жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іNode StreamдёӯиҝҗиЎҢжңәеҲ¶зҡ„зӨәдҫӢеҲҶжһҗпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дҪ еҸҜд»ҘжҠҠжөҒзҗҶи§ЈжҲҗдёҖз§Қдј иҫ“зҡ„иғҪеҠӣгҖӮйҖҡиҝҮжөҒпјҢеҸҜд»Ҙд»Ҙе№ізј“зҡ„ж–№ејҸпјҢж— еүҜдҪңз”Ёзҡ„е°Ҷж•°жҚ®дј иҫ“еҲ°зӣ®зҡ„ең°гҖӮеңЁNodeдёӯпјҢNode StreamеҲӣе»әзҡ„жөҒйғҪжҳҜдё“з”ЁдәҺStringе’ҢBufferдёҠзҡ„пјҢдёҖиҲ¬жғ…еҶөдёӢдҪҝз”ЁBufferгҖӮStreamиЎЁзӨәзҡ„жҳҜдёҖз§Қдј иҫ“иғҪеҠӣпјҢBufferжҳҜдј иҫ“еҶ…е®№зҡ„иҪҪдҪ“ (еҸҜд»Ҙиҝҷж ·зҗҶи§ЈпјҢStreamпјҡеӨ–еҚ–е°Ҹе“Ҙе“ҘпјҢ BufferпјҡдҪ зҡ„еӨ–еҚ–)гҖӮеҲӣе»әжөҒзҡ„ж—¶еҖҷе°ҶObjectModeи®ҫзҪ®true пјҢStreamеҗҢж ·еҸҜд»Ҙдј иҫ“д»»ж„Ҹзұ»еһӢзҡ„JSеҜ№иұЎпјҲйҷӨдәҶnullпјҢnullеңЁжөҒдёӯжңүзү№ж®Ҡз”ЁйҖ”пјүгҖӮ
зҺ°еңЁжңүдёӘйңҖжұӮпјҢжҲ‘们иҰҒеҗ‘е®ўжҲ·з«Ҝдј иҫ“дёҖдёӘеӨ§ж–Ү件гҖӮеҰӮжһңйҮҮз”ЁдёӢйқўзҡ„ж–№ејҸ
const fs = require('fs');
const server = require('http').createServer();
server.on('request', (req, res) => {
fs.readFile('./big.file', (err, data) => {
if (err) throw err;
res.end(data);
});
});
server.listen(8000);жҜҸж¬ЎжҺҘ收дёҖдёӘиҜ·жұӮпјҢе°ұиҰҒжҠҠиҝҷдёӘеӨ§ж–Ү件иҜ»е…ҘеҶ…еӯҳпјҢ然еҗҺеҶҚдј иҫ“з»ҷе®ўжҲ·з«ҜгҖӮйҖҡиҝҮиҝҷз§Қж–№ејҸеҸҜиғҪдјҡдә§з”ҹд»ҘдёӢдёүз§ҚеҗҺжһңпјҡ
еҶ…еӯҳиҖ—е°Ҫ
жӢ–ж…ўе…¶д»–иҝӣзЁӢ
еўһеҠ еһғеңҫеӣһ收еҷЁзҡ„иҙҹиҪҪ
жүҖд»Ҙиҝҷз§Қж–№ејҸеңЁдј иҫ“еӨ§ж–Ү件зҡ„жғ…еҶөдёӢпјҢдёҚжҳҜдёҖдёӘеҘҪзҡ„ж–№жЎҲгҖӮ并еҸ‘йҮҸдёҖеӨ§пјҢеҮ зҷҫдёӘиҜ·жұӮиҝҮжқҘеҫҲе®№жҳ“е°ұе°ҶеҶ…еӯҳиҖ—е°ҪгҖӮ
еҰӮжһңйҮҮз”ЁжөҒе‘ўпјҹ
const fs = require('fs');
const server = require('http').createServer();
server.on('request', (req, res) => {
const src = fs.createReadStream('./big.file');
src.pipe(res);
});
