您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
使用Python爬虫库requests多线程抓取猫眼电影TOP100思路:
按F12查看网页源代码发现每一个电影的信息都在“<dd></dd>”标签之中。
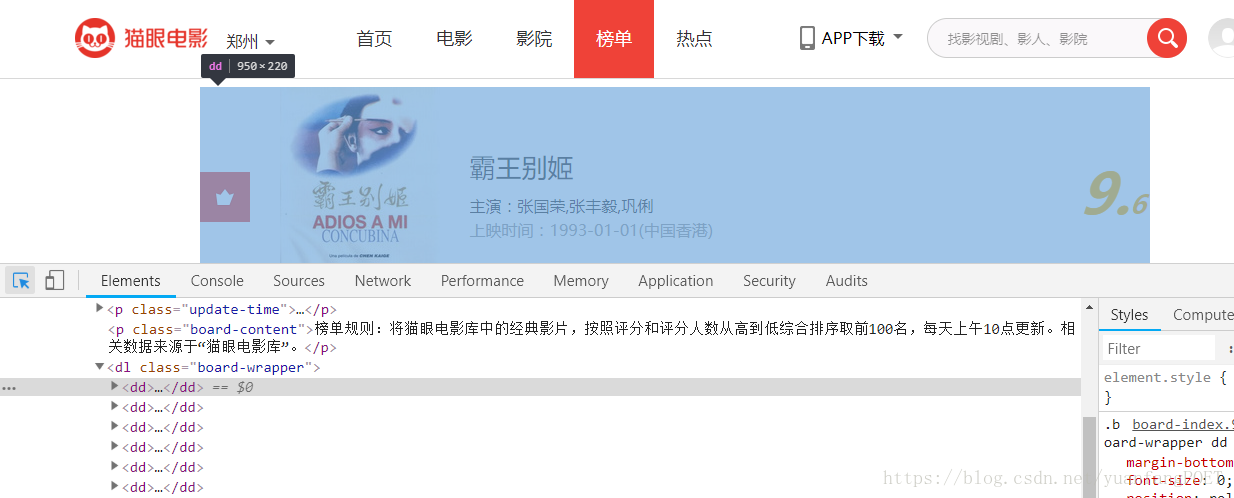
点开之后,信息如下:
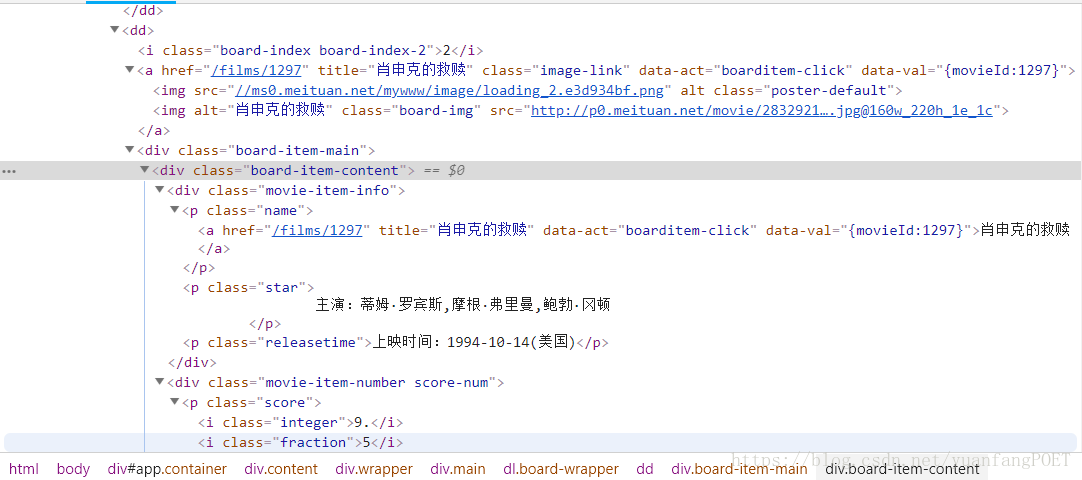
在浏览器中打开猫眼电影网站,点击“榜单”,再点击“TOP100榜”如下图:
接下来通过以下代码获取网页源代码:
#-*-coding:utf-8-*-
import requests
from requests.exceptions import RequestException
#猫眼电影网站有反爬虫措施,设置headers后可以爬取
headers = {
'Content-Type': 'text/plain; charset=UTF-8',
'Origin':'https://maoyan.com',
'Referer':'https://maoyan.com/board/4',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#爬取网页源代码
def get_one_page(url,headers):
try:
response =requests.get(url,headers =headers)
if response.status_code == 200:
return response.text
return None
except RequestsException:
return None
def main():
url = "https://maoyan.com/board/4"
html = get_one_page(url,headers)
print(html)
if __name__ == '__main__':
main()
执行结果如下:
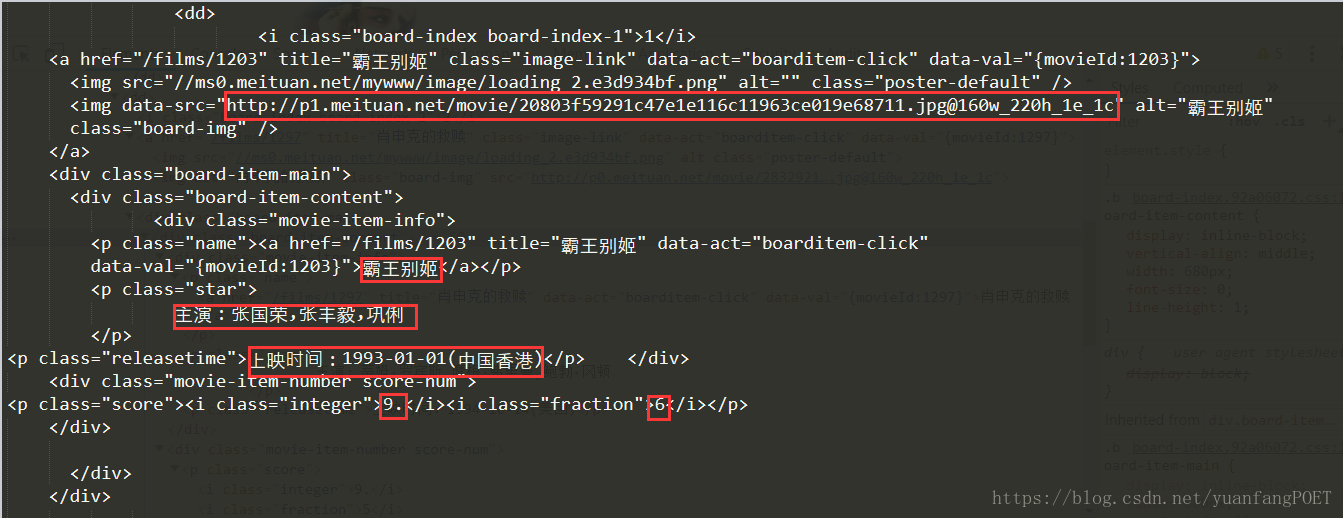
上图标示信息即为要提取的信息,代码实现如下:
#-*-coding:utf-8-*-
import requests
import re
from requests.exceptions import RequestException
