您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“Node.js怎么实现爬取网站图片”,在日常操作中,相信很多人在Node.js怎么实现爬取网站图片问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Node.js怎么实现爬取网站图片”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
开发一个小爬虫,涉及的知识点如下所示:
https模块,主要是用户获取网络资源,如:网页源码,图片资源等。
cheerio模块,主要用于解析html源码,并可访问,查找html节点内容。
fs模块,主要用于文件的读写操作,如保存图片,日志等。
闭包,主要是对于异步操作,对象的隔离保护。
cheerio是为服务器特别定制的,快速、灵活、实施的jQuery核心实现。主要用于在服务端解析html。特点如下所示:
易用,语法类似jQuery语法,从jQuery库中去除了所有 DOM不一致性和浏览器尴尬的部分。
解析快,比JSDOM快八倍。
灵活,Cheerio 封装了兼容的htmlparser。Cheerio 几乎能够解析任何的 HTML 和 XML document。
首先在命令行,切换到程序目录,然后输入安装命令进行安装,如下所示:
cnpm install cheerio
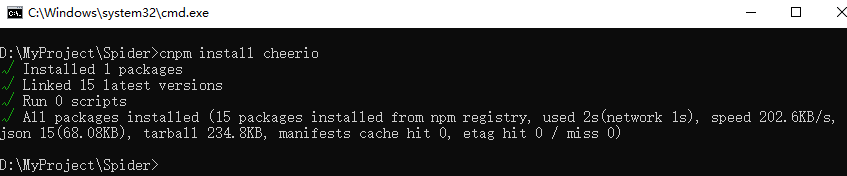
安装过程,如下所示:
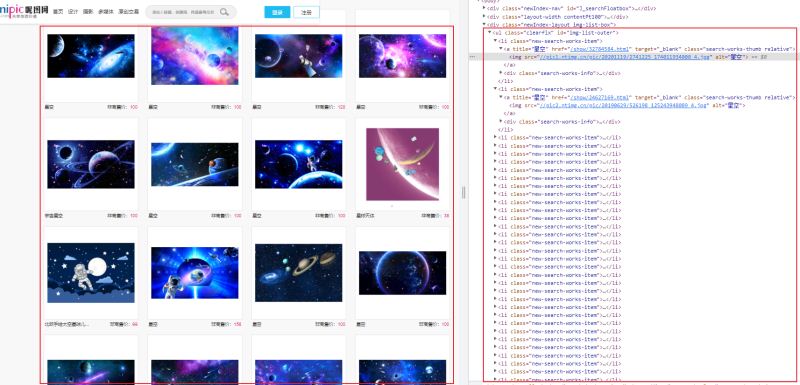
在编写爬虫之前,首先需要分析目标内容,本次需要爬取的是某网站,星空类型的图片内容,经过分析,发现所有的图片都是在ul下每一个li中的a标签内的img中,本次只需要解析出img的src属性,即可获取图片的下载路径。如下所示:
经过以上分析,通过Node.js编写代码,分为两步,获取所有图片的url路径,即解析所有目标img元素的src属性。然后再下载具体图片进行保存即可。
引用所需要的功能模块,如下所示:
var https = require('https');
var cheerio = require('cheerio');
var fs = require('fs');获取并解析html页面内容,如下所示:
//爬取的网址
var addrs=['https://www.*****.com/topic/show_27202_1.html','https://www.******.com/topic/show_27202_2.html','https://www.*****.com/topic/show_27202_3.html'];
var logger = fs.createWriteStream('./download/log.txt',{flags:'a+',autoClose:'true'});
for(i in addrs){
(function(num){
var addr = addrs[num];
//创建目录
var p1 = new Promise(function(resolve,reject){
fs.access('./download',function(err){
if(err){
fs.mkdir('./download',function(e){
if(e){
console.log('创建失败');
}
});
}else{
resolve("success");
}
});
});
p1.then(function(datas){
var html='';
var p2 = new Promise(function(resolve,reject){
https.get(addr,function(res){
res.on('data',function(data){
html+=data.toString();
})
res.on('end',function(){
resolve("success");
});
});
});
p2.then(function(data){
//下载完成后,进行解析
const $ =cheerio.load(html);
var lis = $('#img-list-outer').find('li');
for(var j=0;j<lis.length-1;j++){
var li = lis[j];
var src =$(li).find('a').find('img').attr('src');
//console.log(src);
//console.log('-------------------------');
var imgurl='https:'+src;
download(imgurl);
var msg='['+j+']下载成功:'+imgurl;
logger.write(msg+'\n');
console.log(msg);
}
});
});
})(i);
}注意:因为所有爬取的目标共分为3页,所以用到了循环,并且在循环中用到了闭包。
下载并保存单张图片代码,如下所示:
//下载图片
function download(imgurl){
var p1 = new Promise(function(resolve,reject){
https.get(imgurl,function(res){
var imgName=imgurl.substr(imgurl.lastIndexOf('/')+1);
var stream = fs.createWriteStream('./download/'+imgName);
res.pipe(stream);
setTimeout(function(){
resolve('success');
},300);
});
});
p1.then(function(data){
return;
});
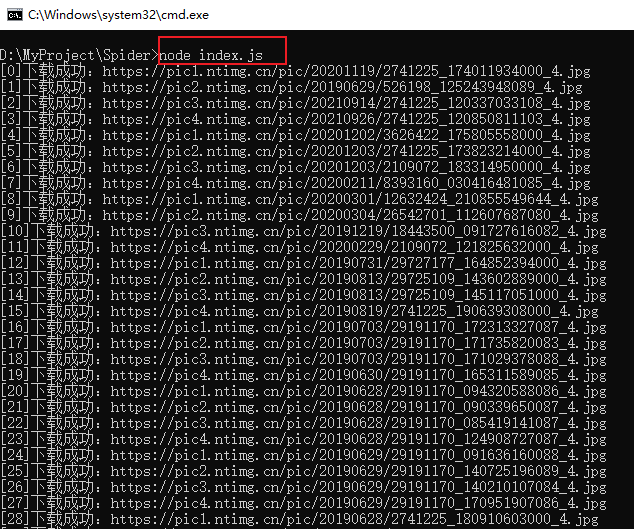
}开发完成后,运行代码,如下所示
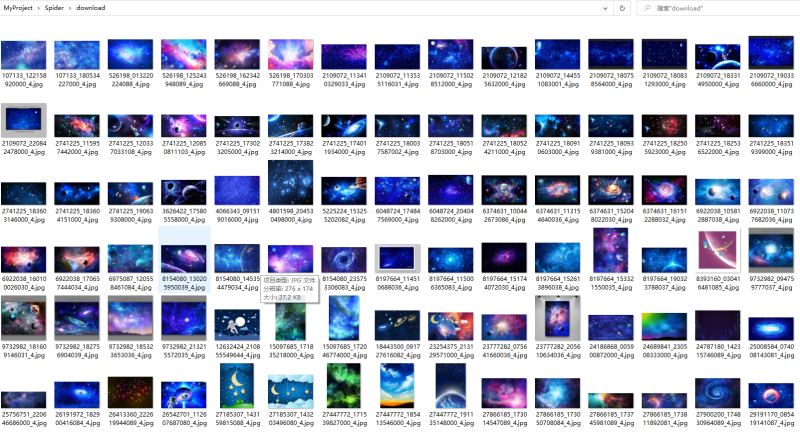
爬取的图片,保存在文件夹中,如下所示:
注意:添加日志,是为了方便记录程序执行过程,对比图片和日志,便于发现问题。
到此,关于“Node.js怎么实现爬取网站图片”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。