您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
在看过很多博客的时候发现了一个用法self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size)),首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。
使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
出现这个函数的地方
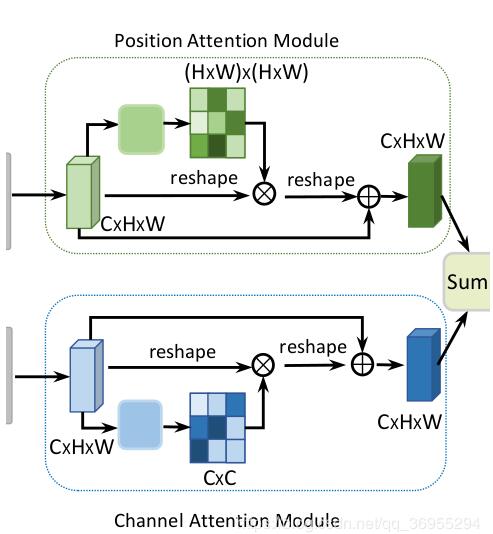
在concat注意力机制中,权值V是不断学习的所以要是parameter类型,不直接使用一个torch.nn.Linear()可能是因为学习的效果不好。
通过做下面的实验发现,linear里面的weight和bias就是parameter类型,且不能够使用tensor类型替换,还有linear里面的weight甚至可能通过指定一个不同于初始化时候的形状进行模型的更改。

self.gamma被绑定到模型中了,所以可以在训练的时候优化
以上这篇PyTorch里面的torch.nn.Parameter()详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。