жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҰӮдҪ•еңЁPythonдёӯдҪҝз”ЁYellowbrickе®һзҺ°еҸҜи§ҶеҢ–пјҹеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
Yellowbrickдё»иҰҒеҢ…еҗ«зҡ„组件еҰӮдёӢпјҡ
Visualizers Visualizersд№ҹжҳҜestimatorsпјҲд»Һж•°жҚ®дёӯд№ еҫ—зҡ„еҜ№иұЎпјүпјҢе…¶дё»иҰҒд»»еҠЎжҳҜдә§з”ҹеҸҜеҜ№жЁЎеһӢйҖүжӢ©иҝҮзЁӢжңүжӣҙж·ұе…ҘдәҶи§Јзҡ„и§ҶеӣҫгҖӮд»ҺScikit-LearnжқҘзңӢпјҢеҪ“еҸҜи§ҶеҢ–ж•°жҚ®з©әй—ҙжҲ–иҖ…е°ҒиЈ…дёҖдёӘжЁЎеһӢestimatorж—¶пјҢе…¶е’ҢиҪ¬жҚўеҷЁпјҲtransformersпјүзӣёдјјпјҢе°ұеғҸ"ModelCV" (жҜ”еҰӮ RidgeCV, LassoCV )зҡ„е·ҘдҪңеҺҹзҗҶдёҖж ·гҖӮYellowbrickзҡ„дё»иҰҒзӣ®ж ҮжҳҜеҲӣе»әдёҖдёӘе’ҢScikit-Learnзұ»дјјзҡ„жңүж„Ҹд№үзҡ„APIгҖӮе…¶дёӯжңҖеҸ—ж¬ўиҝҺзҡ„visualizersеҢ…жӢ¬пјҡ зү№еҫҒеҸҜи§ҶеҢ– Rank Features: еҜ№еҚ•дёӘжҲ–иҖ…дёӨдёӨеҜ№еә”зҡ„зү№еҫҒиҝӣиЎҢжҺ’еәҸд»ҘжЈҖжөӢе…¶зӣёе…іжҖ§ Parallel Coordinates: еҜ№е®һдҫӢиҝӣиЎҢж°ҙе№іи§Ҷеӣҫ Radial Visualization: еңЁдёҖдёӘеңҶеҪўи§Ҷеӣҫдёӯе°Ҷе®һдҫӢеҲҶйҡ”ејҖ PCA Projection: йҖҡиҝҮдё»жҲҗеҲҶе°Ҷе®һдҫӢжҠ•е°„ Feature Importances: еҹәдәҺе®ғ们еңЁжЁЎеһӢдёӯзҡ„иЎЁзҺ°еҜ№зү№еҫҒиҝӣиЎҢжҺ’еәҸ Scatter and Joint Plots: з”ЁйҖүжӢ©зҡ„зү№еҫҒеҜ№е…¶иҝӣиЎҢеҸҜи§ҶеҢ– еҲҶзұ»еҸҜи§ҶеҢ– Class Balance: