您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下如何利用python实现逐步回归,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
逐步回归的基本思想是将变量逐个引入模型,每引入一个解释变量后都要进行F检验,并对已经选入的解释变量逐个进行t检验,当原来引入的解释变量由于后面解释变量的引入变得不再显著时,则将其删除。以确保每次引入新的变量之前回归方程中只包含显著性变量。这是一个反复的过程,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止。以保证最后所得到的解释变量集是最优的。
本例的逐步回归则有所变化,没有对已经引入的变量进行t检验,只判断变量是否引入和变量是否剔除,“双重检验”逐步回归,简称逐步回归。例子的链接:(原链接已经失效),4项自变量,1项因变量。下文不再进行数学推理,进对计算过程进行说明,对数学理论不明白的可以参考《现代中长期水文预报方法及其应用》汤成友,官学文,张世明著;论文《逐步回归模型在大坝预测中的应用》王晓蕾等;
逐步回归的计算步骤:
1.计算第零步增广矩阵。第零步增广矩阵是由预测因子和预测对象两两之间的相关系数构成的。
2.引进因子。在增广矩阵的基础上,计算每个因子的方差贡献,挑选出没有进入方程的因子中方差贡献最大者对应的因子,计算该因子的方差比,查F分布表确定该因子是否引入方程。
3.剔除因子。计算此时方程中已经引入的因子的方差贡献,挑选出方差贡献最小的因子,计算该因子的方差比,查F分布表确定该因子是否从方程中剔除。
4.矩阵变换。将第零步矩阵按照引入方程的因子序号进行矩阵变换,变换后的矩阵再次进行引进因子和剔除因子的步骤,直到无因子可以引进,也无因子可以剔除为止,终止逐步回归分析计算。
a.以下代码实现了数据的读取,相关系数的计算子程序和生成第零步增广矩阵的子程序。
注意:pandas库读取csv的数据结构为DataFrame结构,此处转化为numpy中的(n-dimension array,ndarray)数组进行计算
import numpy as np
import pandas as pd
#数据读取
#利用pandas读取csv,读取的数据为DataFrame对象
data = pd.read_csv('sn.csv')
# 将DataFrame对象转化为数组,数组的最后一列为预报对象
data= data.values.copy()
# print(data)
# 计算回归系数,参数
def get_regre_coef(X,Y):
S_xy=0
S_xx=0
S_yy=0
# 计算预报因子和预报对象的均值
X_mean = np.mean(X)
Y_mean = np.mean(Y)
for i in range(len(X)):
S_xy += (X[i] - X_mean) * (Y[i] - Y_mean)
S_xx += pow(X[i] - X_mean, 2)
S_yy += pow(Y[i] - Y_mean, 2)
return S_xy/pow(S_xx*S_yy,0.5)
#构建原始增广矩阵
def get_original_matrix():
# 创建一个数组存储相关系数,data.shape几行(维)几列,结果用一个tuple表示
# print(data.shape[1])
col=data.shape[1]
# print(col)
r=np.ones((col,col))#np.ones参数为一个元组(tuple)
# print(np.ones((col,col)))
# for row in data.T:#运用数组的迭代,只能迭代行,迭代转置后的数组,结果再进行转置就相当于迭代了每一列
# print(row.T)
for i in range(col):
for j in range(col):
r[i,j]=get_regre_coef(data[:,i],data[:,j])
return rb.第二部分主要是计算公差贡献和方差比。
def get_vari_contri(r): col = data.shape[1] #创建一个矩阵来存储方差贡献值 v=np.ones((1,col-1)) # print(v) for i in range(col-1): # v[0,i]=pow(r[i,col-1],2)/r[i,i] v[0, i] = pow(r[i, col - 1], 2) / r[i, i] return v #选择因子是否进入方程, #参数说明:r为增广矩阵,v为方差贡献值,k为方差贡献值最大的因子下标,p为当前进入方程的因子数 def select_factor(r,v,k,p): row=data.shape[0]#样本容量 col=data.shape[1]-1#预报因子数 #计算方差比 f=(row-p-2)*v[0,k-1]/(r[col,col]-v[0,k-1]) # print(calc_vari_contri(r)) return f
c.第三部分调用定义的函数计算方差贡献值
#计算第零步增广矩阵 r=get_original_matrix() # print(r) #计算方差贡献值 v=get_vari_contri(r) print(v) #计算方差比
计算结果: 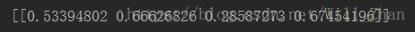
