您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
优化数据访问
1.是否向数据库请求了不需要的数据
解决方式:
A. 查询后加limit
B. Select后写需要的列而不是*
2. 是否扫描了额外的数据
数据库的访问方式速度由慢到快:全表扫描,索引扫描,范围扫描,唯一索引查询,常数引用
MYSQL Explain命令 的type(数据库引擎访问表的方式):Const > ref > range > index > all
1. const 常数引用
如果是根据主键查询,将会将查询转化为一个常数,只取出确定的一行数据。是最快的一种。
2. Ref
查找条件列使用了索引而且不为主键和unique(值允许重复),只取出确定值的数据,可能多行。
3. ref_eq 唯一索引查询
ref_eq 与 ref相比,这种类型的查找结果集只有一个
4. range 范围扫描
索引或主键,在某个范围内时
4. index 索引扫描
仅仅只有索引被扫描
5. all 全表扫描
一般mysql应用where条件的方式由好到坏:
1. 在索引中使用where条件过滤,这是在存储引擎层完成;
2. 使用索引覆盖扫描,直接从索引中过滤不需要的数据并返回结果,这是在mysql服务器层完成,无需再回表查询(在extra中出现using index)
3. 从数据表中返回数据,然后过滤不满足条件的数据,在服务器层完成,mysql需要先从数据表读出记录然后过滤(在extra中出现using where)
好的索引可以让查询使用合适的访问类型,减少扫描的数据行数。
执行查询的基础:
1. 客户端发送一条查询给服务器
2. 服务器先检查缓存,如果命中缓存,立刻返回结果
3. 服务器进行sql解析,预处理,再由优化器生成对应执行计划
4. Mysql根据优化器生成的执行计划,调用存储引擎API执行查询计划
5. 将结果返回给客户端
第一步(客户端发送一条查询给服务器):
Mysql客户端与服务器之间的通信是半双工的,要么由服务器向客户端发送数据,要么由客户端向服务器发送数据,不能同时进行;
所以为了进行流量控制,客户端发送查询语句过长时,超过max_allowed_packet参数,服务器会抛出相应错误。
客户端从服务器获取数据时,多数连接mysql的库函数都可以获得全部结果集并缓存到内存里,mysql需要等所有数据都发给客户端才能释放这条查询所占用的资源;
第三步(服务器进行sql解析、预处理、查询优化):
首先,通过关键字将sql语句进行解析,生成一颗“解析树”;
解析器验证语法规则;
预处理器检查解析树是否合法,验证权限;
查询优化器使用优化策略生成一个最优的执行计划:
1. 重新定义关联表的顺序
2. 将外连接转化为内连接
3. 优化count(),min(),max()(根据b-tree只读取第一条或最后一条数据)
4. 预估并转化为常数表达式
5. 提前终止查询
6. 列表in()的比较(将in列表的数据先排序,通过二分查找确定值是否满足条件)
生成一个执行计划——指令树:因为mysql的关联从一张表开始嵌套,所以执行计划是一颗左侧深度优先的树。
第四步(调用存储引擎API执行查询计划)
查询优化器在服务器层,而统计信息(每个表或索引有多少页,每个表的每个索引的基数是多少,数据行和索引长度,索引的分布信息等)在存储引擎层;
MYSQL执行关联查询方式:
Mysql认为任何一次查询都是一次关联,并不仅仅一次查询关系到两张表时。
在MySQL 中,只有一种 Join 算法,就是 Nested Loop Join嵌套迭代。
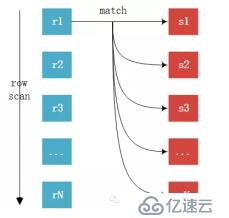
Simple Nested-Loop Join简单嵌套循环:从驱动表中取出R1匹配S表所有列,然后R2,R3,直到将R表中的所有数据匹配完,然后合并数据,可以看到这种算法要对S表进行RN次访问,虽然简单,但是相对来说开销还是太大了。
Index Nested-Loop Join索引嵌套循环:由于非驱动表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。
优化:
选择记录数少的作为驱动表;
优先优化NestedLoop的内层循环;
保证被驱动表上Join条件字段已经被索引
Mysql查询优化器的局限性
1.关联子查询
使用in加子查询,性能非常糟糕
//未完
2. 最大值和最小值
对于max()和min()查询,mysql的优化并不好,如:
Select min(actor_id) from sakila.actor where first_name = “pene”;
因为first_name字段上没有索引,所以mysql会进行一次全表扫描;
一个优化办法是:(使mysql进行主键扫描)
select actor_id from sakila.actor use index(primary) where first_name = “pene” limit 1;
用主建索引查询,因为b-tree是按照主键顺序排序,所以limit 1 = min(actor_id),查找索引直到复合where条件的第一条数据
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。