您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
先放一段代码
for(int i=0;i<1000;i++){
for(int j=0;j<5;j++){
System.out.println("hello");
}
}
for(int i=0;i<5;i++){
for(int j=0;j<1000;j++){
System.out.println("hello");
}
}
分析以上代码可以看到两行代码除了循环的次序不一致意外,其他并无区别,在实际执行时两者所消耗的时间和空间应该也是一致的。但是这仅仅是在Java中,现在我们转化一下情景,最外层循环是数据库中的连接操作,内层循环为查找操作,那么现在两次的结果将相差巨大。
之所以出现这样的原因是数据库的特点决定的,数据库中相比较于查询操作而言,建立连接是更消耗资源的。第一段代码建立了1000次连接,每一次连接却只做了5次查询,显然是很浪费的。
因此在我们对数据库进行操作时需要遵循的操作应当是小表驱动大表(小的数据集驱动大的数据集)。
in与exists
表结构
tbl_emp为员工表,deptld为部门id。tbl_dept为部门表。员工表中含有客人,其deptld字段为-1
mysql> desc tbl_emp; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | deptld | int(11) | YES | MUL | NULL | | +--------+-------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec) mysql> desc tbl_dept; +----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | deptName | varchar(30) | YES | MUL | NULL | | | locAdd | varchar(40) | YES | | NULL | | +----------+-------------+------+-----+---------+----------------+ 3 rows in set (0.01 sec)
我们知道对于一个公司而言相对于部门来说员工数要多得多。现在我们有这样一个需求:查询属于这个公司的员工(不含来访客人),我们可以用以下代码解决
利用in
# 先查询部门表中所有的id,然后拿员工表中的deptld字段与之对比,若含有则保留。
mysql> select * from tbl_emp a where a.deptld in (select id from tbl_dept);
in关键字就像or的拼接,例如上述sql雨中子查询查出的结果为1,2,3。则sql语句等价于以下形式
mysql> select * from tbl_emp a where a.deptld=1 or a.deptld=2 or a.deptld=3
总的来说in关键字就是将子查询中的所有结果都查出来,假设结果集为B,共有m条记录,然后在将子查询条件的结果集分解成m个,再进行m次查询。可以看到这里主要是用到了A的索引,B表如何对查询影响不大
利用exists
mysql> select * from tbl_emp a where exists (select 1 from tbl_dept b where a.deptld = b.id );
exits:将主查询的数据放到子查询中做条件验证,根据验证结果(True或False)来判断是否保留主查询中的记录。
for (i = 0; i < count(A); i++) { //遍历A的总记录数
a = get_record(A, i); //从A表逐条获取记录
if (B.id = a[id]) //如果子条件成立
result[] = a;
}
return result;
可以看到:exists主要是用到了B表的索引,A表如何对查询的效率影响不大
结论
mysql> select * from tbl_emp a where a.deptld in (select id from tbl_dept);
若tbl_dept的记录数少余tbl_emp则使用in效率比较高
mysql> select * from tbl_emp a where exists (select 1 from tbl_dept b where a.deptld = b.id );
若tbl_dept的记录数多余tbl_emp则使用in效率比较高
下面给大家介绍IN与EXISTS的区别
1、IN查询分析
SELECT * FROM A WHERE id IN (SELECT id FROM B);
等价于:1、SELECT id FROM B ----->先执行in中的查询
2、SELECT * FROM A WHERE A.id = B.id
以上in()中的查询只执行一次,它查询出B中的所有的id并缓存起来,然后检查A表中查询出的id在缓存中是否存在,如果存在则将A的查询数据加入到结果集中,直到遍历完A表中所有的结果集为止。
以下用遍历结果集的方式来分析IN查询
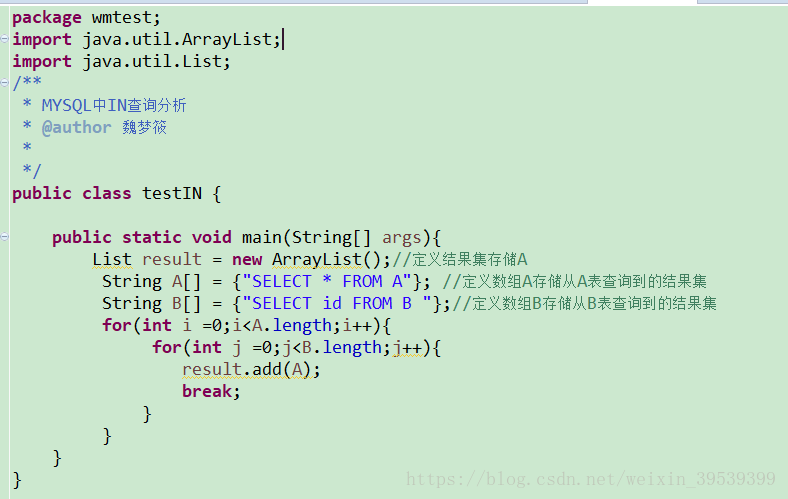
通过以上程序可以看出,当B表的数据较大时不适合使用in()查询,因为它会将B表中的数据全部遍历一次
例如:
1、A表中有100条记录,B表中有1000条记录,那么最多可能遍历100*1000次,效率很差
2、A表中有1000条记录,B表中有100条记录,那么最多可遍历1000*100此,内循环次数减少,效率大大提升
结论:IN()查询适合B表数据比A表数据小的情况,IN()查询是从缓存中取数据
2、EXISTS查询分析
语法:SELECT 字段 FROM table WHERE EXISTS(subquery);
SELECT * FROM a WHERE EXISTS(SELECT 1 FROM b WHERE B.id = A.id);
以上查询等价于:
SELECT * FROM A; SELECT I FROM B WHERE B.id = A.id;
EXISTS()查询会执行SELECT * FROM A查询,执行A.length次,并不会将EXISTS()查询结果结果进行缓存,因为EXISTS()查询返回一个布尔值true或flase,它只在乎EXISTS()的查询中是否有记录,与具体的结果集无关。
EXISTS()查询是将主查询的结果集放到子查询中做验证,根据验证结果是true或false来决定主查询数据结果是否得以保存。
总结
以上所述是小编给大家介绍的MySQL中in与exists的使用及区别介绍,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对亿速云网站的支持!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。