жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
вҖӢ з”ұFacebookејҖжәҗз”ЁдәҺи§ЈеҶіжө·йҮҸз»“жһ„еҢ–ж—Ҙеҝ—зҡ„ж•°жҚ®з»ҹи®ЎгҖӮжҳҜеҹәдәҺHadoopзҡ„дёҖдёӘж•°жҚ®д»“еә“е·Ҙе…·пјҢеҸҜд»Ҙе°Ҷз»“жһ„еҢ–зҡ„ж•°жҚ®ж–Ү件жҳ е°„дёәдёҖеј иЎЁпјҢ并жҸҗдҫӣзұ»SQLжҹҘиҜўеҠҹиғҪгҖӮжң¬иҙЁдёҠе…¶е®һе°ұжҳҜе°ҶHQL/SQLиҪ¬еҢ–дёәMapReduceжҲ–иҖ…sparkд»»еҠЎжү§иЎҢпјҢ然еҗҺиҝ”еӣһз»“жһңгҖӮжңүд»ҘдёӢеҮ дёӘжң¬иҙЁпјҡ
1пјүHiveеӨ„зҗҶзҡ„ж•°жҚ®еӯҳеӮЁеңЁHDFSгҖӮй»ҳи®ӨеңЁ
еңЁ/ user/hive/warehouse/<databaseName>.db/<tableName>/ дёӢеҲӣе»әеҜ№еә”ж–Ү件
2пјүHiveеҲҶжһҗж•°жҚ®еә•еұӮзҡ„е®һзҺ°жҳҜMapReduceжҲ–иҖ…sparkзӯүеҲҶеёғејҸи®Ўз®—еј•ж“Һ
3пјүжү§иЎҢзЁӢеәҸиҝҗиЎҢеңЁYarnдёҠ
жүҖд»Ҙз”ұжӯӨеҸҜд»Ҙеҫ—еҮәпјҡhiveжҳҜдҪҝз”ЁSQLзұ»дјјзҡ„иҜӯиЁҖжҺҘеҸЈиҖҢе·ІпјҢе…¶д»–зү№еҫҒе’Ңmysqlд№Ӣзұ»зҡ„ж•°жҚ®еә“е®Ңе…ЁжҳҜдёӨз ҒдәӢ
дјҳзӮ№пјҡ
1пјүж“ҚдҪңжҺҘеҸЈйҮҮз”Ёзұ»SQLиҜӯжі•пјҢжҸҗдҫӣеҝ«йҖҹејҖеҸ‘зҡ„иғҪеҠӣпјҲз®ҖеҚ•гҖҒе®№жҳ“дёҠжүӢпјү
2пјүйҒҝе…ҚдәҶеҺ»еҶҷMapReduceпјҢеҮҸе°‘ејҖеҸ‘дәәе‘ҳзҡ„еӯҰд№ жҲҗжң¬гҖӮ
3пјүHiveзҡ„жү§иЎҢ延иҝҹжҜ”иҫғй«ҳпјҢеӣ жӯӨHiveеёёз”ЁдәҺж•°жҚ®еҲҶжһҗпјҢеҜ№е®һж—¶жҖ§иҰҒжұӮдёҚй«ҳзҡ„еңәеҗҲпјӣ
4пјүHiveдјҳеҠҝеңЁдәҺеӨ„зҗҶеӨ§ж•°жҚ®пјҢеҜ№дәҺеӨ„зҗҶе°Ҹж•°жҚ®жІЎжңүдјҳеҠҝпјҢеӣ дёәHiveзҡ„жү§иЎҢ延иҝҹжҜ”иҫғй«ҳгҖӮ
5пјүHiveж”ҜжҢҒз”ЁжҲ·иҮӘе®ҡд№үеҮҪж•°пјҢз”ЁжҲ·еҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„йңҖжұӮжқҘе®һзҺ°иҮӘе·ұзҡ„еҮҪж•°гҖӮ
зјәзӮ№пјҡ
1пјүHiveзҡ„HQLиЎЁиҫҫиғҪеҠӣжңүйҷҗ
пјҲ1пјүиҝӯд»ЈејҸз®—жі•ж— жі•иЎЁиҫҫ
пјҲ2пјүж•°жҚ®жҢ–жҺҳж–№йқўдёҚж“…й•ҝ
2пјүHiveзҡ„ж•ҲзҺҮжҜ”иҫғдҪҺ
пјҲ1пјүHiveиҮӘеҠЁз”ҹжҲҗзҡ„MapReduceдҪңдёҡпјҢйҖҡеёёжғ…еҶөдёӢдёҚеӨҹжҷәиғҪеҢ–
пјҲ2пјүHiveи°ғдјҳжҜ”иҫғеӣ°йҡҫпјҢзІ’еәҰиҫғзІ—
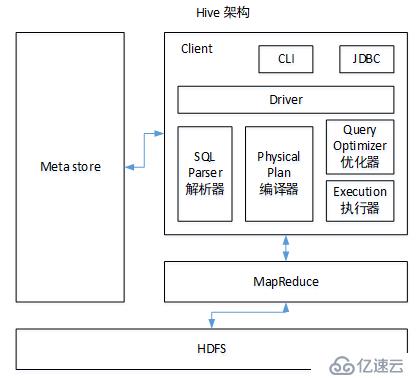
вҖӢ еӣҫ1.1 hiveжһ¶жһ„
вҖӢ еҰӮеӣҫдёӯжүҖзӨәпјҢHiveйҖҡиҝҮз»ҷз”ЁжҲ·жҸҗдҫӣзҡ„дёҖзі»еҲ—дәӨдә’жҺҘеҸЈпјҢжҺҘ收еҲ°з”ЁжҲ·зҡ„жҢҮд»Ө(SQL)пјҢдҪҝз”ЁиҮӘе·ұзҡ„DriverпјҢз»“еҗҲе…ғж•°жҚ®(MetaStore)пјҢе°ҶиҝҷдәӣжҢҮд»Өзҝ»иҜ‘жҲҗMapReduceпјҲжҲ–иҖ…sparkпјүпјҢжҸҗдәӨеҲ°Hadoopдёӯжү§иЎҢпјҢжңҖеҗҺпјҢе°Ҷжү§иЎҢиҝ”еӣһзҡ„з»“жһңиҫ“еҮәеҲ°з”ЁжҲ·дәӨдә’жҺҘеҸЈгҖӮ
1пјүз”ЁжҲ·жҺҘеҸЈпјҡClient
CLIпјҲhive shellпјүгҖҒJDBC/ODBC(javaи®ҝй—®hive)гҖҒWEBUIпјҲжөҸи§ҲеҷЁи®ҝй—®hiveпјү
2пјүе…ғж•°жҚ®пјҡMetastore
е…ғж•°жҚ®еҢ…жӢ¬пјҡиЎЁеҗҚгҖҒиЎЁжүҖеұһзҡ„ж•°жҚ®еә“пјҲй»ҳи®ӨжҳҜdefaultпјүгҖҒиЎЁзҡ„жӢҘжңүиҖ…гҖҒеҲ—/еҲҶеҢәеӯ—ж®өгҖҒиЎЁзҡ„зұ»еһӢпјҲжҳҜеҗҰжҳҜеӨ–йғЁиЎЁпјүгҖҒиЎЁзҡ„ж•°жҚ®жүҖеңЁзӣ®еҪ•зӯүпјӣ
й»ҳи®ӨеӯҳеӮЁеңЁиҮӘеёҰзҡ„derbyж•°жҚ®еә“дёӯпјҢдҪҶжҳҜжҖ§иғҪдёҚеҘҪпјҢжҺЁиҚҗдҪҝз”ЁMySQLеӯҳеӮЁMetastore
иЎЁдёӯзҡ„ж•°жҚ®жҳҜеӯҳеӮЁеңЁhdfsдёҠзҡ„пјҢеҸӘжңүиЎЁе…ғж•°жҚ®жүҚеӯҳеӮЁеңЁmysqlдёӯ
3пјүHadoop
дҪҝз”ЁHDFSиҝӣиЎҢеӯҳеӮЁпјҢдҪҝз”ЁMapReduceиҝӣиЎҢи®Ўз®—гҖӮ
4пјүй©ұеҠЁеҷЁпјҡDriver
пјҲ1пјүи§ЈжһҗеҷЁпјҲSQL Parserпјүпјҡе°ҶSQLеӯ—з¬ҰдёІиҪ¬жҚўжҲҗжҠҪиұЎиҜӯжі•ж ‘ASTпјҢиҝҷдёҖжӯҘдёҖиҲ¬йғҪ用第дёүж–№е·Ҙе…·еә“е®ҢжҲҗпјҢжҜ”еҰӮantlrпјӣеҜ№ASTиҝӣиЎҢиҜӯжі•еҲҶжһҗпјҢжҜ”еҰӮиЎЁжҳҜеҗҰеӯҳеңЁгҖҒеӯ—ж®өжҳҜеҗҰеӯҳеңЁгҖҒSQLиҜӯд№үжҳҜеҗҰжңүиҜҜгҖӮ
пјҲ2пјүзј–иҜ‘еҷЁпјҲPhysical Planпјүпјҡе°ҶASTзј–иҜ‘з”ҹжҲҗйҖ»иҫ‘жү§иЎҢи®ЎеҲ’гҖӮ
пјҲ3пјүдјҳеҢ–еҷЁпјҲQuery OptimizerпјүпјҡеҜ№йҖ»иҫ‘жү§иЎҢи®ЎеҲ’иҝӣиЎҢдјҳеҢ–гҖӮ
пјҲ4пјүжү§иЎҢеҷЁпјҲExecutionпјүпјҡжҠҠйҖ»иҫ‘жү§иЎҢи®ЎеҲ’иҪ¬жҚўжҲҗеҸҜд»ҘиҝҗиЎҢзҡ„зү©зҗҶи®ЎеҲ’гҖӮеҜ№дәҺHiveжқҘиҜҙпјҢе°ұжҳҜMR/SparkгҖӮ
| йЎ№зӣ® | дҝЎжҒҜ |
|---|---|
| дё»жңә | bigdata121(192.168.50.121) |
| hadoop | 2.8.4пјҲдјӘеҲҶеёғејҸжҗӯе»әпјҢдёҖдёӘdatanodeиҠӮзӮ№пјү |
| hive | 1.2.1 |
| mysql | 5.7 |
mysqlпјҢhadoopзҡ„йғЁзҪІдёҚйҮҚеӨҚиҜҙжҳҺпјҢзңӢд№ӢеүҚзҡ„ж–Үз« гҖӮ
и§ЈеҺӢзЁӢеәҸеҲ°/opt/modulesпјҢ并йҮҚе‘ҪеҗҚ
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/modules/
mv /opt/modules/apache-hive-1.2.1-bin /opt/modules/hive-1.2.1-binдҝ®ж”№зҺҜеўғй…ҚзҪ®ж–Ү件hive-env.sh
cd /opt/modules/hive-1.2.1-bin/conf
mv hive-env.sh.template hive-env.sh
ж·»еҠ еҰӮдёӢй…ҚзҪ®пјҡ
пјҲaпјүй…ҚзҪ®HADOOP_HOMEи·Ҝеҫ„,hadoop家зӣ®еҪ•
export HADOOP_HOME=/opt/modules/hadoop-2.8.4
пјҲbпјүй…ҚзҪ®HIVE_CONF_DIRи·Ҝеҫ„гҖӮhiveй…ҚзҪ®дҝЎжҒҜзҡ„зӣ®еҪ•
export HIVE_CONF_DIR=/opt/modules/hive-1.2.1-bin/confдҝ®ж”№ж—Ҙеҝ—иҫ“еҮәй…ҚзҪ® hive-log4j.properties
cd /opt/modules/hive-1.2.1-bin/conf
mv hive-log4j.properties.template hive-log4j.properties
дҝ®ж”№дёә hive.log.dir=/opt/module/hive-1.2.1-bin/logsй…ҚзҪ®hiveзҺҜеўғеҸҳйҮҸпјҡ
vim /etc/profile.d/hive.sh
ж·»еҠ д»ҘдёӢеҶ…е®№пјҡ
#!/bin/bash
export HIVE_HOME=/opt/modules/hive-1.2.1-bin
export PATH=$PATH:${HIVE_HOME}/bin
еҗҜз”ЁзҺҜеўғеҸҳйҮҸ
source /etc/profile.d/hive.shиҝҷж ·й…ҚзҪ®еҘҪеҗҺпјҢе°ұеҸҜд»ҘдҪҝз”Ё hive е‘Ҫд»ӨеҗҜеҠЁhiveдәҶгҖӮй»ҳи®Өе…ғж•°жҚ®еӯҳеӮЁеңЁиҮӘеёҰзҡ„detryж•°жҚ®еә“дёӯ
дҝ®ж”№й…ҚзҪ®ж–Ү件 conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore,jdbcиҝһжҺҘеӯ—з¬ҰдёІ,并жҢҮе®ҡеӯҳеӮЁе…ғж•°жҚ®зҡ„еә“еҗҚдёә metastore,еҗҚеӯ—еҸҜд»ҘиҮӘе®ҡд№ү</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore,иҝһжҺҘй©ұеҠЁзұ»</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database,mysqlз”ЁжҲ·</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wjt86912572</value>
<description>password to use against metastore databasem,mysqlеҜҶз Ғ</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>жҢҮе®ҡdefaultж•°жҚ®еә“зҡ„еңЁhdfsдёӯеӯҳеӮЁи·Ҝеҫ„</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>жҳҫзӨәиЎЁеӨҙ</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>жҳҫзӨәеҪ“еүҚжүҖеңЁж•°жҚ®еә“зҡ„еҗҚеӯ—</description>
</property>
</configuration>жҺҘзқҖиҮӘе·ұдёӢиҪҪ mysql-connector-java-5.1.27.jarпјҲзүҲжң¬еҸҜиҮӘиЎҢйҖүжӢ©пјүпјҢе°ұжҳҜдёҖдёӘjdbcзҡ„jarеҢ…иҖҢе·ІпјҢ然еҗҺж”ҫеҲ° /opt/modules/hive-1.2.1-bin/lib дёӢгҖӮ
