您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“hbase的基本原理和使用”,在日常操作中,相信很多人在hbase的基本原理和使用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”hbase的基本原理和使用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
HBase是一个分布式的、面向列的开源数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
大:上亿行、百万列
面向列:面向列(族)的存储和权限控制,列(簇)独立检索
稀疏:对于为空(null)的列,并不占用存储空间,因此,表的设计的非常的稀疏
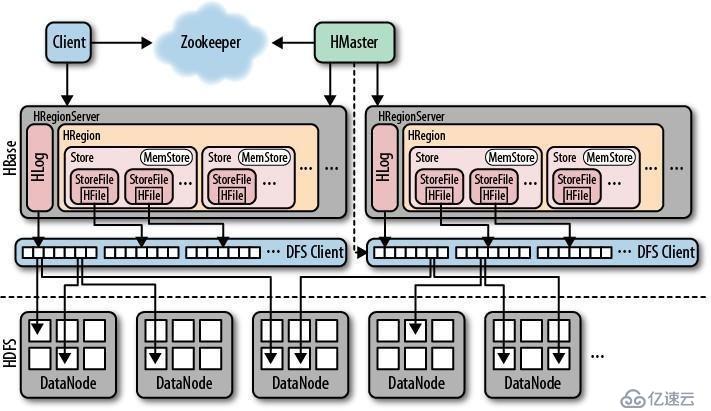
图 1.1 hbase架构图
可以看到,hbase是基于hdfs作为数据存储的。在hdfs之上就是hbase,hbase主要有三个组件:HMaster、HRegionServer、zookeeper。下面看看每个组件的功能。
HMaster不存储实际的数据,只是起到管理整个集群的作用。一般情况下集群中只有一个HMaster,如果配置了高可用,则还有一个备节点。功能如下:
1) 监控RegionServer,看是否正常工作,并将信息更新到zk的节点信息中
2) 处理RegionServer故障转移。将上面的region分配到其他RegionServer
3) 处理元数据的变更
4) 处理region的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过Zookeeper发布自己的位置给客户端
7)在Region Split后,负责新Region的分配
8)管理用户对Table的增、删、改、查操作
HRegionServer在集群中是有多个的,每个HRegionServer内部负责管理若干个region。每个region包含若干个store,每个store内部包含一个memstore和至少一个storefile,storefile内部包含一个hfile。memstore负责将数据暂存到内存中,当memstore的数据量达到阈值时,就会flush写到storefile中,最终写入到hdfs中。
由于memstore的数据并不是实时同步写入到storefile中的,而是达到一定条件才会写入,所以如果此时HRegionServer故障,内存的数据肯定会丢失的。但是如果同步写入到hdfs中,频繁触发IO,性能就会很差。所以出现了Hlog,一个HRegionServer只有一个hlog,用于记录对数据的更新操作,并且是这个hlog是实时写入到hdfs中的,防止丢失,这个机制类似于mysql的二进制日志。
HRegionServer的功能总结如下:
1) 负责存储HBase的实际数据
2) 处理分配给它的Region
3) 刷新缓存到HDFS
4) 维护HLog
5) 执行压缩
6) 负责处理Region分片
看到这里,疑问多多啊,比如region是个啥东西?别急,下面开始详细说。
一般来说,在普通RDBMS中,一张表的存储结构如下:以student表为例,有id、name、sex、pwd这几个列
| id | name | sex | pwd |
|---|---|---|---|
| 1 | 张三 | male | 123 |
| 2 | 李四 | female | 456 |
而在HBASE中,上面的表的逻辑结构大致为:
| row-key | column family1 | column family2 |
|---|---|---|
| 1 | info:{name:"张三",sex:“male”} | password:{pwd:123} |
| 2 | info:{name:"李四",sex:“female”} | password:{pwd:456} |
看的是不是有点懵?别急,慢慢来。有些名词先解释下
rowkey:
这是一行的key,但是这里的key的设计是很考究的,并不一定是原来的student表中的id字段作为rowkey(实际上生产中确实不会这么单一使用)
column family:
这是个新的概念,中文直译过来通常称为“列簇”,是列的一个集合,简称CF。一张表可以有多个CF(创建表时必须指定cf的名称,但不需要指定column名称),一个cf内部可以有任意多个column,而且是在插入数据的时候,才会指定有哪些column,以及这些column是在哪个cf下的。即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户使用时需要自行进行类型转换。 比如上面的 Info以及password就是cf,info这个cf内部有两个column,分别是name和sex,每个column对应一个value。password这个cf则只有pwd这个column。在hbase中column也称为 qulifimer。
刚刚说到了,这上面只是表在hbase中的逻辑结构,那么实际上hbase是怎么存储表的呢?上面我们说到hbase是个列式数据库,这里就体现出来了。
hbase的实际存储结构如下:
| rowkey | cf:column | cell value | timestamp |
|---|---|---|---|
| 1 | info:name | 张三 | 1564393837300 |
| 1 | info:sex | male | 1564393810196 |
| 1 | password:pwd | 123 | 1564393788068 |
| 2 | info:name | 李四 | 1564393837300 |
| 2 | info:sex | female | 1564393810196 |
| 2 | password:pwd | 456 | 1564393788068 |
可以看到,hbase中是将每一个单元格(cell)作为单独一行进行存储的,如果对应的cf的column没有value,那么就不会有任何存储记录,更不会占用任何空间。这也是hbase作为列式存储很典型的结构。
而且需要确定一个cell的位置,需要4个参数:rowkey+cf+column+timestamp。前面三个可以理解,为啥多个timestamp?那是因为hbase中对应一个cell的value有多版本(version)的概念,一个cell可以有多个value,那么这些value相互之间怎么区分?这时候仅凭rowkey+cf+column是没法区分的,所以就加了个timestamp,是该value更新的最后的时间戳,这样可以唯一确定一个cell了。默认情况下,一个cell的value的version是一个(实际上是cf的version才对,column只是基于cf的version设置的),而且就算有多个value,只有最新得一个value对外显示。一个column有多少个版本是可以设置的,如果插入的值超过设置的版本数,会优先覆盖最旧的版本。
你以为上面就是hbase的物理存储结构了?还不完全是哦,下面继续讲
我们知道,HRegionServer是负责数据的存储的。HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region(后面可以将HRrgion和region 是一个意思),一个表至少有一个region,一个region由[startkey,endkey)表示,注意闭开区间。一般来说,会事先根据原始数据的特性,预先划分为几个分区,然后每个分区一个region进行管理。至于region分布到哪些regionserver上是由HMaster分配的。HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
