жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶPythonзҲ¬иҷ«зҲ¬еҸ–з…ҺиӣӢзҪ‘еӣҫзүҮд»Јз Ғе®һдҫӢ,ж–ҮдёӯйҖҡиҝҮзӨәдҫӢд»Јз Ғд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢеҜ№еӨ§е®¶зҡ„еӯҰд№ жҲ–иҖ…е·ҘдҪңе…·жңүдёҖе®ҡзҡ„еҸӮиҖғеӯҰд№ д»·еҖј,йңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ
д»ҠеӨ©пјҢиҜ•зқҖзҲ¬еҸ–дәҶз…ҺиӣӢзҪ‘зҡ„еӣҫзүҮгҖӮ
з”ЁеҲ°зҡ„еҢ…пјҡ
еҲҶеҲ«дҪҝз”ЁеҮ дёӘеҮҪж•°пјҢжқҘжҺ§еҲ¶дёӢиҪҪзҡ„еӣҫзүҮзҡ„йЎөж•°пјҢиҺ·еҸ–еӣҫзүҮзҡ„зҪ‘йЎөпјҢиҺ·еҸ–зҪ‘йЎөйЎөж•°д»ҘеҸҠдҝқеӯҳеӣҫзүҮеҲ°жң¬ең°гҖӮиҝҮзЁӢз®ҖеҚ•жё…жҷ°жҳҺдәҶ
зӣҙжҺҘдёҠжәҗд»Јз Ғпјҡ
import urllib.request
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read()
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page')+23
b = html.find(']',a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg',a ,a+255)
if b != -1:
img_addrs.append('https:'+html[a+9:b+4]) # 'img src='дёә9дёӘеҒҸ移 '.jpg'дёә4дёӘеҒҸ移
else:
b = a+9
a = html.find('img src=', b)
return img_addrs
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename, 'wb') as f:
img = url_open(each)
f.write(img)
print(img_addrs)
def download_mm(folder = 'xxoo', pages = 5):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + 'page-'+ str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
download_mm()
е…¶дёӯеңЁдё»еҮҪж•°download_mm()дёӯпјҢе°Ҷpagesи®ҫзҪ®еңЁдәҶ5йқўгҖӮ