жҺҘзқҖпјҢеҲқе§ӢеҢ–е…ғж•°жҚ®зҡ„ж•°жҚ®еә“еңЁmysqlдёӯзҡ„ж•°жҚ®пјҢ并иҝҒ移detryзҡ„ж•°жҚ®еҲ°mysqlдёӯ
schematool -dbType mysql -initSchema
иҝҷдёӘе‘Ҫд»ӨеңЁ /opt/modules/hive-1.2.1-bin/bin дёӢжңҖеҗҺеҮәзҺ°зұ»дјјдёӢйқўзҡ„еӯ—зңјпјҢиЎЁзӨәеҲқе§ӢеҢ–е®ҢжҲҗ
schemeTool completedеҰӮжһңеҮәзҺ°дёӢйқўзҡ„й—®йўҳпјҡ
Metastore connection URL: jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 1.2.0
Initialization script hive-schema-1.2.0.mysql.sql
Error: Duplicate entry '1' for key 'PRIMARY' (state=23000,code=1062)
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
*** schemaTool failed ***и§ЈеҶіж–№жі•пјҡ
еҲ°mysqlжүӢеҠЁеҲ йҷӨеҲҡжүҚеҲӣе»әзҡ„ж•°жҚ®еә“ drop database metastoreпјҢ然еҗҺеҶҚжү§иЎҢдёҖж¬ЎдёҠйқўзҡ„еҲқе§ӢеҢ–е‘Ҫд»ӨеҚіеҸҜеҲқе§ӢеҢ–е®ҢжҲҗеҗҺпјҢе°ұеҸҜд»ҘеҗҜеҠЁhiveдәҶгҖӮ
й»ҳи®ӨжҳҜеӯҳеӮЁеңЁ /user/hive/warehouse/дёӢпјҢжҜҸдёӘеә“жңүиҮӘе·ұзӢ¬з«Ӣзҡ„зӣ®еҪ•пјҢд»Ҙ databaseName.db е‘ҪеҗҚпјҢеә“зӣ®еҪ•дёӢеҲҷжҳҜ жҜҸдёӘиЎЁпјҢжҜҸдёӘиЎЁд»ҘиЎЁеҗҚе‘ҪеҗҚзӣ®еҪ•пјҢзӣ®еҪ•дёӢеӯҳеӮЁиЎЁж•°жҚ®гҖӮ
вҖӢ й»ҳи®Өжғ…еҶөдёӢпјҢhiveйғҪжҳҜзӣҙжҺҘж №жҚ®hive-site.xmlдёӯй…ҚзҪ®зҡ„е…ғж•°жҚ®еә“зҡ„иҝһжҺҘдҝЎжҒҜзӣҙжҺҘиҝһжҺҘmysqlзҡ„пјҢиҖҢдё”еҗҢж—¶еҸӘиғҪдёҖдёӘhiveе®ўжҲ·з«ҜиҝһжҺҘе…ғж•°жҚ®еә“пјҲжҖ•жңүдәӢеҠЎй—®йўҳпјүгҖӮиҖҢmetaserverжҳҜдёҖдёӘе…ғж•°жҚ®еә“serverпјҢе®ғзӣҙжҺҘиҝһжҺҘmysqlпјҢе…¶д»–hiveе®ўжҲ·з«ҜйҖҡиҝҮmetaserverжқҘй—ҙжҺҘиҝһжҺҘmysqlпјҢиҜ»еҸ–е…ғж•°жҚ®дҝЎжҒҜгҖӮжӯӨж—¶е…Ғи®ёеӨҡдёӘhiveе®ўжҲ·з«ҜиҝһжҺҘпјҢдё”дёҚйңҖиҰҒжҢҮе®ҡиҝһжҺҘMySQLзҡ„ең°еқҖгҖҒз”ЁжҲ·еҗҚеҜҶз ҒзӯүдҝЎжҒҜгҖӮеҪ“然дҪңдёәhive clientпјҢеҸҜд»ҘеңЁй…ҚзҪ®ж–Ү件дёӯжҢҮе®ҡиҝһжҺҘmysqlзҡ„з”ЁжҲ·дҝЎжҒҜпјҢдҪҶжҳҜдёҖиҲ¬йңҖиҰҒеҲӣе»әеӨҡдёӘmysqlз”ЁжҲ·пјҢз”ЁдәҺз»ҷдёҚеҗҢзҡ„hive clientиҝһжҺҘmysqlпјҢжҜ”иҫғз№ҒзҗҗгҖӮдёҖиҲ¬з”ЁеңЁе…¬еҸёеҶ…йғЁ
вҖӢ дёҖиҲ¬еңЁз”ҹдә§зҺҜеўғдёӯпјҢйғҪжҳҜеңЁдёҖеҸ°дё»жңәдёҠй…ҚзҪ®дәҶдёҖдёӘmetaServerпјҢ然еҗҺеңЁе…¶д»–еӨҡеҸ°дё»жңәдёҠй…ҚзҪ®hive clientгҖӮиҖҢmetaServerжүҖеңЁдё»жңәжқғйҷҗиҰҒжұӮй«ҳпјҢдёҚе…Ғи®ёе…¶д»–дәәд»»ж„Ҹи®ҝй—®пјҢиҖҢhive clientзҡ„дё»жңәеҲҷжҳҜеҸҜд»Ҙз»ҷдҪҺжқғйҷҗзҡ„дәәдҪҝз”ЁгҖӮдёҖе®ҡзЁӢеәҰдёҠдҝқжҠӨдәҶе…ғж•°жҚ®еә“mysqlзҡ„йҡҗз§ҳжҖ§гҖӮ
| дё»жңә | еҠҹиғҪ |
|---|---|
| bigdata121(192.168.50.121) | hive metastore,mysql |
| bigdata122(192.168.50.122) | hive client |
й…ҚзҪ®пјҡ
1>bigdata121:
vim conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore,jdbcиҝһжҺҘеӯ—з¬ҰдёІ,并жҢҮе®ҡеӯҳеӮЁе…ғж•°жҚ®зҡ„еә“еҗҚдёә metastore,еҗҚеӯ—еҸҜд»ҘиҮӘе®ҡд№ү</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore,иҝһжҺҘй©ұеҠЁзұ»</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database,mysqlз”ЁжҲ·</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wjt86912572</value>
<description>password to use against metastore databasem,mysqlеҜҶз Ғ</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>жҢҮе®ҡdefaultж•°жҚ®еә“зҡ„еңЁhdfsдёӯеӯҳеӮЁи·Ҝеҫ„</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>жҳҫзӨәиЎЁеӨҙ</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>жҳҫзӨәеҪ“еүҚжүҖеңЁж•°жҚ®еә“зҡ„еҗҚеӯ—</description>
</property>
<!-- жҢҮе®ҡzkйӣҶзҫӨзҡ„ең°еқҖд»ҘеҸҠз«ҜеҸЈ,з”ЁдәҺи®ҝй—®hbaseдёӯзҡ„hmaster-->
<property>
<name>hive.zookeeper.quorum</name>
<value>bigdata121,bigdata122,bigdata123</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<!--=========иҝҷйҮҢе°ұжҳҜmetastore server зҡ„й…ҚзҪ®-->
<!--жҢҮе®ҡmetastoreserverзҡ„жңҚеҠЎз«Ҝең°еқҖ-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata121:9083</value>
</property>
</configuration>й…ҚзҪ®е®ҢжҲҗеҗҺпјҢеҗҜеҠЁmetastore server:
hive --service metastore &
netstat -tnlp | grep 9083 зңӢеҜ№еә”з«ҜеҸЈиө·жқҘжІЎ2> bigdata122пјҡ
vim conf/hive-site.xml
</configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>жҢҮе®ҡdefaultж•°жҚ®еә“зҡ„еңЁhdfsдёӯеӯҳеӮЁи·Ҝеҫ„ </description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>жҳҫзӨәиЎЁеӨҙ</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>жҳҫзӨәеҪ“еүҚжүҖеңЁж•°жҚ®еә“зҡ„еҗҚеӯ—</description>
</property>
<!-- жҢҮе®ҡzkйӣҶзҫӨзҡ„ең°еқҖд»ҘеҸҠз«ҜеҸЈ,з”ЁдәҺи®ҝй—®hbaseдёӯзҡ„hmaster-->
<property>
<name>hive.zookeeper.quorum</name>
<value>bigdata121,bigdata122,bigdata123</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<!--жҢҮе®ҡmetastoreserverзҡ„иҝһжҺҘURLпјҢз”ЁдәҺhiveclientиҝһжҺҘе…ғж•°жҚ®еә“-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata121:9083</value>
</property>
</configuration>
hive clientзҡ„й…ҚзҪ®е°ұжҜ”иҫғз®ҖеҚ•дәҶпјҢдёҚйңҖиҰҒеҶҚй…ҚзҪ®mysqlзҡ„иҝһжҺҘдҝЎжҒҜдәҶпјҢзӣҙжҺҘй…ҚзҪ®hiveеңЁhdfsзҡ„ж•°жҚ®зӣ®еҪ•пјҢд»ҘеҸҠhive metastore serverзҡ„иҝһжҺҘең°еқҖе°ұеҸҜд»ҘдәҶй…ҚзҪ®е®ҢжҲҗеҗҺпјҢзӣҙжҺҘhiveеҗҜеҠЁclientе°ұеҸҜд»ҘиҝһжҺҘmetastoreпјҢ然еҗҺдҪҝз”ЁhiveдәҶгҖӮ
дёҚйңҖиҰҒеҗҜеҠЁhiveserverпјҢеӣ дёәжң¬иә«hiveе‘Ҫд»Өе°ұжҳҜдёҖдёӘhiveserver
вҖӢ й»ҳи®Өжғ…еҶөдёӢпјҢhiveеҸӘе…Ғи®ёhive clientиҝһжҺҘhiveпјҢеӣ дёәиҝҷз§Қжғ…еҶөhiveдёҚйңҖиҰҒеҗҜеҠЁserverжңҚеҠЎпјҢжҜҸдёӘhive clientжң¬иҙЁдёҠйғҪжҳҜеңЁиҮӘе·ұжң¬ең°еҗҜеҠЁдәҶдёҖдёӘhive serverпјҢ然еҗҺиҝһжҺҘmetastore serverпјҢиҜ»еҸ–hdfsзҡ„ж•°жҚ®зӣ®еҪ•пјҢиҝҷж ·е°ұеҸҜд»ҘдҪҝз”ЁhiveжңҚеҠЎдәҶгҖӮ
вҖӢ еҰӮжһңйңҖиҰҒйҖҡиҝҮjdbcиҝҷж ·зҡ„ж–№ејҸиҝһжҺҘhiveпјҢйӮЈд№Ҳе°ұйңҖиҰҒе°Ҷhiveд»ҘеҗҺеҸ°жңҚеҠЎзҡ„еҪўејҸеҗҜеҠЁдәҶпјҢйңҖиҰҒжҸҗдҫӣеҜ№еә”зҡ„ең°еқҖд»ҘеҸҠз«ҜеҸЈз»ҷjdbcиҝһжҺҘгҖӮиҰҒжіЁж„ҸпјҢиҝҷдёӘhiveserverе’ҢеүҚйқўзҡ„metastore serverжІЎжңүе•Ҙе…ізі»пјҢдёӨдёӘжҳҜзӢ¬з«Ӣзҡ„иҝӣзЁӢгҖӮиҖҢдё”hive serverеҗҜеҠЁд№ӢеҗҺпјҢеҶ…йғЁд№ҹдјҡжңүдёҖдёӘеҶ…зҪ®зҡ„metastore serverпјҢиҝҷдёӘжүҚжҳҜиҮӘе·ұз”Ёзҡ„пјҢеӨ–йғЁж— жі•дҪҝз”ЁгҖӮжүҖд»ҘиҝҷдёӨиҖ…жҳҜдёҚеҗҢдҪҝз”ЁеңәжҷҜдёӢзҡ„дә§зү©пјҢжіЁж„ҸеҢәеҲҶгҖӮ
