您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章运用简单易懂的例子给大家介绍C#调用API生成RSS资源文件的方法,代码非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
RSS就是简易信息聚合(也叫聚合内容),是一种RSS基于XML标准,在互联网上被广泛采用的内容包装和投递协议。RSS(Really Simple Syndication)是一种描述和同步网站内容的格式,是使用最广泛的XML应用。RSS搭建了信息迅速传播的一个技术平台,使得每个人都成为潜在的信息提供者。发布一个RSS文件后,这个RSS Feed中包含的信息就能直接被其他站点调用,而且由于这些数据都是标准的XML格式,所以也能在其他的终端和服务中使用,是一种描述和同步网站内容的格式。
1. 新浪微博RSS订阅第三方网站
新浪微博本身没有提供RSS订阅,但是到网上搜索,发现了一个第三方的网站,提供新浪微博的RSS资源,所以,本文的RSS订阅说白了都是基于这个第三方网站的。
log.medcl.net/item/2010/02/sina-bo-rss-subscribe-feed-generate-micro/
2. 网上通用的OPML文件的XML格式
下面是从Google Reader中导出的opml文件,这是网络RSS阅读器甚至所有RSS阅读器的标准格式吧,至少“鲜果”,“有道”这些比较流行的在线阅读器都支持这个格式的文件导入。
<?xml version="1.0" encoding="UTF-8"?><opml version="1.0"> <head> <title>subscriptions</title> <dateCreated>2010-05-16 15:45:03</dateCreated> <ownerName></ownerName> </head> <body> <outline text="微博客" title="微博客"> <outline text="冷笑话(1567852087)" title="冷笑话(1567852087)" type="rss" htmlUrl="http://t.sina.com.cn/1567852087" xmlUrl="http://medcl.net/SinaRss.aspx?uid=1567852087" /> <outline text="后宫优雅(1665289110)" title="后宫优雅(1665289110)" type="rss" htmlUrl="http://t.sina.com.cn/1665289110" xmlUrl="http://medcl.net/SinaRss.aspx?uid=1665289110" /> <outline text="围脖经典语录" title="围脖经典语录" type="rss" htmlUrl="http://t.sina.com.cn/1646465281" xmlUrl="http://medcl.net/SinaRss.aspx?uid=1646465281" /> <outline text="破阵子(1644022141)" title="破阵子(1644022141)" type="rss" htmlUrl="http://t.sina.com.cn/1644022141" xmlUrl="http://medcl.net/SinaRss.aspx?uid=1644022141" /> </outline> <outline text="珞珈山水" title="珞珈山水"> <outline text="今日十大热门话题" title="今日十大热门话题" type="rss" htmlUrl="http://bbs.whu.edu.cn/frames.html" xmlUrl="http://bbs.whu.edu.cn/rssi.php?h=1" /> <outline text="贴图版" title="贴图版" type="rss" htmlUrl="http://bbs.whu.edu.cn/wForum/board.php?name=Picture" xmlUrl="http://bbs.whu.edu.cn/wForum/rss.php?board=Picture&ic=1" /> </outline> </body></opml> |
分析OPML文件的架构,然后方便通过程序来将它需要的信息写成此架构的文件,便于阅读器引用。 OPML文件由头部标签<head>(主要是本文件的一些注释,不影响实际的RSS订阅信息,不是太重要)和<body>(RSS阅读器提取订阅资源的全部数据来源)。在<body>节点下面有个一级的<outline>节点,这个节点对应RSS阅读器中地RSS资源的分类文件夹相关信息(显然text表示的就是文件夹名称),然后一级<outline>下面就是二级的<outline>标签对,这里面就是RSS资源的相关数据内容了。二级<outline>中的节点的一些重要属性:text表示资源的标题,htmlUrl表示的是信息的的Web网页地址,xmlUrl表示的是信息的RSS订阅地址。
3. 新浪微博API――从服务器上导出用户好友数据到本地XML文件