server.listen(8000);йҮҮз”Ёиҝҷз§Қж–№ејҸпјҢдёҚдјҡеҚ з”ЁеӨӘеӨҡеҶ…еӯҳпјҢиҜ»еҸ–дёҖзӮ№е°ұдј иҫ“дёҖзӮ№пјҢж•ҙдёӘиҝҮзЁӢе№ізј“иҝӣиЎҢпјҢйқһеёёдјҳйӣ…гҖӮеҰӮжһңжғіеңЁдј иҫ“зҡ„иҝҮзЁӢдёӯпјҢжғіеҜ№ж–Ү件иҝӣиЎҢеӨ„зҗҶпјҢжҜ”еҰӮеҺӢзј©гҖҒеҠ еҜҶзӯүзӯүпјҢд№ҹеҫҲеҘҪжү©еұ•пјҲеҗҺйқўдјҡе…·дҪ“д»Ӣз»ҚпјүгҖӮ
жөҒеңЁNodeдёӯж— еӨ„дёҚеңЁгҖӮд»ҺдёӢеӣҫдёӯеҸҜд»ҘзңӢеҮәпјҡ

StreamеҲҶдёәеӣӣеӨ§зұ»пјҡ
ReadableпјҲеҸҜиҜ»жөҒпјү
Writable пјҲеҸҜеҶҷжөҒпјү
Duplex пјҲеҸҢе·ҘжөҒпјү
Transform пјҲиҪ¬жҚўжөҒпјү
еҸҜиҜ»жөҒдёӯзҡ„ж•°жҚ®пјҢеңЁд»ҘдёӢдёӨз§ҚжЁЎејҸдёӢйғҪиғҪдә§з”ҹж•°жҚ®гҖӮ
Flowing Mode
Non-Flowing Mode
дёӨз§ҚжЁЎејҸдёӢпјҢи§ҰеҸ‘зҡ„ж–№ејҸд»ҘеҸҠж¶ҲиҖ—зҡ„ж–№ејҸдёҚдёҖж ·гҖӮ
Flowing Modeпјҡж•°жҚ®дјҡжәҗжәҗдёҚж–ӯең°з”ҹдә§еҮәжқҘпјҢеҪўжҲҗвҖңжөҒеҠЁвҖқзҺ°иұЎгҖӮзӣ‘еҗ¬жөҒзҡ„dataдәӢ件дҫҝеҸҜиҝӣе…ҘиҜҘжЁЎејҸгҖӮ
Non-Flowing ModeдёӢпјҡйңҖиҰҒжҳҫзӨәең°и°ғз”Ёread()ж–№жі•пјҢжүҚиғҪиҺ·еҸ–ж•°жҚ®гҖӮ
дёӨз§ҚжЁЎејҸеҸҜд»Ҙдә’зӣёиҪ¬жҚў
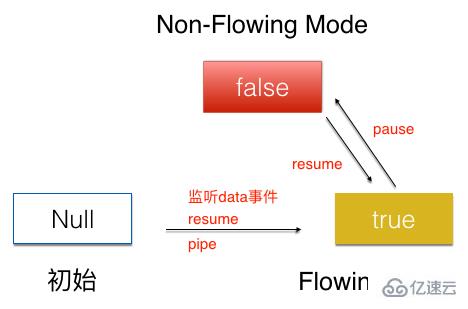
жөҒзҡ„еҲқе§ӢзҠ¶жҖҒжҳҜNullпјҢйҖҡиҝҮзӣ‘еҗ¬dataдәӢ件пјҢжҲ–иҖ…pipeж–№жі•пјҢи°ғз”Ёresumeж–№жі•пјҢе°ҶжөҒиҪ¬дёәFlowing ModeзҠ¶жҖҒгҖӮFlowing ModeзҠ¶жҖҒдёӢи°ғз”Ёpauseж–№жі•пјҢе°ҶжөҒзҪ®дёәNon-Flowing ModeзҠ¶жҖҒгҖӮNon-Flowing ModeзҠ¶жҖҒдёӢи°ғз”Ёresumeж–№жі•пјҢеҗҢж ·еҸҜд»Ҙе°ҶжөҒзҪ®дёәFlowing ModeзҠ¶жҖҒгҖӮ
дёӢйқўиҜҰз»Ҷд»Ӣз»ҚдёӢдёӨз§ҚжЁЎејҸдёӢпјҢReadableжөҒзҡ„иҝҗиЎҢжңәеҲ¶гҖӮ
еңЁFlowing ModeзҠ¶жҖҒдёӢпјҢеҲӣе»әзҡ„myReadableиҜ»жөҒпјҢзӣҙжҺҘзӣ‘еҗ¬dataдәӢ件пјҢж•°жҚ®е°ұжәҗжәҗдёҚж–ӯзҡ„жөҒеҮәжқҘиҝӣиЎҢж¶Ҳиҙ№дәҶгҖӮ
myReadable.on('data',function(chunk){
consume(chunk);//ж¶Ҳиҙ№жөҒ
})дёҖж—Ұзӣ‘еҗ¬dataдәӢ件д№ӢеҗҺпјҢReadableеҶ…йғЁзҡ„жөҒзЁӢеҰӮдёӢеӣҫжүҖзӨә
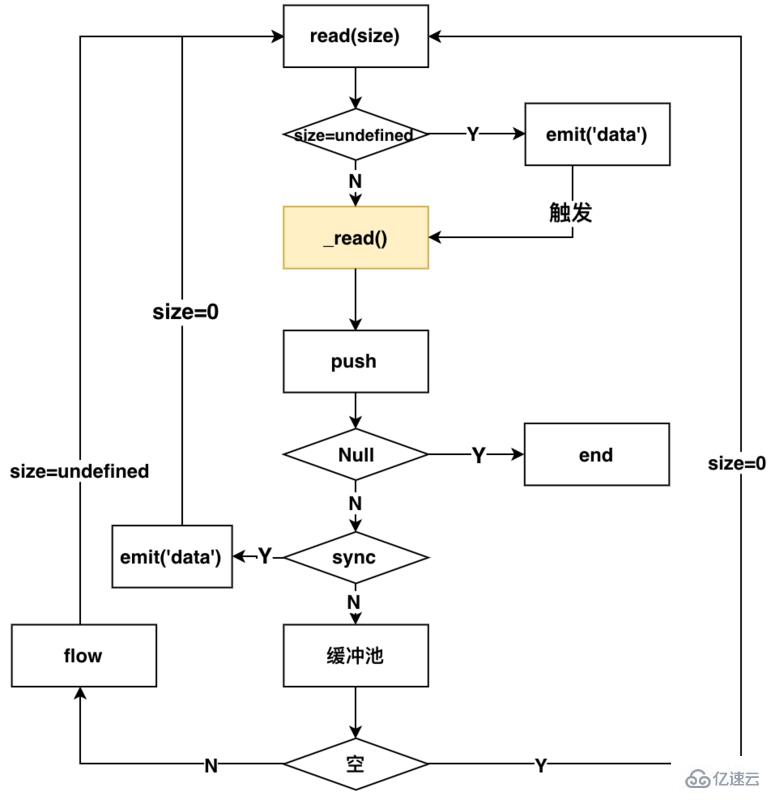
ж ёеҝғзҡ„ж–№жі•жҳҜжөҒеҶ…йғЁзҡ„readж–№жі•пјҢе®ғеңЁеҸӮж•°nдёәдёҚеҗҢеҖјж—¶пјҢеҲҶеҲ«и§ҰеҸ‘дёҚеҗҢзҡ„ж“ҚдҪңгҖӮдёӢйқўжҸҸиҝ°дёӯзҡ„hightwatermarkиЎЁзӨәзҡ„жҳҜжөҒеҶ…йғЁзҡ„зј“еҶІжұ зҡ„еӨ§е°ҸгҖӮ