еңЁbigdata121(192.168.50.121) дёҠй…ҚзҪ®hive server
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore,jdbcиҝһжҺҘеӯ—з¬ҰдёІ,并жҢҮе®ҡеӯҳеӮЁе…ғж•°жҚ®зҡ„еә“еҗҚдёә metastore,еҗҚеӯ—еҸҜд»ҘиҮӘе®ҡд№ү</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore,иҝһжҺҘй©ұеҠЁзұ»</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database,mysqlз”ЁжҲ·</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wjt86912572</value>
<description>password to use against metastore databasem,mysqlеҜҶз Ғ</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>жҢҮе®ҡdefaultж•°жҚ®еә“зҡ„еңЁhdfsдёӯеӯҳеӮЁи·Ҝеҫ„</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>жҳҫзӨәиЎЁеӨҙ</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>жҳҫзӨәеҪ“еүҚжүҖеңЁж•°жҚ®еә“зҡ„еҗҚеӯ—</description>
</property>
<!-- жҢҮе®ҡzkйӣҶзҫӨзҡ„ең°еқҖд»ҘеҸҠз«ҜеҸЈ,з”ЁдәҺи®ҝй—®hbaseдёӯзҡ„hmaster-->
<property>
<name>hive.zookeeper.quorum</name>
<value>bigdata121,bigdata122,bigdata123</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
// metastoreиҝҷйҮҢжІЎжңүз”ЁпјҢ
<!--жҢҮе®ҡmetastoreserverзҡ„жңҚеҠЎз«Ҝең°еқҖ-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata121:9083</value>
</property>
<!--жҢҮе®ҡhiveserverзҡ„жңҚеҠЎз«Ҝең°еқҖ,з«ҜеҸЈ-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bigdata121</value>
<!--жӣҙж”№дёәиҮӘе·ұзҡ„дё»жңәеҗҚеӯ—-->
</property>
<property>
<name>hive.server2.long.polling.timeout</name>
<value>5000</value>
</property>
</configuration>еҗҜеҠЁhiveserverпјҡ
hive --service hiveserver2 &
n | grep 10000 жҹҘзңӢз«ҜеҸЈиө·жқҘжІЎжҺҘзқҖеҶҚbigdata122дёҠжөӢиҜ•дёӢjdbcпјҢеңЁhiveзҡ„binдёӢжңүдёӘе‘Ҫд»Өпјҡ
bin/beeline
[root@bigdata122 hive-1.2.1-bin]# bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://bigdata121:10000 иҝҷйҮҢе°ұжҳҜжөӢиҜ•jdbcиҝһжҺҘhive serverдәҶ
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/modules/hbase-1.3.1/lib/phoenix-4.14.2-HBase-1.3-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/modules/hadoop-2.8.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Connecting to jdbc:hive2://bigdata121:10000
Enter username for jdbc:hive2://bigdata121:10000:
Enter password for jdbc:hive2://bigdata121:10000:
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://bigdata121:10000> иҝҷйҮҢжҳҫзӨәе·Із»ҸжҲҗеҠҹиҝһжҺҘ
0: jdbc:hive2://bigdata121:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| test |
+----------------+--+hive -options
зӣҙжҺҘиҫ“еҮә hive е‘Ҫд»ӨеҚіеҸҜиҝӣе…Ҙhiveж“ҚдҪңе‘Ҫд»ӨиЎҢ
еёёз”Ёoptionsпјҡ
--database databaseNameпјҡ жҢҮе®ҡиҝӣе…ҘжҹҗдёӘеә“
-e SQLпјҡдёҚиҝӣе…ҘhiveпјҢзӣҙжҺҘжү§иЎҢsqlе‘Ҫд»ӨпјҢз»“жһңеңЁе‘Ҫд»ӨиЎҢиҝ”еӣһ
-f xxx.sqlпјҡжү§иЎҢж–Ү件дёӯзҡ„sqlпјҢз»“жһңзӣҙжҺҘиҝ”еӣһиҝӣе…Ҙhiveд№ӢеҗҺеёёз”Ёзҡ„ж“ҚдҪңе‘Ҫд»Өпјҡ
exit/quitпјҡйҖҖеҮәhive
dfs xxx пјҡеңЁhiveдёӯеҜ№hdfsиҝӣиЎҢж“ҚдҪң
пјҒ shellCommandпјҡеңЁhiveдёӯзӣҙжҺҘжү§иЎҢshellе‘Ҫд»Ө
~/.hivehistoryпјҡиҝҷжҳҜи®°еҪ•hiveеҺҶеҸІе‘Ҫд»Өзҡ„ж–Ү件пјҲ1пјүеҸҜд»ҘеңЁ hive-site.xml дёӯй…ҚзҪ®еҸӮж•°
пјҲ2пјүеңЁеҗҜеҠЁhiveж—¶йҖҡиҝҮ -hiveconf param=valueпјҢеҸӮж•°еҸӘеҜ№жң¬ж¬ЎеҗҜеҠЁжңүж•Ҳ
пјҲ3пјүеңЁhiveдёӯйҖҡиҝҮ set param=value; й…ҚзҪ®пјҢеҸҜд»ҘйҖҡиҝҮ set paramжҹҘзңӢеҸӮж•°й…ҚзҪ®зҡ„value
дёҠиҝ°дёүз§Қи®ҫе®ҡж–№ејҸзҡ„дјҳе…Ҳзә§дҫқж¬ЎйҖ’еўһгҖӮеҚій…ҚзҪ®ж–Ү件<е‘Ҫд»ӨиЎҢеҸӮж•°<еҸӮж•°еЈ°жҳҺгҖӮжіЁж„Ҹжҹҗдәӣзі»з»ҹзә§зҡ„еҸӮж•°пјҢдҫӢеҰӮlog4jзӣёе…ізҡ„и®ҫе®ҡпјҢеҝ…йЎ»з”ЁеүҚдёӨз§Қж–№ејҸи®ҫе®ҡпјҢеӣ дёәйӮЈдәӣеҸӮж•°зҡ„иҜ»еҸ–еңЁдјҡиҜқе»әз«Ӣд»ҘеүҚе·Із»Ҹе®ҢжҲҗдәҶгҖӮ| hiveж•°жҚ®зұ»еһӢ | javaж•°жҚ®зұ»еһӢ | й•ҝеәҰ | дҫӢеӯҗ |
|---|---|---|---|
| BOOLEAN | boolean | еёғе°”зұ»еһӢпјҢtrueжҲ–иҖ…false | TRUE FALSE |
| TINYINT | byte | 1byteжңүз¬ҰеҸ·ж•ҙж•° | 20 |
| SMALINT | short | 2byteжңүз¬ҰеҸ·ж•ҙж•° | 20 |
| INT | int | 4byteжңүз¬ҰеҸ·ж•ҙж•° | 20 |
| BIGINT | long | 8byteжңүз¬ҰеҸ·ж•ҙж•° | 20 |
| FLOAT | float | еҚ•зІҫеәҰжө®зӮ№ж•° | 3.14159 |
| DOUBLE | double | еҸҢзІҫеәҰжө®зӮ№ж•° | 3.14159 |
| STRING | string | еӯ—з¬Ұзі»еҲ—гҖӮеҸҜд»ҘжҢҮе®ҡеӯ—з¬ҰйӣҶгҖӮеҸҜд»ҘдҪҝз”ЁеҚ•еј•еҸ·жҲ–иҖ…еҸҢеј•еҸ·гҖӮ | вҖҳnow is the timeвҖҷ вҖңfor all good menвҖқ |
| TIMESTAMP | ж—¶й—ҙзұ»еһӢ | ||
| BINARY | еӯ—иҠӮж•°з»„ |
| ж•°жҚ®зұ»еһӢ | жҸҸиҝ° | иҜӯжі•е®һдҫӢ |
|---|---|---|
| STRUCT | е’ҢcиҜӯиЁҖдёӯзҡ„structзұ»дјјпјҢйғҪеҸҜд»ҘйҖҡиҝҮвҖңзӮ№вҖқз¬ҰеҸ·и®ҝй—®е…ғзҙ еҶ…е®№гҖӮдҫӢеҰӮпјҢеҰӮжһңжҹҗдёӘеҲ—зҡ„ж•°жҚ®зұ»еһӢжҳҜSTRUCT{first STRING, last<br/>STRING},йӮЈд№Ҳ第1дёӘе…ғзҙ еҸҜд»ҘйҖҡиҝҮеӯ—ж®ө.firstжқҘеј•з”ЁгҖӮ | struct() |
| MAP | MAPжҳҜдёҖз»„й”®-еҖјеҜ№е…ғз»„йӣҶеҗҲпјҢдҪҝз”Ёж•°з»„иЎЁзӨәжі•еҸҜд»Ҙи®ҝй—®ж•°жҚ®гҖӮдҫӢеҰӮпјҢеҰӮжһңжҹҗдёӘеҲ—зҡ„ж•°жҚ®зұ»еһӢжҳҜMAPпјҢе…¶дёӯй”®->еҖјеҜ№жҳҜвҖҷfirstвҖҷ->вҖҷJohnвҖҷе’ҢвҖҷlastвҖҷ->вҖҷDoeвҖҷпјҢйӮЈд№ҲеҸҜд»ҘйҖҡиҝҮеӯ—ж®өеҗҚ[вҖҳlastвҖҷ]иҺ·еҸ–жңҖеҗҺдёҖдёӘе…ғзҙ | map() |
| ARRAY | ж•°з»„жҳҜдёҖз»„е…·жңүзӣёеҗҢзұ»еһӢе’ҢеҗҚз§°зҡ„еҸҳйҮҸзҡ„йӣҶеҗҲгҖӮиҝҷдәӣеҸҳйҮҸз§°дёәж•°з»„зҡ„е…ғзҙ пјҢжҜҸдёӘж•°з»„е…ғзҙ йғҪжңүдёҖдёӘзј–еҸ·пјҢзј–еҸ·д»Һйӣ¶ејҖе§ӢгҖӮдҫӢеҰӮпјҢж•°з»„еҖјдёә[вҖҳJohnвҖҷ, вҖҳDoeвҖҷ]пјҢйӮЈд№Ҳ第2дёӘе…ғзҙ еҸҜд»ҘйҖҡиҝҮж•°з»„еҗҚ[1]иҝӣиЎҢеј•з”ЁгҖӮ | Array() |
е…¶дёӯmapе’ҢstructжңүзӮ№зӣёдјјпјҢдҪҶе…¶е®һstructдёӯдёҚеӯҳеңЁkeyзҡ„жҰӮеҝөпјҢдҪҶжҳҜзұ»дјјkeyпјҢе°ұзӣёеҪ“дәҺstructеҶ…йғЁжң¬иә«е°ұе®ҡд№үдәҶдёҖдёӘдёӘзҡ„еұһжҖ§зҡ„еҗҚз§°пјҢжҲ‘们填充зҡ„еҸӘжҳҜиҝҷдәӣе·ІжңүеұһжҖ§еҜ№еә”зҡ„valueиҖҢе·ІгҖӮжүҖд»ҘkeyеҜ№дәҺstructжқҘиҜҙжҳҜе·ІеӯҳеңЁзҡ„гҖӮиҖҢmapе°ұеҫҲеҘҪзҗҶи§ЈдәҶпјҢkeyе’ҢvalueйғҪжҳҜд»»ж„Ҹзҡ„пјҢйғҪжҳҜпјҢдёӨдёӘйғҪжҳҜж•°жҚ®пјҢеЎ«е……ж•°жҚ®ж—¶йңҖиҰҒеҗҢж—¶иҫ“е…Ҙkeyе’ҢvalueгҖӮ
