您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍怎么用Python进行时间序列预测,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
python的数据类型:1. 数字类型,包括int(整型)、long(长整型)和float(浮点型)。2.字符串,分别是str类型和unicode类型。3.布尔型,Python布尔类型也是用于逻辑运算,有两个值:True(真)和False(假)。4.列表,列表是Python中使用最频繁的数据类型,集合中可以放任何数据类型。5. 元组,元组用”()”标识,内部元素用逗号隔开。6. 字典,字典是一种键值对的集合。7. 集合,集合是一个无序的、不重复的数据组合。
数据准备
数据集(JetRail高铁的乘客数量)下载.
假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('train.csv')
df.head()
df.shape依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘客数量。为了解释每种方法的不同之处,以每天为单位构造和聚合了一个数据集。
从 2012 年 8 月- 2013 年 12 月的数据中构造一个数据集。
创建 train and test 文件用于建模。前 14 个月( 2012 年 8 月- 2013 年 10 月)用作训练数据,后两个月(2013 年 11 月 – 2013 年 12 月)用作测试数据。
以每天为单位聚合数据集。
import pandas as pd
import matplotlib.pyplot as plt
# Subsetting the dataset
# Index 11856 marks the end of year 2013
df = pd.read_csv('train.csv', nrows=11856)
# Creating train and test set
# Index 10392 marks the end of October 2013
train = df[0:10392]
test = df[10392:]
# Aggregating the dataset at daily level
df['Timestamp'] = pd.to_datetime(df['Datetime'], format='%d-%m-%Y %H:%M') # 4位年用Y,2位年用y
df.index = df['Timestamp']
df = df.resample('D').mean() #按天采样,计算均值
train['Timestamp'] = pd.to_datetime(train['Datetime'], format='%d-%m-%Y %H:%M')
train.index = train['Timestamp']