зңӢзұ»зҡ„еҲҶеёғжҖҺж ·еҪұе“ҚжЁЎеһӢ Classification Report: з”Ёи§Ҷеӣҫзҡ„ж–№ејҸе‘ҲзҺ°зІҫзЎ®зҺҮпјҢеҸ¬еӣһзҺҮе’ҢF1еҖј ROC/AUC Curves: зү№еҫҒжӣІзәҝе’ҢROCжӣІзәҝеӯҗдёӢзҡ„йқўз§Ҝ Confusion Matrices: еҜ№еҲҶзұ»еҶіе®ҡиҝӣиЎҢи§ҶеӣҫжҸҸиҝ° еӣһеҪ’еҸҜи§ҶеҢ– Prediction Error Plot: жІҝзқҖзӣ®ж ҮеҢәеҹҹеҜ№жЁЎеһӢиҝӣиЎҢз»ҶеҲҶ Residuals Plot: жҳҫзӨәи®ӯз»ғж•°жҚ®е’ҢжөӢиҜ•ж•°жҚ®дёӯж®Ӣе·®зҡ„е·®ејӮ Alpha Selection: жҳҫзӨәдёҚеҗҢalphaеҖјйҖүжӢ©еҜ№жӯЈеҲҷеҢ–зҡ„еҪұе“Қ иҒҡзұ»еҸҜи§ҶеҢ– K-Elbow Plot: з”ЁиӮҳйғЁжі•еҲҷжҲ–иҖ…е…¶д»–жҢҮж ҮйҖүжӢ©kеҖј Silhouette Plot: йҖҡиҝҮеҜ№иҪ®е»“зі»ж•°еҖјиҝӣиЎҢи§ҶеӣҫжқҘйҖүжӢ©kеҖј ж–Үжң¬еҸҜи§ҶеҢ– Term Frequency: еҜ№иҜҚйЎ№еңЁиҜӯж–ҷеә“дёӯзҡ„еҲҶеёғйў‘зҺҮиҝӣиЎҢеҸҜи§ҶеҢ– t-SNE Corpus Visualization: з”ЁйҡҸжңәйӮ»еҹҹеөҢе…ҘжқҘжҠ•е°„ж–ҮжЎЈ
иҝҷйҮҢд»ҘзҷҢз—Үж•°жҚ®йӣҶдёәдҫӢз»ҳеҲ¶ROCжӣІзәҝпјҢеҰӮдёӢпјҡ
def testFunc1(savepath='Results/breast_cancer_ROCAUC.png'): ''' еҹәдәҺзҷҢз—Үж•°жҚ®йӣҶзҡ„жөӢиҜ• ''' data=load_breast_cancer() X,y=data['data'],data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y) viz=ROCAUC(LogisticRegression()) viz.fit(X_train, y_train) viz.score(X_test, y_test) viz.poof(outpath=savepath)
з»“жһңеҰӮдёӢпјҡ