n=undefinedпјҲж¶Ҳиҙ№ж•°жҚ®пјҢ并и§ҰеҸ‘дёҖж¬ЎеҸҜиҜ»жөҒпјү
n=0пјҲи§ҰеҸ‘дёҖж¬ЎеҸҜиҜ»жөҒпјҢдҪҶжҳҜдёҚдјҡж¶Ҳиҙ№пјү
n>hightwatermarkпјҲдҝ®ж”№hightwatermarkзҡ„еҖјпјү
n<bufferзҡ„жҖ»ж•°жҚ®ж•°пјҲзӣҙжҺҘиҝ”еӣһnдёӘеӯ—иҠӮзҡ„ж•°жҚ®пјү
n>buffer (еҸҜд»Ҙиҝ”еӣһnullпјҢд№ҹеҸҜд»Ҙиҝ”еӣһbufferжүҖжңүзҡ„ж•°жҚ®пјҲеҪ“ж—¶жңҖеҗҺдёҖж¬ЎиҜ»еҸ–пјү)
еӣҫдёӯй»„иүІж ҮиҜҶзҡ„_read()пјҢжҳҜз”ЁжҲ·е®һзҺ°жөҒжүҖйңҖиҰҒиҮӘе·ұе®һзҺ°зҡ„ж–№жі•пјҢиҝҷдёӘж–№жі•е°ұжҳҜе®һйҷ…иҜ»еҸ–жөҒзҡ„ж–№ејҸпјҲеҸҜд»Ҙиҝҷж ·зҗҶи§ЈпјҢеӨ–еҚ–е№іеҸ°з»ҷдҪ жҸҗдҫӣеӨ–еҚ–зҡ„иғҪеҠӣпјҢйӮЈ_read()ж–№жі•е°ұзӣёеҪ“дәҺдҪ дёӢеҚ•зӮ№еӨ–еҚ–пјүгҖӮеҗҺйқўдјҡиҜҰз»Ҷд»Ӣз»ҚеҰӮдҪ•е®һзҺ°_readж–№жі•гҖӮ
д»ҘдёҠзҡ„жөҒзЁӢеҸҜд»ҘжҸҸиҝ°дёәпјҡзӣ‘еҗ¬dataж–№жі•пјҢReadableеҶ…йғЁе°ұдјҡи°ғз”Ёreadж–№жі•пјҢжқҘиҝӣиЎҢи§ҰеҸ‘иҜ»жөҒж“ҚдҪңпјҢйҖҡиҝҮеҲӨж–ӯжҳҜеҗҢжӯҘиҝҳжҳҜејӮжӯҘиҜ»еҸ–пјҢжқҘеҶіе®ҡиҜ»еҸ–зҡ„ж•°жҚ®жҳҜеҗҰж”ҫе…Ҙзј“еҶІеҢәгҖӮеҰӮжһңдёәејӮжӯҘзҡ„пјҢйӮЈд№Ҳе°ұиҰҒи°ғз”Ёflowж–№жі•пјҢжқҘ继з»ӯи§ҰеҸ‘readж–№жі•пјҢжқҘиҜ»еҸ–жөҒпјҢеҗҢж—¶ж №жҚ®sizeеҸӮж•°еҲӨе®ҡжҳҜеҗҰemit('data')жқҘж¶Ҳиҙ№жөҒпјҢеҫӘзҺҜиҜ»еҸ–гҖӮеҰӮжһңжҳҜеҗҢжӯҘзҡ„пјҢйӮЈе°ұemit('data')жқҘж¶Ҳиҙ№жөҒпјҢеҗҢ时继з»ӯи§ҰеҸ‘readж–№жі•пјҢжқҘиҜ»еҸ–жөҒгҖӮдёҖж—Ұpushж–№жі•дј е…Ҙзҡ„жҳҜnullпјҢж•ҙдёӘжөҒе°ұз»“жқҹдәҶгҖӮ
д»ҺдҪҝз”ЁиҖ…зҡ„и§’еәҰжқҘзңӢпјҢеңЁиҝҷз§ҚжЁЎејҸдёӢпјҢдҪ еҸҜд»ҘйҖҡиҝҮдёӢйқўзҡ„ж–№ејҸжқҘдҪҝз”ЁжөҒ
const fs = require('./fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('data',function(chunk){
writeFile1.write(chunk);
})зӣёеҜ№дәҺFlowing modeпјҢNon-Flowing ModeиҰҒзӣёеҜ№з®ҖеҚ•еҫҲеӨҡгҖӮ
ж¶Ҳиҙ№иҜҘжЁЎејҸдёӢзҡ„жөҒпјҢйңҖиҰҒдҪҝз”ЁдёӢйқўзҡ„ж–№ејҸ
myReadable.on(вҖҳreadableвҖҷ,function(){
const chunk = myReadable.read()