train = train.resample('D').mean() #
test['Timestamp'] = pd.to_datetime(test['Datetime'], format='%d-%m-%Y %H:%M')
test.index = test['Timestamp']
test = test.resample('D').mean()
#Plotting data
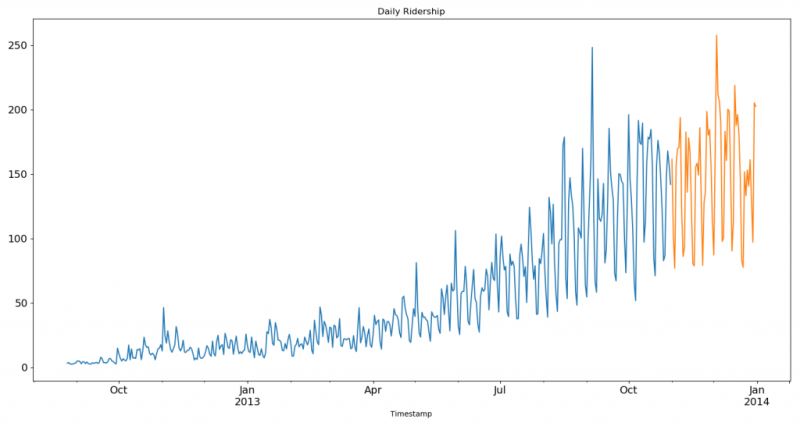
train.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
test.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
plt.show()我们将数据可视化(训练数据和测试数据一起),从而得知在一段时间内数据是如何变化的。
方法1:朴素法
假设 y 轴表示物品的价格,x 轴表示时间(天)
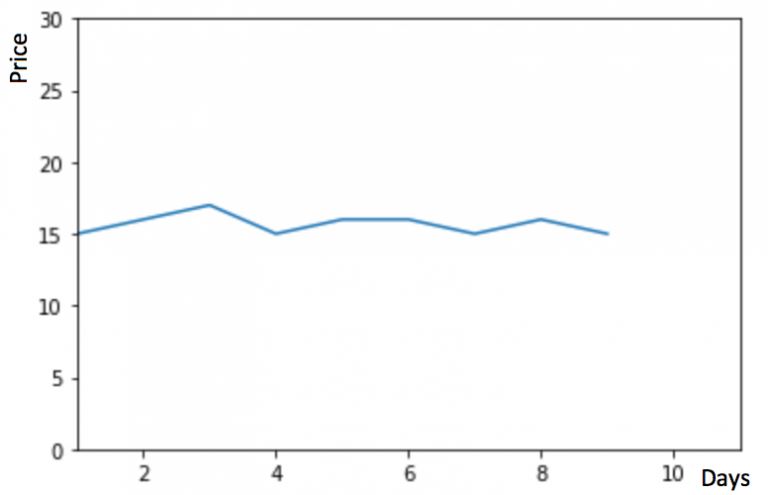
如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素法。即 $\hat{y_{t+1}} = y_t$
dd = np.asarray(train['Count'])
y_hat = test.copy()
y_hat['naive'] = dd[len(dd) - 1]
plt.figure(figsize=(12, 8))
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index, test['Count'], label='Test')
plt.plot(y_hat.index, y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()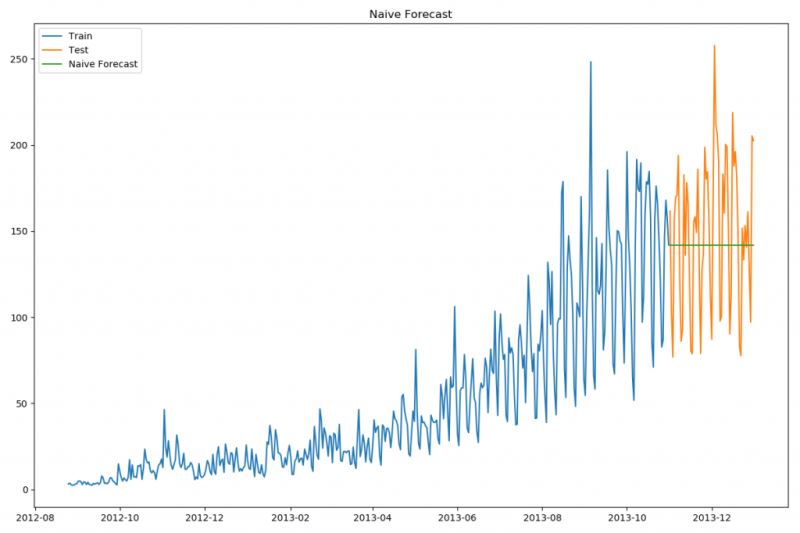
朴素法并不适合变化很大的数据集,最适合稳定性很高的数据集。我们计算下均方根误差,检查模型在测试数据集上的准确率:
from sklearn.metrics import mean_squared_error from math import sqrt rms = sqrt(mean_squared_error(test['Count'], y_hat['naive'])) print(rms)
最终均方误差RMS为:43.91640614391676
方法2:简单平均法
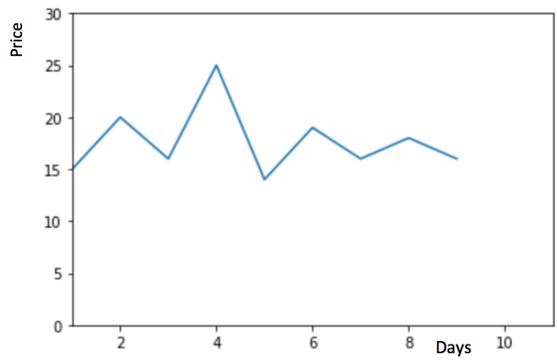
物品价格会随机上涨和下跌,平均价格会保持一致。我们经常会遇到一些数据集,虽然在一定时期内出现小幅变动,但每个时间段的平均值确实保持不变。这种情况下,我们可以预测出第二天的价格大致和过去天数的价格平均值一致。这种将预期值等同于之前所有观测点的平均值的预测方法就叫简单平均法。即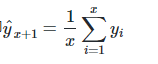