з»“жһңзңӢиө·жқҘд№ҹжҳҜжҢәзҫҺи§Ӯзҡ„гҖӮ
д№ӢеҗҺз”Ёе№іиЎҢеқҗж Үзҡ„ж–№жі•еҜ№й«ҳз»ҙж•°жҚ®иҝӣиЎҢдҪңеӣҫпјҢж•°жҚ®йӣҶеҗҢдёҠпјҡ
def testFunc2(savepath='Results/breast_cancer_ParallelCoordinates.png'): ''' з”Ёе№іиЎҢеқҗж Үзҡ„ж–№жі•еҜ№й«ҳз»ҙж•°жҚ®иҝӣиЎҢдҪңеӣҫ ''' data=load_breast_cancer() X,y=data['data'],data['target'] print 'X_shape: ',X.shape #X_shape: (569L, 30L) visualizer=ParallelCoordinates() visualizer.fit_transform(X,y) visualizer.poof(outpath=savepath)
з»“жһңеҰӮдёӢпјҡ
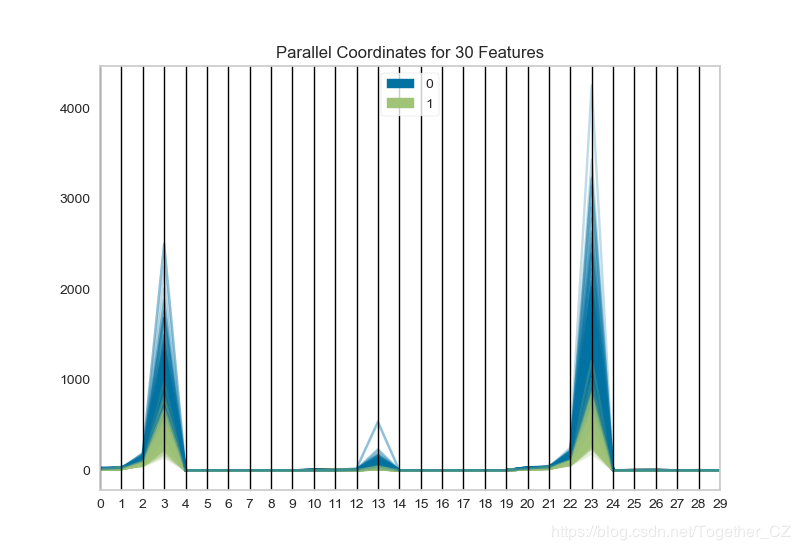
иҝҷдёӘжңҖеҲқжІЎжңүзңӢжҳҺзҷҪд»Җд№Ҳж„ҸжҖқпјҢе…¶е®һе°ұжҳҜй«ҳз»ҙзү№еҫҒж•°жҚ®зҡ„еҸҜи§ҶеҢ–еҲҶжһҗпјҢиҝҷдёӘеҠҹиғҪиҝҳеҸҜд»ҘеҜ№еҺҹе§Ӣж•°жҚ®иҝӣиЎҢйҮҮж ·пјҢд№ӢеҗҺеҶҚз»ҳеӣҫгҖӮ
еҹәдәҺзҷҢз—Үж•°жҚ®йӣҶпјҢдҪҝз”ЁйҖ»иҫ‘еӣһеҪ’жЁЎеһӢжқҘеҲҶзұ»пјҢз»ҳеҲ¶еҲҶзұ»жҠҘе‘Ҡ
def testFunc3(savepath='Results/breast_cancer_LR_report.png'): ''' еҹәдәҺзҷҢз—Үж•°жҚ®йӣҶпјҢдҪҝз”ЁйҖ»иҫ‘еӣһеҪ’жЁЎеһӢжқҘеҲҶзұ»пјҢз»ҳеҲ¶еҲҶзұ»жҠҘе‘Ҡ ''' data=load_breast_cancer() X,y=data['data'],data['target'] model=LogisticRegression() visualizer=ClassificationReport(model) X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42) visualizer.fit(X_train,y_train) visualizer.score(X_test,y_test) visualizer.poof(outpath=savepath)