下面是自己整理的代码,从服务器上请求用户的好友信息:
private void getFriends()
{ int previous_cursor=-1; int next_cursor = -1; while (next_cursor != 0)
{ string cursor = Convert.ToString(previous_cursor); string url = " http://api.t.sina.com.cn/statuses/friends.xml?source=AppKey&cursor=" + cursor; string username = "dreamzsm@gmail.com"; string password = name; //这里输入你自己微博登录的的密码
//注意这里的格式哦,为 "username:password"
System.Net.WebRequest webRequest = System.Net.WebRequest.Create(url);
System.Net.HttpWebRequest myReq = webRequest as System.Net.HttpWebRequest; //身份验证
string usernamePassword = username + ":" + password;
CredentialCache mycache = new CredentialCache();
mycache.Add(new Uri(url), "Basic", new NetworkCredential(username, password));
myReq.Credentials = mycache;
myReq.Headers.Add("Authorization", "Basic " + Convert.ToBase64String(new ASCIIEncoding().GetBytes(usernamePassword)));
WebResponse wr = myReq.GetResponse();
Stream receiveStream = wr.GetResponseStream();
StreamReader reader = new StreamReader(receiveStream, Encoding.UTF8); string content = reader.ReadToEnd();
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.LoadXml(content); // xmlDoc.Load("data1.xml");
XmlNodeList nodeList = xmlDoc.SelectSingleNode("users").ChildNodes;//获取根节点的所有子节点
next_cursor = Convert.ToInt16(nodeList.Item(nodeList.Count - 2).InnerText);
previous_cursor = Convert.ToInt16(nodeList.Item(nodeList.Count-1).InnerText); string xmlName = "friends_" + nodeList.Item(nodeList.Count - 1).InnerText + "_" + Convert.ToInt16(nodeList.Item(nodeList.Count - 2).InnerText) + ".xml";
previous_cursor = next_cursor;
xmlDoc.Save(xmlName);
}
} |
 为了程序设计简单一点,笔者就有点偷懒了,没有仔细研究如何将所有的数据写到一个XML文件中,而是每次请求得到的20条数据写成一个XML文件,最后我159个好友,按照指定的命名方法生成了8个XML文件。
为了程序设计简单一点,笔者就有点偷懒了,没有仔细研究如何将所有的数据写到一个XML文件中,而是每次请求得到的20条数据写成一个XML文件,最后我159个好友,按照指定的命名方法生成了8个XML文件。
如此,就得到了所有的你的好友(就是你跟随的人)的信息了,以单人为例,其主要信息如下:
<user>
<id>1710993410</id>
<screen_name>某丫大人</screen_name>
<name>某丫大人</name>
<province>43</province>
<city>1</city>
<location>湖南 长沙</location>
<description>饭否儿,心朝饭否,春暖花开。 我还是@饿YA 我还真是懒得介绍了。</description>
<url>http://1</url>
<profile_image_url>http://tp3.sinaimg.cn/1710993410/50/1273755892</profile_image_url>
<domain>
</domain>
<gender>f</gender>
<followers_count>168</followers_count>
<friends_count>79</friends_count>
<statuses_count>846</statuses_count>
