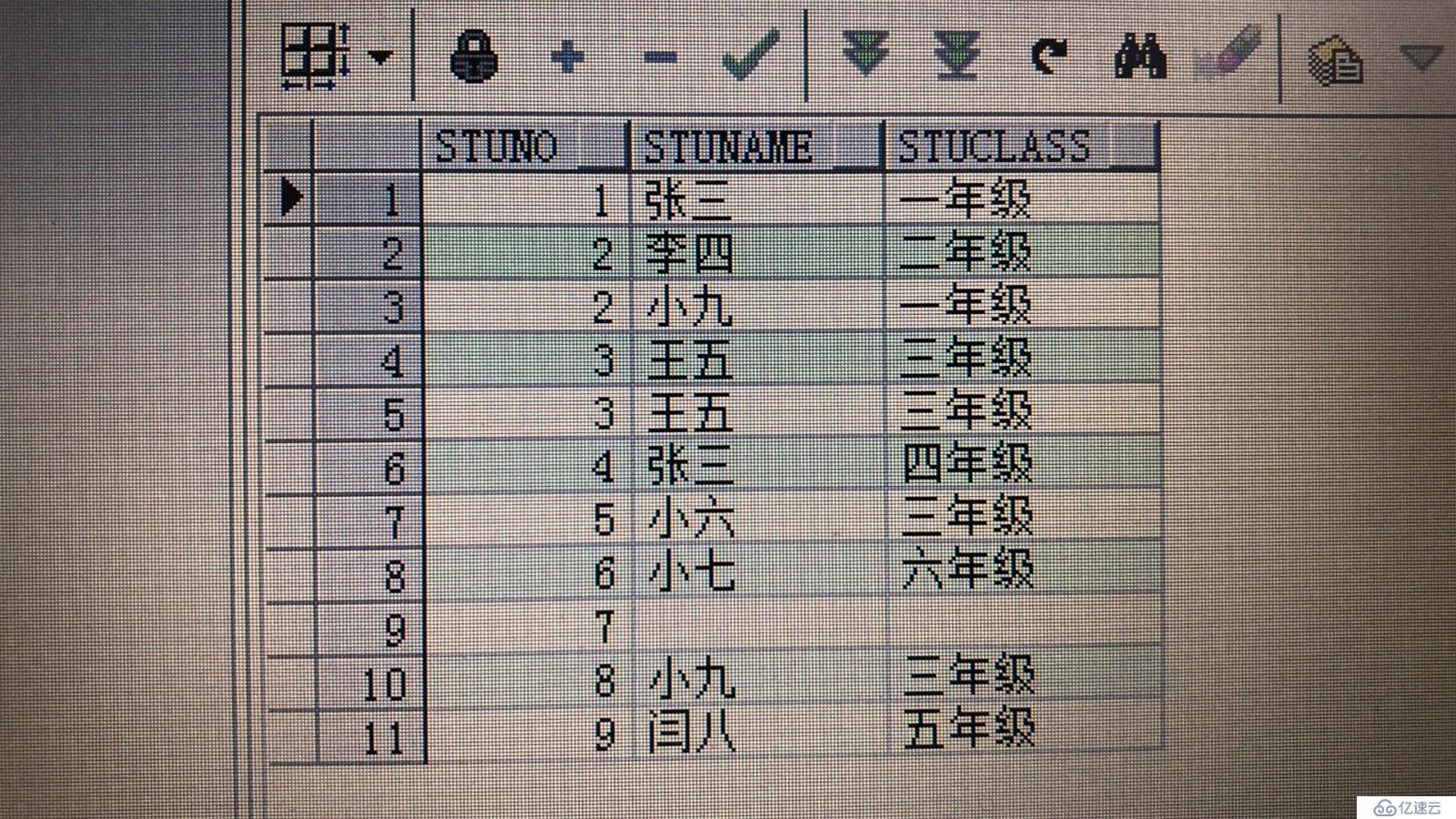
grade表存放学生的编号以及分数。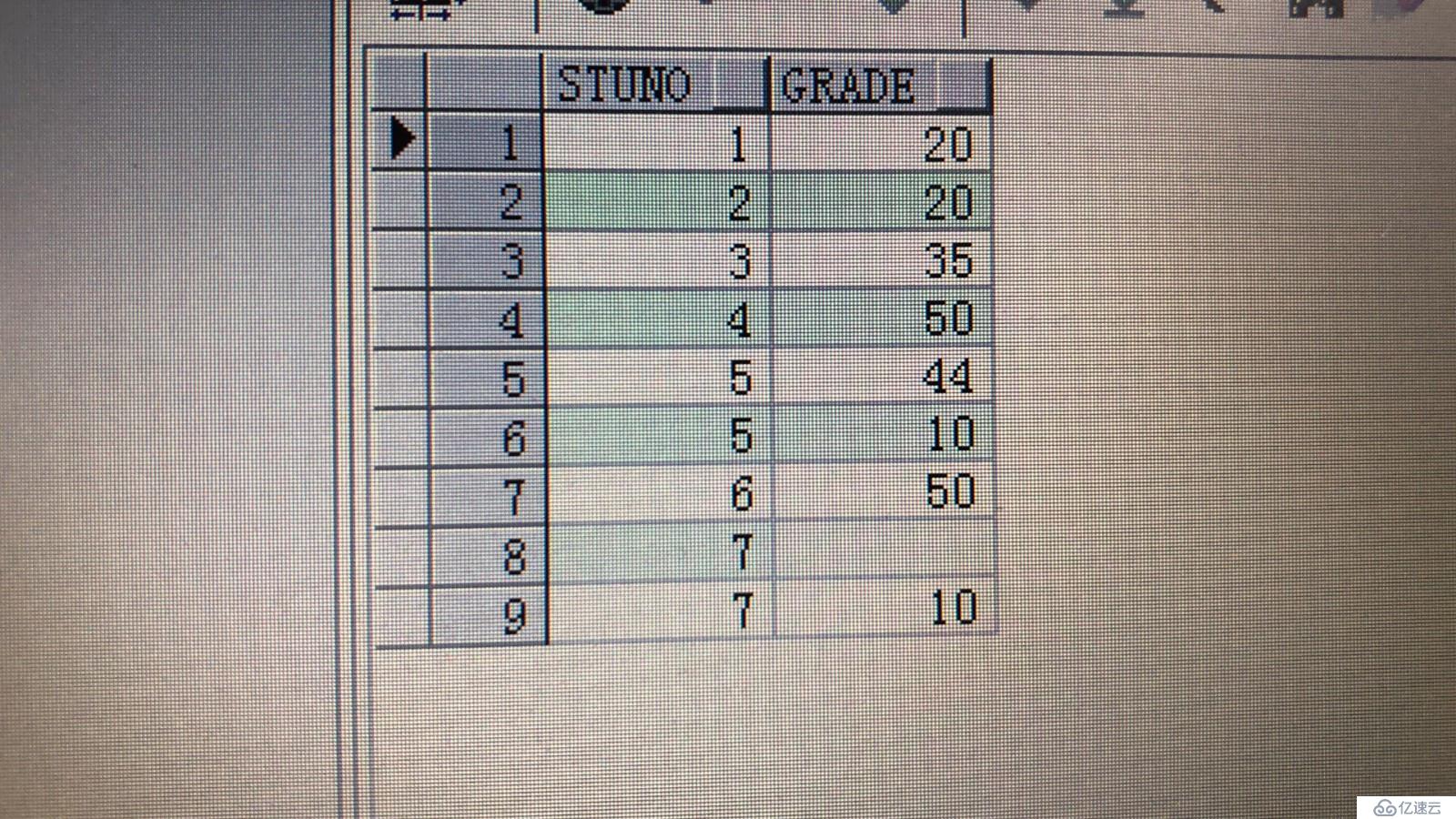
代码如下:
select from stu t1 where exists (select from grade t2 where t1.stuno = t2.stuno) order by t1.stuno;