дҪҝз”ЁдҫӢеӯҗпјҡ
еҒҮи®ҫжҹҗиЎЁжңүдёҖиЎҢж•°жҚ®еҰӮдёӢпјҲиҪ¬еҢ–дёәjsonж јејҸжҳҫзӨәпјүпјҡ
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //еҲ—иЎЁArray,
"children": { //й”®еҖјMap,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //з»“жһ„Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}еҺҹе§Ӣж•°жҚ®еҰӮдёӢпјҡ
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
дёҚеҗҢеӯ—ж®өзҡ„ж•°жҚ®з”ЁвҖңпјҢвҖқеҲҶйҡ”пјҢеҗҢдёҖеӯ—ж®өеҶ…зҡ„еӨҡдёӘеҖјз”ЁвҖң_вҖқеҲҶйҡ”пјҢKVд№Ӣй—ҙз”ЁвҖң:вҖқеҲҶйҡ”еҲӣе»әжөӢиҜ•иЎЁпјҲеҗҺйқўдјҡи®Із”Ёжі•пјҢе…ҲзңӢзңӢпјүпјҡ
create table test(
name string,
friends array<string>,
children map<string, int>, mapе°ұжҳҜе®ҡд№үKVзҡ„зұ»еһӢеҚіеҸҜ
address struct<street:string, city:string> з»“жһ„дҪ“жҳҜеңЁе®ҡд№үж—¶е°ұжҢҮе®ҡжңүе“ӘдәӣkeyпјҢ然еҗҺеЎ«е……value
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
еӯ—ж®өи§ЈйҮҠпјҡ
row format delimited fields terminated by ',' -- еҲ—еҲҶйҡ”з¬Ұ
collection items terminated by '_' --MAP STRUCT е’Ң ARRAY зҡ„еҲҶйҡ”з¬Ұ(ж•°жҚ®еҲҶеүІз¬ҰеҸ·)
map keys terminated by ':' -- MAPдёӯзҡ„keyдёҺvalueзҡ„еҲҶйҡ”з¬Ұ
lines terminated by '\n'; -- иЎҢеҲҶйҡ”з¬ҰеҜје…Ҙж•°жҚ®пјҡ
hive (default)> load data local inpath '/opt/module/datas/test.txt' into table test;жҹҘиҜўж•°жҚ®пјҡ
hive (default)> select friends[1],children['xiao song'],address.city from test where name="songsong";
OK
_c0 _c1 city
lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)Hiveзҡ„еҺҹеӯҗж•°жҚ®зұ»еһӢжҳҜеҸҜд»ҘиҝӣиЎҢйҡҗејҸиҪ¬жҚўзҡ„пјҢзұ»дјјдәҺJavaзҡ„зұ»еһӢиҪ¬жҚўпјҢдҫӢеҰӮжҹҗиЎЁиҫҫејҸдҪҝз”ЁINTзұ»еһӢпјҢTINYINTдјҡиҮӘеҠЁиҪ¬жҚўдёәINTзұ»еһӢпјҢдҪҶжҳҜHiveдёҚдјҡиҝӣиЎҢеҸҚеҗ‘иҪ¬еҢ–пјҢдҫӢеҰӮпјҢжҹҗиЎЁиҫҫејҸдҪҝз”ЁTINYINTзұ»еһӢпјҢINTдёҚдјҡиҮӘеҠЁиҪ¬жҚўдёәTINYINTзұ»еһӢпјҢе®ғдјҡиҝ”еӣһй”ҷиҜҜпјҢйҷӨйқһдҪҝз”ЁCASTж“ҚдҪңгҖӮ
1пјүйҡҗејҸзұ»еһӢиҪ¬жҚўи§„еҲҷеҰӮдёӢгҖӮ
пјҲ1пјүд»»дҪ•ж•ҙж•°зұ»еһӢйғҪеҸҜд»ҘйҡҗејҸең°иҪ¬жҚўдёәдёҖдёӘиҢғеӣҙжӣҙе№ҝзҡ„зұ»еһӢпјҢеҰӮTINYINTеҸҜд»ҘиҪ¬жҚўжҲҗINTпјҢINTеҸҜд»ҘиҪ¬жҚўжҲҗBIGINTгҖӮ
пјҲ2пјүжүҖжңүж•ҙж•°зұ»еһӢгҖҒFLOATе’ҢSTRINGзұ»еһӢйғҪеҸҜд»ҘйҡҗејҸең°иҪ¬жҚўжҲҗDOUBLEгҖӮ
пјҲ3пјүTINYINTгҖҒSMALLINTгҖҒINTйғҪеҸҜд»ҘиҪ¬жҚўдёәFLOATгҖӮ
пјҲ4пјүBOOLEANзұ»еһӢдёҚеҸҜд»ҘиҪ¬жҚўдёәд»»дҪ•е…¶е®ғзҡ„зұ»еһӢгҖӮ
2пјүеҸҜд»ҘдҪҝз”ЁCASTж“ҚдҪңжҳҫзӨәиҝӣиЎҢж•°жҚ®зұ»еһӢиҪ¬жҚўпјҢдҫӢеҰӮCAST('1' AS INT)е°ҶжҠҠеӯ—з¬ҰдёІ'1' иҪ¬жҚўжҲҗж•ҙж•°1пјӣеҰӮжһңејәеҲ¶зұ»еһӢиҪ¬жҚўеӨұиҙҘпјҢеҰӮжү§иЎҢCAST('X' AS INT)пјҢиЎЁиҫҫејҸиҝ”еӣһз©әеҖј NULLгҖӮ
дёӢйқўејҖе§Ӣи®ІHQLзҡ„дҪҝз”Ё
create database [if not exists] DBNAME [location PATH];
if not existsпјҡеә“еӯҳеңЁе°ұдёҚеҲӣе»әпјҢдёҚеӯҳеңЁе°ұеҲӣе»ә
location PATHпјҡжҢҮе®ҡеә“еңЁhdfsдёӯзҡ„еӯҳеӮЁи·Ҝеҫ„ з”ЁжҲ·еҸҜд»ҘдҪҝз”ЁALTER DATABASEе‘Ҫд»ӨдёәжҹҗдёӘж•°жҚ®еә“зҡ„DBPROPERTIESи®ҫзҪ®й”®-еҖјеҜ№еұһжҖ§еҖјпјҢжқҘжҸҸиҝ°иҝҷдёӘж•°жҚ®еә“зҡ„еұһжҖ§дҝЎжҒҜгҖӮж•°жҚ®еә“зҡ„е…¶д»–е…ғж•°жҚ®дҝЎжҒҜйғҪжҳҜдёҚеҸҜжӣҙж”№зҡ„пјҢеҢ…жӢ¬ж•°жҚ®еә“еҗҚе’Ңж•°жҚ®еә“жүҖеңЁзҡ„зӣ®еҪ•дҪҚзҪ®гҖӮ\
alter database DBNAME set dbproperties('param'='value');
еҰӮпјҡдҝ®ж”№еҲӣе»әж—¶й—ҙ
alter database db_hive set dbproperties('createtime'='20180830');жҹҘзңӢж•°жҚ®еә“еҹәжң¬дҝЎжҒҜпјҡshow databases
жҹҘзңӢиҜҰз»ҶдҝЎжҒҜпјҡdesc database DBNAME
жҹҘзңӢж•°жҚ®еә“жӣҙиҜҰз»Ҷзҡ„дҝЎжҒҜпјҡdesc database extended DBNAMEdrop database [if exists] DBNAME [cascade]
if exists:жңҖеҘҪз”ЁеҲӨж–ӯеә“жҳҜеҗҰеӯҳеңЁпјҢдёҚ然容жҳ“жҠҘй”ҷгҖӮ
cascadeпјҡејәеҲ¶еҲ йҷӨйқһз©әзҡ„еә“пјҢй»ҳи®ӨеҸӘиғҪеҲ йҷӨз©әзҡ„еә“CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[LIKE DBNAME]
еӯ—ж®өи§ЈйҮҠпјҡ
пјҲ1пјүEXTERNALпјҡеҲӣе»әдёҖдёӘеӨ–йғЁиЎЁпјҢй»ҳи®ӨеҲӣе»әзҡ„жҳҜеҶ…йғЁиЎЁгҖӮеҗҺйқўжңүи®ІдёӨиҖ…зҡ„еҢәеҲ«
пјҲ2пјүCOMMENTпјҡдёәиЎЁе’ҢеҲ—ж·»еҠ жіЁйҮҠпјҢеҗҺйқўжңүиҜҙ
пјҲ3пјүPARTITIONED BYеҲӣе»әеҲҶеҢәиЎЁпјҢеҗҺйқўжңүиҜҙ
пјҲ4пјүCLUSTERED BYеҲӣе»әеҲҶжЎ¶иЎЁпјҢеҗҺйқўжңүиҜҙ
пјҲ5пјүSORTED BYдёҚеёёз”ЁпјҡmrеҶ…йғЁжҺ’еәҸпјҢеҗҺйқўжңүиҜҙ
пјҲ6пјүROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATE D BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
иҝҷдәӣе®ҡд№үзҡ„иҫ“еҮәж•°жҚ®зҡ„ж јејҸпјҢеҲҶеҲ«дҫқж¬ЎжҳҜ еӯ—ж®өеҲҶйҡ”з¬ҰгҖҒеҖјеҲҶйҡ”з¬ҰгҖҒKVеҲҶйҡ”з¬ҰгҖҒиЎҢеҲҶйҡ”з¬Ұ
пјҲ7пјүSTORED ASжҢҮе®ҡеӯҳеӮЁж–Ү件зұ»еһӢ
еӨ§дҪ“дёҠеҲҶдёәиЎҢеӯҳеӮЁе’ҢеҲ—ејҸеӯҳеӮЁпјҢеҗҺйқўжңүи®ІпјҢй»ҳи®ӨжҳҜtextfileпјҢеҚіиЎҢеӯҳеӮЁж–Үжң¬ж јејҸ
пјҲ8пјүLOCATION пјҡжҢҮе®ҡиЎЁеңЁHDFSдёҠзҡ„еӯҳеӮЁдҪҚзҪ®гҖӮжҢҮе®ҡж•°жҚ®еҠ иҪҪи·Ҝеҫ„пјҢе°Ҷж–Ү件ж”ҫеҲ°иҜҘи·Ҝеҫ„дёӢпјҢж— йңҖloadеҚіеҸҜиҮӘеҠЁеҠ иҪҪж•°жҚ®гҖӮеҰӮжһңжҳҜиҮӘе·ұзӢ¬з«ӢеҲӣе»әеҲҶеҢәзӣ®еҪ•пјҢеҲҷйңҖиҰҒжүӢеҠЁload
пјҲ9пјүLIKEпјҡе…Ғи®ёз”ЁжҲ·еӨҚеҲ¶зҺ°жңүзҡ„иЎЁз»“жһ„пјҢдҪҶжҳҜдёҚеӨҚеҲ¶ж•°жҚ®
дҫӢеӯҗпјҡ
create table if not exists student2(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student2';жҹҘзңӢиЎЁеҹәжң¬дҝЎжҒҜпјҡdesc TABLENAME
жҹҘзңӢиҜҰз»ҶдҝЎжҒҜпјҡdesc formatted TABLENAMEеҶ…йғЁиЎЁе’ҢеӨ–йғЁиЎЁзҡ„еҢәеҲ«пјҡ
еӨ–йғЁиЎЁпјҡеңЁдҪҝз”ЁdropеҲ йҷӨеӨ–йғЁиЎЁж—¶пјҢеҸӘдјҡеҲ йҷӨиЎЁз»“жһ„пјҢдёҚдјҡеҲ йҷӨж•°жҚ®
еҶ…йғЁиЎЁпјҡд№ҹз§°дёәз®ЎзҗҶиЎЁпјҢеңЁдҪҝз”ЁdropеҲ йҷӨеӨ–йғЁиЎЁж—¶пјҢиЎЁз»“жһ„е’Ңж•°жҚ®йғҪдјҡеҲ йҷӨ
дёҖиҲ¬жқҘиҜҙпјҢеӨ–йғЁиЎЁз”ЁжқҘеӯҳеӮЁеҺҹе§Ӣ收йӣҶиҝҮжқҘзҡ„ж•°жҚ®пјҢдёҚе…Ғи®ёиҪ»жҳ“еҲ йҷӨпјҢжүҖд»ҘдҪҝз”ЁеӨ–йғЁиЎЁжқҘдҝқеӯҳеҫҲйҖӮеҗҲгҖӮеҗҺйқўеҹәдәҺеӨ–йғЁиЎЁж•°жҚ®еҲҶжһҗпјҢйңҖиҰҒеӯҳеӮЁдёҖдәӣдёӯй—ҙз»“жһңиЎЁж—¶пјҢиҝҷж—¶еҖҷз”ЁеҶ…йғЁиЎЁеҫҲйҖӮеҗҲпјҢеҸҜд»ҘйҡҸж—¶еҲ йҷӨиЎЁз»“жһ„е’Ңж•°жҚ®гҖӮжҹҘзңӢиЎЁзҡ„зұ»еһӢ
desc formatted TABLEName;
.....