з»“жһңеҰӮдёӢпјҡ
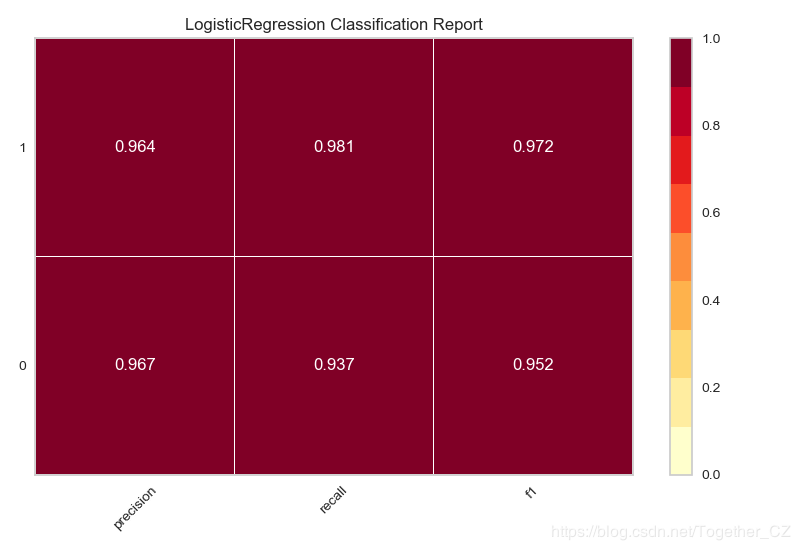
иҝҷж ·зҡ„з»“жһңеұ•зҺ°ж–№ејҸиҝҳжҳҜжҜ”иҫғзҫҺи§Ӯзҡ„пјҢеңЁдҪҝз”Ёзҡ„ж—¶еҖҷеҸ‘зҺ°дәҶиҝҷдёӘжЁЎеқ—зҡ„дёҖдёӘдёҚи¶ізҡ„ең°ж–№пјҢе°ұжҳҜпјҡеҰӮжһңиҝһз»ӯз»ҳеҲ¶дёӨе№…еӣҫзүҮзҡ„иҜқпјҢ第дёҖе№…еӣҫзүҮе°ұдјҡзҙҜеҠ еҲ°з¬¬дәҢе№…еӣҫзүҮдёӯеҺ»пјҢеӨҡе№…еӣҫзүҮз»ҳеҲ¶дәҰжҳҜеҰӮжӯӨпјҢеңЁmatplotlibдёӯеҸҜд»ҘдҪҝз”Ёplt.clf()ж–№жі•жқҘжё…йҷӨдёҠдёҖе№…еӣҫзүҮпјҢиҝҷйҮҢжІЎжңүжүҫеҲ°еҜ№еә”зҡ„APIпјҢеёҢжңӣжңүжүҫеҲ°зҡ„жңӢеҸӢе‘ҠзҹҘдёҖдёӢгҖӮ
жҺҘдёӢжқҘеҹәдәҺе…ұдә«еҚ•иҪҰж•°жҚ®йӣҶиҝӣиЎҢз§ҹеҖҹйў„жөӢпјҢе…·дҪ“еҰӮдёӢпјҡ
йҰ–е…ҲеҹәдәҺзү№еҫҒеҜ№зӣёдјјеәҰеҲҶжһҗж–№жі•жқҘеҲҶжһҗе…ұдә«еҚ•иҪҰж•°жҚ®йӣҶдёӯдёӨдёӨзү№еҫҒд№Ӣй—ҙзҡ„зӣёдјјеәҰ
def testFunc5(savepath='Results/bikeshare_Rank2D.png'):
'''
е…ұдә«еҚ•иҪҰж•°жҚ®йӣҶйў„жөӢ
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"
]]
y=data["riders"]
visualizer=Rank2D(algorithm="pearson")
visualizer.fit_transform(X)
visualizer.poof(outpath=savepath)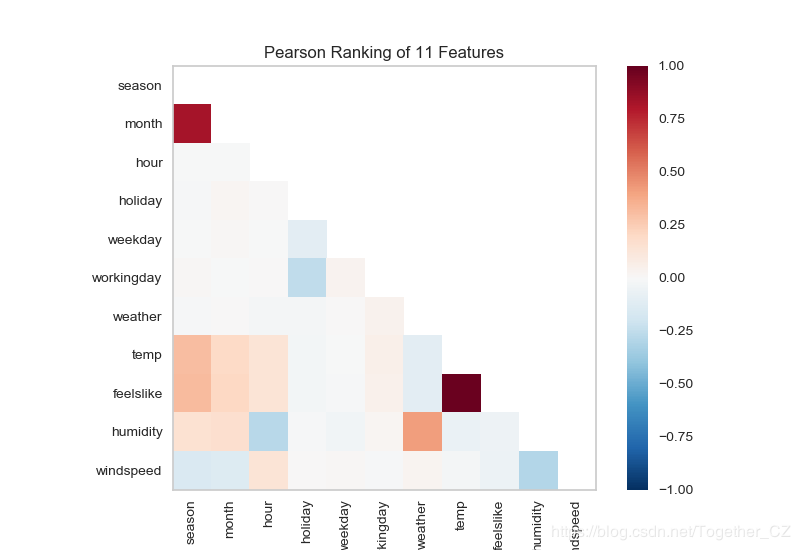
еҹәдәҺзәҝжҖ§еӣһеҪ’жЁЎеһӢе®һзҺ°йў„жөӢеҲҶжһҗ
def testFunc7(savepath='Results/bikeshare_LinearRegression_ResidualsPlot.png'):