而每个HStore内部由两部分组成,MemStore(只有一个) & StoreFiles(至少一个)。下面讲讲这个两个东东。
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
这里思考一个点,compact操作中的作用:
我们知道,storefile是从memstore中flush出来的数据。那么我们可以假设有这么一种情况,就是有个cell的value一开始1,然后这时候memstore满了,flush到storefile中。接着后面这个cell 的value改为2了,然后这时候memstore又满了,flush到storefile中。这时候这个cell在storefile中就有多个value了(这里说的并不是cell多version)。这样表面上看,memstore中的数据时修改操作,但是对于底层的storefile来说只是一次数据的增加操作,因为增加数据比修改数据效率要高。当然这也有缺点,就是同一个cell存储了多个版本的数据,占用存储空间,所以这是一种以空间换时间的策略。而当storefile增长到一定数量时,就会将多个storefile合并,这时候就会去除那些重复的数据(只保留最后一次的value,之前的全部删除),最终释放了一定量的存储空间,得出最新的数据。所以这合并的过程其实就是完成更新、修改以及删除的操作。
上面说到,memstore的数据是等到数据量达到阈值时,才会flush到storefile中,那如果还没等到flush的时候,regionserver突然宕机,那么内存的数据肯定会丢失的,那咋办?别急,有 hlog哦
每个HRegionServer中都只有一个HLog对象,所有region共用。HLog是一个实现Write Ahead Log的类,在有写操作的时候,会先将相应的操作记录到hlog,且hlog是实时同步到磁盘中的,所以不用担心宕机丢失hlog。等hlog返回记录完成后,才会写入到memstore中。这样就保证了内存的数据操作一定会记录到hlog中。HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。
hlog在regionserver故障时起到非常重要的恢复数据的作用。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
首先每个table至少是一个region,每个region中一个CF对应一个storefile。所以实际上不同的CF是分开存储的物理文件的。也就是在数据模型中,student表的物理存储结构实际上是这样的:
格式为:rowkey:cf:column:value:timestamp hfile for cf--info: 1:info:name:张三:1564393837300 1:info:sex:male:1564393837300 2:info:name:李四:1564393837302 2:info:sex:female:1564393837302 hfile for cf--password: 1:password:pwd:123:1564393837300 2:password:pwd:456:1564393837300
当我们需要查询一行数据时,遍历所有所属的region的所有hfile,然后找出同一rowkey的数据即可。hfile在hdfs中是直接使用二进制方式存储的,比较快。
接着就是hlog了,在底层是以Sequence File方式存储的
HBASE存在在两张特殊的table的,-ROOT-以及.META.,前者用于记录meta表的region信息,后者则记录用户表的region信息。目前来说,-ROOT-已经被移除了,因为有些多余,所以直接使用meta表即可。meta表时整个hbase集群的入口表,读写操作都得先访问meta表。
1)HRegionServer保存着.META.的这样一张表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面找到.META.表所在的位置信息,即找到这个.META.表在哪个HRegionServer上保存着。
2) 接着Client通过刚才获取到的HRegionServer的IP来访问.META.表所在的HRegionServer,从而读取到.META.,进而获取到.META.表中存放的元数据。
3) Client通过元数据中存储的信息,访问对应的HRegionServer,然后扫描(scan)所在
HRegionServer的Memstore和Storefile来查询数据。
4) 最后HRegionServer把查询到的数据响应给Client。
1)Client也是先访问zookeeper,找到.META.表所在的regionserver,并获取.META.表信息。
2) 确定当前将要写入的数据所对应的RegionServer服务器和Region。这个过程需要HMaster的参与,决定数据要往哪个region写
3) Client向该RegionServer服务器发起写入数据请求,然后RegionServer收到请求并响应。
4) Client先把数据写入到HLog,以防止数据丢失。
5) 然后将数据写入到Memstore。
6) 如果Hlog和Memstore均写入成功,则这条数据写入成功。在此过程中,如果Memstore达到阈值,会把Memstore中的数据flush到StoreFile中。
7) 当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile。当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为二。
| 软件 | 版本 | 主机(192.168.50.x/24) |
|---|---|---|
| zookeeper(已部署) | 3.4.10 | bigdata121(50.121),bigdata122(50.122),bigdata123(50.123) |
| hadoop(已部署) | 2.8.4 | bigdata121(50.121)namenode所在,bigdata122(50.122),bigdata123(50.123) |
| hbase | 1.3.1 | bigdata121(50.121)HMaster所在,bigdata122(50.122),bigdata123(50.123) |
在bigdata121上
解压 hbase-1.3.1-bin.tar.gz
tar zxf hbase-1.3.1-bin.tar.gz -c /opt/modules/
修改/opt/modules/hbase-1.3.1-bin/conf/hbase-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144 # 禁用hbase自带的zookeeper,使用额外安装的zookeeper export HBASE_MANAGES_ZK=false
修改/opt/modules/hbase-1.3.1-bin/conf/hbase-site.xml