y_hat_avg = test.copy() y_hat_avg['avg_forecast'] = train['Count'].mean() plt.figure(figsize=(12,8)) plt.plot(train['Count'], label='Train') plt.plot(test['Count'], label='Test') plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast') plt.legend(loc='best') plt.show()
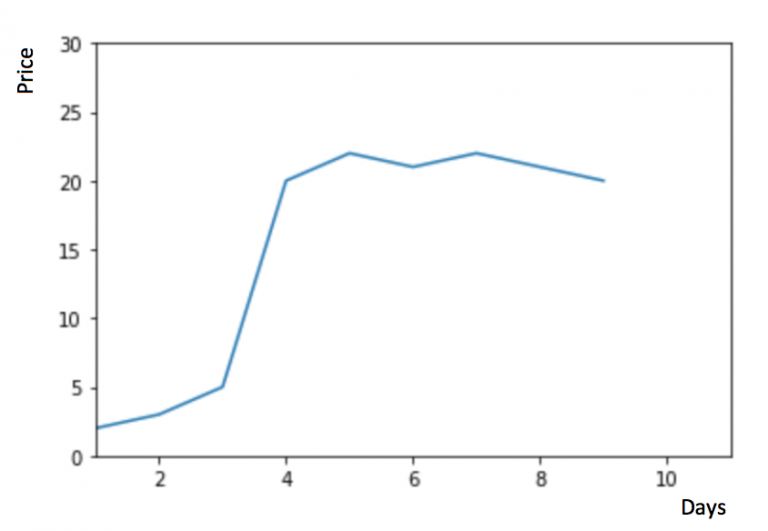
物品价格在一段时间内大幅上涨,但后来又趋于平稳。我们也经常会遇到这种数据集,比如价格或销售额某段时间大幅上升或下降。如果我们这时用之前的简单平均法,就得使用所有先前数据的平均值,但在这里使用之前的所有数据是说不通的,因为用开始阶段的价格值会大幅影响接下来日期的预测值。因此,我们只取最近几个时期的价格平均值。很明显这里的逻辑是只有最近的值最要紧。这种用某些窗口期计算平均值的预测方法就叫移动平均法。
计算移动平均值涉及到一个有时被称为“滑动窗口”的大小值p。使用简单的移动平均模型,我们可以根据之前数值的固定有限数p的平均值预测某个时序中的下一个值。这样,对于所有的 i > p:
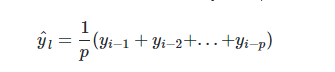
在上文移动平均法可以看到,我们对“p”中的观察值赋予了同样的权重。但是我们可能遇到一些情况,比如“p”中每个观察值会以不同的方式影响预测结果。将过去观察值赋予不同权重的方法就叫做加权移动平均法。加权移动平均法其实还是一种移动平均法,只是“滑动窗口期”内的值被赋予不同的权重,通常来讲,最近时间点的值发挥的作用更大了。即
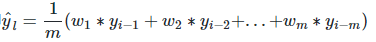
这种方法并非选择一个窗口期的值,而是需要一列权重值(相加后为1)。例如,如果我们选择[0.40, 0.25, 0.20, 0.15]作为权值,我们会为最近的4个时间点分别赋给40%,25%,20%和15%的权重。
方法4:简单指数法
我们注意到简单平均法和加权移动平均法在选取时间点的思路上存在较大的差异。我们就需要在这两种方法之间取一个折中的方法,在将所有数据考虑在内的同时也能给数据赋予不同非权重。例如,相比更早时期内的观测值,它会给近期的观测值赋予更大的权重。按照这种原则工作的方法就叫做简单指数平滑法。它通过加权平均值计算出预测值,其中权重随着观测值从早期到晚期的变化呈指数级下降,最小的权重和最早的观测值相关:
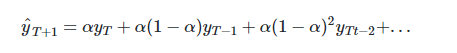