consume(chunk);//ж¶Ҳиҙ№жөҒ
})еңЁNon-Flowing ModeдёӢпјҢReadableеҶ…йғЁзҡ„жөҒзЁӢеҰӮдёӢеӣҫпјҡ
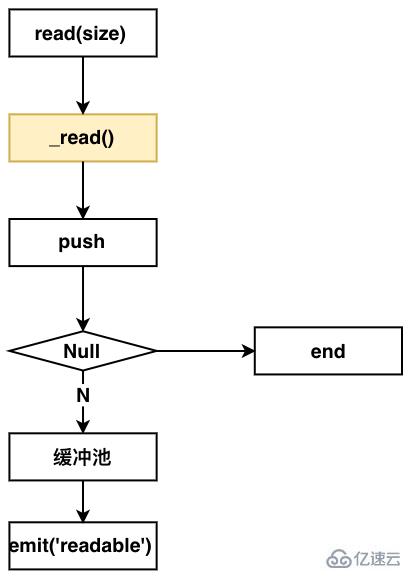
д»ҺиҝҷдёӘеӣҫдёҠзңӢеҮәпјҢдҪ иҰҒе®һзҺ°иҜҘжЁЎејҸзҡ„иҜ»жөҒпјҢеҗҢж ·иҰҒе®һзҺ°дёҖдёӘ_readж–№жі•гҖӮ
ж•ҙдёӘжөҒзЁӢеҰӮдёӢпјҡзӣ‘еҗ¬readableж–№жі•пјҢReadableеҶ…йғЁе°ұдјҡи°ғз”Ёreadж–№жі•гҖӮи°ғз”Ёз”ЁжҲ·е®һзҺ°зҡ„_readж–№жі•пјҢжқҘpushж•°жҚ®еҲ°зј“еҶІжұ пјҢ然еҗҺеҸ‘йҖҒemit readableдәӢ件пјҢйҖҡзҹҘз”ЁжҲ·з«Ҝж¶Ҳиҙ№гҖӮ
д»ҺдҪҝз”ЁиҖ…зҡ„и§’еәҰжқҘзңӢпјҢдҪ еҸҜд»ҘйҖҡиҝҮдёӢйқўзҡ„ж–№ејҸжқҘдҪҝз”ЁиҜҘжЁЎејҸдёӢзҡ„жөҒ
const fs = require('fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('readable',function(chunk) {
while (null !== (chunk = myReadable.read())) {
writeFile.write(chunk);
}
});зӣёеҜ№дәҺиҜ»жөҒпјҢеҶҷжөҒзҡ„жңәеҲ¶е°ұжӣҙе®№жҳ“зҗҶи§ЈдәҶгҖӮ
еҶҷжөҒдҪҝз”ЁдёӢйқўзҡ„ж–№ејҸиҝӣиЎҢж•°жҚ®еҶҷе…Ҙ
myWrite.write(chunk);
и°ғз”ЁwriteеҗҺпјҢеҶ…йғЁWritableзҡ„жөҒзЁӢеҰӮдёӢеӣҫжүҖзӨә
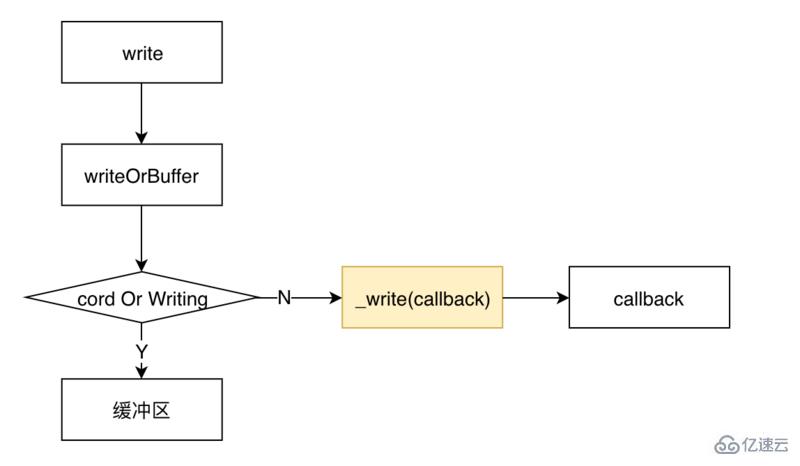
зұ»дјјдәҺиҜ»жөҒпјҢе®һзҺ°дёҖдёӘеҶҷжөҒпјҢеҗҢж ·йңҖиҰҒз”ЁжҲ·е®һзҺ°дёҖдёӘ_writeж–№жі•гҖӮ
ж•ҙдёӘжөҒзЁӢжҳҜиҝҷж ·зҡ„пјҡи°ғз”Ёwriteд№ӢеҗҺпјҢдјҡйҰ–е…ҲеҲӨе®ҡжҳҜеҗҰиҰҒеҶҷе…Ҙзј“еҶІеҢәгҖӮеҰӮжһңдёҚйңҖиҰҒпјҢйӮЈе°ұи°ғз”Ёз”ЁжҲ·е®һзҺ°зҡ„_writeж–№жі•пјҢе°ҶжөҒеҶҷе…ҘеҲ°зӣёеә”зҡ„ең°ж–№пјҢ_writeдјҡи°ғз”ЁдёҖдёӘwriteableеҶ…йғЁзҡ„дёҖдёӘеӣһи°ғеҮҪж•°гҖӮ
д»ҺдҪҝз”ЁиҖ…зҡ„и§’еәҰжқҘзңӢпјҢдҪҝз”ЁдёҖдёӘеҶҷжөҒпјҢйҮҮз”ЁдёӢйқўзҡ„д»Јз ҒжүҖзӨәзҡ„ж–№ејҸгҖӮ
const fs = require('fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('data',function(chunk) {
writeFile.write(chunk);
})еҸҜд»ҘзңӢеҲ°пјҢдҪҝз”ЁеҶҷжөҒжҳҜйқһеёёз®ҖеҚ•зҡ„гҖӮ
жҲ‘们е…Ҳи®Іи§ЈдёҖдёӢеҰӮдҪ•е®һзҺ°дёҖдёӘиҜ»жөҒе’ҢеҶҷжөҒпјҢеҶҚжқҘзңӢDuplexе’ҢTransformжҳҜд»Җд№ҲпјҢеӣ дёәдәҶи§ЈдәҶеҰӮдҪ•е®һзҺ°дёҖдёӘиҜ»жөҒе’ҢеҶҷжөҒпјҢеҶҚжқҘзҗҶи§ЈDuplexе’ҢTransformе°ұйқһеёёз®ҖеҚ•дәҶгҖӮ