<configuration> <!--指定hbase在hdfs中的存储目录 --> <property> <name>hbase.rootdir</name> <value>hdfs://bigdata121:9000/hbase</value> </property> <!--是否集群 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!--HMASTER的端口 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <!--zk集群的服务器信息 --> <property> <name>hbase.zookeeper.quorum</name> <value>bigdata121:2181,bigdata122:2181,bigdata123:2181</value> </property> <!--zk的数据目录 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/modules/zookeeper-3.4.10/zkData</value> </property> <!--HMaster的和regionserver之间最大的时间差,单位是秒 --> <property> <name>hbase.master.maxclockskew</name> <value>180000</value> </property> </configuration>
配置环境变量:
vim /etc/profile.d/hbase.sh
#!/bin/bash
export HBASE_HOME=/opt/modules/hbase-1.3.1
export PATH=$PATH:${HBASE_HOME}/bin
然后
source /etc/profile.d/hbase.sh配置完成后,将整个hbase目录scp到bigdata122和bigdata123的/opt/modules 目录下。
别忘记配置环境变量。
启动/关闭整个集群
start-hbase.sh stop-hbase.sh 提示: 如果集群中HMaster挂了,你会发现没法用stop-hbase.sh关闭集群了,这时候请手动关闭其他region server。
单独启动和关闭集群及节点:
hbase-daemon.sh start/stop master hbase-daemon.sh start/stop regionserver
并且启动成功后通过HMasterIP:16010 可以看到hbase 的web管理页面
hbase集群启动之后,会创建一个 /hbase 节点,该节点下创建多个维护hbase集群信息的子节点
[zk: localhost:2181(CONNECTED) 1] ls /hbase [replication, meta-region-server, rs, splitWAL, backup-masters, table-lock, flush-table-proc, region-in-transition, online-snapshot, switch, master, running, recovering-regions, draining, namespace, hbaseid, table] 其中: rs 这个节点下面有regionserver的信息,以"hostname,port,id"格式命名的 [zk: localhost:2181(CONNECTED) 6] ls /hbase/rs [bigdata122,16020,1564564185736, bigdata121,16020,1564564193102, bigdata123,16020,1564564178848] 这个节点下有哪些节点,就表示对应的regionserver是正常运行的,下线的regionserver对应的节点信息会被删除,因为是临时节点而已,具体临时节点有啥特性,请看zookeeper系列的文章。 meta-region-server 这个节点的value中保存了存储meta表的regionserver的信息 master 当前HMaster所在的主机信息 backup-masters 备master节点信息,如果没有配置的话,是空的 namespace 下面每个子节点对应一个命名空间,相当于RDBMS中库的概念 hbaseid value记录了hbase集群的唯一标志id table 下面每个子节点对应一张表
可以使用下面的命令启动新的节点
hbase-daemon.sh start regionserver
刚开始的时候,新的节点没有任何数据。如果此时平衡器(balance_switch)开启,HMaster会调度其他节点的region移动到这个新的节点上,也就说我们所说的数据平衡。
启动节点完成后,在hbase shell 中查看平衡器的状态
balancer_enabled 返回的就是平衡器当前的状态,默认是false关闭的
开启/关闭平衡器
balance_switch true/false
有小坑的地方:
有个 balance_switch status 命令,我看字面意思,以为是用来查询平衡器当前的状态的,后面被坑了之后,发现有点问题。经过反复试验,得出的结论是: 该命令执行之后,无论平衡器当前是什么状态,一律改为false,也就是关闭状态。 而且命令返回的结果是平衡器上一次的状态,注意是上一次,不是当前状态。 这个就是这个命令坑爹的地方了,什么鬼啊,谁tm设计的。 所以这个命令千万别乱执行,执行了这个命令,平衡器就直接给你关掉了。
当我们想将某个节点下线时,一般步骤如下:
先停止平衡器
balance_switch false
然后停止节点上的regionserver
hbase-daemon.sh stop regionserver
节点关闭之后,所有原先该节点上的region全部不能访问,处于维护状态。然后zk上/hbase/rs/下对应的临时节点会消失(zk临时节点的特性,不清楚的可以看我之前写的zk的文章)。然后master节点发现zk中的节点信息变化后,就会检测到该regionserver下线,自动开启平衡器,将下线的server上的region迁移到其他server上。
这种方式最大的弊端在于,首先server关闭后,上面的region都会停用。而且因为数据都保存在了hdfs+hlog中,导致后面迁移region的时候,需要从hdfs读取数据,并且重新执行hlog中的操作,才能恢复出完整的region来。读hdfs和执行hlog的操作是很慢的。这就导致这些region长时间没法访问。因为hbase后面提供另外一种方式来更加平滑的下线节点。
在hbase的bin目录下,执行
graceful_stop.sh <RegionServer-hostname> 该命令会先关闭平衡器,然后直接assign region,将所有region迁移完成后,才会关闭server。这就充分利用了内存中region数据了,减少从hdfs中的数据读取量,以及无需执行hlog中的操作,速度快了很多。所以region暂停访问的时间也缩短了
进入命令行:
hbase shell
查看命令帮助
hbase(main)> help
查看当前命名空间有哪些表(默认是default)
hbase(main)> list
查看有哪些命名空间,类似于RDBMS中库的概念
hbase(main)> list_namespace
查看指定namespace有哪些表
hbase(main)> list_namespace_tables ‘namespace_name’
创建namespace
hbase(main)>create_namespace 'namespace'
查看namespace信息:
hbase(main)> describe_namespace 'namespace'
创建表
Create ‘namespace:表名’,‘CF1','CF2','CFX',{para1=>value,para2=>value,} 不指定namespace,默认是default这个namespace
例子:
hbase(main)> create 'student','info' 创建student表,列簇有info