其中0≤α≤1是平滑参数。对时间点T+1的单步预测值是时序$y_1,…,y_T$的所有观测值的加权平均数。权重下降的速率由参数α控制,预测值$\hat{y}_x$是$\alpha \cdot y_t $与$(1-\alpha) \cdot \hat{y}_x$的和。
因此,它可以写为:
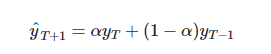
所以本质上,我们是用两个权重α和1−α得到一个加权移动平均值,让表达式呈递进形式。
from statsmodels.tsa.api import SimpleExpSmoothing y_hat_avg = test.copy() fit = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6, optimized=False) y_hat_avg['SES'] = fit.forecast(len(test)) plt.figure(figsize=(16, 8)) plt.plot(train['Count'], label='Train') plt.plot(test['Count'], label='Test') plt.plot(y_hat_avg['SES'], label='SES') plt.legend(loc='best') plt.show()
模型中使用的α值为0.6,我们可以用测试集继续调整参数以生成一个更好的模型。
方法5:霍尔特(Holt)线性趋势法
假设y轴表示某个物品的价格,x轴表示时间(天)。
如果物品的价格是不断上涨的(见上图),我们上面的方法并没有考虑这种趋势,即我们在一段时间内观察到的价格的总体模式。
每个时序数据集可以分解为相应的几个部分:趋势(Trend),季节性(Seasonal)和残差(Residual)。任何呈现某种趋势的数据集都可以用霍尔特线性趋势法用于预测。
import statsmodels.api as sm sm.tsa.seasonal_decompose(train['Count']).plot() result = sm.tsa.stattools.adfuller(train['Count']) plt.show()
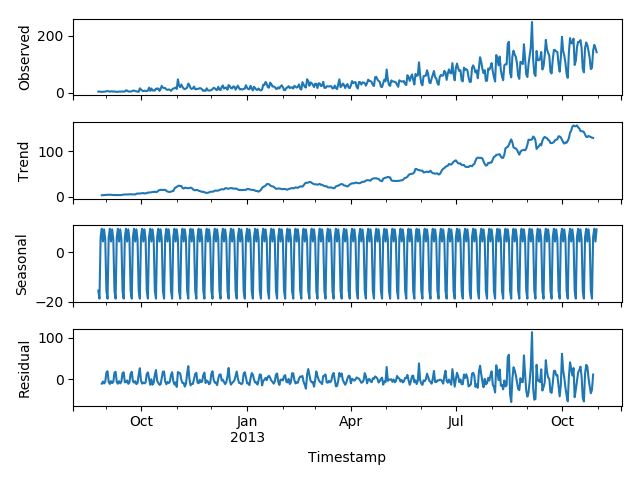
我们从图中可以看出,该数据集呈上升趋势。因此我们可以用霍尔特线性趋势法预测未来价格。该算法包含三个方程:一个水平方程,一个趋势方程,一个方程将二者相加以得到预测值$\hat{y}$:
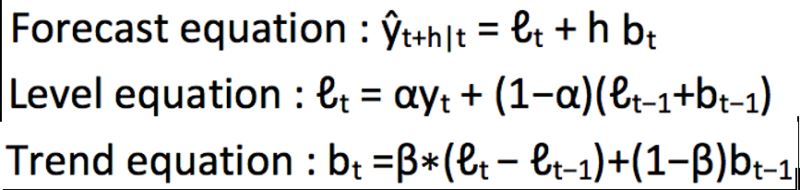
我们在上面算法中预测的值称为水平(level)。正如简单指数平滑一样,这里的水平方程显示它是观测值和样本内单步预测值的加权平均数,趋势方程显示它是根据 ℓ(t)−ℓ(t−1) 和之前的预测趋势 b(t−1) 在时间t处的预测趋势的加权平均值。
我们将这两个方程相加,得出一个预测函数。我们也可以将两者相乘而不是相加得到一个乘法预测方程。当趋势呈线性增加和下降时,我们用相加得到的方程;当趋势呈指数级增加或下降时,我们用相乘得到的方程。实践操作显示,用相乘得到的方程,预测结果会更稳定,但用相加得到的方程,更容易理解。