жң¬жқҘи®ҫзҪ®зҡ„жҳҜ10пјҢдҪҶжҳҜеңЁзЁӢеәҸжү§иЎҢзҡ„иҝҮзЁӢдёӯгҖӮеҮәзҺ°дәҶ404ERRORй”ҷиҜҜ
еҚіimgae_urlеҮәзҺ°дәҶй”ҷиҜҜгҖӮе°қиҜ•зқҖеңЁsave_img()еҮҪж•°дёӯеҠ е…ҘдәҶжөӢиҜ•д»Јз Ғпјҡprint(img_addrs)пјҢ
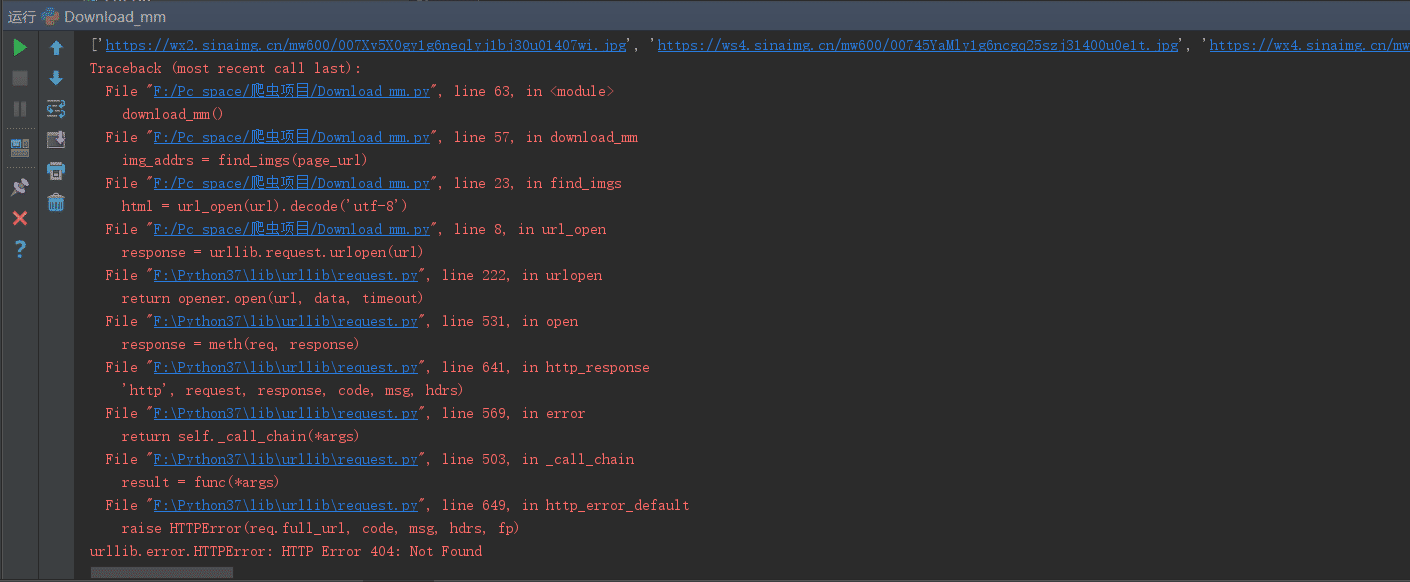
жғіеҲ°дјҡдёҚдјҡжҳҜеӣ дёәеҗҺйқўйЎөж•°зҡ„еӣҫзүҮпјҢimg_urlзҡ„ж јејҸеҮәзҺ°дәҶж”№еҸҳпјҢеҜјиҮҙ404пјҢжүҖд»Ҙе°Ҷpagesж”№жҲҗ5пјҢ
еҶҚж¬ЎиҝҗиЎҢпјҢз»“жһңжІЎжңүй—®йўҳпјҢеӣҫзүҮиғҪжӯЈеёёдёӢиҪҪпјҡ
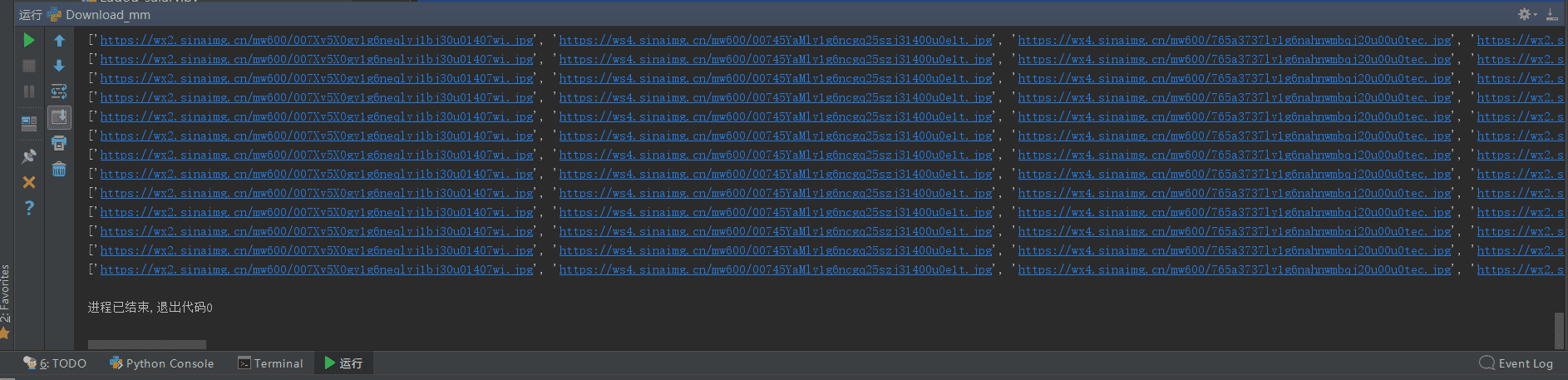
д»”з»Ҷи§ӮеҜҹеҸ‘зҺ°пјҢеҲҡеҘҪжҳҜеңЁз¬¬дә”йқўзҡ„еӣҫзүҮеҫҖеҗҺпјҢеҮәзҺ°дәҶдёҚеҸҜдёӢиҪҪзҡ„й—®йўҳпјҲ404пјүгҖӮжүҖд»ҘеңЁз…ҺиӣӢзҪ‘дёҠпјҢжҲ‘们зӣҙжҺҘи·іеҲ°з¬¬6йқўжҹҘзңӢеӣҫзүҮзҡ„urlгҖӮ

дёҠеӣҫжҳҜеҗҺ5йқўзҡ„еӣҫзүҮurlпјҢдёӢеӣҫжҳҜеүҚ5йқўзҡ„еӣҫзүҮurl

иҖҢжәҗд»Јз ҒдёӯпјҢеҜ»жүҫзҡ„еӣҫзүҮurlдёәдҪҝз”Ёfind()еҮҪж•°пјҢиҝӣиЎҢе®ҡдёә<img src=вҖҳ'> <.jpg>дёӯзҡ„еӣҫзүҮurlпјҢжүҖд»ҘеҗҺ5йқўеҮәзҺ°зҡ„a hrefж— жі•еҢ№й…ҚпјҢеҚіеҮәзҺ°дәҶ404 ERRORгҖӮеҰӮжһңжғіиҰҒдёӢиҪҪеҗҺз»ӯзҡ„еӣҫзүҮпјҢйңҖиҰҒйҮҚж–°ж·»еҠ дёҖдёӘurlе®ҡдҪҚ
еҚіеңЁfindдёӯе°Ҷ img srcж”№жҲҗ a hrefпјҢеҒҸ移йҮҸд№ҹйңҖиҰҒжӣҙж”№гҖӮ
жҖ»з»“пјҡ
дҪҝз”Ёfind()жқҘе®ҡдҪҚзҪ‘йЎөж ҮзӯҫзЎ®е®һеӨӘиҝҮlowпјҢжүҖд»Ҙд»ҘеҗҺеңЁзҲ¬иҷ«дёӯиҰҒе°ҪйҮҸдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸе’ҢBeautifulsoupеҢ…жқҘжҸҗй«ҳж•ҲзҺҮпјҢиҖҢиҝҷдёӨйЎ№жҲ‘иҝҳдёҚжҳҜзү№еҲ«зҶҹпјҢжүҖд»ҘйңҖиҰҒжӣҙеӨҡзҡ„и®ӯз»ғгҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