жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іMySQLеӨ§ж•°жҚ®жҹҘиҜўжҖ§иғҪдјҳеҢ–зҡ„зӨәдҫӢпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
MySQLжҖ§иғҪдјҳеҢ–еҢ…жӢ¬иЎЁзҡ„дјҳеҢ–дёҺеҲ—зұ»еһӢйҖүжӢ©пјҢиЎЁзҡ„дјҳеҢ–еҸҜд»Ҙз»ҶеҲҶдёәд»Җд№Ҳпјҹ 1гҖҒе®ҡй•ҝдёҺеҸҳй•ҝеҲҶзҰ»пјӣ2гҖҒеёёз”Ёеӯ—ж®өдёҺдёҚеёёз”Ёеӯ—ж®өиҰҒеҲҶзҰ»пјӣ 3гҖҒеңЁ1еҜ№еӨҡпјҢйңҖиҰҒе…іиҒ”з»ҹи®Ўзҡ„еӯ—ж®өдёҠж·»еҠ еҶ—дҪҷеӯ—ж®өгҖӮ
дёҖгҖҒиЎЁзҡ„дјҳеҢ–дёҺеҲ—зұ»еһӢйҖүжӢ©
иЎЁзҡ„дјҳеҢ–пјҡ
1гҖҒе®ҡй•ҝдёҺеҸҳй•ҝеҲҶзҰ»
еҰӮ id int,еҚ 4дёӘеӯ—иҠӮпјҢchar(4)еҚ 4дёӘеӯ—з¬Ұй•ҝеәҰпјҢд№ҹжҳҜе®ҡй•ҝпјҢtimeеҚіжҜҸдёҖеҚ•е…ғеҖјеҚ зҡ„еӯ—иҠӮжҳҜеӣәе®ҡзҡ„гҖӮ
ж ёеҝғдё”еёёз”Ёеӯ—ж®өпјҢе®ңе»әжҲҗе®ҡй•ҝпјҢж”ҫеңЁдёҖеј иЎЁгҖӮ
иҖҢvarchar,text,blobиҝҷз§ҚеҸҳй•ҝеӯ—ж®өпјҢйҖӮеҗҲеҚ•ж”ҫдёҖеј иЎЁпјҢз”Ёдё»й”®дёҺж ёеҝғиЎЁе…іиҒ”иө·жқҘгҖӮ
2гҖҒеёёз”Ёеӯ—ж®өдёҺдёҚеёёз”Ёеӯ—ж®өиҰҒеҲҶзҰ»
йңҖиҰҒз»“еҗҲзҪ‘з«ҷе…·дҪ“зҡ„дёҡеҠЎжқҘеҲҶжһҗпјҢеҲҶжһҗеӯ—ж®өзҡ„жҹҘиҜўеңәжҷҜпјҢжҹҘиҜўйў‘зҺҮдҪҺзҡ„еӯ—ж®өпјҢеҚ•жӢҶеҮәжқҘгҖӮ
3гҖҒеңЁ1еҜ№еӨҡпјҢйңҖиҰҒе…іиҒ”з»ҹи®Ўзҡ„еӯ—ж®өдёҠж·»еҠ еҶ—дҪҷеӯ—ж®өгҖӮ
зңӢеҰӮдёӢзҡ„ж•Ҳжһңпјҡ
жҜҸдёӘзүҲеқ—йҮҢпјҢжңүNжқЎеё–еӯҗпјҢеңЁйҰ–йЎөжҳҫзӨәдәҶзүҲеқ—дҝЎжҒҜе’ҢзүҲеқ—дёӢзҡ„её–еӯҗж•°гҖӮ
иҝҷжҳҜеҰӮдҪ•еҒҡзҡ„

еҰӮжһңboardиЎЁеҸӘжңүеүҚ2еҲ—пјҢеҲҷйңҖиҰҒеҸ–еҮәзүҲеқ—еҗҺпјҢ
еҶҚжҹҘpostиЎЁпјҢselect count(*) from post group by board_idпјҢеҫ—еҮәжҜҸдёӘзүҲеқ—зҡ„её–еӯҗж•°гҖӮ
дәҢгҖҒеҲ—зұ»еһӢйҖүжӢ©
1гҖҒеӯ—ж®өзұ»еһӢдјҳе…Ҳзә§
ж•ҙеһӢ>date
time>enum
char>varchar>blob,text
ж•ҙеһӢпјҡе®ҡй•ҝпјҢжІЎжңүеӣҪ家/ең°еҢәд№ӢеҲҶпјҢжІЎжңүеӯ—з¬ҰйӣҶзҡ„е·®ејӮгҖӮжҜ”еҰӮпјҡ
tinyint 1,2,3,4,5 <--> char(1) a,b,c,d,e