е®һзҺ°иҮӘе®ҡд№үзҡ„ReadableпјҢеҸӘйңҖиҰҒе®һзҺ°дёҖдёӘ_readж–№жі•еҚіеҸҜпјҢйңҖиҰҒеңЁ_readж–№жі•дёӯи°ғз”Ёpushж–№жі•жқҘе®һзҺ°ж•°жҚ®зҡ„з”ҹдә§гҖӮеҰӮдёӢйқўзҡ„д»Јз ҒжүҖзӨәпјҡ
const Readable = require('stream').Readable;
class MyReadable extends Readable {
constructor(dataSource, options) {
super(options);
this.dataSource = dataSource;
}
_read() {
const data = this.dataSource.makeData();
setTimeout(()=>{
this.push(data);
});
}
}
// жЁЎжӢҹиө„жәҗжұ
const dataSource = {
data: new Array(10).fill('-'),
makeData() {
if (!dataSource.data.length) return null;
return dataSource.data.pop();
}
};
const myReadable = new MyReadable(dataSource,);
myReadable.on('readable', () => {
let chunk;
while (null !== (chunk = myReadable.read())) {
console.log(chunk);
}
});е®һзҺ°иҮӘе®ҡд№үзҡ„writableпјҢеҸӘйңҖиҰҒе®һзҺ°дёҖдёӘ_writeж–№жі•еҚіеҸҜгҖӮеңЁ_writeдёӯж¶Ҳиҙ№chunkеҶҷе…ҘеҲ°зӣёеә”ең°ж–№пјҢ并且и°ғз”Ёcallbackеӣһи°ғгҖӮеҰӮдёӢйқўд»Јз ҒжүҖзӨәпјҡ
const Writable = require('stream').Writable;
class Mywritable extends Writable{
constuctor(options){
super(options);
}
_write(chunk,endcoding,callback){
console.log(chunk);
callback && callback();
}
}
const myWritable = new Mywritable();еҸҢе·ҘжөҒпјҡз®ҖеҚ•зҗҶи§ЈпјҢе°ұжҳҜи®ІдёҖдёӘReadableжөҒе’ҢдёҖдёӘWritableжөҒз»‘е®ҡеҲ°дёҖиө·пјҢе®ғж—ўеҸҜд»Ҙз”ЁжқҘеҒҡиҜ»жөҒпјҢеҸҲеҸҜд»Ҙз”ЁжқҘеҒҡеҶҷжөҒгҖӮ
е®һзҺ°дёҖдёӘDuplexжөҒпјҢдҪ йңҖиҰҒеҗҢж—¶е®һзҺ°_readе’Ң_writeж–№жі•гҖӮ
жңүдёҖзӮ№йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡе®ғжүҖеҢ…еҗ«зҡ„ ReadableжөҒе’ҢWritableжөҒжҳҜе®Ңе…ЁзӢ¬з«ӢпјҢдә’дёҚеҪұе“Қзҡ„дёӨдёӘжөҒпјҢдёӨдёӘжөҒдҪҝз”Ёзҡ„дёҚжҳҜеҗҢдёҖдёӘзј“еҶІеҢәгҖӮйҖҡиҝҮдёӢйқўзҡ„д»Јз ҒеҸҜд»ҘйӘҢиҜҒ