#猫眼电影网站有反爬虫措施,设置headers后可以爬取
headers = {
'Content-Type': 'text/plain; charset=UTF-8',
'Origin':'https://maoyan.com',
'Referer':'https://maoyan.com/board/4',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#爬取网页源代码
def get_one_page(url,headers):
try:
response =requests.get(url,headers =headers)
if response.status_code == 200:
return response.text
return None
except RequestsException:
return None
#正则表达式提取信息
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'index':item[0],
'image':item[1],
'title':item[2],
'actor':item[3].strip()[3:],
'time':item[4].strip()[5:],
'score':item[5]+item[6]
}
def main():
url = "https://maoyan.com/board/4"
html = get_one_page(url,headers)
for item in parse_one_page(html):
print(item)
if __name__ == '__main__':
main()
执行结果如下:
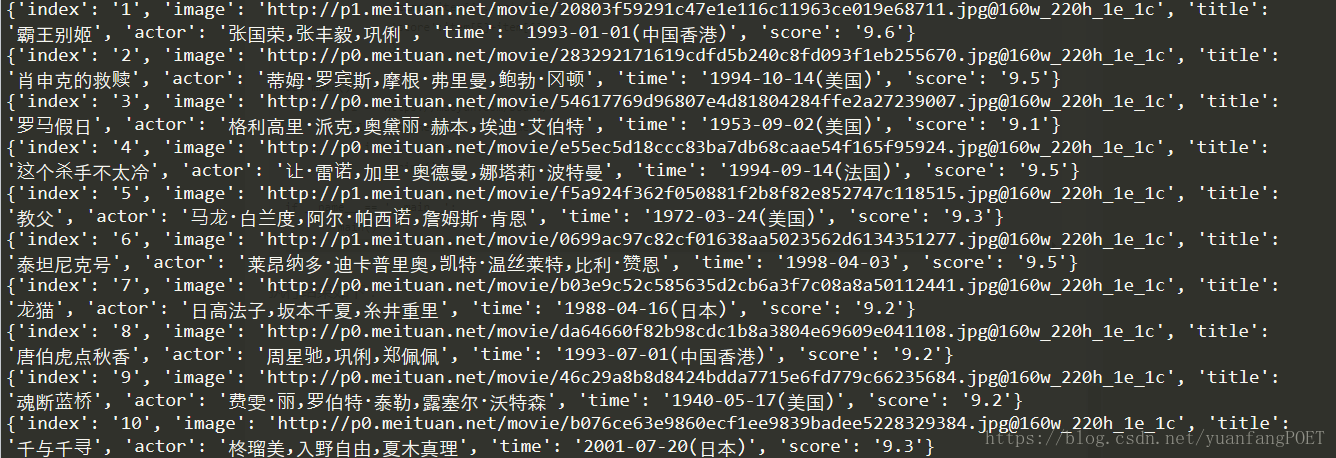
上边代码实现单页的信息抓取,要想爬取100个电影的信息,先观察每一页url的变化,点开每一页我们会发现url进行变化,原url后面多了‘?offset=0',且offset的值变化从0,10,20,变化如下:
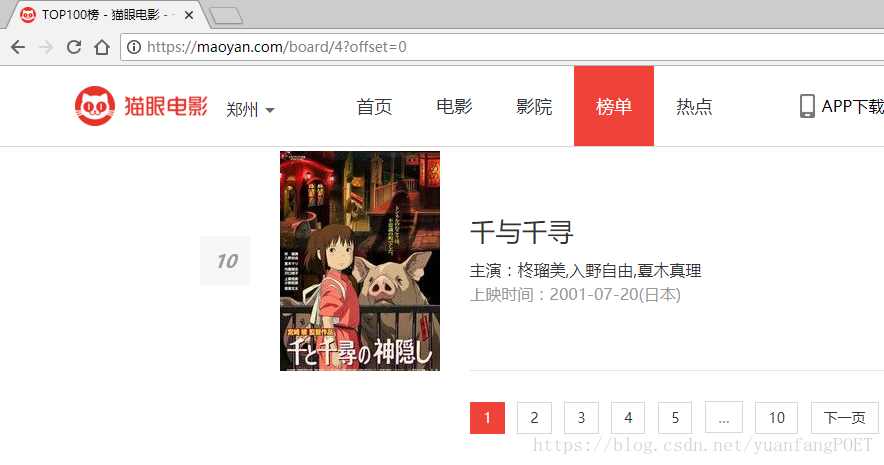
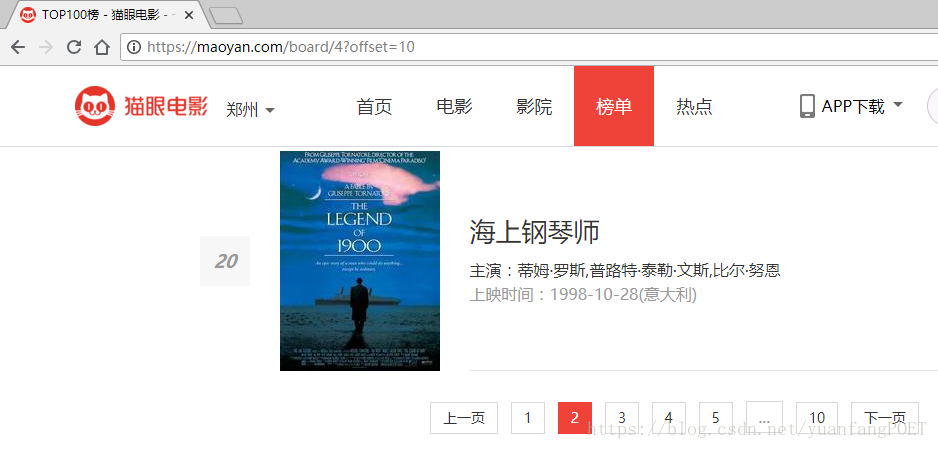
代码实现如下:
#-*-coding:utf-8-*-
import requests
import re