д»Һз©әй—ҙдёҠпјҢйғҪеҚ 1дёӘеӯ—иҠӮпјҢдҪҶжҳҜ order by жҺ’еәҸпјҢеүҚиҖ…еҝ«гҖӮеҺҹеӣ пјҢжҲ–иҖ…йңҖиҰҒиҖғиҷ‘еӯ—з¬ҰйӣҶдёҺж ЎеҜ№йӣҶпјҲе°ұжҳҜжҺ’еәҸ规еҲҷпјүпјӣ
timeе®ҡй•ҝпјҢиҝҗз®—еҝ«пјҢиҠӮзңҒз©әй—ҙгҖӮиҖғиҷ‘ж—¶еҢәпјҢеҶҷsqlж—¶дёҚж–№дҫҝ where > `2018-08-08`;
enum,иғҪиө·еҲ°зәҰжқҹзҡ„зӣ®зҡ„пјҢеҶ…йғЁз”Ёж•ҙеһӢжқҘеӯҳеӮЁпјҢдҪҶдёҺcahrиҒ”жҹҘж—¶пјҢеҶ…йғЁиҰҒз»ҸеҺҶдёІдёҺеҖјзҡ„иҪ¬еҢ–пјӣ
charе®ҡй•ҝпјҢиҖғиҷ‘еӯ—з¬ҰйӣҶе’ҢпјҲжҺ’еәҸпјүж ЎеҜ№йӣҶпјӣ
varcharдёҚе®ҡй•ҝпјҢиҰҒиҖғиҷ‘еӯ—з¬ҰйӣҶзҡ„иҪ¬жҚўдёҺжҺ’еәҸж—¶зҡ„ж ЎеҜ№йӣҶпјҢйҖҹеәҰж…ўпјӣ
text/blob ж— жі•дҪҝз”ЁеҶ…еӯҳдёҙж—¶иЎЁпјҲжҺ’еәҸзӯүж“ҚдҪңеҸӘиғҪеңЁзЈҒзӣҳдёҠиҝӣиЎҢпјү
йҷ„пјҡе…ідәҺdate/timeзҡ„йҖүжӢ©пјҢеӨ§еёҲзҡ„жҳҺзЎ®ж„Ҹи§ҒпјҢзӣҙжҺҘйҖү int unsgined not null,еӯҳеӮЁж—¶й—ҙжҲігҖӮ
дҫӢеҰӮпјҡ
жҖ§еҲ«пјҡд»Ҙutf8дёәдҫӢ
char(1) ,3дёӘеӯ—й•ҝеӯ—иҠӮ
enum('з”·','еҘі')пјӣ еҶ…йғЁиҪ¬жҲҗж•°еӯ—жқҘеӯҳпјҢеӨҡдёҖдёӘиҪ¬жҚўиҝҮзЁӢ
tinyint()пјҢ е®ҡй•ҝ1дёӘеӯ—иҠӮ
2гҖҒеӨҹз”Ёе°ұиЎҢпјҢдёҚиҰҒж…·ж…ЁпјҲеҰӮ smallint varchar(N)пјү
еҺҹеӣ пјҡеӨ§зҡ„еӯ—иҠӮжөӘиҙ№еҶ…еӯҳпјҢеҪұе“ҚйҖҹеәҰгҖӮ
д»Ҙе№ҙйҫ„дёәдҫӢ tinyint unsigned not nullпјҢеҸҜд»ҘеӯҳеӮЁ255еІҒпјҢи¶іеӨҹгҖӮз”ЁintжөӘиҙ№дәҶ3дёӘеӯ—иҠӮпјӣ
д»Ҙvarchar(10),varchar(300)еӯҳеӮЁзҡ„еҶ…е®№зӣёеҗҢпјҢдҪҶеңЁиЎЁиҒ”жҹҘж—¶varchar(300)иҰҒиҠұжӣҙеӨҡеҶ…еӯҳгҖӮ
3гҖҒе°ҪйҮҸйҒҝе…Қз”ЁNULL()
еҺҹеӣ пјҡNULLдёҚеҲ©дәҺзҙўеј•пјҢиҰҒз”Ёзү№ж®Ҡзҡ„еӯ—з¬ҰжқҘж ҮжіЁгҖӮ
еңЁзЈҒзӣҳдёҠеҚ жҚ®зҡ„з©әй—ҙе…¶е®һжӣҙеӨ§пјҲMySQL5.5е·ІеҜ№nullеҒҡзҡ„ж”№иҝӣпјҢдҪҶжҹҘиҜўд»ҚжҳҜдёҚдҫҝпјү
дёүгҖҒзҙўеј•дјҳеҢ–зӯ–з•Ҙ
1гҖҒзҙўеј•зұ»еһӢ
1.1 B-treeзҙўеј•
еҗҚеҸ«btreeзҙўеј•пјҢеӨ§зҡ„ж–№йқўзңӢпјҢйғҪз”Ёзҡ„е№іиЎЎж ‘пјҢдҪҶе…·дҪ“зҡ„е®һзҺ°дёҠпјҢеҗ„еј•ж“ҺзЁҚжңүдёҚеҗҢпјҢжҜ”еҰӮпјҢдёҘж јзҡ„иҜҙпјҢNDBеј•ж“ҺпјҢдҪҝз”Ёзҡ„жҳҜT-tree.
