您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
周一到周五,每天一篇,北京时间早上7点准时更新~
The Model–View Transform(模型视口变换)
In a simple OpenGL application, one of the most common transformations is to take a model from model space to view space so as to render it(在OpenGL程序里,最常见的变换就是把一个模型转到视口坐标系下去,然后渲染它). In effect, we move the model first into world space (i.e., place it relative to the world’s origin) and then from there into view space (placing it relative to the viewer)(实际上我们先把模型变换到了世界坐标系下,然后再把它变换到了视口坐标系下). This process establishes the vantage point of the scene. By default, the point of observation in a perspective projection is at the origin (0,0,0) looking down the negative z axis (into the monitor or screen)(这种处理流程就决定了观察点的位置,在默认状况下,观察者的位置在投影矩阵里在0,0,0的地方,看向z轴的负方向). This point of observation is moved relative to the eye coordinate system to provide a specific vantage point(这个观察点会相对于视口坐标系运动). When the point of observation is located at the origin, as in a perspective projection, objects drawn with positive z values are behind the observer(当观察者位于投影坐标系的原点的时候,所有z轴正方向的东西都在观察者后面). In an orthographic projection, however, the viewer is assumed to be infinitely far away on the positive z axis and can see everything within the viewing volume(在正交投影里,观察者被设定为可以看到z轴的无穷远处,所以只要在观察者的视锥体之内,都可以被观察者看到). Because this transform takes vertices from model space (which is also sometimes known as object space) directly into view space and effectively bypasses world space(因为这个矩阵会直接把物体从模型坐标系扔到世界坐标系里,然后直接丢进视口里去), it is often referred to as the model–view transform and the matrix that encodes this transformation is known as the model–view matrix(模型矩阵和视口矩阵的合体一般叫做模型视口矩阵). The model transform essentially places objects into world space(模型矩阵基本上就是把模型变换到世界坐标系里去). Each object is likely to have its own model transform, which will generally consist of a sequence of scale, rotation, and translation operations(每个物体基本上都包含一个模型变换,它包含了旋转、缩放和平移). The result of multiplying the positions of vertices in model space by the model transform is a set of positions in world space. This transformation is sometimes called the model–world transform(模型矩阵乘以点能将点转换到世界坐标系里去,所以有时候模型矩阵又叫做模型世界变换). The view transformation allows you to place the point of observation anywhere you want and look in any direction(视口变换可以让你把观察者放在任意位置,面向任意方向). Determining the viewing transformation is like placing and pointing a camera at the scene(定义一个视口变换就像是定义一个场景中的摄像机). In the grand scheme of things, you must apply the viewing transformation before any other modeling transformations(宏观意义上,你必须在模型变换之前进行视口变换). The reason is that it appears to move the current working coordinate system with respect to the eye coordinate system(原因是它会相对于视口坐标系对物体进行操作). All subsequent transformations then occur based on the newly modified coordinate system(所有后续的变换都是基于当前的坐标系统进行的). The transform that moves coordinates from world space to view space is sometimes called the world–view transform(将世界坐标系的东西变换到视口坐标系的变换叫世界视口变换). Concatenating the model–world and world–view transform matrices by multiplying them together yields the model–view matrix(模型矩阵和视口矩阵结合的产物叫模型视口矩阵) (i.e., the matrix that takes coordinates from model to view space). There are some advantages to doing this(这么做是有好处的). First, there are likely to be many models in your scene and many vertices in each model(第一,你的场景中会有很多模型,模型中会有很多点). Using a singlecomposite transform to move the model into view space is more efficient than moving it first into world space and then into view space as explained earlier(使用合成矩阵比起分开会更高效). The second advantage has more to do with the numerical accuracy of single-precision floating-point numbers: The world could be huge and computation performed in world space will have different precision depending on how far the vertices are from the world origin(第二个好处就是与单精度浮点数的精度有关了:世界会很大,在世界坐标系下根据各个点离远点的距离的不同变换的各个点的精度是不一样的). However, if you perform the same calculations in view space, then precision is dependent on how far vertices are from the viewer, which is probably what you want— a great deal of precision is applied to objects that are close to the viewer at the expense of precision very far from the viewer(如果把他们直接转换到视口坐标系里,精度与观察者的距离有关,刚好符合我们的需要).