hbase(main)> create 'student','info',{VERSIONS=>3} 创建student表,列簇有info,且版本数为3
如果需要给不同的cf设置不同的参数属性,那么就需要下面的方式来创建表
create 'teacher_2',{NAME=>'info',VERSIONS=>3},{NAME=>'password',VERSIONS=>2}
创建表teacher_2,CF为info和password,版本个数为3和2插入数据(更新数据也是同样的命令,一样的操作)
Put ‘namespace:table’, ‘rowkey’, ‘cf:colume’, ‘value’, [timestamp] [timestamp]不指定的话默认为当前时间。一次只能插入一个cell的数据 例子: hbase(main) > put 'student','1001','info:name','Thomas'
查看表数据
scan ‘namespace:table’,{param1=>value}
例子:
扫描全表:scan 'student'
扫描指定字段:scan 'student',{COLUMNS=>['info:name','info:sex']}
限制返回的行数: scan 'student',{LIMIT=>1} 实际上返回的是 n+1行
返回指定rowkey范围的数据:scan 'student',{STARTROW => '1001', STOPROW => '1002'},可以单独使用STARTROW和STOPROW
返回指定时间戳范围的数据:scan 'student', {TIMERANGE => [1303668804, 1303668904]}查看表结构
desc 'namespace:table'
例子:
desc 'student'
打印的内容如下:
Table student is ENABLED
student
COLUMN FAMILIES DESCRIPTION {NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION =>
'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'
可以看到表的列簇信息查看指定行或者列的数据(scan也能实现)
get 'namespace:table','rowkey','cf:column',{para1=value....}
例子:
get 'student','1001','info:name'
get 'student','1001','info:name',{VERSIONS=>2} 查看前两个版本的数据
注意:这个命令只能用于查询单行的数据(同一rowkey的数据)删除数据
delete 'namespace:table','rowkey','cf:column' 用于删除指定字段的数据 deleteall 'namespace:table','rowkey' 用于删除同一rowkey的数据
禁用/启用/查看表状态
查看表是否启用:is_enabled 'namespace:table' 启用表:enable 'namespace:table' 禁用表:disable 'namespace:table' 禁用表之后,该表无法被读写
清空表数据
要先禁用表,然后再清空数据 truncate 'namespace:table'
删除表
确认表是启用的状态,禁用状态下不能删除表 drop 'namespace:table'
统计行数
count 'namespace:table'
变更表信息
alter 'namespace:table',{param1:value...}
例子:
alter 'student',{NAME='info',VERSIONS=>5} 修改列簇info的版本数为5
alter 'student',{NAME='info:name',METHOD='delete'} 删除字段info:name
alter 'student',{NAME=>'address_info'} 增加列簇address_info检查表是否存在
exist 'namespace:table'
查看当前hbase集群的节点状态
status 显示信息如下: 1 active master, 1 backup masters, 3 servers, 0 dead, 17.0000 average load 分别是:master、备master的状态,regionserver存活个数以及死亡个数、平均负载
新建maven 项目,pom.xml添加以下依赖
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.3.1</version> </dependency>
public class HbaseTest01 {
public static Configuration conf;
static{
//使用HBaseConfiguration的单例方法实例化,配置zk集群ip,端口,zk节点名
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "bigdata121");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("zookeeper.znode.parent", "/hbase");
}
public static boolean isTableExist(String tableName) throws IOException {
//根据conf创建连接对象
Connection connection = ConnectionFactory.createConnection(conf);
//通过连接获取admin管理员对象,用于管理表
HBaseAdmin admin = (HBaseAdmin)connection.getAdmin();
return admin.tableExists(tableName);
}
}public static void createTable(String tableName, String... columnFamily) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
HBaseAdmin admin = (HBaseAdmin)connection.getAdmin();
//创建表描述对象
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
for (String cf: columnFamily) {
//每个cf创建一个字段描述对象,添加到表描述对象中
hTableDescriptor.addFamily(new HColumnDescriptor(cf));
}
//创建表
admin.createTable(hTableDescriptor);
}
注意:如果创建表时没有指定namespace,默认就在default这个namespace,如果需要指定namespace,那么就需要将创建的表名命名为 "namespace:tableName" 的形式,中间用冒号分隔 public static void deleteTable(String tableName) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
HBaseAdmin admin = (HBaseAdmin)connection.getAdmin();
//禁用表
admin.disableTable(tableName);