import json
import os
from requests.exceptions import RequestException
#猫眼电影网站有反爬虫措施,设置headers后可以爬取
headers = {
'Content-Type': 'text/plain; charset=UTF-8',
'Origin':'https://maoyan.com',
'Referer':'https://maoyan.com/board/4',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#爬取网页源代码
def get_one_page(url,headers):
try:
response =requests.get(url,headers =headers)
if response.status_code == 200:
return response.text
return None
except RequestsException:
return None
#正则表达式提取信息
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'index':item[0],
'image':item[1],
'title':item[2],
'actor':item[3].strip()[3:],
'time':item[4].strip()[5:],
'score':item[5]+item[6]
}
#猫眼TOP100所有信息写入文件
def write_to_file(content):
#encoding ='utf-8',ensure_ascii =False,使写入文件的代码显示为中文
with open('result.txt','a',encoding ='utf-8') as f:
f.write(json.dumps(content,ensure_ascii =False)+'\n')
f.close()
#下载电影封面
def save_image_file(url,path):
jd = requests.get(url)
if jd.status_code == 200:
with open(path,'wb') as f:
f.write(jd.content)
f.close()
def main(offset):
url = "https://maoyan.com/board/4?offset="+str(offset)
html = get_one_page(url,headers)
if not os.path.exists('covers'):
os.mkdir('covers')
for item in parse_one_page(html):
print(item)
write_to_file(item)
save_image_file(item['image'],'covers/'+item['title']+'.jpg')
if __name__ == '__main__':
#对每一页信息进行爬取
for i in range(10):
main(i*10)
爬取结果如下:
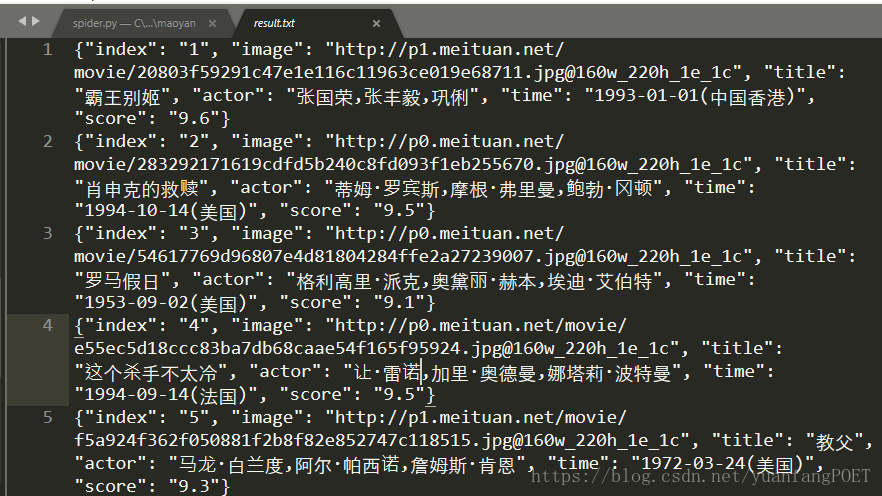
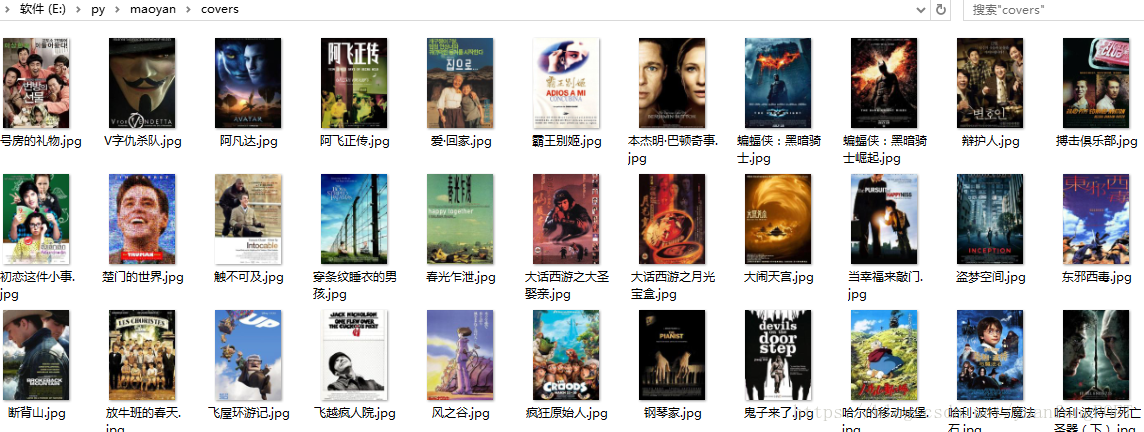
进行比较,发现多线程爬取时间明显较快:

多线程:

以下为完整代码:
#-*-coding:utf-8-*-
import requests
import re
import json
import os
from requests.exceptions import RequestException
from multiprocessing import Pool
#猫眼电影网站有反爬虫措施,设置headers后可以爬取
headers = {
'Content-Type': 'text/plain; charset=UTF-8',
'Origin':'https://maoyan.com',
'Referer':'https://maoyan.com/board/4',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#爬取网页源代码
def get_one_page(url,headers):
try:
response =requests.get(url,headers =headers)
if response.status_code == 200:
return response.text
return None
except RequestsException:
return None
#正则表达式提取信息