// жЁЎжӢҹиө„жәҗжұ 1
const dataSource1 = {
data: new Array(10).fill('a'),
makeData() {
if (!dataSource1.data.length) return null;
return dataSource1.data.pop();
}
};
// жЁЎжӢҹиө„жәҗжұ 2
const dataSource2 = {
data: new Array(10).fill('b'),
makeData() {
if (!dataSource2.data.length) return null;
return dataSource2.data.pop();
}
};
const Readable = require('stream').Readable;
class MyReadable extends Readable {
constructor(dataSource, options) {
super(options);
this.dataSource = dataSource;
}
_read() {
const data = this.dataSource.makeData();
setTimeout(()=>{
this.push(data);
})
}
}
const Writable = require('stream').Writable;
class MyWritable extends Writable{
constructor(options){
super(options);
}
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback && callback();
}
}
const Duplex = require('stream').Duplex;
class MyDuplex extends Duplex{
constructor(dataSource,options) {
super(options);
this.dataSource = dataSource;
}
_read() {
const data = this.dataSource.makeData();
setTimeout(()=>{
this.push(data);
})
}
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback && callback();
}
}
const myWritable = new MyWritable();
const myReadable = new MyReadable(dataSource1);
const myDuplex = new MyDuplex(dataSource1);
myReadable.pipe(myDuplex).pipe(myWritable);жү“еҚ°зҡ„з»“жһңжҳҜ
abababababababababab
д»ҺиҝҷдёӘз»“жһңеҸҜд»ҘзңӢеҮәпјҢmyReadable.pipe(myDuplex)пјҢmyDuplexе……еҪ“зҡ„жҳҜеҶҷжөҒпјҢеҶҷе…Ҙзҡ„еҶ…е®№жҳҜaпјӣmyDuplex.pipe(myWritable)пјҢmyDuplexе……еҪ“зҡ„жҳҜиҜ»жөҒпјҢеҫҖmyWritableеҶҷзҡ„еҚҙжҳҜbпјӣжүҖд»ҘиҜҙе®ғжүҖеҢ…еҗ«зҡ„ ReadableжөҒе’ҢWritableжөҒжҳҜе®Ңе…ЁзӢ¬з«Ӣзҡ„гҖӮ