//删除表
admin.deleteTable(tableName);
} public static void putData(String tableName, String rowKey, String columnFamily, String column, String value) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
//通过connection对象获取表管理对象
Table table = connection.getTable(TableName.valueOf(tableName));
//创建行对象
Put put = new Put(rowKey.getBytes());
//给行添加column,写入value
put.addColumn(columnFamily.getBytes(), column.getBytes(), value.getBytes());
//将行提交到表中实现更改
table.put(put);
table.close();
}
} public static void deleteData(String tableName, String... rowKey) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
//通过connection对象获取表管理对象
Table table = connection.getTable(TableName.valueOf(tableName));
//创建删除对象
ArrayList<Delete> deleteList = new ArrayList<>();
for (String row: rowKey) {
deleteList.add(new Delete(row.getBytes()));
}
//将行提交到表中实现删除
table.delete(deleteList);
table.close();
}public static void scanData(String tableName) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
//通过connection对象获取表管理对象
Table table = connection.getTable(TableName.valueOf(tableName));
//创建扫描器,可以设置startRow,stopRow读取指定key范围内的数据
Scan scan = new Scan();
//使用扫描器扫描表
ResultScanner scanner = table.getScanner(scan);
for (Result result: scanner) {
Cell[] cells = result.rawCells();
for (Cell cell:cells) {
//得到rowkey
System.out.println("行键:" + Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
table.close();
connection.close();
}
查询指定CF、指定“CF:COLUMN”,可以在扫描器中添加要扫描的列或者cf
scan.addColumn(family,column);
scan.addFamily(cf.getBytes())public static void getRow(String tableName, String rowKey) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
//通过connection对象获取表管理对象
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
Result result = table.get(get);
for (Cell cell:result.rawCells()) {
//得到rowkey
System.out.println("行键:" + Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println("时间戳:" + cell.getTimestamp());
}
table.close();
connection.close();
}public static void getRowCF(String tableName, String rowKey, String family, String column) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
//通过connection对象获取表管理对象
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
get.addColumn(family.getBytes(),column.getBytes());
Result result = table.get(get);
for (Cell cell:result.rawCells()) {
//得到rowkey
System.out.println("行键:" + Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println("时间戳:" + cell.getTimestamp());
}
table.close();
connection.close();
}public static void createNamespace(String namespace) throws IOException {
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
//创建namespace描述对象
NamespaceDescriptor province = NamespaceDescriptor.create(namespace).build();
//创建namespace
admin.createNamespace(province);
}查看hbase运行MapReduce任务所需的依赖
hbase mapredcp
添加依赖路径到环境变量
export HADOOP_CLASSPATH=`hbase mapredcp`
(1)统计表有多少行
cd /opt/modules/hbase-1.3.1/lib yarn jar hbase-server-1.3.1.jar rowcounter student 执行结果看到: org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper$Countes ROWS=3
(2)使用MapReduce将hdfs中的数据导入hbase