Table Type: EXTERNAL_TABLE(еӨ–йғЁиЎЁ)/ MANAGED_TABLE(еҶ…йғЁиЎЁ)
.....еҲҶеҢәиЎЁе…¶е®һе°ұе°ҶдёҖдёӘиЎЁзҡ„ж•°жҚ®еҲ’еҲҶдёәеҮ дёӘеҲҶеҢәпјҢжҜҸдёӘеҲҶеҢәеңЁиЎЁзҡ„еӯҳеӮЁзӣ®еҪ•дёӢзӢ¬з«ӢеҲӣе»әдёҖдёӘеҲҶеҢәзӣ®еҪ•пјҢзӣ®еҪ•е‘ҪеҗҚдёәпјҡвҖңеҲҶеҢәkey=valueвҖқзҡ„еҪўејҸпјҢеҰӮпјҡвҖңmonth=201902вҖқпјҢзӣ®еҪ•дёӢеӯҳеӮЁиҜҘж–Ү件зҡ„ж•°жҚ®ж–Ү件гҖӮ并且жҹҘиҜўж—¶еҸҜйҖҡиҝҮwhereиҜӯеҸҘжқҘжҹҘиҜўжҢҮе®ҡеҲҶеҢәзҡ„ж•°жҚ®гҖӮдёҖе®ҡзЁӢеәҰдёҠеҮҸе°‘дәҶдёҖж¬ЎжҖ§иҜ»еҸ–ж•°жҚ®зҡ„еҺӢеҠӣгҖӮжҜ”еҰӮжҢүеӨ©еҲҶеҢәпјҢжҜҸеӨ©зҡ„ж•°жҚ®еҚ•зӢ¬еӯҳеӮЁгҖӮд№ҹдҫҝдәҺз®ЎзҗҶгҖӮ
пјҲ1пјүеҲӣе»әеҲҶеҢәиЎЁ
create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';
е…¶дёӯpartitioned by (month string) е°ұжҳҜе®ҡд№үеҲҶеҢәзҡ„еӯ—ж®өеҗҚз§°д»ҘеҸҠзұ»еһӢгҖӮжіЁж„ҸиҝҷдёӘеӯ—ж®ө并дёҚжҳҜж•°жҚ®жң¬иә«зҡ„еӯ—ж®өпјҢиҖҢжҳҜдәәдёәе®ҡд№үзҡ„гҖӮиҖҢдё”дҪҝз”ЁselectжҹҘзңӢиЎЁж•°жҚ®ж—¶пјҢдјҡжҳҫзӨәиҜҘеӯ—ж®өгҖӮпјҲ2пјүеҠ иҪҪж•°жҚ®еҲ°жҢҮе®ҡеҲҶеҢә
load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201809');
еҝ…йЎ»д»Ҙmonth=valueзҡ„еҪўејҸжҢҮе®ҡ,еҗҰеҲҷжҠҘй”ҷ,дјҡеңЁиЎЁзӣ®еҪ•дёӢеҲӣе»әзӣ®еҪ•еҗҚдёә month=201809 пјҢ然еҗҺе°Ҷж•°жҚ®ж–Ү件дҝқеӯҳеҲ°иҜҘзӣ®еҪ•дёӢ
load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201807');
еҰӮжһңеҲҶеҢәе·ІеӯҳеңЁпјҢеҲҷдјҡе°Ҷж–°зҡ„ж•°жҚ®ж–Ү件ж”ҫеҲ°еҗҢдёҖеҲҶеҢәзӣ®еҪ•дёӢ пјҲ3пјүжҹҘзңӢеҲҶеҢәиЎЁж•°жҚ®
select * from dept_partition where month='201809';
_u3.deptno _u3.dname _u3.loc _u3.month
10 ACCOUNTING NEW YORK 201809
еҸҜд»ҘзңӢеҲ°monthжҳҜдҪңдёәеӯ—ж®өжҳҫзӨәеҮәжқҘзҡ„пјҲ4пјүеўһеҠ еҲҶеҢә
еҲӣе»әеҚ•дёӘеҲҶеҢә:
hive (default)> alter table dept_partition add partition(month='201806') ;
еҗҢж—¶еҲӣе»әеӨҡдёӘеҲҶеҢә:
hive (default)> alter table dept_partition add partition(month='201805') partition(month='201804');
еӨҡдёӘеҲҶеҢәд№Ӣй—ҙз”Ёз©әж јеҲҶйҡ”ејҖпјҲ5пјүеҲ йҷӨеҲҶеҢә
еҲ йҷӨеҚ•дёӘеҲҶеҢәпјҡ
hive (default)> alter table dept_partition drop partition (month='201804');
еҗҢж—¶еҲ йҷӨеӨҡдёӘеҲҶеҢәпјҡ
hive (default)> alter table dept_partition drop partition (month='201805'), partition (month='201806');
еӨҡдёӘеҲҶеҢәд№Ӣй—ҙз”ЁйҖ—еҸ·еҲҶйҡ”ејҖпјҲ6пјүжҹҘзңӢеҲҶеҢәиЎЁжңүеӨҡе°‘еҲҶеҢә
hive>show partitions dept_partition;пјҲ7пјүжҹҘзңӢеҲҶеҢәиЎЁз»“жһ„
hive>desc formatted dept_partition;
desc dept_partition жҹҘзңӢз®ҖеҚ•зҡ„дҝЎжҒҜ
.......
# Partition Information
# col_name data_type comment
month string
........пјҲ8пјүдәҢзә§еҲҶеҢәиЎЁ
еҲӣе»әдәҢзә§еҲҶеҢәиЎЁпјҡ
create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';
е…¶е®һе°ұжҳҜе®ҡд№үдәҶдёӨдёӘеҲҶеҢәеӯ—ж®ө
еҠ иҪҪж•°жҚ®еҲ°дәҢзә§еҲҶеҢәпјҡ
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition2 partition(month='201809', day='13');
жҹҘзңӢж•°жҚ®пјҡ
hive (default)> select * from dept_partition2 where month='201809' and day='13';пјҲ9пјүеҲҶеҢәиЎЁзҡ„еӯҳеӮЁз»“жһ„
дјҡеңЁиЎЁзӣ®еҪ•дёӢпјҢеҲӣе»ә month=xxx дҪңдёәеҗҚеӯ—зҡ„зӣ®еҪ•пјҢдәҢзә§еҲҶеҢәзұ»дјјпјҲ10пјүжүӢеҠЁеҲӣе»әеҲҶеҢәзӣ®еҪ•е№¶дёҠдј ж•°жҚ®зҡ„еӨ„зҗҶж–№ејҸ
жүӢеҠЁеҲӣе»әеҲҶеҢәзӣ®еҪ•е№¶дёҠдј ж•°жҚ®пјҢжҳҜжІЎеҠһжі•зӣҙжҺҘйҖҡиҝҮselectжҹҘзңӢеҲ°ж•°жҚ®зҡ„гҖӮеӨ„зҗҶж–№ејҸеҰӮдёӢ
ж–№ејҸ1пјҡmsck repair table tb_name дҝ®еӨҚиЎЁ
ж–№ејҸ2пјҡжүӢеҠЁйҖҡиҝҮ alter table tb add parition(xxxx)ж·»еҠ еҲҶеҢә
ж–№ејҸ3пјҡжүӢеҠЁдҪҝз”ЁloadеҠ иҪҪж•°жҚ®еҲ°жҢҮе®ҡеҲҶеҢәдҝ®ж”№иЎЁеҗҚпјҡ
ALTER TABLE table_name RENAME TO new_table_name
жӣҙж–°еҲ—пјҡжӣҙж–°еҚ•дёӘеӯ—ж®ө
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
еҰӮпјҡ alter table dept_partition change column deptdesc desc int;
еўһеҠ еҲ—пјҡ
alter table dept_partition add columns(deptdesc string);
жӣҝжҚўеҲ—пјҡжіЁж„ҸиҝҷйҮҢжҳҜжӣҝжҚўж•ҙдёӘиЎЁзҡ„жүҖжңүеӯ—ж®ө
alter table dept_partition replace columns(deptno string, dname string, loc string);drop table TB_NAMEhive>load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student [partition (partcol1=val1,вҖҰ)];
local:иЎЁзӨәд»Һжң¬ең°еҠ иҪҪж•°жҚ®еҲ°hiveиЎЁпјӣеҗҰеҲҷд»ҺHDFSеҠ иҪҪж•°жҚ®еҲ°hiveиЎЁгҖӮйҖҡиҝҮhdfsеҠ иҪҪж•°жҚ®еҲ°иЎЁдёӯж—¶пјҢдјҡе°Ҷж–Ү件еүӘеҲҮеҲ°иЎЁжүҖеңЁзҡ„и·Ҝеҫ„дёӢгҖӮж— и®әжҳҜеӨ–йғЁиЎЁиҝҳжҳҜеҶ…йғЁиЎЁ
overwrite:иЎЁзӨәиҰҶзӣ–иЎЁдёӯе·Іжңүж•°жҚ®пјҢеҗҰеҲҷиЎЁзӨәиҝҪеҠ ,еҰӮжһңжІЎжңүoverwriteзҡ„иҜқпјҢеҗҢеҗҚзҡ„ж–Ү件еҠ иҪҪиҝӣеҺ»ж—¶еҖҷпјҢдјҡйҮҚе‘ҪеҗҚдёә tableName_copy_1
partition:иЎЁзӨәдёҠдј еҲ°жҢҮе®ҡеҲҶеҢәеҲӣе»әдёҖеј еҲҶеҢәиЎЁж–№дҫҝз”Ёе®һдҫӢи®Іи§Јпјҡ
hive (default)> create table student2(id int, name string) partitioned by (month string) row format delimited fields terminated by '\t';
еҹәжң¬жҸ’е…Ҙпјҡ insert into table student partition(month='201809') values(1,'wangwu');
еҚ•иЎЁжҹҘиҜўжҸ’е…Ҙпјҡ
insert overwrite table student2 partition(month='201808')
select id, name from student where month='201809';
еӨҡиЎЁжҹҘиҜўжҸ’е…Ҙпјҡ
from student
insert overwrite table student2 partition(month='201807')
select id, name where month='201809'
insert overwrite table student2 partition(month='201806')
select id, name where month='201809';create table if not exists student3
as select id, name from student;
дёҖиҲ¬з”ЁеңЁз»“жһңиЎЁдёӯпјҢжҹҘиҜўе®ҢжҜ•еҗҺдҝқеӯҳз»“жһңеҲ°еҸҰеӨ–дёҖеј иЎЁcreate table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student5';
жҺҘзқҖзӣҙжҺҘе°Ҷж•°жҚ®дёҠдј еҲ°дёҠйқўжҢҮе®ҡзҡ„зӣ®еҪ•дёӢпјҢе°ұеҸҜзӣҙжҺҘselectжҹҘиҜўеҲ°ж•°жҚ®пјҢж— йңҖеҶҚж¬ЎжүӢеҠЁloadгҖӮеҰӮжһңжІЎжңүжҢҮе®ҡlocationпјҢеҲҷй»ҳи®ӨиЎЁзӣ®еҪ•дёә /user/hive/warehouse/xxxx/дёӢпјҢдё”йңҖиҰҒжүӢеҠЁloadж•°жҚ®иҝҷйҮҢеҸӘиғҪеҜје…ҘдҪҝз”ЁexportеҜјеҮәзҡ„ж•°жҚ®пјҢдёӢйқўжңүи®Іexport