'''
еҹәдәҺе…ұдә«еҚ•иҪҰж•°жҚ®дҪҝз”ЁзәҝжҖ§еӣһеҪ’жЁЎеһӢйў„жөӢ
'''
data = pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=ResidualsPlot(LinearRegression())
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)з»“жһңеҰӮдёӢпјҡ

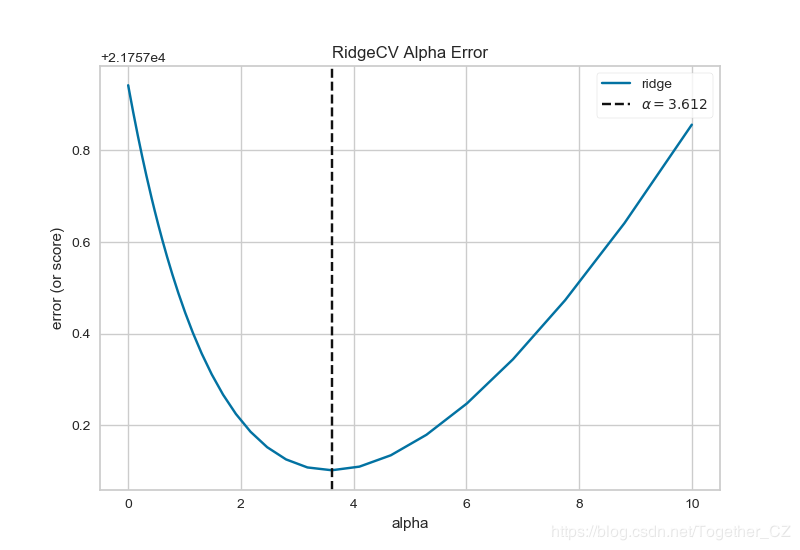
еҹәдәҺе…ұдә«еҚ•иҪҰж•°жҚ®дҪҝз”ЁAlphaSelection
def testFunc8(savepath='Results/bikeshare_RidgeCV_AlphaSelection.png'):
'''
еҹәдәҺе…ұдә«еҚ•иҪҰж•°жҚ®дҪҝз”ЁAlphaSelection
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
alphas=np.logspace(-10, 1, 200)
visualizer=AlphaSelection(RidgeCV(alphas=alphas))
visualizer.fit(X, y)
visualizer.poof(outpath=savepath)з»“жһңеҰӮдёӢпјҡ
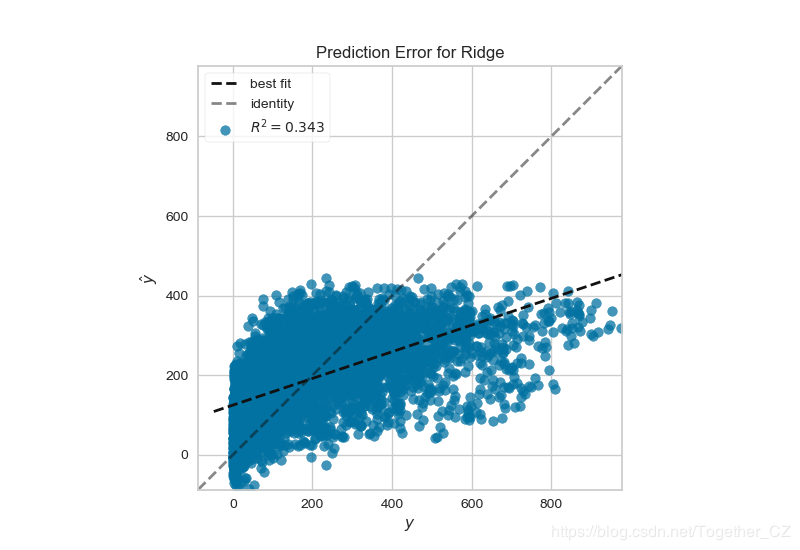
еҹәдәҺе…ұдә«еҚ•иҪҰж•°жҚ®з»ҳеҲ¶йў„жөӢй”ҷиҜҜеӣҫ
def testFunc9(savepath='Results/bikeshare_Ridge_PredictionError.png'):
'''
еҹәдәҺе…ұдә«еҚ•иҪҰж•°жҚ®з»ҳеҲ¶йў„жөӢй”ҷиҜҜеӣҫ
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=PredictionError(Ridge(alpha=3.181))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)
blog.csdn.net/Together_CZ/article/details/86640784з»“жһңеҰӮдёӢпјҡ
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