vim /tmp/fruit_input.txt 1001 apple red 1002 pear yellow 1003 orange orange 上传到hdfs中 hdfs dfs -mkdir /input_fruit hdfs dfs -put /tmp/fruit_input.txt /input_fruit/ hbase中创建目标表: hbase(main)> create 'fruit_input','info' yarn jar hbase-server-1.3.1.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit_input hdfs://bigdata121:900/input_fruit 解释:-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color 指定的是导入的字段的对应,用逗号分隔 查看数据: hbase(main):002:0> scan 'fruit_input' ROW COLUMN+CELL 1001 column=info:color, timestamp=1564710439420, value=red 1001 column=info:name, timestamp=1564710439420, value=apple 1002 column=info:color, timestamp=1564710439420, value=yellow 1002 column=info:name, timestamp=1564710439420, value=pear 1003 column=info:color, timestamp=1564710439420, value=orange 1003 column=info:name, timestamp=1564710439420, value=orange
需求:将fruit表的部分列簇的数据通过mr导入到fruit_mr表中。将info列簇中的name和color提取到fruit_mr表中
fruit表格内容如下:
ROW COLUMN+CELL 1001 column=account:sells, timestamp=1564393837300, value=20 1001 column=info:color, timestamp=1564393810196, value=red 1001 column=info:name, timestamp=1564393788068, value=apple 1001 column=info:price, timestamp=1564393864714, value=10 1002 column=account:sells, timestamp=1564393937058, value=100 1002 column=info:color, timestamp=1564393908332, value=orange 1002 column=info:name, timestamp=1564393897787, value=orange 1002 column=info:price, timestamp=1564393918141, value=8
提前创建输出表:
hbase(main):002:0> create 'fruit_mr','info'
mapper:
package HBaseMR;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* TableMapper<ImmutableBytesWritable, Put> 这里指定的是map的输出kv类型
* 因为输入是从hbase的表输入的,输入的KV类型是恒定的,所以无需指定
*
* 然后 hbase中的如果是以rowkey作为key的话,那么类型就是 ImmutableBytesWritable
*/
public class HBaseMrMapper extends TableMapper<ImmutableBytesWritable, Put> {
/**
* cell 存储hbase物理存储中一个行对应的value信息
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
Put put = new Put(key.get());
//筛选出列簇info中的列name和color,放到put对象中
for (Cell cell : value.rawCells()) {
if ("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) {
if ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell))) || "color".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
put.add(cell);
}
}
}
//如果put是非空的才写入到Context,否则最终写入到hbase时会报错“空值不能写入”
if (! put.isEmpty()) {
context.write(key, put);
}
}
}reducer:
package HBaseMR;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
/**
* 继承TableReducer<keyin,valuein,keyout>
这里不用指定reduce的输出value的类型,因为必须是Put类型
*/
public class HBaseMrReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
//将同一个key的写入Context
for (Put p : values) {
context.write(NullWritable.get(), p);
}
}
}runner:
package HBaseMR;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HBaseMrRunner extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//创建job对象
Configuration conf = this.getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(HBaseMrRunner.class);
//创建扫描器,用于扫描hbase表的数据
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setCaching(500);
//设置job参数,包括map和reduce
//设置map输入,类,输出的kv的类
TableMapReduceUtil.initTableMapperJob(
"fruit",
scan,
HBaseMrMapper.class,
ImmutableBytesWritable.class,
Put.class,
job
);
//设置reducer类,输出的表
TableMapReduceUtil.initTableReducerJob(
"fruit_mr",
HBaseMrReducer.class,
job
);
job.setNumReduceTasks(1);
//提交job
boolean isSuccess = job.waitForCompletion(true);
return isSuccess? 1:0;
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
//调用runner中的run方法
int status = ToolRunner.run(conf, new HBaseMrRunner(), args);
System.exit(status);
}
}使用maven打包,到集群上运行:
yarn jar hbasetest-1.0-SNAPSHOT.jar HBaseMR.HBaseMrRunner
将hdfs中的/input_fruit/fruit_input.txt的数据导入到hbase表fruit_hdfs_mr中
文本格式如下:
1001 apple red 1002 pear yellow 1003 orange orange 字段间使用 “\t” 分隔