from statsmodels.tsa.api import Holt y_hat_avg = test.copy() fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_slope=0.1) y_hat_avg['Holt_linear'] = fit.forecast(len(test)) plt.figure(figsize=(16, 8)) plt.plot(train['Count'], label='Train') plt.plot(test['Count'], label='Test') plt.plot(y_hat_avg['Holt_linear'], label='Holt_linear') plt.legend(loc='best') plt.show()
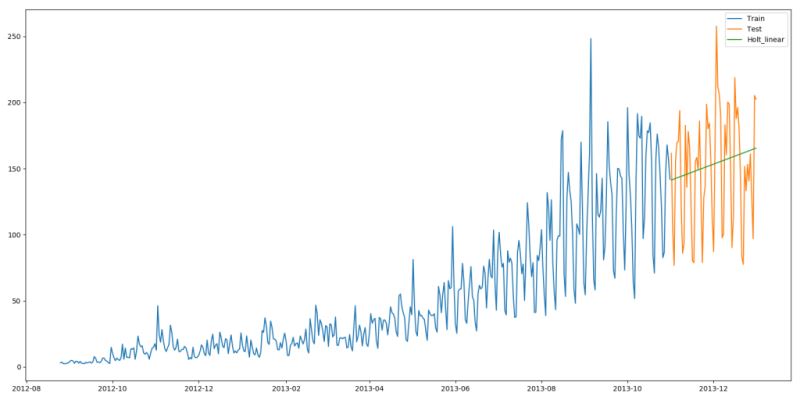
这种方法能够准确地显示出趋势,因此比前面的几种模型效果更好。如果调整一下参数,结果会更好。
方法6:Holt-Winters季节性预测模型
在应用这种算法前,我们先介绍一个新术语。假如有家酒店坐落在半山腰上,夏季的时候生意很好,顾客很多,但每年其余时间顾客很少。因此,每年夏季的收入会远高于其它季节,而且每年都是这样,那么这种重复现象叫做“季节性”(Seasonality)。如果数据集在一定时间段内的固定区间内呈现相似的模式,那么该数据集就具有季节性。

我们之前讨论的5种模型在预测时并没有考虑到数据集的季节性,因此我们需要一种能考虑这种因素的方法。应用到这种情况下的算法就叫做Holt-Winters季节性预测模型,它是一种三次指数平滑预测,其背后的理念就是除了水平和趋势外,还将指数平滑应用到季节分量上。
Holt-Winters季节性预测模型由预测函数和三次平滑函数——一个是水平函数ℓt,一个是趋势函数bt,一个是季节分量 st,以及平滑参数α,β和γ。
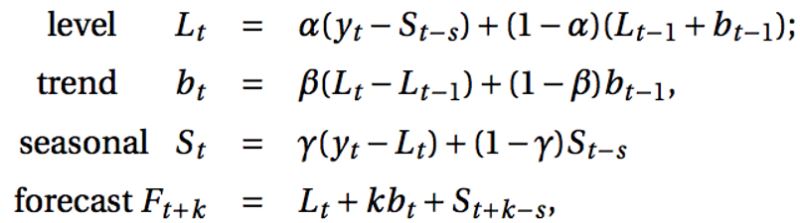
其中 s 为季节循环的长度,0≤α≤ 1, 0 ≤β≤ 1 , 0≤γ≤ 1。水平函数为季节性调整的观测值和时间点t处非季节预测之间的加权平均值。趋势函数和霍尔特线性方法中的含义相同。季节函数为当前季节指数和去年同一季节的季节性指数之间的加权平均值。在本算法,我们同样可以用相加和相乘的方法。当季节性变化大致相同时,优先选择相加方法,而当季节变化的幅度与各时间段的水平成正比时,优先选择相乘的方法。