select from stu t1 where t1.stuno in (select t2.stuno from grade t2 where t1.stuno = t2.stuno) order by t1.stuno;
查询结果是一样的,如下: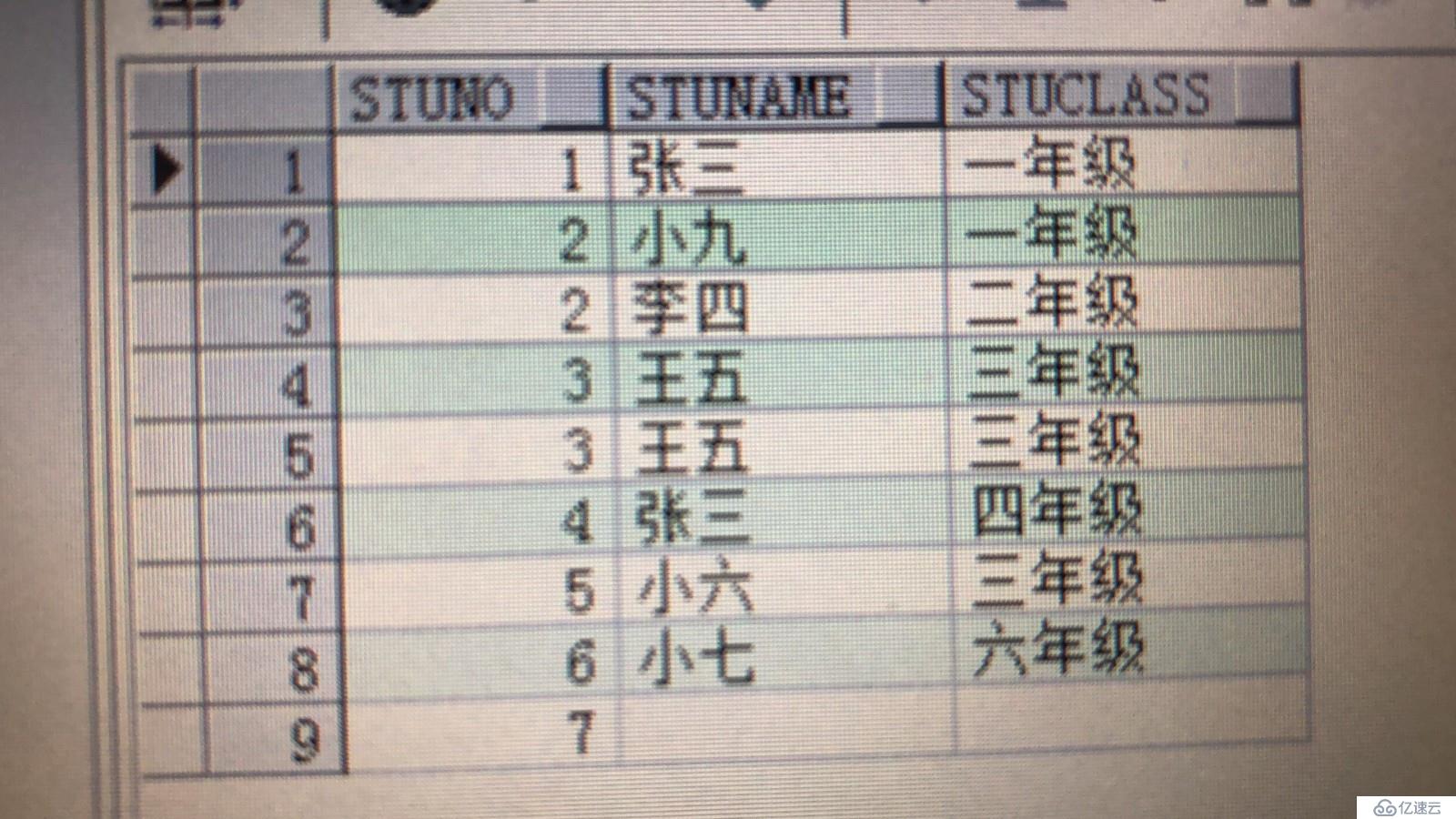
在这里注意两点:
1、sql中查询的字段均为stu表中的字段,不能写为:
select t2. from stu t1 where t1.stuno in (select t2.stuno from grade t2 where t1.stuno = t2.stuno) order by t1.stuno;否则会报错t2.标示符无效。
2、in是单字段查询,所以子查询中一定要注意!不能写为:
select from stu t1 where t1.stuno in (select * from grade t2 where t1.stuno = t2.stuno) order by t1.stuno;否则会报错值过多。
如果哪位小伙伴有不同的见解,欢迎给小编留言,小编好及时纠正,谢谢!