先创建表:
create 'fruit_hdfs_mr','info'
mapper:
package HDFSToHBase;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ToHBaseMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
ImmutableBytesWritable keyOut = new ImmutableBytesWritable();
//Put value = new Put();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
keyOut.set(fields[0].getBytes());
Put put = new Put(fields[0].getBytes());
put.addColumn("info".getBytes(), "name".getBytes(), fields[1].getBytes());
put.addColumn("info".getBytes(), "color".getBytes(), fields[2].getBytes());
context.write(keyOut, put);
}
}reducer:
package HDFSToHBase;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
public class ToHBaseReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
for (Put p : values) {
context.write(NullWritable.get(), p);
}
}
}runner:
package HDFSToHBase;
import HBaseMR.HBaseMrRunner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ToHBaseRunner extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//创建job对象
Configuration conf = this.getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(ToHBaseRunner.class);
//设置数据输入路径
Path inPath = new Path("/input_fruit/fruit_input.txt");
FileInputFormat.addInputPath(job, inPath);
//设置map类,输出的KV类型
job.setMapperClass(ToHBaseMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
//设置reduce类,输出表
TableMapReduceUtil.initTableReducerJob(
"fruit_hdfs_mr",
ToHBaseReducer.class,
job
);
job.setNumReduceTasks(1);
boolean isSuccess = job.waitForCompletion(true);
return isSuccess?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
int status = ToolRunner.run(configuration, new ToHBaseRunner(), args);
System.exit(status);
}
}打包运行jar包:
yarn jar hbasetest-1.0-SNAPSHOT.jar HDFSToHBase.ToHBaseRunner
使用的hive版本为1.2,hive 的部署请看之前的hive相关的文章。
hive需要对hbase进行操作,需要需要经hbase的lib目录下的一些依赖jar复制一些到hive的lib目录下,并且hive需要访问zookeeper集群,以便访问hbase,所以zk相应的jar也需要复制。
hbase依赖: cp /opt/modules/hbase-1.3.1/lib/hbase-* /opt/modules/hive-1.2.1-bin/lib/ cp /opt/modules/hbase-1.3.1/lib/htrace-core-3.1.0-incubating.jar /opt/modules/hive-1.2.1-bin/lib/ zookeeper依赖: cp /opt/modules/hbase-1.3.1/lib/zookeeper-3.4.6.jar /opt/modules/hive-1.2.1-bin/lib/
接着修改hive 的配置文件 conf/hive-site.xml,增加以下配置项
<!-- 指定zk集群的地址以及端口--> <property> <name>hive.zookeeper.quorum</name> <value>bigdata121,bigdata122,bigdata123</value> <description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> <description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property>
create table student_hbase_hive(
id int,
name string,
sex string,
score double)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:name,info:sex,info:score")
TBLPROPERTIES("hbase.table.name"="hbase_hive_student");
语句解释:
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
存储的类用hbase的类
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:name,info:sex,info:score")
定义hive中表的字段和hbase的字段的映射关系,按先后顺序映射
TBLPROPERTIES("hbase.table.name"="hbase_hive_student");
在hbase中创建的表的参数,这里指定表名为 hbase_hive_student报错小插曲
创建过程中,出现以下报错:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org.apache.hadoop.hbase.HTableDescriptor.addFamily(Lorg/apache/hadoop/hbase/HColumnDescriptor;)V
不太详细,接着看看详细点的报错信息,将debug信息都打印出来,以下面方式启动hive
hive -hiveconf hive.root.logger=DEBUG,console
然后再次执行上面的创建语句,出现很多信息,我们往下翻,翻到一条关键性的信息:
ERROR exec.DDLTask: java.lang.NoSuchMethodError: org.apache.hadoop.hbase.HTableDescriptor.addFamily......