зҗҶи§ЈдәҶDuplexпјҢе°ұжӣҙеҘҪзҗҶи§ЈTransformдәҶгҖӮTransformжҳҜдёҖдёӘиҪ¬жҚўжөҒпјҢе®ғж—ўжңүиҜ»зҡ„еҠҹиғҪеҸҲжңүеҶҷзҡ„еҠҹиғҪпјҢдҪҶжҳҜе®ғе’ҢDuplexдёҚеҗҢзҡ„жҳҜпјҢе®ғзҡ„иҜ»жөҒе’ҢеҶҷжөҒе…ұз”ЁеҗҢдёҖдёӘзј“еҶІеҢәпјӣд№ҹе°ұжҳҜиҜҙпјҢйҖҡиҝҮе®ғиҜ»е…Ҙд»Җд№ҲпјҢйӮЈе®ғе°ұиғҪеҶҷе…Ҙд»Җд№ҲгҖӮ
е®һзҺ°дёҖдёӘTransformпјҢдҪ еҸӘйңҖиҰҒе®һзҺ°дёҖдёӘ_transformж–№жі•гҖӮжҜ”еҰӮжңҖз®ҖеҚ•зҡ„Transform:PassThroughпјҢе…¶жәҗд»Јз ҒеҰӮдёӢжүҖзӨә
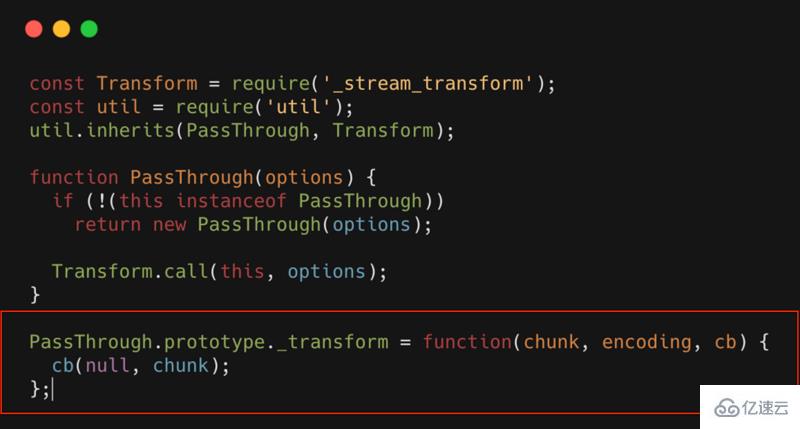
PassThroughе°ұжҳҜдёҖдёӘTransformпјҢдҪҶжҳҜиҝҷдёӘиҪ¬жҚўжөҒпјҢд»Җд№Ҳд№ҹжІЎеҒҡпјҢзӣёеҪ“дәҺдёҖдёӘйҖҸжҳҺзҡ„иҪ¬жҚўжөҒгҖӮеҸҜд»ҘзңӢеҲ°_transformдёӯд»Җд№ҲйғҪжІЎжңүпјҢеҸӘжҳҜз®ҖеҚ•зҡ„е°Ҷж•°жҚ®иҝӣиЎҢеӣһи°ғгҖӮ
еҰӮжһңжҲ‘们еңЁиҝҷдёӘзҺҜиҠӮеҒҡдәӣжү©еұ•пјҢеҸӘйңҖиҰҒеңЁ_transformдёӯзӣҙжҺҘжү©еұ•е°ұиЎҢдәҶгҖӮжҜ”еҰӮжҲ‘们еҸҜд»ҘеҜ№жөҒиҝӣиЎҢеҺӢзј©пјҢеҠ еҜҶпјҢж··ж·Ҷзӯүзӯүж“ҚдҪңгҖӮ
жңҖеҗҺд»Ӣз»ҚдёҖдёӘжөҒдёӯйқһеёёйҮҚиҰҒзҡ„дёҖдёӘжҰӮеҝөпјҡиғҢеҺӢгҖӮиҰҒдәҶи§ЈиҝҷдёӘпјҢжҲ‘们йҰ–е…ҲжқҘзңӢдёӢpipeе’ҢhighWaterMakerжҳҜд»Җд№ҲгҖӮ
йҰ–е…ҲзңӢдёӢдёӢйқўзҡ„д»Јз Ғ
const fs = require('./fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.pipe(writeFile);дёҠйқўзҡ„д»Јз Ғе’ҢдёӢйқўжҳҜзӯүд»·зҡ„
const fs = require('./fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('data',function(data){
var flag = ws.write(data);
if(!flag){ // еҪ“еүҚеҶҷжөҒзј“еҶІеҢәе·Іж»ЎпјҢжҡӮеҒңиҜ»ж•°жҚ®
readFile.pause();
}
})
writeFile.on('drain',function()){
readFile.resume();// еҪ“еүҚеҶҷжөҒзј“еҶІеҢәе·Іжё…з©әпјҢйҮҚж–°ејҖе§ӢиҜ»жөҒ
}
readFile.on('end',function(data){
writeFile.end();//е°ҶеҶҷжөҒзј“еҶІеҢәзҡ„ж•°жҚ®е…ЁйғЁеҶҷе…ҘпјҢ并且关й—ӯеҶҷе…Ҙзҡ„ж–Ү件
})pipeжүҖеҒҡзҡ„ж“ҚдҪңе°ұжҳҜзӣёеҪ“дәҺдёәеҶҷжөҒе’ҢиҜ»жөҒиҮӘеҠЁеҒҡдәҶйҖҹеәҰзҡ„еҢ№й…ҚгҖӮ