дҪҶжҠҪиұЎдёҖдёӢ B-treeзі»з»ҹпјҢеҸҜзҗҶи§ЈдёәвҖңжҺ’еҘҪеәҸзҡ„еҝ«йҖҹжҹҘиҜўз»“жһ„вҖқгҖӮ
1.2 hashзҙўеј•
еңЁmemoryиЎЁйҮҢй»ҳи®ӨжҳҜhashзҙўеј•пјҢhashзҡ„зҗҶи®әжҹҘиҜўж—¶й—ҙеӨҚжқӮеәҰдёәO(1)гҖӮ
з–‘й—®пјҡ既然hashзҡ„жҹҘжүҫеҰӮжӯӨй«ҳж•ҲпјҢдёәд»Җд№ҲдёҚйғҪз”Ёhashзҙўеј•пјҹ
еӣһзӯ”пјҡ
1гҖҒhashеҮҪж•°и®Ўз®—еҗҺзҡ„з»“жһңпјҢжҳҜйҡҸжңәзҡ„пјҢеҰӮжһңжҳҜеңЁзЈҒзӣҳдёҠж”ҫзҪ®ж•°жҚ®пјҢд»Ҙдё»й”®дёәidдёәдҫӢпјҢйӮЈд№ҲйҡҸзқҖidзҡ„еўһй•ҝпјҢidеҜ№еә”зҡ„иЎҢпјҢеңЁзЈҒзӣҳдёҠйҡҸжңәж”ҫзҪ®гҖӮ
2гҖҒж— жі•еҜ№иҢғеӣҙжҹҘиҜўиҝӣиЎҢдјҳеҢ–гҖӮ
3гҖҒж— жі•еҲ©з”ЁеүҚзјҖзҙўеј•пјҢжҜ”еҰӮеңЁbtreeдёӯпјҢfieldеҲ—зҡ„еҖјвҖңhelloworldвҖқ,并еҠ зҙўеј•жҹҘиҜў x=helloworldиҮӘ然еҸҜд»ҘеҲ©з”Ёзҙўеј•пјҢx=helloд№ҹеҸҜд»ҘеҲ©з”Ёзҙўеј•пјҲе·ҰеүҚзјҖзҙўеј•пјүгҖӮ
4гҖҒжҺ’еәҸд№ҹж— жі•дјҳеҢ–гҖӮ
5гҖҒеҝ…йЎ»еӣһиЎҢпјҢе°ұжҳҜиҜҙйҖҡиҝҮзҙўеј•жӢҝеҲ°ж•°жҚ®дҪҚзҪ®пјҢеҝ…йЎ»еӣһеҲ°иЎЁдёӯеҸ–ж•°жҚ®гҖӮ
2гҖҒbtreeзҙўеј•зҡ„еёёи§ҒиҜҜеҢә
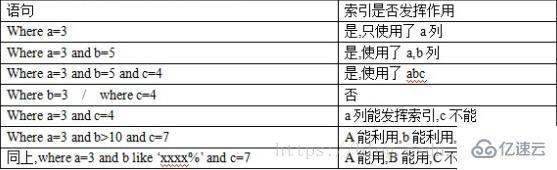
2.1 еңЁwhereжқЎд»¶еёёз”Ёзҡ„еҲ—дёҠеҠ зҙўеј•пјҢдҫӢеҰӮпјҡ
where cat_id = 3 and price>100;жҹҘиҜўз¬¬дёүдёӘж Ҹзӣ®пјҢ100е…ғд»ҘдёҠзҡ„е•Ҷе“ҒгҖӮ
иҜҜеҢәпјҡcat_id дёҠе’ҢpriceдёҠйғҪеҠ дёҠзҙўеј•гҖӮ
й”ҷпјҡеҸӘиғҪз”ЁдёҠcat_id жҲ– priceзҙўеј•пјҢеӣ дёәжҳҜзӢ¬з«Ӣзҡ„зҙўеј•пјҢеҗҢж—¶еҸӘиғҪз”ЁдёҖдёӘгҖӮ
2.2 еңЁеӨҡеҲ—дёҠе»әз«Ӣзҙўеј•еҗҺпјҲиҒ”еҗҲзҙўеј•пјүпјҢжҹҘиҜўе“ӘдёӘеҲ—пјҢзҙўеј•йғҪдјҡе°ҶеҸ‘жҢҘдҪңз”Ё
иҜҜеҢәпјҡеӨҡеҲ—зҙўеј•дёҠпјҢзҙўеј•еҸ‘жҢҘдҪңз”ЁпјҢйңҖиҰҒж»Ўи¶іе·ҰеүҚзјҖиҰҒжұӮгҖӮ