<favourites_count>0</favourites_count>
<created_at>Sun Mar 14 00:00:00 +0800 2010</created_at>
<following>false</following>
<verified>false</verified>
<allow_all_act_msg>false</allow_all_act_msg>
<geo_enabled>false</geo_enabled>
<status>
<created_at>Sun May 16 21:02:44 +0800 2010</created_at>
<id>364379114</id>
<text>烦死了快、</text>
<source>
<a href="">新浪微博</a>
</source>
<favorited>false</favorited>
<truncated>false</truncated>
<geo />
<in_reply_to_status_id>
</in_reply_to_status_id>
<in_reply_to_user_id>
</in_reply_to_user_id>
<in_reply_to_screen_name>
</in_reply_to_screen_name>
</status>
</user> |
可以看到这里面的信息量是超级多的,我简单介绍下几个主要的节点吧
id | 用户新浪微博的数字ID,就像你的QQ号一样 |
name | 用户昵称 |
province | 省代号 |
city | 市代号 |
location | 所在省市(好像和上面两个节点重复了) |
description | 自我描述 |
domain | 域名,就是除了数字ID后,用户申请的修改域名 |
gender | 性别。男的是Male,女的是Female. |
followers_count | 粉丝数 |
friends_count | 跟随的人数 |
statuses_count | 发表的状态也就是微博数 |
favourites_count | 收藏微博数目吧?(不知道这个有什么用) |
created_at | 用户创建此微博客的时间 |
verified | 是否经过新浪的VIP认证 |
status | 用户最近的一次状态 |
除了user信息外,还有一些其它信息,比如根节点下的next_cursor和previous_cousor,这方便用户分多次到服务器上请求数据时可以此作为定位依据。
<next_cursor>20</next_cursor> <previous_cursor>0</previous_cursor> |
4. 将XML文件存储到ACCESS数据库中进行备份
如果不想备份的可以直接从第3步中到第5步,但是笔者,觉得将数据转换成此构架后,更加方便后来的程序操作以及浏览数据。
关于XML的详细方法参考:小气的鬼
《在C#.net中如何操作XML》
www.cnblogs.com/weekzero/archive/2005/06/21/178140.html
下面开始读取刚才从新浪微博服务器上请求得到的XML文件了。然后转换成ACCESS数据库内容。(当然你要先用ACCESS在指定目录下建立一个*.mdb文件用来存储数据)
下面是对单个XML文件进行读取,并插入到数据库中(这段代码是在ASP.NET中写的)
public void readTsinaFriends(string fileName)
{
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.Load(Server.MapPath(fileName));
XmlNodeList nodeList = xmlDoc.SelectSingleNode("users").ChildNodes;//获取 根节点的所有子节点
; //删除不用的一级节点,比如提示人数的所在位置的标记
XmlNode root = xmlDoc.SelectSingleNode("users"); // XmlNodeList xnl = xmlDoc.SelectSingleNode("Employees").ChildNodes;
for (int k = 0; k < nodeList.Count; k++)
{
XmlElement xe = (XmlElement)nodeList.Item(k); if(xe.Name=="user")
{//去掉XML文件中不需要的节点:next_cursor,previous_coursor以及user节点中的status,方便XML直接转换成DataTable
XmlNodeList nodeList1 = xmlDoc.SelectNodes("users/user");//得到所有的标签user一级节点
foreach (XmlNode xmlNodeTemp in nodeList1)
{ if (xmlNodeTemp.LastChild.Name == "status")//移除每个user节点中的"status"子节点--(一般情况下此节点都放在最后一个,所以就不遍历了,直接地址定位)
{
xmlNodeTemp.RemoveChild(xmlNodeTemp.LastChild);