иҜ»еҶҷжөҒйҖҹеәҰдёҚеҢ№й…Қзҡ„жғ…еҶөдёӢпјҢдёҖиҲ¬жғ…еҶөдёӢдёҚдјҡйҖ жҲҗд»Җд№Ҳй—®йўҳпјҢдҪҶжҳҜдјҡйҖ жҲҗеҶ…еӯҳеўһеҠ гҖӮеҶ…еӯҳж¶ҲиҖ—еўһеҠ пјҢе°ұжңүеҸҜиғҪдјҡеёҰжқҘдёҖзі»еҲ—зҡ„й—®йўҳгҖӮжүҖд»ҘеңЁдҪҝз”Ёзҡ„жөҒзҡ„ж—¶еҖҷпјҢејәзғҲжҺЁиҚҗдҪҝз”ЁpipeгҖӮ
highWaterMakerиҜҙзҷҪдәҶпјҢе°ұжҳҜе®ҡд№үзј“еҶІеҢәзҡ„еӨ§е°ҸгҖӮ
й»ҳи®Ө16KbпјҲReadableжңҖеӨ§8M)
еҸҜд»ҘиҮӘе®ҡд№ү
иғҢеҺӢзҡ„жҰӮеҝөеҸҜд»ҘзҗҶи§ЈдёәпјҡдёәдәҶйҳІжӯўиҜ»еҶҷжөҒйҖҹеәҰдёҚеҢ№й…ҚиҖҢдә§з”ҹзҡ„дёҖз§Қи°ғж•ҙжңәеҲ¶пјӣиғҢеҺӢиҜҘи°ғж•ҙжңәеҲ¶зҡ„и§ҰеҸ‘ж—¶жңәпјҢеҸ—йҷҗдәҺhighWaterMakerи®ҫзҪ®зҡ„еӨ§е°ҸгҖӮ
еҰӮдёҠйқўзҡ„д»Јз Ғ var flag = ws.write(data);пјҢдёҖж—ҰеҶҷжөҒзҡ„зј“еҶІеҢәж»ЎдәҶпјҢйӮЈflagе°ұдјҡзҪ®дёәfalseпјҢеҸҚеҗ‘дҝғиҝӣиҜ»жөҒзҡ„йҖҹеәҰи°ғж•ҙгҖӮ
дё»иҰҒжңүд»ҘдёӢеңәжҷҜ
ж–Ү件ж“ҚдҪң(еӨҚеҲ¶пјҢеҺӢзј©пјҢи§ЈеҺӢпјҢеҠ еҜҶзӯү)
дёӢйқўзҡ„е°ұеҫҲе®№жҳ“е°ұе®һзҺ°дәҶж–Ү件еӨҚеҲ¶зҡ„еҠҹиғҪгҖӮ
const fs = require('fs');
const readFile = fs.createReadStream('big.file');
const writeFile = fs.createWriteStream('big_copy.file');
readFile.pipe(writeFile);йӮЈжҲ‘们жғіеңЁеӨҚеҲ¶зҡ„иҝҮзЁӢдёӯеҜ№ж–Ү件иҝӣиЎҢеҺӢзј©е‘ўпјҹ
const fs = require('fs');
const readFile = fs.createReadStream('big.file');
const writeFile = fs.createWriteStream('big.gz');
const zlib = require('zlib');
readFile.pipe(zlib.createGzip()).pipe(writeFile);е®һзҺ°и§ЈеҺӢгҖҒеҠ еҜҶд№ҹжҳҜзұ»дјјзҡ„гҖӮ
йқҷжҖҒж–Ү件жңҚеҠЎеҷЁ
жҜ”еҰӮйңҖиҰҒиҝ”еӣһдёҖдёӘhtmlпјҢеҸҜд»ҘдҪҝз”ЁеҰӮдёӢд»Јз ҒгҖӮ
var http = require('http');
var fs = require('fs');
http.createServer(function(req,res){
fs.createReadStream('./a.html').pipe(res);
}).listen(8000);е…ідәҺвҖңNode StreamдёӯиҝҗиЎҢжңәеҲ¶зҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