import table student2 partition(month='201809') from '/user/hive/warehouse/export/student';insert overwrite [local] directory'/opt/module/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
localпјҡиЎЁзӨәеҜјеҮәеҲ°жң¬ең°ж–Ү件系з»ҹпјҢеҗҰеҲҷеҜјеҮәеҲ°hdfs
еҜјеҮәж—¶еҸҜд»ҘжҢҮе®ҡеӯ—ж®өзҡ„еҲҶйҡ”з¬ҰгҖҒиЎҢеҲҶйҡ”з¬Ұзӯүеӣ дёәhiveзҡ„ж•°жҚ®ж–Ү件е°ұжҳҜж–Үжң¬ж–Ү件пјҢеҸҜд»ҘзӣҙжҺҘйҖҡиҝҮhdfsеҜјеҮә
hive (default)> dfs -get /user/hive/warehouse/student/month=201809/000000_0 /opt/module/datas/export/student3.txt;export table default.student to '/user/hive/warehouse/export/student';truncate table TB_NAMESELECT [ALL | DISTINCT] select_expr, elect_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]дёӢйқўе®һдҫӢдёӯж¶үеҸҠеҲ°еҮ дёӘиЎЁпјҡ
е‘ҳе·ҘиЎЁempпјҡ
empno neame job mgr hiredate comm deptno
е‘ҳе·ҘеҸ· е‘ҳе·ҘеҗҚ иҒҢдҪҚ йўҶеҜј йӣҮдҪЈж—Ҙжңҹ и–Әиө„ йғЁй—ЁеҸ·
йғЁй—ЁиЎЁdeptпјҡ
deptno dname loc
йғЁй—ЁеҸ· йғЁй—ЁеҗҚ дҪҚзҪ®
дҪҚзҪ®дҝЎжҒҜиЎЁlocationпјҡ
loc loc_nmae
дҪҚзҪ®ж ҮеҸ· дҪҚзҪ®еҗҚselect еӯ—ж®өеҗҚ from table_name
еӯ—ж®өеҗҚеҸҜд»ҘдҪҝз”Ёпјҡеӯ—ж®өеҗҚ as еҲ«еҗҚ зҡ„ж–№ејҸжқҘз»ҷеӯ—ж®өе®ҡд№үеҲ«еҗҚ
пјҲ1пјүеҜ№еӯ—ж®өиҝӣиЎҢз®—жңҜж“ҚдҪң
дҫӢеӯҗпјҡselect sal +1 from emp;
пјҲ2пјүеёёз”ЁеҮҪж•°
1пјүжұӮжҖ»иЎҢж•°пјҲcountпјү
hive (default)> select count(*) cnt from emp;
иҝҷйҮҢеҸҜд»ҘеҶҷжҲҗcount(1)пјҢжҜ”count(*)ж•ҲзҺҮй«ҳ
2пјүжұӮе·Ҙиө„зҡ„жңҖеӨ§еҖјпјҲmaxпјү
hive (default)> select max(sal) max_sal from emp;
3пјүжұӮе·Ҙиө„зҡ„жңҖе°ҸеҖјпјҲminпјү
hive (default)> select min(sal) min_sal from emp;
4пјүжұӮе·Ҙиө„зҡ„жҖ»е’ҢпјҲsumпјү
hive (default)> select sum(sal) sum_sal from emp;
5пјүжұӮе·Ҙиө„зҡ„е№іеқҮеҖјпјҲavgпјү
hive (default)> select avg(sal) avg_sal from emp;
пјҲ3пјүlimit N
йҷҗеҲ¶иҝ”еӣһеүҚNиЎҢwhere еҲӨж–ӯжқЎд»¶
еҲӨж–ӯжқЎд»¶:
пјҲ1пјүжҜ”иҫғиҝҗз®—з¬Ұпјҡеёёз”Ёзҡ„еӨ§дәҺе°ҸдәҺзӯүпјҢbetween andгҖҒinгҖҒis nullз”Ёжі•е’Ңmysqlзұ»дјј
пјҲ2пјүlike BпјҡBжҳҜз®ҖеҚ•зҡ„йҖҡй…Қз¬Ұеӯ—з¬ҰдёІпјҢ
% д»ЈиЎЁйӣ¶дёӘжҲ–еӨҡдёӘеӯ—з¬Ұ(д»»ж„ҸдёӘеӯ—з¬Ұ)гҖӮ
_ д»ЈиЎЁдёҖдёӘеӯ—з¬Ұ
RLIKE BпјҡиҝҷжҳҜдҪҝз”Ёж ҮеҮҶзҡ„жӯЈеҲҷиЎЁиҫҫејҸ
пјҲ3пјүйҖ»иҫ‘иҝҗз®—з¬ҰпјҡAND OR NOTGROUP BYиҜӯеҸҘйҖҡеёёдјҡе’ҢиҒҡеҗҲеҮҪж•°дёҖиө·дҪҝз”ЁпјҢжҢүз…§дёҖдёӘжҲ–иҖ…еӨҡдёӘеҲ—йҳҹз»“жһңиҝӣиЎҢеҲҶз»„пјҢ然еҗҺеҜ№жҜҸдёӘз»„жү§иЎҢиҒҡеҗҲж“ҚдҪңгҖӮ
жЎҲдҫӢе®һж“Қпјҡ
пјҲ1пјүи®Ўз®—empиЎЁжҜҸдёӘйғЁй—Ёзҡ„е№іеқҮе·Ҙиө„.д»ҘйғЁй—ЁеҸ·еҲҶз»„
hive (default)> select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
пјҲ2пјүи®Ўз®—empжҜҸдёӘйғЁй—ЁдёӯжҜҸдёӘеІ—дҪҚзҡ„жңҖй«ҳи–Әж°ҙгҖӮд»ҘйғЁй—ЁеҸ·еҲҶз»„
hive (default)> select t.deptno, t.job, max(t.sal) max_sal from emp t group by t.deptno, t.job;
жіЁж„Ҹпјҡgroup byж—¶иҰҒжіЁж„ҸпјҢеүҚйқўselectзҡ„еӯ—ж®өпјҢйғҪиҰҒеҮәзҺ°еңЁgroup byйҮҢпјҢдҫӢеҰӮ
select id,name from a group id,name; дёҚеҸҜд»ҘеҶҷжҲҗ select id,name from a group id;havingе’Ңwhereз”Ёжі•дёҖж ·пјҢеҢәеҲ«еҰӮдёӢпјҡ
пјҲ1пјүwhereй’ҲеҜ№иЎЁдёӯзҡ„еҲ—еҸ‘жҢҘдҪңз”ЁпјҢжҹҘиҜўж•°жҚ®пјӣhavingй’ҲеҜ№жҹҘиҜўз»“жһңдёӯзҡ„еҲ—еҸ‘жҢҘдҪңз”ЁпјҢзӯӣйҖүж•°жҚ®гҖӮ
пјҲ2пјүwhereеҗҺйқўдёҚиғҪеҶҷеҲҶз»„еҮҪж•°пјҢиҖҢhavingеҗҺйқўеҸҜд»ҘдҪҝз”ЁеҲҶз»„еҮҪж•°гҖӮ
пјҲ3пјүhavingеҸӘз”ЁдәҺgroup byеҲҶз»„з»ҹи®ЎиҜӯеҸҘгҖӮ
дҫӢеӯҗпјҡ
жұӮжҜҸдёӘйғЁй—Ёзҡ„е№іеқҮи–Әж°ҙеӨ§дәҺ2000зҡ„йғЁй—Ё
hive (default)> select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;hiveд»…д»…ж”ҜжҢҒзӯүеҖјиҝһжҺҘпјҢдёҚж”ҜжҢҒйқһзӯүеҖјиҝһжҺҘгҖӮжіЁж„Ҹjoinзҡ„onиҜӯеҸҘдёӯпјҢдёҚж”ҜжҢҒдҪҝз”Ё or иҝӣиЎҢеӨҡжқЎд»¶иҒ”еҗҲ
select xx from A еҲ«еҗҚ1 join B еҲ«еҗҚ2 on зӯүеҖјеҲӨж–ӯ
дҫӢеӯҗпјҡ
ж №жҚ®е‘ҳе·ҘиЎЁе’ҢйғЁй—ЁиЎЁзҡ„йғЁй—Ёзј–еҸ·иҝӣиЎҢиҝһжҺҘ
select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;JOINж“ҚдҪңз¬Ұе·Ұиҫ№иЎЁдёӯз¬ҰеҗҲWHEREеӯҗеҸҘзҡ„жүҖжңүи®°еҪ•е°Ҷдјҡиў«иҝ”еӣһ.
д»Ҙе·ҰиЎЁдёәеҮҶпјҢеҸіиЎЁдёӯзҡ„иЎҢжІЎжңүеҢ№й…ҚеҲ°е·ҰиЎЁзҡ„пјҢе°ұзӣҙжҺҘеҺ»жҺүпјҢеҢ№й…ҚеҲ°зҡ„е°ұжҳҫзӨәпјҢеҰӮжһңеҸіиЎЁжңүеӨҡиЎҢеҢ№й…Қе·ҰиЎЁзҡ„еҗҢдёҖиЎҢпјҢйӮЈд№ҲиҜҘиЎҢе°ұдјҡжҳҫзӨәеӨҡж¬ЎгҖӮеҰӮжһңе·ҰиЎЁзҡ„иЎҢеңЁеҸіиЎЁдёӯжІЎжңүеҢ№й…ҚпјҢеҸіиЎЁзҡ„ж•°жҚ®е°ұдјҡжҳҫзӨәдёәnull
select xx from A еҲ«еҗҚ1 left join B еҲ«еҗҚ2 on зӯүеҖјеҲӨж–ӯ
дҫӢеӯҗпјҡ
select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;е’Ңе·ҰиҝһжҺҘпјҢеҸӘдёҚиҝҮе°ҶеҗҺйқўзҡ„иЎЁдҪңдёәе·ҰиЎЁдәҶгҖӮиҝҳжҳҜд»Ҙе·ҰиЎЁдёәеҮҶиҝӣиЎҢиҝһжҺҘ
select xx from A еҲ«еҗҚ1 right join B еҲ«еҗҚ2 on зӯүеҖјеҲӨж–ӯ
дҫӢеӯҗпјҡ
select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;жҳҫзӨәдёӨиЎЁзҡ„жүҖжңүи®°еҪ•пјҢдёҚеҢ№й…Қзҡ„е°ұеҜ№еә”жҳҫзӨәдёәnull
select xx from A еҲ«еҗҚ1 full join B еҲ«еҗҚ2 on зӯүеҖјеҲӨж–ӯ
дҫӢеӯҗпјҡ
select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;иҝһжҺҘ nдёӘиЎЁпјҢиҮіе°‘йңҖиҰҒn-1дёӘиҝһжҺҘжқЎд»¶гҖӮдҫӢеҰӮпјҡиҝһжҺҘдёүдёӘиЎЁпјҢиҮіе°‘йңҖиҰҒдёӨдёӘиҝһжҺҘжқЎд»¶гҖӮ
дҫӢеӯҗпјҡ
SELECT e.ename, d.deptno, l. loc_name
FROM emp e
JOIN dept d
ON d.deptno = e.deptno
JOIN location l
ON d.loc = l.loc;
еӨ§еӨҡж•°жғ…еҶөдёӢпјҢHiveдјҡеҜ№жҜҸеҜ№JOINиҝһжҺҘеҜ№иұЎеҗҜеҠЁдёҖдёӘMapReduceд»»еҠЎгҖӮжң¬дҫӢдёӯдјҡйҰ–е…ҲеҗҜеҠЁдёҖдёӘMapReduce jobеҜ№иЎЁeе’ҢиЎЁdиҝӣиЎҢиҝһжҺҘж“ҚдҪңпјҢ然еҗҺдјҡеҶҚеҗҜеҠЁдёҖдёӘMapReduce jobе°Ҷ第дёҖдёӘMapReduce jobзҡ„иҫ“еҮәе’ҢиЎЁl;иҝӣиЎҢиҝһжҺҘж“ҚдҪңгҖӮ
жіЁж„Ҹпјҡдёәд»Җд№ҲдёҚжҳҜиЎЁdе’ҢиЎЁlе…ҲиҝӣиЎҢиҝһжҺҘж“ҚдҪңе‘ўпјҹиҝҷжҳҜеӣ дёәHiveжҖ»жҳҜжҢүз…§д»Һе·ҰеҲ°еҸізҡ„йЎәеәҸжү§иЎҢзҡ„гҖӮOrder Byпјҡе…ЁеұҖжҺ’еәҸпјҢжң¬иҙЁе°ұжҳҜеҚ•зӢ¬еҗҜеҠЁдёҖдёӘMapReduceз”ЁдәҺе…ЁеұҖжҺ’еәҸ
1пјүдҪҝз”Ё ORDER BY еӯҗеҸҘжҺ’еәҸ
ASCпјҲascendпјү: еҚҮеәҸпјҲй»ҳи®Өпјү
DESCпјҲdescendпјү: йҷҚеәҸ
2пјүORDER BY еӯҗеҸҘеңЁSELECTиҜӯеҸҘзҡ„з»“е°ҫгҖӮ
3пјүжЎҲдҫӢе®һж“Қ
пјҲ1пјүжҹҘиҜўе‘ҳе·ҘдҝЎжҒҜжҢүе·Ҙиө„еҚҮеәҸжҺ’еҲ—
hive (default)> select * from emp order by sal;
пјҲ2пјүжҹҘиҜўе‘ҳе·ҘдҝЎжҒҜжҢүе·Ҙиө„йҷҚеәҸжҺ’еҲ—