}
}
} else if (xe.Name == "next_cursor" || xe.Name == "previous_cursor")
{
root.RemoveChild(xe); if (k < nodeList.Count) k = k - 1;
}
} string tbxml = xmlDoc.OuterXml;
DataTable dt = new DataTable();
DataSet ds = new DataSet();
System.IO.StringReader reader = new System.IO.StringReader(tbxml);
ds.ReadXml(reader);
dt = ds.Tables[0];//如果XML文本中有同名的父子节点,那么此语句就会多读出一条数据,这可能是此API函数的局限性吧
DataTable dtCopy = dt.Copy(); //dtCopy.Columns.Remove("url");
//dtCopy.Columns.Remove("profile_image_url");
dtCopy.Columns.Remove("description"); //这个字段里面字符编码不太规则,在插入ACCESS的时候总有问题,而且用处不大,所以就去除了。(又偷懒了呃)
DataRow drTemp = dtCopy.NewRow(); string strInsert = string.Empty;
OleDbConnection aConnection = new OleDbConnection("Provider=Microsoft.Jet.OLEDB.4.0;Data Source=E:\\coursware\\网络软文\\API_微波\\weibo.mdb");
aConnection.Open(); for (int i = 0; i < dtCopy.Rows.Count - 1; i++)
{
drTemp = dtCopy.Rows[i];
strInsert = "'"+drTemp[0].ToString()+"','"; for (int j = 1; j < dtCopy.Columns.Count - 1; j++)
{
strInsert += (drTemp[j].ToString() + "','");
}
strInsert += drTemp[dtCopy.Columns.Count - 1].ToString() + "'";
string strCmd = "INSERT INTO Friends VALUES(" + strInsert + ")";
OleDbCommand command = new
OleDbCommand(strCmd, aConnection);
command.ExecuteNonQuery();
}
aConnection.Close();
} |
对多个XML文件进行遍历,一个个导入到ACCESS数据库中:
/// <summary>
/// 将所有好友都导出了,然后存储在ACCESS数据库中了。
/// </summary>
public void readAllXml()
{ for (int i = 0; i < 8; i++)
{ string fileName = "friends_" + Convert.ToString(i * 20) + "_" + Convert.ToString(i*20+20)+".xml";//按照存储XML文件时的命名规则进行读取
readTsinaFriends(fileName);
}
} |
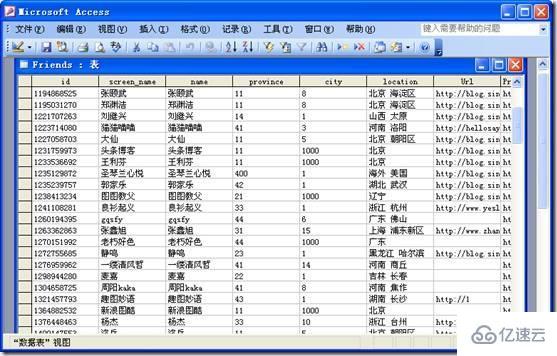
经过上面的操作后,你再打开你的ACCESS数据库文件weibo.mdb文件中对应的表,就可以看到所以的信息都已经导入到ACCESS中了。如下图所示:
5. 对ACCESS数据库查询并写成RSS阅读器的OPML格式
对于制作RSS阅读器的OPML格式,需要的数据只有两条字段:一个是id字段,一个是name字段。
这个过程实际上就是对数据进行XML编码的过程,啥都不说了,一切都在代码中了(也是在ASP.NET工程中写的):
/// <summary>
/// 建立新浪微博的RSS文件
/// </summary>
public void CreateTsinaRssXmlFile()
{
OleDbConnection aConnection = new OleDbConnection("Provider=Microsoft.Jet.OLEDB.4.0;Data Source=E:\\coursware\\网络软文\\API_微波\\weibo.mdb"); string strCmd = "select id as idnum,screen_name as name from Friends"; //从ACCESS中获取数据
aConnection.Open();
OleDbDataAdapter da = new OleDbDataAdapter(strCmd, aConnection);
DataSet ds = new DataSet();
da.Fill(ds, "TSina");