此处没有编写判断方差贡献最大的子程序,因为在其他计算中我还需要变量的具体物理含义所以不能单纯的由计算决定对变量的取舍,此处看出第四个变量的方查贡献最大
# #计算方差比 # print(data.shape[0]) f=select_factor(r,v,4,0) print(f) #######输出########## 22.79852020138227
计算第四个预测因子的方差比(粘贴在了代码中),并查F分布表3.280进行比对,22.8>3.28,引入第四个预报因子。(前三次不进行剔除椅子的计算)
d.第四部分进行矩阵的变换。
#逐步回归分析与计算 #通过矩阵转换公式来计算各部分增广矩阵的元素值 def convert_matrix(r,k): col=data.shape[1] k=k-1#从第零行开始计数 #第k行的元素单不属于k列的元素 r1 = np.ones((col, col)) # np.ones参数为一个元组(tuple) for i in range(col): for j in range(col): if (i==k and j!=k): r1[i,j]=r[k,j]/r[k,k] elif (i!=k and j!=k): r1[i,j]=r[i,j]-r[i,k]*r[k,j]/r[k,k] elif (i!= k and j== k): r1[i,j] = -r[i,k]/r[k,k] else: r1[i,j] = 1/r[k,k] return r1
e.进行完矩阵变换就循环上面步骤进行因子的引入和剔除
再次计算各因子的方差贡献 
前三个未引入方程的方差因子进行排序,得到第一个因子的方差贡献最大,计算第一个预报因子的F检验值,大于临界值引入第一个预报因子进入方程。
#矩阵转换,计算第一步矩阵 r=convert_matrix(r,4) # print(r) #计算第一步方差贡献值 v=get_vari_contri(r) #print(v) f=select_factor(r,v,1,1) print(f) #########输出##### 108.22390933074443
进行矩阵变换,计算方差贡献 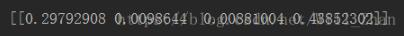
可以看出还没有引入方程的因子2和3,方差贡献较大的是因子2,计算因子2的f检验值5.026>3.28,故引入预报因子2
f=select_factor(r,v,2,2) print(f) ##########输出######### 5.025864648951804
继续进行矩阵转换,计算方差贡献 
这一步需要考虑剔除因子了,有方差贡献可以知道,已引入方程的因子中方差贡献最小的是因子4,分别计算因子3的引进f检验值0.0183
和因子4的剔除f检验值1.863,均小于3.28(查F分布表)因子3不能引入,因子4需要剔除,此时方程中引入的因子数为2
#选择是否剔除因子, #参数说明:r为增广矩阵,v为方差贡献值,k为方差贡献值最大的因子下标,t为当前进入方程的因子数 def delete_factor(r,v,k,t): row = data.shape[0] # 样本容量 col = data.shape[1] - 1 # 预报因子数 # 计算方差比 f = (row - t - 1) * v[0, k - 1] / r[col, col] # print(calc_vari_contri(r)) return f #因子3的引进检验值0.018233473487350636 f=select_factor(r,v,3,3) print(f) #因子4的剔除检验值1.863262422188088 f=delete_factor(r,v,4,3) print(f)
在此对矩阵进行变换,计算方差贡献 ,已引入因子(因子1和2)方差贡献最小的是因子1,为引入因子方差贡献最大的是因子4,计算这两者的引进f检验值和剔除f检验值
,已引入因子(因子1和2)方差贡献最小的是因子1,为引入因子方差贡献最大的是因子4,计算这两者的引进f检验值和剔除f检验值
#因子4的引进检验值1.8632624221880876,小于3.28不能引进 f=select_factor(r,v,4,2) print(f) #因子1的剔除检验值146.52265486251397,大于3.28不能剔除 f=delete_factor(r,v,1,2) print(f)
不能剔除也不能引进变量,此时停止逐步回归的计算。引进方程的因子为预报因子1和预报因子2,借助上一篇博客写的多元回归。对进入方程的预报因子和预报对象进行多元回归。输出多元回归的预测结果,一次为常数项,第一个因子的预测系数,第二个因子的预测系数。
#因子1和因子2进入方程 #对进入方程的预报因子进行多元回归 # regs=LinearRegression() X=data[:,0:2] Y=data[:,4] X=np.mat(np.c_[np.ones(X.shape[0]),X])#为系数矩阵增加常数项系数 Y=np.mat(Y)#数组转化为矩阵 #print(X) B=np.linalg.inv(X.T*X)*(X.T)*(Y.T) print(B.T)#输出系数,第一项为常数项,其他为回归系数 ###输出## #[[52.57734888 1.46830574 0.66225049]]
以上是“如何利用python实现逐步回归”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。