hive (default)> select * from emp order by sal desc;жҢүз…§е‘ҳе·Ҙи–Әж°ҙзҡ„2еҖҚжҺ’еәҸ
select ename, sal*2 twosal from emp order by twosal;жҢүз…§йғЁй—Ёе’Ңе·Ҙиө„еҚҮеәҸжҺ’еәҸ
hive (default)> select ename, deptno, sal from emp order by deptno, sal ;иҝҷдёӘиҜӯеҸҘжҳҜз”ЁеңЁMapReduceдёӯжҜҸдёӘеҲҶеҢәзҡ„еҢәеҶ…жҺ’еәҸгҖӮжңҖз»ҲжҜҸдёӘreduceзӢ¬иҮӘиҫ“еҮәиҮӘе·ұзҡ„жҺ’еәҸз»“жһңпјҢдёҚдјҡиҝӣиЎҢжүҖжңүreduceзҡ„еҶҚдёҖж¬ЎжҺ’еәҸ
1пјүи®ҫзҪ®reduceдёӘж•°
hive (default)> set mapreduce.job.reduces=3;
2пјүжҹҘзңӢи®ҫзҪ®reduceдёӘж•°
hive (default)> set mapreduce.job.reduces;
3пјүж №жҚ®йғЁй—Ёзј–еҸ·йҷҚеәҸжҹҘзңӢе‘ҳе·ҘдҝЎжҒҜ
hive (default)> select * from emp sort by empno desc;Distribute Byпјҡзұ»дјјMRдёӯpartitionпјҢиҝӣиЎҢеҲҶеҢәпјҢеҚіжҢҮе®ҡеҲҶеҢәзҡ„еӯ—ж®өжҳҜе“ӘдёӘпјҢиҝҷйҮҢзҡ„еҲҶеҢәе’ҢдёҠйқўзҡ„partitionзҡ„еҲҶеҢәдёҚжҳҜдёҖдёӘж„ҸжҖқпјҢиҰҒжіЁж„ҸпјҢиҝҷйҮҢжҢҮзҡ„жҳҜзЁӢеәҸдёӯзҡ„еҲҶеҢәпјҢдёҠйқўжҢҮзҡ„жҳҜеӯҳеӮЁзҡ„еҲҶеҢәгҖӮз»“еҗҲsort byдҪҝз”ЁгҖӮ
жіЁж„ҸпјҡHiveиҰҒжұӮDISTRIBUTE BYиҜӯеҸҘиҰҒеҶҷеңЁSORT BYиҜӯеҸҘд№ӢеүҚгҖӮ
еҜ№дәҺdistribute byиҝӣиЎҢжөӢиҜ•пјҢдёҖе®ҡиҰҒеҲҶй…ҚеӨҡreduceиҝӣиЎҢеӨ„зҗҶпјҢеҗҰеҲҷж— жі•зңӢеҲ°distribute byзҡ„ж•ҲжһңгҖӮ
пјҲ1пјүе…ҲжҢүз…§йғЁй—Ёзј–еҸ·еҲҶеҢәпјҢеҶҚжҢүз…§е‘ҳе·Ҙзј–еҸ·йҷҚеәҸжҺ’еәҸгҖӮ
hive (default)> set mapreduce.job.reduces=3;
hive (default)> insert overwrite local directory '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
иҝҷйҮҢеҶҷеҲ°ж–Ү件дёӯпјҢеӣ дёәеҲҶеҢәдәҶпјҢжүҖд»Ҙдјҡдә§з”ҹеӨҡдёӘж–Ү件пјҲжҜҸдёӘreduceдёҖдёӘж–Ү件пјүпјҢиҝҷж ·дҫҝдәҺжҹҘзңӢеҲҶеҢәзҡ„з»“жһңеҪ“distribute byе’Ңsorts byеӯ—ж®өзӣёеҗҢж—¶пјҢеҸҜд»ҘдҪҝз”Ёcluster byж–№ејҸгҖӮ
cluster byйҷӨдәҶе…·жңүdistribute byзҡ„еҠҹиғҪеӨ–иҝҳе…је…·sort byзҡ„еҠҹиғҪгҖӮдҪҶжҳҜжҺ’еәҸеҸӘиғҪжҳҜеҖ’еәҸжҺ’еәҸпјҢдёҚиғҪжҢҮе®ҡжҺ’еәҸ规еҲҷдёәASCжҲ–иҖ…DESCгҖӮеҚіе®һзҺ°жҢҮе®ҡеӯ—ж®өеҲҶеҢәпјҢ并еҜ№иҜҘеӯ—ж®өжҺ’еәҸ
1пјүд»ҘдёӢдёӨз§ҚеҶҷжі•зӯүд»·
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
жіЁж„ҸпјҡжҢүз…§йғЁй—Ёзј–еҸ·еҲҶеҢәпјҢдёҚдёҖе®ҡе°ұжҳҜеӣәе®ҡжӯ»зҡ„ж•°еҖјпјҢеҸҜд»ҘжҳҜ20еҸ·е’Ң30еҸ·йғЁй—ЁеҲҶеҲ°дёҖдёӘеҲҶеҢәйҮҢйқўеҺ»гҖӮвҖӢ еҲҶеҢәй’ҲеҜ№зҡ„жҳҜж•°жҚ®зҡ„еӯҳеӮЁи·Ҝеҫ„пјӣеҲҶжЎ¶й’ҲеҜ№зҡ„жҳҜж•°жҚ®ж–Ү件гҖӮеҲҶжЎ¶д№ӢеҗҺпјҢдјҡе°ҶеҺҹе…Ҳзҡ„ж•°жҚ®ж–Ү件зӣҙжҺҘеҲҶйҡ”жҲҗеӨҡдёӘжЎ¶ж–Ү件пјҢжҜҸдёӘжЎ¶дёҖдёӘж–Ү件гҖӮеҲҶеҢәеҸӘжҳҜе°Ҷж•°жҚ®ж–Ү件жң¬иә«ж”ҫеҲ°дёҚеҗҢзҡ„еҲҶеҢәзӣ®еҪ•иҖҢе·ІпјҢдёҚдјҡеҜ№ж•°жҚ®ж–Ү件иҝӣиЎҢеҲҶеүІгҖӮ
вҖӢ еҲҶеҢәжҸҗдҫӣдёҖдёӘйҡ”зҰ»ж•°жҚ®е’ҢдјҳеҢ–жҹҘиҜўзҡ„дҫҝеҲ©ж–№ејҸгҖӮдёҚиҝҮпјҢ并йқһжүҖжңүзҡ„ж•°жҚ®йӣҶйғҪеҸҜеҪўжҲҗеҗҲзҗҶзҡ„еҲҶеҢәпјҢзү№еҲ«жҳҜд№ӢеүҚжүҖжҸҗеҲ°иҝҮзҡ„иҰҒзЎ®е®ҡеҗҲйҖӮзҡ„еҲ’еҲҶеӨ§е°ҸиҝҷдёӘз–‘иҷ‘гҖӮиҖҢеҲҶжЎ¶е…¶е®һе°ұжҳҜе®һзҺ°е°ҶдёҖдёӘеӨ§зҡ„ж•°жҚ®ж–Үд»¶ж №жҚ®еҲҶеҢәеӯ—ж®өиҮӘеҠЁеҲҶжҲҗеҮ дёӘеҲҶеҢәпјҢиҝҷе°ұжҳҜеҲҶжЎ¶зҡ„дҪңз”Ё
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
еӯ—ж®өи§ЈйҮҠпјҡ
clustered by(id) пјҡеҲҶжЎ¶зҡ„еӯ—ж®өеҗҚ
into 4 bucketsпјҡеҲҶжЎ¶дёӘж•°
еҺҹе§Ӣж•°жҚ®дёәпјҡstudent.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
дҪҝз”ЁеҲҶжЎ¶йңҖиҰҒжү“ејҖзӣёеә”еҸӮж•°и®ҫзҪ®пјҡ
hive (default)> set hive.enforce.bucketing=true;
hive (default)> set mapreduce.job.reduces=-1;
жҺҘзқҖеҸҰеӨ–еҲӣе»әдёҖеј еҗҢж ·зҡ„иЎЁпјҲжІЎжңүеҲҶжЎ¶пјүпјҢ并еҜје…Ҙж•°жҚ®пјҡ
create table stu2(id int, name string) row format delimited fields terminated by '\t';
load data local inpath '/opt/module/datas/student.txt' into table stu2;
жҺҘзқҖйҖҡиҝҮеӯҗжҹҘиҜўзҡ„ж–№ејҸеҜје…Ҙж•°жҚ®еҲ°еҲҶжЎ¶иЎЁпјҲеҲҶжЎ¶иЎЁеҸӘиғҪйҖҡиҝҮиҝҷз§Қж–№ејҸеҜје…Ҙж•°жҚ®пјүпјҡ
insert overwrite table stu_buck
select id, name from stu2;
жҹҘзңӢеҲҶжЎ¶ж•°жҚ®пјҡ
hive (default)> select * from stu_buck;
OK
stu_buck.id stu_buck.name
1016 ss16
1012 ss12
1008 ss8
1004 ss4
1009 ss9
1005 ss5
1001 ss1
1013 ss13
1010 ss10
1002 ss2
1006 ss6
1014 ss14
1003 ss3
1011 ss11
1007 ss7
1015 ss15
еҸҜд»ҘзңӢеҲ°дёҖиҲ¬жғ…еҶөдёӢпјҢеә”иҜҘжҳҜжҢүidжңүеәҸжҳҫзӨәзҡ„пјҢдҪҶжҳҜиҝҷйҮҢжҳҺжҳҫдёҚжҳҜпјҢиҝҷе°ұжҳҜеҲҶжЎ¶зҡ„еҪұе“ҚдәҶ
жҹҘзңӢеҲҶжЎ¶иЎЁзҡ„дҝЎжҒҜпјҡ
desc formatted stu_buck;еҜ№дәҺйқһеёёеӨ§зҡ„ж•°жҚ®йӣҶпјҢжңүж—¶з”ЁжҲ·йңҖиҰҒдҪҝз”Ёзҡ„жҳҜдёҖдёӘе…·жңүд»ЈиЎЁжҖ§зҡ„жҹҘиҜўз»“жһңиҖҢдёҚжҳҜе…ЁйғЁз»“жһңгҖӮHiveеҸҜд»ҘйҖҡиҝҮеҜ№иЎЁиҝӣиЎҢжҠҪж ·жқҘж»Ўи¶іиҝҷдёӘйңҖжұӮгҖӮ
жҹҘиҜўиЎЁstu_buckдёӯзҡ„ж•°жҚ®гҖӮ
hive (default)> select * from stu_buck tablesample(bucket 1 out of 4 on id);
жіЁпјҡtablesampleжҳҜжҠҪж ·иҜӯеҸҘпјҢиҜӯжі•пјҡTABLESAMPLE(BUCKET x OUT OF y) гҖӮ
yеҝ…йЎ»жҳҜtableжҖ»bucketж•°зҡ„еҖҚж•°жҲ–иҖ…еӣ еӯҗгҖӮhiveж №жҚ®yзҡ„еӨ§е°ҸпјҢеҶіе®ҡжҠҪж ·зҡ„жҜ”дҫӢгҖӮдҫӢеҰӮпјҢtableжҖ»е…ұеҲҶдәҶ4д»ҪпјҢеҪ“y=2ж—¶пјҢжҠҪеҸ–(4/2=)2дёӘbucketзҡ„ж•°жҚ®пјҢеҪ“y=8ж—¶пјҢжҠҪеҸ–(4/8=)1/2дёӘbucketзҡ„ж•°жҚ®гҖӮ
пјҲдёӘдәәзҗҶи§ЈпјүyиЎЁзӨәзҡ„жҳҜжҠҪж ·зҡ„й—ҙйҡ”зҡ„bucketзҡ„дёӘж•°пјҢжҜ”еҰӮ2пјҢиЎЁзӨәдёӯй—ҙз©әдёҖдёӘbucketпјҢ然еҗҺеҶҚжҠҪгҖӮеҰӮжһңyеӨ§дәҺbucketзҡ„дёӘж•°пјҢйӮЈд№Ҳе°ұдјҡеңЁз¬¬дёҖдёӘејҖе§ӢжҠҪж ·зҡ„bucketдёӯ继з»ӯиҝӣиЎҢеү©дёӢзҡ„й—ҙйҡ”жҖ§жҠҪж ·гҖӮеҰӮbucketж•°дёә4пјҢy=12пјҢйӮЈд№ҲжңҖеҗҺиӮҜе®ҡеҸӘжңү第дёҖдёӘејҖе§ӢжҠҪзҡ„bucketдјҡиў«жҠҪж ·пјҢеңЁиҝҷдёӘbucketдёӯдјҡжҠҪеҸ– 4/12=1/3 дёӘж•°жҚ®гҖӮ
xиЎЁзӨәд»Һе“ӘдёӘbucketејҖе§ӢжҠҪеҸ–гҖӮдҫӢеҰӮпјҢtableжҖ»bucketж•°дёә4пјҢtablesample(bucket 4 out of 4)пјҢиЎЁзӨәжҖ»е…ұжҠҪеҸ–пјҲ4/4=пјү1дёӘbucketзҡ„ж•°жҚ®пјҢжҠҪеҸ–第4дёӘbucketзҡ„ж•°жҚ®гҖӮ
жіЁж„Ҹпјҡxзҡ„еҖјеҝ…йЎ»е°ҸдәҺзӯүдәҺyзҡ„еҖјпјҢеҗҰеҲҷ
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck1пјүжҹҘзңӢзі»з»ҹиҮӘеёҰзҡ„еҮҪж•°
hive> show functions;
2пјүжҳҫзӨәиҮӘеёҰзҡ„еҮҪж•°зҡ„з”Ёжі•
hive> desc function upper;
3пјүиҜҰз»ҶжҳҫзӨәиҮӘеёҰзҡ„еҮҪж•°зҡ„з”Ёжі•
hive> desc function extended upper;еҰӮжһңиҮӘеёҰзҡ„еҮҪж•°ж»Ўи¶ідёҚдәҶйңҖжұӮпјҢеҸҜд»ҘиҮӘе®ҡд№үеҮҪж•°пјҢз§°дёәUDF--user defined function