接下来讨论一下exists和distinct去重:
代码如下,id唯一:
select from stu t1 where exists (select from grade t2 where t1.stuno = t2.stuno) order by t1.stuno;
查询出的数据结果如下图:
我当时就一直在这里困扰,exists不是有去重的效果吗?为什么数据里id还是有重复数据出现,后来小编一直做实验测试发现,查询出的数据好像是先满足子查询中的where条件之后,然后对子查询中的数据去重,并不是对主表去重,最后返回符合数据的主表中的数据。后来就根据这个发现多做了一个测试,发现还真是这样。
还可以用一下sql代码替换:
select t1.* from stu t1,(select distinct a.stuno from grade a) t2 where t1.stuno = t2.stuno order by t1.stuno;
相信大家通过这两条代码发现通过distinct不能直接实现exists上面查询的效果!exists的效率会更高:
以下exists的解释计划窗口截图: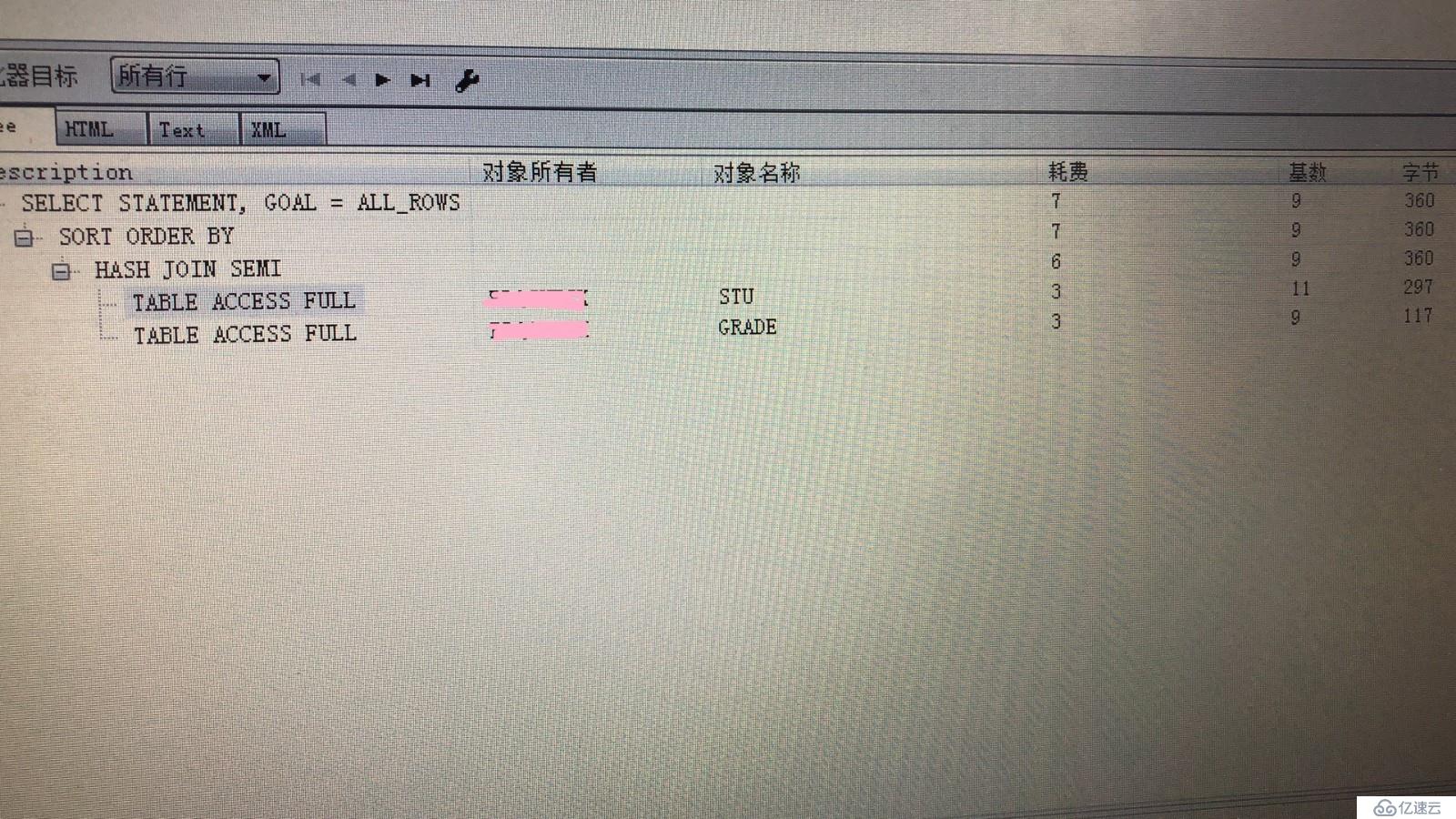
以下distinct的解释计划窗口截图: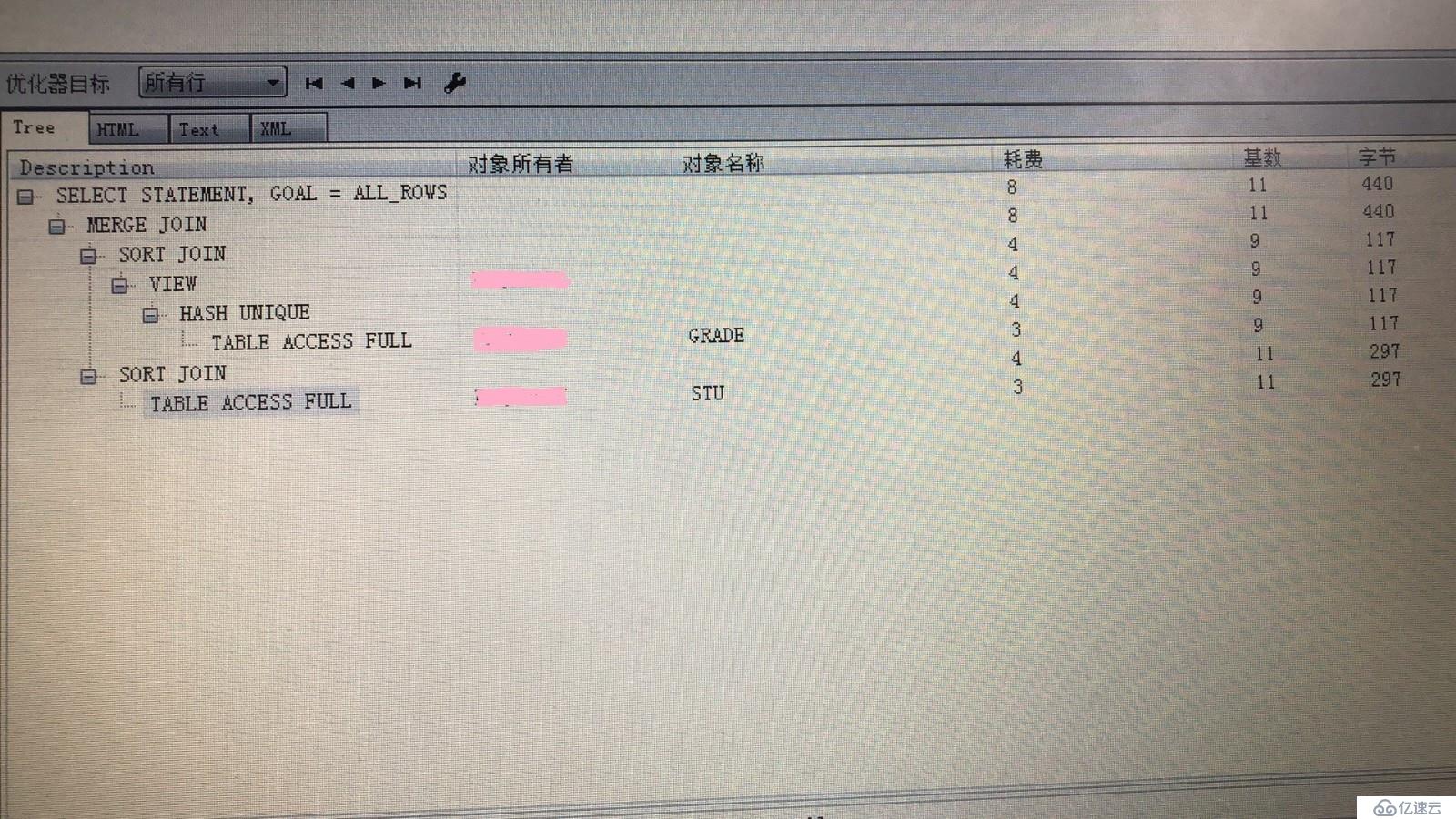
所以小编今天整理一下,也希望更多网友不要跟我一样再犯傻了,浪费时间不说,还一直有一个错误的理解!
大家还有什么更好的想法欢迎给小编留言!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。