您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“怎么用Python预测房价走势”,在日常操作中,相信很多人在怎么用Python预测房价走势问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么用Python预测房价走势”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并对模型的性能和预测能力进行测试;
数据集字段解释:
鸿蒙官方战略合作共建——HarmonyOS技术社区
RM: 住宅平均房间数量;
LSTAT: 区域中被认为是低收入阶层的比率;
PTRATIO: 镇上学生与教师数量比例;
MEDV: 房屋的中值价格(目标特征,即我们要预测的值);
其实现在回过头来看,前三个特征应该都是挖掘后的组合特征,比如RM,通常在原始数据中会分为多个特征:一楼房间、二楼房间、厨房、卧室个数、地下室房间等等,这里应该是为了教学简单化了;
MEDV为我们要预测的值,属于回归问题,另外数据集不大(不到500个数据点),小数据集上的回归问题,现在的我初步考虑会用SVM,稍后让我们看看当时的选择;
Step 1 导入数据
注意点:
鸿蒙官方战略合作共建——HarmonyOS技术社区
如果数据在多个csv中(比如很多销售项目中,销售数据和店铺数据是分开两个csv的,类似数据库的两张表),这里一般要连接起来;
训练数据和测试数据连接起来,这是为了后续的数据处理的一致,否则训练模型时会有问题(比如用训练数据训练的模型,预测测试数据时报错维度不一致);
观察下数据量,数据量对于后续选择算法、可视化方法等有比较大的影响,所以一般会看一下;
pandas内存优化,这一点项目中目前没有,但是我最近的项目有用到,简单说一下,通过对特征字段的数据类型向下转换(比如int64转为int8)降低对内存的使用,这里很重要,数据量大时很容易撑爆个人电脑的内存存储;
上代码:
# 载入波士顿房屋的数据集 data = pd.read_csv('housing.csv') prices = data['MEDV'] features = data.drop('MEDV', axis =1) # 完成 print"Boston housing dataset has {} data points with {} variables each.".format(*data.shape)Step 2 分析数据
加载数据后,不要直接就急匆匆的上各种处理手段,加各种模型,先慢一点,对数据进行一个初步的了解,了解其各个特征的统计值、分布情况、与目标特征的关系,最好进行可视化,这样会看到很多意料之外的东西;
基础统计运算
统计运算用于了解某个特征的整体取值情况,它的最大最小值,平均值中位数,百分位数等等,这些都是最简单的对一个字段进行了解的手段;
上代码:
#目标:计算价值的最小值 minimum_price = np.min(prices)# prices.min #目标:计算价值的最大值 maximum_price = np.max(prices)# prices.max #目标:计算价值的平均值 mean_price = np.mean(prices)# prices.mean #目标:计算价值的中值 median_price = np.median(prices)# prices.median #目标:计算价值的标准差 std_price = np.std(prices)# prices.std
特征观察
这里主要考虑各个特征与目标之间的关系,比如是正相关还是负相关,通常都是通过对业务的了解而来的,这里就延伸出一个点,机器学习项目通常来说,对业务越了解,越容易得到好的效果,因为所谓的特征工程其实就是理解业务、深挖业务的过程;
比如这个问题中的三个特征:
RM:房间个数明显应该是与房价正相关的;
LSTAT:低收入比例一定程度上表示着这个社区的级别,因此应该是负相关;
PTRATIO:学生/教师比例越高,说明教育资源越紧缺,也应该是负相关;
上述这三个点,同样可以通过可视化的方式来验证,事实上也应该去验证而不是只靠主观猜想,有些情况下,主观感觉与客观事实是完全相反的,这里要注意;
Step 3 数据划分
为了验证模型的好坏,通常的做法是进行cv,即交叉验证,基本思路是将数据平均划分N块,取其中N-1块训练,并对另外1块做预测,并比对预测结果与实际结果,这个过程反复N次直到每一块都作为验证数据使用过;
上代码:
# 提示:导入train_test_split fromsklearn.model_selectionimporttrain_test_split X_train, X_test, y_train, y_test = train_test_split(features, prices, test_size=0.2, random_state=RANDOM_STATE) printX_train.shape printX_test.shape printy_train.shape printy_test.shape
Step 4 定义评价函数
这里主要是根据问题来定义,比如分类问题用的最多的是准确率(精确率、召回率也有使用,具体看业务场景中更重视什么),回归问题用RMSE(均方误差)等等,实际项目中根据业务特点经常会有需要去自定义评价函数的时候,这里就比较灵活;
Step 5 模型调优
通过GridSearch对模型参数进行网格组合搜索最优,注意这里要考虑数据量以及组合后的可能个数,避免运行时间过长哈。
上代码:
fromsklearn.model_selectionimportKFold,GridSearchCV fromsklearn.treeimportDecisionTreeRegressor fromsklearn.metricsimportmake_scorer deffit_model(X, y): """ 基于输入数据 [X,y],利于网格搜索找到最优的决策树模型""" cross_validator = KFold regressor = DecisionTreeRegressor params = {'max_depth':[1,2,3,4,5,6,7,8,9,10]} scoring_fnc = make_scorer(performance_metric) grid = GridSearchCV(estimator=regressor, param_grid=params, scoring=scoring_fnc, cv=cross_validator) # 基于输入数据 [X,y],进行网格搜索 grid = grid.fit(X, y) # 返回网格搜索后的最优模型 returngrid.best_estimator_可以看到当时项目中选择的是决策树模型,现在看,树模型在这种小数据集上其实是比较容易过拟合的,因此可以考虑用SVM代替,你也可以试试哈,我估计是SVM效果比较好;
学习曲线
通过绘制分析学习曲线,可以对模型当前状态有一个基本了解,如下图:
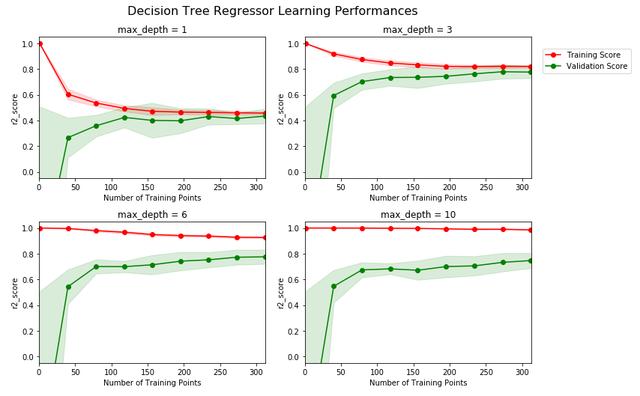
可以看到,超参数max_depth为1和3时,明显训练分数过低,这说明此时模型有欠拟合的情况,而当max_depth为6和10时,明显训练分数和验证分析差距过大,说明出现了过拟合,因此我们初步可以猜测,优质参数在3和6之间,即4,5中的一个,其他参数一样可以通过学习曲线来进行可视化分析,判断是欠拟合还是过拟合,再分别进行针对处理;
到此,关于“怎么用Python预测房价走势”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。