ж №жҚ®з”ЁжҲ·иҮӘе®ҡд№үеҮҪж•°зұ»еҲ«еҲҶдёәд»ҘдёӢдёүз§Қпјҡ
пјҲ1пјүUDFпјҲUser-Defined-Functionпјү
дёҖиҝӣдёҖеҮә
пјҲ2пјүUDAFпјҲUser-Defined Aggregation Functionпјү
иҒҡйӣҶеҮҪж•°пјҢеӨҡиҝӣдёҖеҮә
зұ»дјјдәҺпјҡcount/max/min
пјҲ3пјүUDTFпјҲUser-Defined Table-Generating Functionsпјү
дёҖиҝӣеӨҡеҮә
еҰӮlateral view explore()иҮӘе®ҡд№үеҮҪж•°зҡ„жӯҘйӘӨпјҡ
пјҲ1пјү继жүҝorg.apache.hadoop.hive.ql.UDF
пјҲ2пјүйңҖиҰҒе®һзҺ°evaluateеҮҪж•°пјӣevaluateеҮҪж•°ж”ҜжҢҒйҮҚиҪҪпјӣ
пјҲ3пјүеңЁhiveзҡ„е‘Ҫд»ӨиЎҢзӘ—еҸЈеҲӣе»әеҮҪж•°
aпјүж·»еҠ jar
add jar linux_jar_path
bпјүеҲӣе»әfunctionпјҢ
create [temporary] function [dbname.]function_name AS
class_name;
еҗҺйқўе°ұеҸҜд»ҘдҪҝз”Ё function_name жқҘи°ғз”ЁеҮҪж•°
пјҲ4пјүеңЁhiveзҡ„е‘Ҫд»ӨиЎҢзӘ—еҸЈеҲ йҷӨеҮҪж•°
Drop [temporary] function [if exists] [dbname.]function_name;еҪ“hiveеә•еұӮдҪҝз”ЁMapReduceж—¶пјҢдҪҝз”ЁеҺӢзј©еҠҹиғҪйңҖиҰҒhadoopжң¬иә«ејҖеҗҜзӣёеә”зҡ„й…ҚзҪ®пјҢд»ҘеҸҠзӣёеә”зҡ„еҺӢзј©ж јејҸзҡ„jarеҢ…дҫқиө–гҖӮе…ідәҺиҝҷеҶ…е®№дёҚйҮҚеӨҚиҜҙпјҢзңӢд№ӢеүҚзҡ„вҖңhadoop-еҺӢзј©вҖқдёӯзҡ„й…ҚзҪ®гҖӮдёӢйқўи®Ізҡ„жҳҜhiveдёӯзҡ„й…ҚзҪ®гҖӮ
ејҖеҗҜmapиҫ“еҮәйҳ¶ж®өеҺӢзј©еҸҜд»ҘеҮҸе°‘jobдёӯmapе’ҢReduce taskй—ҙж•°жҚ®дј иҫ“йҮҸгҖӮе…·дҪ“й…ҚзҪ®еҰӮдёӢ:
1пјүејҖеҗҜhiveдёӯй—ҙдј иҫ“ж•°жҚ®еҺӢзј©еҠҹиғҪ
hive (default)>set hive.exec.compress.intermediate=true;
2пјүејҖеҗҜmapreduceдёӯmapиҫ“еҮәеҺӢзј©еҠҹиғҪ
hive (default)>set mapreduce.map.output.compress=true;
3пјүи®ҫзҪ®mapreduceдёӯmapиҫ“еҮәж•°жҚ®зҡ„еҺӢзј©ж–№ејҸ,иҝҷйҮҢдҪҝз”Ёsnappy
hive (default)>set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
4пјүжү§иЎҢжҹҘиҜўиҜӯеҸҘ
hive (default)> select count(ename) name from emp;еҪ“Hiveе°Ҷиҫ“еҮәеҶҷе…ҘеҲ°иЎЁдёӯж—¶пјҢиҫ“еҮәеҶ…е®№еҗҢж ·еҸҜд»ҘиҝӣиЎҢеҺӢзј©гҖӮеұһжҖ§hive.exec.compress.outputжҺ§еҲ¶зқҖиҝҷдёӘеҠҹиғҪгҖӮз”ЁжҲ·еҸҜиғҪйңҖиҰҒдҝқжҢҒй»ҳи®Өи®ҫзҪ®ж–Ү件дёӯзҡ„й»ҳи®ӨеҖјfalseпјҢиҝҷж ·й»ҳи®Өзҡ„иҫ“еҮәе°ұжҳҜйқһеҺӢзј©зҡ„зәҜж–Үжң¬ж–Ү件дәҶгҖӮз”ЁжҲ·еҸҜд»ҘйҖҡиҝҮеңЁжҹҘиҜўиҜӯеҸҘжҲ–жү§иЎҢи„ҡжң¬дёӯи®ҫзҪ®иҝҷдёӘеҖјдёәtrueпјҢжқҘејҖеҗҜиҫ“еҮәз»“жһңеҺӢзј©еҠҹиғҪгҖӮ
1пјүејҖеҗҜhiveжңҖз»Ҳиҫ“еҮәж•°жҚ®еҺӢзј©еҠҹиғҪ
hive (default)>set hive.exec.compress.output=true;
2пјүејҖеҗҜmapreduceжңҖз»Ҳиҫ“еҮәж•°жҚ®еҺӢзј©
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3пјүи®ҫзҪ®mapreduceжңҖз»Ҳж•°жҚ®иҫ“еҮәеҺӢзј©ж–№ејҸ
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
4пјүи®ҫзҪ®mapreduceжңҖз»Ҳж•°жҚ®иҫ“еҮәеҺӢзј©дёәеқ—еҺӢзј©
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5пјүжөӢиҜ•дёҖдёӢиҫ“еҮәз»“жһңжҳҜеҗҰжҳҜеҺӢзј©ж–Ү件,еҰӮжһңејҖеҗҜеҺӢзј©зҡ„иҜқпјҢиҫ“еҮәзҡ„ж–Ү件е°ұжҳҜеҺӢзј©ж јејҸзҡ„
hive (default)> insert overwrite local directory '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;hiveдё»иҰҒеҲҶдёәиЎҢеӯҳеӮЁе’ҢеҲ—еӯҳеӮЁдёӨеӨ§зұ»пјҢдё»иҰҒж јејҸжңүпјҡ
иЎҢеӯҳеӮЁпјҡTEXTFILEпјҲж–Үжң¬ж јејҸпјү гҖҒSEQUENCEFILEпјҲдәҢиҝӣеҲ¶ж јејҸпјү
еҲ—еӯҳеӮЁпјҡORCпјҲOptimized Row ColumnarпјҢй»ҳи®ӨејҖеҗҜеҺӢзј©пјҢдё”йҮҮз”ЁzlibеҺӢзј©пјүгҖҒPARQUETпјҢиҝҷдёӨз§Қж јејҸзҡ„еӯҳеӮЁеҺҹзҗҶеҸҜиҮӘиЎҢеӯҰд№ пјҢиҝҷйҮҢдёҚиҜҰз»ҶиҜҙжҳҺ
иЎҢеӯҳеӮЁзҡ„зү№зӮ№пјҡ жҹҘиҜўж»Ўи¶іжқЎд»¶зҡ„дёҖж•ҙиЎҢж•°жҚ®зҡ„ж—¶еҖҷпјҢеҲ—еӯҳеӮЁеҲҷйңҖиҰҒеҺ»жҜҸдёӘиҒҡйӣҶзҡ„еӯ—ж®өжүҫеҲ°еҜ№еә”зҡ„жҜҸдёӘеҲ—зҡ„еҖјпјҢиЎҢеӯҳеӮЁеҸӘйңҖиҰҒжүҫеҲ°е…¶дёӯдёҖдёӘеҖјпјҢе…¶дҪҷзҡ„еҖјйғҪеңЁзӣёйӮ»ең°ж–№пјҢжүҖд»ҘжӯӨж—¶иЎҢеӯҳеӮЁжҹҘиҜўзҡ„йҖҹеәҰжӣҙеҝ«гҖӮдёҖиЎҢзҡ„ж•°жҚ®йғҪжҳҜиҝһз»ӯеӯҳеӮЁзҡ„гҖӮ
еҲ—еӯҳеӮЁзҡ„зү№зӮ№пјҡ еӣ дёәжҜҸдёӘеӯ—ж®өзҡ„ж•°жҚ®иҒҡйӣҶеӯҳеӮЁпјҢеңЁжҹҘиҜўеҸӘйңҖиҰҒе°‘ж•°еҮ дёӘеӯ—ж®өзҡ„ж—¶еҖҷпјҢиғҪеӨ§еӨ§еҮҸе°‘иҜ»еҸ–зҡ„ж•°жҚ®йҮҸпјӣжҜҸдёӘеӯ—ж®өзҡ„ж•°жҚ®зұ»еһӢдёҖе®ҡжҳҜзӣёеҗҢзҡ„пјҢеҲ—ејҸеӯҳеӮЁеҸҜд»Ҙй’ҲеҜ№жҖ§зҡ„и®ҫи®ЎжӣҙеҘҪзҡ„и®ҫи®ЎеҺӢзј©з®—жі•гҖӮ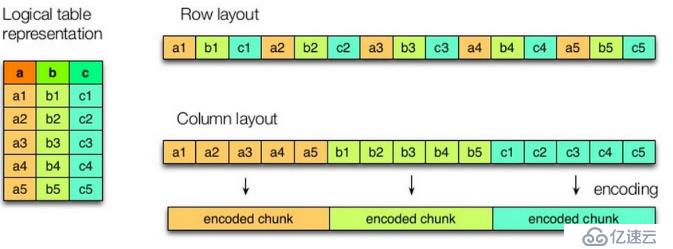
вҖӢ еӣҫ8.1 hiveд№ӢеҲ—е’ҢиЎҢеӯҳеӮЁ
иҝҷжҳҜиЎҢе’ҢеҲ—еӯҳеӮЁзҡ„жһ¶жһ„еӣҫпјҢеҸҜд»ҘжҳҺжҳҫзңӢеҲ°еҢәеҲ«
дҪҝз”Ё stored as xxx е…ій”®еӯ—жҢҮе®ҡеӯҳеӮЁж јејҸ
еҰӮпјҡ
create table log_text (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as textfile ; иҝҷйҮҢе°ұжҢҮе®ҡдёәtextfileж јејҸпјҢд№ҹжҳҜй»ҳи®Өзҡ„еӯҳеӮЁж јејҸ
з”ұдәҺй»ҳи®Өжғ…еҶөдёӢпјҢеҲ—еӯҳеӮЁйғҪдјҡйҮҮз”ЁеҺӢзј©ж–№ејҸеӯҳеӮЁпјҢиҖҢиЎҢеӯҳеӮЁеҲҷдёҚдјҡгҖӮжүҖд»ҘдёҖиҲ¬еҚ з”Ёз©әй—ҙжҺ’еҗҚдёәпјҡ
д»Һе°ҸеҲ°еӨ§жҺ’еәҸ ORC > Parquet > textFileеҲӣе»әиЎЁжҢҮе®ҡеӯҳеӮЁж јејҸд»ҘеҸҠеҺӢзј©ж–№ејҸпјҡ
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc tblproperties ("orc.compress"="SNAPPY");
е…¶дёӯtblpropertiesжҳҜз”ЁжқҘжҢҮе®ҡorc зҡ„е·ҘдҪңеҸӮж•°зҡ„пјҢйҮҢйқўжҳҜжңүkey=valueзҡ„еҪўејҸжқҘжҢҮе®ҡеҸӮж•°гҖӮorc.compress жҳҜжҢҮе®ҡorcдҪҝз”Ёзҡ„еҺӢзј©ж јејҸпјҢиҝҷйҮҢжҢҮе®ҡжҳҜз”ЁSNAPPYвҖӢ hiveеңЁз”ҹдә§зҺҜеўғдёӯдёҖиҲ¬з”ЁдәҺеӯҳеӮЁз»“жһ„еҢ–ж•°жҚ®гҖӮжҜ”еҰӮдёҖиҲ¬жғ…еҶөдёӢпјҢдјҡд»Һз”ҹдә§ж•°жҚ®еә“дёӯпјҲжҜ”еҰӮmysqlпјүдёӯе®ҡж—¶иҜ»еҸ–ж•°жҚ®еҶҷе…ҘеҲ°hiveпјҢ然еҗҺе…¶д»–зЁӢеәҸеҶҚд»ҺhiveдёӯиҜ»еҸ–ж•°жҚ®иҝӣиЎҢеҲҶжһҗеӨ„зҗҶгҖӮжүҖд»ҘhiveжҳҜе……еҪ“ж•°жҚ®д»“еә“зҡ„дҪңз”Ё
вҖӢ mysqlе’ҢhiveйғҪж”ҜжҢҒintзұ»еһӢпјҢдҪҶжҳҜдёӨиҖ…зҡ„еҸҜи§ЈжһҗиҢғеӣҙжҳҜдёҚеҗҢзҡ„пјҢmysqlдёӯзҡ„intзұ»еһӢиҜҫиЎЁзӨәзҡ„ж•°еӯ—иҢғеӣҙеӨ§дәҺhiveдёӯзҡ„intпјҢиҝҷе°ұеҜјиҮҙдёҖдёӘй—®йўҳпјҢйӮЈе°ұжҳҜеҪ“mysqlдёӯзҡ„intзҡ„еҖјеӨ§дәҺиҝҷдёӘз•Ңйҷҗж—¶пјҢе°ұж— жі•еңЁhiveдёӯжӯЈеёёи§ЈжһҗпјҢйҖҡеёёд№ҹе°ұдјҡеҜје…ҘеӨұиҙҘгҖӮ
вҖӢ жүҖд»ҘдёәдәҶйҒҝе…Қиҝҷз§Қжғ…еҶөпјҢе»әи®®еҜје…Ҙhiveдёӯзҡ„иЎЁзҡ„жүҖжңүеӯ—ж®өйғҪи®ҫзҪ®дёәstringзұ»еһӢпјҢиҝҷж ·еҸҜд»ҘйҒҝе…Қиҝҷдәӣй—®йўҳгҖӮеҪ“йңҖиҰҒе°Ҷеӯ—ж®өзұ»еһӢиҪ¬дёәе®һйҷ…зұ»еһӢж—¶пјҢеңЁдҪҝз”Ёж—¶еҶҚиҝӣиЎҢиҪ¬жҚўеҚіеҸҜ
еҪ“然иҝҷзӮ№е…¶е®һеңЁspark sqlдёӯд№ҹйҖӮз”ЁпјҢжҜ•з«ҹе®ғ们йғҪ并дёҚе®Ңе…Ёе…је®№ж ҮеҮҶзҡ„sql
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