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'index':item[0],
'image':item[1],
'title':item[2],
'actor':item[3].strip()[3:],
'time':item[4].strip()[5:],
'score':item[5]+item[6]
}
#猫眼TOP100所有信息写入文件
def write_to_file(content):
#encoding ='utf-8',ensure_ascii =False,使写入文件的代码显示为中文
with open('result.txt','a',encoding ='utf-8') as f:
f.write(json.dumps(content,ensure_ascii =False)+'\n')
f.close()
#下载电影封面
def save_image_file(url,path):
jd = requests.get(url)
if jd.status_code == 200:
with open(path,'wb') as f:
f.write(jd.content)
f.close()
def main(offset):
url = "https://maoyan.com/board/4?offset="+str(offset)
html = get_one_page(url,headers)
if not os.path.exists('covers'):
os.mkdir('covers')
for item in parse_one_page(html):
print(item)
write_to_file(item)
save_image_file(item['image'],'covers/'+item['title']+'.jpg')
if __name__ == '__main__':
#对每一页信息进行爬取
pool = Pool()
pool.map(main,[i*10 for i in range(10)])
pool.close()
pool.join()
本文主要讲解了使用Python爬虫库requests多线程抓取猫眼电影TOP100数据的实例,更多关于Python爬虫库的知识请查看下面的相关链接
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。