ds.DataSetName = "RssReader";
DataTable dt = ds.Tables[0];//数据集的第0张表格
XmlDocument xmldoc;
XmlElement xmlelem;
xmldoc = new XmlDocument(); //加入XML的声明段落
XmlDeclaration xmldecl;
xmldecl = xmldoc.CreateXmlDeclaration("1.0", "UTF-8", null);
xmldoc.AppendChild(xmldecl); //加入一个根元素
xmlelem = xmldoc.CreateElement(" ", "opml", " ");
xmldoc.AppendChild(xmlelem);
XmlNode root = xmldoc.SelectSingleNode("opml");//查找<opml> 节点
XmlElement xeHead = xmldoc.CreateElement("head");//创建一个<head>节点
//为head节点增加子节点
XmlElement xeHeadsub = xmldoc.CreateElement("title");
xeHeadsub.InnerText = "Rss Reader";//设置节点文本
xeHead.AppendChild(xeHeadsub);//添加到<head>子节点中
root.AppendChild(xeHead);//添加到<head>节点中
//增加body子节点,然后,将所有的RSS订阅信息全部写入到body节点中间
XmlElement xeBody = xmldoc.CreateElement("body");
root.AppendChild(xeBody); //第一层循环是标签(文件夹循环)由于本次只做一个标签,所以就只循环一次了
//RSS的文件夹属性节点
XmlElement xe1 = xmldoc.CreateElement("outline");
xe1.SetAttribute("text", "Tsina");//设置该节点title属性
xe1.SetAttribute("title", "Tsina");//设置该节点title属性 --第一层的outline节点的属性表示的是RSS的标签或者说是文件夹
//下面就要开始为此文件夹节点添加下属子节点,也就是添加一些实质的RSS地址了
string strTitle = string.Empty; string strText = string.Empty; string strXmlUrl = string.Empty; string strHtmlUrl = string.Empty; for (int i = 0; i < dt.Rows.Count; i++)
{
strTitle = dt.Rows[i]["NAME"].ToString().Trim();
strText = strTitle;
strXmlUrl = "http://medcl.net/SinaRss.aspx?uid=" + dt.Rows[i]["IDNum"].ToString().Trim();
strHtmlUrl = "http://t.sina.com.cn/" + dt.Rows[i]["IDNum"].ToString().Trim();
XmlElement xesub1 = xmldoc.CreateElement("outline");
xesub1.SetAttribute("text", strText);//设置该节点title属性
xesub1.SetAttribute("title", strTitle);//设置该节点title属性 --第一层的outline节点的属性表示的是RSS的标签或者说是文件夹
xesub1.SetAttribute("type", "rss");
xesub1.SetAttribute("xmlUrl", strXmlUrl);
xesub1.SetAttribute("htmlUrl", strHtmlUrl);
xe1.AppendChild(xesub1);//添加到<Node>节点中
}
xeBody.AppendChild(xe1); //保存创建好的XML文档
xmldoc.Save(Server.MapPath("RssReader.xml"));
} |
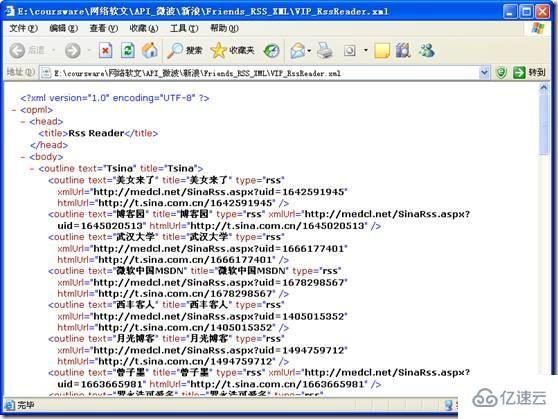
最后在指定的目录下,程序就自动生成了一个RssReader.xml的文件了。大功告成了!
然后将此文件就可以导入到任何一个RSS阅读器中了,用户就能够通过RSS阅读器来获取微博信息了,而且现在的RSS阅读器都有个一键转贴到微博的功能,很方便的,不想转到自己微博的,也可以通过RSS阅读器直接收藏到阅读器中。辛苦了两天,今天能有这么一点小成果,还是觉得很不错的,呵呵,也祝大家也能好运。本次代码比较还需要各种完善,比如,如何将所以的数据写成一个XML文件,这个笔者就暂时不做了,留给大家去做吧。
Rss阅读器效果图如下:
关于C#调用API生成RSS资源文件的方法就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。