from statsmodels.tsa.api import ExponentialSmoothing y_hat_avg = test.copy() fit1 = ExponentialSmoothing(np.asarray(train['Count']), seasonal_periods=7, trend='add', seasonal='add', ).fit() y_hat_avg['Holt_Winter'] = fit1.forecast(len(test)) plt.figure(figsize=(16, 8)) plt.plot(train['Count'], label='Train') plt.plot(test['Count'], label='Test') plt.plot(y_hat_avg['Holt_Winter'], label='Holt_Winter') plt.legend(loc='best') plt.show()
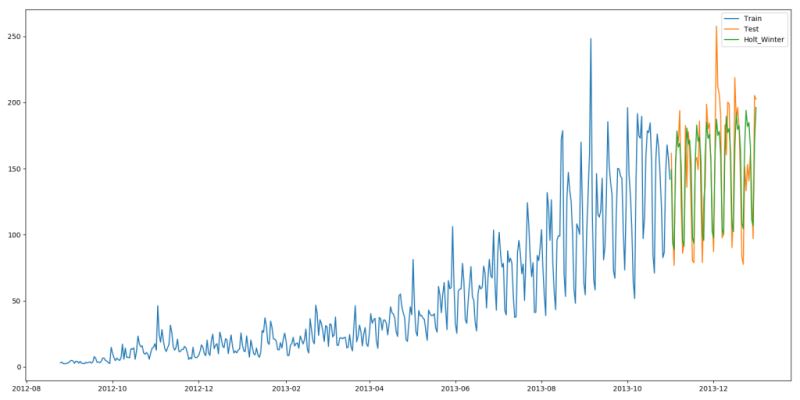
我们可以看到趋势和季节性的预测准确度都很高。我们选择了 seasonal_period = 7作为每周重复的数据。也可以调整其它其它参数,我在搭建这个模型的时候用的是默认参数。你可以试着调整参数来优化模型。
方法7:自回归移动平均模型(ARIMA)
另一个场景的时序模型是自回归移动平均模型(ARIMA)。指数平滑模型都是基于数据中的趋势和季节性的描述,而自回归移动平均模型的目标是描述数据中彼此之间的关系。ARIMA的一个优化版就是季节性ARIMA。它像Holt-Winters季节性预测模型一样,也把数据集的季节性考虑在内。
import statsmodels.api as sm y_hat_avg = test.copy() fit1 = sm.tsa.statespace.SARIMAX(train.Count, order=(2, 1, 4), seasonal_order=(0, 1, 1, 7)).fit() y_hat_avg['SARIMA'] = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True) plt.figure(figsize=(16, 8)) plt.plot(train['Count'], label='Train') plt.plot(test['Count'], label='Test') plt.plot(y_hat_avg['SARIMA'], label='SARIMA') plt.legend(loc='best') plt.show()
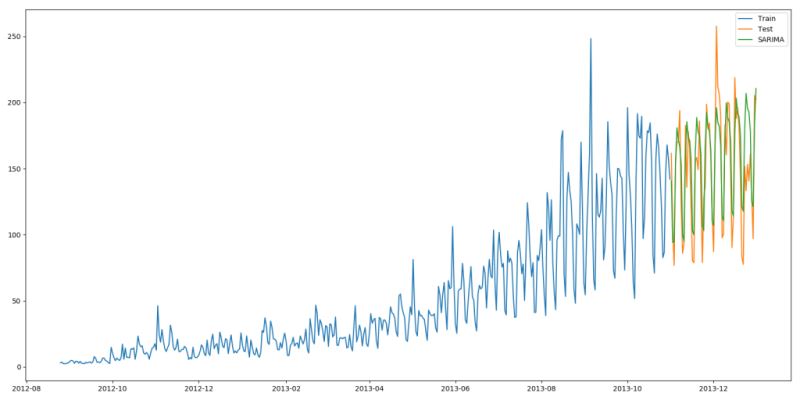
我们可以看到使用季节性 ARIMA 的效果和Holt-Winters差不多。我们根据 ACF(自相关函数)和 PACF(偏自相关) 图选择参数。如果你为 ARIMA 模型选择参数时遇到了困难,可以用 R 语言中的 auto.arima。
最后,我们将这几种模型的准确度比较一下:
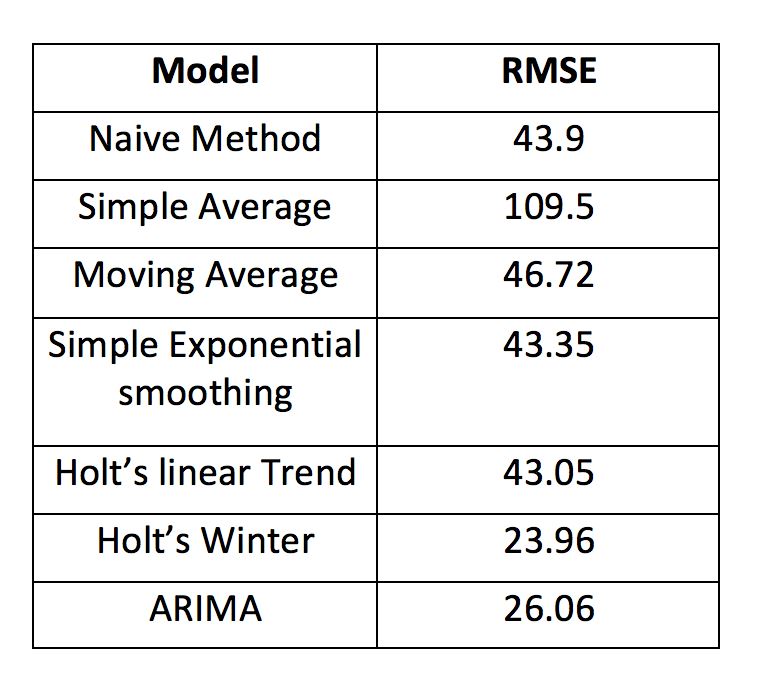
以上是“怎么用Python进行时间序列预测”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。