The Lookat Matrix(模型视口变换)
If you have a vantage point at a known location and a thing you want to look at, you will wish to place your your virtual camera at that location and then point it in the right direction(如果你希望在某个点看向某个方向,那么你将会希望吧虚拟摄像机放到那个点并指向那个你想看的方向). To orient the camera correctly, you also need to know which way is up; otherwise, the camera could spin around its forward axis and, even though it would still be technically be pointing in the right direction, this is almost certainly not what you want(为了知道正确的朝向,你需要知道指向头顶的向量是什么,欢聚话来说,摄像机可能绕着它的前方转,即便它有可能指向的是右边的方向). So, given an origin, a point of interest, and a direction that we consider to be up, we want to construct a sequence of transforms, ideally baked together into a single matrix, that will represent a rotation that will point a camera in the correct direction and a translation that will move the origin to the center of the camera(所以,给定一个原点、一个方向、一个视点后,我们需要构造一个矩阵刚好能表达摄像机的这样一个姿态). This matrix is known as a lookat matrix and can be constructed using only the math covered in this chapter so far.(这个矩阵叫lookat矩阵,你可以使用普通的数学知识就可以得到这个矩阵) First, we know that subtracting two positions gives us a vector which would move a point from the first position to the second and that normalizing that vector result gives us its directional(首先,我们通过向量减法,可以得到一个方向向量). So, if we take the coordinates of a point of interest, subtract from that the position of our camera, and then normalize the resulting vector, we have a new vector that represents the direction of view from the camera to the point of interest. We call this the forward vector(所以我们使用视点减去摄像机的位置,然后单位化,就得到了我们的指向前方的向量了). Next, we know that if we take the cross product of two vectors, we will receive a third vector that is orthogonal (at a right angle) to both input vectors(其次,我们知道叉乘俩向量可以得到一个与这俩向量都垂直的向量). Well, we have two vectors—the forward vector we just calculated, and the up vector, which represents the direction we consider to be upward. Taking the cross product of those two vectors results in a third vector that is orthogonal to each of them and points sideways with respect to our camera(我们让指向前方的向量和up向量叉乘得到一个向量,这个向量依然是相对于摄像机的,我们管这个叫sideways向量). We call this the sideways vector. However, the up and forward vectors are not necessarily orthogonal to each other and we need a third orthogonal vector to construct a rotation matrix(然而,up和forward向量并不是一定要互相垂直,所以我们还需要第三个垂直的向量去构成一个旋转矩阵). To obtain this vector, we can simply apply the same process again—taking the cross product of the forward vector and our sideways vector to produce a third that is orthogonal to both and that represents up with respect to the camera(这个第三个向量就使用向前的向量做叉积与我们刚才得到的sideway向量做叉积).These three vectors are of unit length and are all orthogonal to one another, so they form a set of orthonormal basis vectors and represent our view frame(这仨向量两两垂直且都是单位向量,所以他们构造成了一个正交基). Given these three vectors, we can construct a rotation matrix that will take a point in the standard Cartesian basis and move it into the basis of our camera(使用这些向量,我们可以构建一个旋转矩阵,可以把物体转换到视口坐标系中去). In the following math, e is the eye (or camera) position, p is the point of interest, and u is the up vector. Here we go.(接下来的数学中,e是摄像机的位置,p是视点、u是up向量,让我们开始推导吧) First, construct our forward vector, f:(首先计算向前的向量)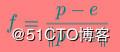
Next, take the cross product of f and u to construct a side vector s:(然后计算side向量)
Now, construct a new up vector u′ in our camera’s reference:(然后计算一个新的摄像机的向上的向量)
Finally, construct a rotation matrix representing a reorientation into our newly constructed orthonormal basis:(最后我们可以得到我们正交的旋转矩阵了)

Finally, we have our lookat matrix, T. If this seems like a lot of steps to you, you’re in luck. There’s a function in the vmath library that will construct the matrix for you:(最后我们得到了lookat矩阵,看起来你需要做很多事,但vmath已经帮你完成了)
template
static inline Tmat4 lookat(const vecN& eye,const vecN& center,
const vecN& up) { ... }
The matrix produced by the vmath::lookat function can be used as the basis for your camera matrix—the matrix that represents the position and orientation of your camera. In other words, this can be your view matrix(vmath::lookat产生的矩阵就是你的视口矩阵了).
本日的翻译就到这里,明天见,拜拜~~
第一时间获取最新桥段,请关注东汉书院以及图形之心公众号
东汉书院,等你来玩哦
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。