意思就是org.apache.hadoop.hbase.HTableDescriptor.addFamily里面没有HTableDescriptor.addFamily这个方法。
接着我用IDEAL下用maven下载对应版本的hbase依赖后,发现还真没有HTableDescriptor.addFamily 这个方法。问题很明显了,应该是hive使用的hbase的某些包和我们使用的hbase不兼容。而用来关联hbase和hive的一个重要包就是我们上面用的
org.apache.hadoop.hive.hbase.HbaseStorageHandler这个类对应的包,其实就是hive-hbase-handler-1.2.1.jar这个包,猜测是因为这个包版本太旧了,不兼容目前的hbase,所以我们到maven下载新的包 hive-hbase-handler-2.3.2.jar,就这个版本吧。然后替换掉hive的lib目录下原本的包,然后重启hive,接着执行上面的创建表的语句,发现正常执行,完美。
执行完创建语句后,进入hive和hbase发现都创建了新的表。随后,从hbase或者hive插入数据到这表中,在两边都可以查看到插入的数据。
在hive 中向关联表导入数据时,不能直接使用load命令导入,只能从其他表通过
insert into table TABLE_NAME select * from ANOTHER_TABLE
或者直接insert 一行一行插入数据也可以。这里就不多说了。
因为hbase提供的sql操作不怎么强大,所以有时候需要对数据进行sql统计,比较麻烦,所以可以通过将hbase 的已有数据的表关联到hive中,然后在hive中通过较为完善的HQL来进行统计分析。创建关联表的方式和上面的一样,这里不重复。
其实本质上数据是存储在hbase中的,hive只是可以通过接口操作hbase中的表中的数据。但是这里有一个坑的地方,就是在hive中字段是有类型的,比如int。然而在hbase中字段不存在类型,或者说全是string类型,然后直接通过二进制的方式存储。如果这时候直接在hbase中查询对应的数据,会发现显示的是乱码,因为hbase压根无法识别数据类型。这点有时候会有坑,要注意下。
sqoop的是之前hive部署的时候一起部署,所以sqoop的部署就看我之前写的hive相关的文档吧。
修改在sqoop配置文件 conf/sqoop-env.sh
export HBASE_HOME=/opt/modules/hbase-1.3.1
需求:将mysql中的表数据抽取到hbase中。
创建mysql表并导入数据:
CREATE DATABASE db_library;
CREATE TABLE db_library.book(
id int(4) PRIMARY KEY NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
price VARCHAR(255) NOT NULL);
INSERT INTO db_library.book (name, price) VALUES('Lie Sporting', '30');
INSERT INTO db_library.book (name, price) VALUES('Pride & Prejudice', '70');
INSERT INTO db_library.book (name, price) VALUES('Fall of Giants', '50');hbase中创建目标表
create 'hbase_book','info'
通过sqoop导入
sqoop import \ --connect jdbc:mysql://bigdata11:3306/db_library \ --username root \ --password 000000 \ --table book \ --columns "id,name,price" \ --column-family "info" \ 指定列簇 --hbase-create-table \ --hbase-row-key "id" \ 指定哪个字段映射为rowkey --hbase-table "hbase_book" \ 目标表名 --num-mappers 1 \ --split-by id
到此,关于“hbase的基本原理和使用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。