д»Ҙ index(a,b,c) дёәдҫӢпјҢпјҲжіЁж„Ҹе’ҢйЎәеәҸжңүе…іпјү
еӣӣгҖҒзҙўеј•е®һйӘҢ
дҫӢеҰӮпјҡselect * from t4 where c1=3 and c2 = 4 and c4>5 and c3=2;
з”ЁеҲ°дәҶе“Әдәӣзҙўеј•пјҡ
explain select * from t4 where c1=3 and c2 = 4 and c4>5 and c3=2 \G
еҰӮдёӢпјҡ
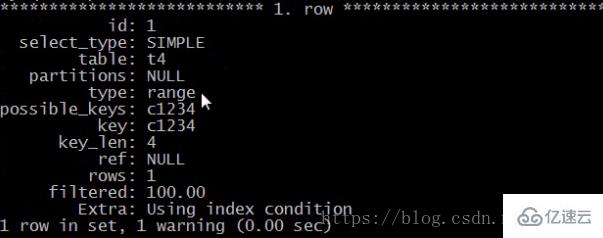
жіЁпјҡпјҲkey_len : 4 пјү
дә”гҖҒиҒҡз°Үзҙўеј•дёҺйқһиҒҡз°Үзҙўеј•
MyisamдёҺinnodbеј•ж“ҺпјҢзҙўеј•ж–Ү件зҡ„ејӮеҗҢ
Myisamпјҡз”ұnews.mydе’Ңnew.myiдёӨдёӘж–Ү件пјҢзҙўеј•ж–Ү件е’Ңж•°жҚ®ж–Ү件жҳҜеҲҶејҖзҡ„пјҢеҸ«йқһиҒҡз°Үзҙўеј•гҖӮдё»зҙўеј•е’Ңж¬Ўзҙўеј•йғҪжҢҮеҗ‘зү©зҗҶиЎҢпјҲзЈҒзӣҳзҡ„дҪҚзҪ®пјү
innodbпјҡзҙўеј•е’Ңж•°жҚ®жҳҜиҒҡеңЁдёҖиө·зҡ„пјҢжүҖд»ҘжҳҜиҒҡз°Үзҙўеј•гҖӮinnodbзҡ„дё»зҙўеј•ж–Ү件дёҠзӣҙжҺҘеӯҳж”ҫиҜҘиЎҢж•°жҚ®пјҢж¬Ўзҙўеј•жҢҮеҗ‘еҜ№дё»й”®зҙўеј•зҡ„еј•з”ЁгҖӮ
жіЁж„ҸпјҡinnodbжқҘиҜҙпјҡ
1гҖҒдё»й”®зҙўеј• еҚіеӯҳж”ҫзҙўеј•еҖјпјҢеҸҲеңЁеҸ¶еӯҗдёӯеӯҳеӮЁиЎҢзҡ„ж•°жҚ®гҖӮ
2гҖҒеҰӮжһңжІЎжңүдё»й”®пјҲprimary keyпјүпјҢеҲҷдјҡunique keyеҒҡдё»й”®гҖӮ
3гҖҒеҰӮжһңжІЎжңүuniqueпјҢеҲҷзі»з»ҹз”ҹжҲҗдёҖдёӘеҶ…йғЁзҡ„rowidеҒҡдё»й”®гҖӮ
4гҖҒеғҸinnodbдёӯпјҢдё»й”®зҡ„зҙўеј•з»“жһ„дёӯпјҢеҚіеӯҳеӮЁдәҶдё»й”®еҖјеҸҲеӯҳеӮЁдәҶиЎҢж•°жҚ®пјҢиҝҷз§Қз»“жһ„з§°дёәиҒҡз°Үзҙўеј•гҖӮ
иҒҡз°Үзҙўеј•
дјҳеҠҝпјҡж №жҚ®дё»й”®жҹҘиҜўжқЎзӣ®жҜ”иҫғе°‘ж—¶пјҢдёҚз”ЁеӣһиЎҢпјҲж•°жҚ®е°ұеңЁдё»й”®иҠӮзӮ№дёӢпјү
еҠЈеҠҝпјҡеҰӮжһңзў°еҲ°дёҚ规еҲҷж•°жҚ®жҸ’е…Ҙж—¶пјҢйҖ жҲҗйў‘з№Ғзҡ„йЎөеҲҶиЈӮ
е…ідәҺвҖңMySQLеӨ§ж•°жҚ®жҹҘиҜўжҖ§иғҪдјҳеҢ–зҡ„зӨәдҫӢвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