您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
接着上篇继续。数据获取之后并不能直接分析或使用,因为里面有很多无效的垃圾数据,所以必须要经过处理才可以。数据处理的主要内容包括数据清洗、数据抽取、数据交换和数据计算等。
数据清洗
数据清洗是数据价值链中最关键的一步。垃圾数据即使是通过最好的分析也可能会产生错误的结果,并造成较大的误导。
数据清洗就是处理缺失数据以及清除无意义的信息,如删除原始数据集中的无关数据、重复数据、平滑噪音数据,筛选掉与分析主题无关的数据等等。
重复值的处理
步骤如下:
1 利用DataFrame中的duplicated方法返回一个布尔型的Series,显示是否有重复行。没有显示FALSE,有则从重复的第二行起显示为TRUE
2 在利用DataFrame中的drop_duplicates方法返回一个移除了重复行的DataFrame
duplicated的格式:
duplicated(subset=None, keep='first')
括号中的参数均为可选,不写默认判断全部列
subset用于识别重复的列标签或列标签序号,默认是所有的列标签
keep为first表示除了第一次出现外,其余相同的数据被标记为重复;为last表示除了最后一次外,其余相同的数据被标记为重复;为false表示所有相同的数据都被标记为重复
drop_duplicates的格式:
drop_duplicates()
如果你想指定某个列就在括号里加入列名即可
from pandas import DataFrame
from pandas import Series
#造数据
df=DataFrame({'age':Series([26,85,85]),'name':Series(['xiaoqiang1','xiaoqiang2','xiaoqiang2'])})
df
#判断是否有重复行
df.duplicated()
#移除重复行
df.drop_duplicates()缺失值的处理
缺失值的处理一般包括两个步骤,分别是缺失数据的识别和缺失数据的处理。
缺失数据的识别
pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据,并使用isnull和notnull函数来判断缺失情况。
#缺失数据的识别 from pandas import DataFrame from pandas import read_excel #有缺失数据 df=read_excel(r'D:python_workspaceanacondarz.xlsx', sheetname='Sheet2') df #识别缺失数据,NaN的就会显示True。notnull函数正好相反 df.isnull()
rz.xlsx的内容如下
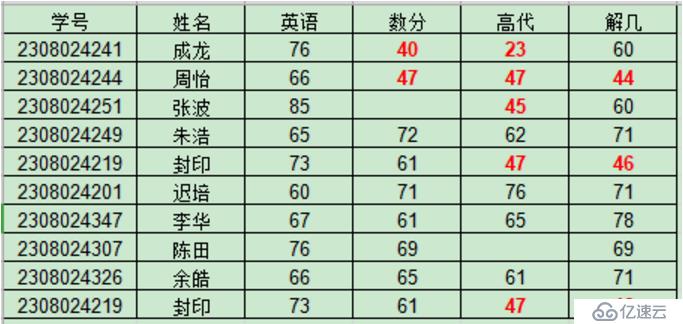
缺失数据的处理
对于缺失数据的处理有数据补齐、删除对应的行、不处理。这里直接撸代码解释
#接着上面的继续,进行数据的处理
#去除数据中值为空的数据行
newdf=df.dropna()
newdf
#用其他数值代替NaN
newdf2=df.fillna('--')
newdf2
#用前一个数据值代替NaN
newdf3=df.fillna(method='pad')
newdf3
#用后一个数据值代替NaN
newdf4=df.fillna(method='bfill')
newdf4
#传入一个字典对不同的列填充不同的值
newdf5=df.fillna({'数分':100,'高代':99})
newdf5
#用平均数来代替NaN。会自动计算有NaN两列的数据的平均数
newdf6=df.fillna(df.mean())
newdf6
#还可以使用strip()来去除数据左右的指定字符,这个是python的基础了,这里不做演示了免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。