您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天就跟大家聊聊有关使用python怎么实现一个文章敏感词过滤功能,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
第一步:建立一个敏感词库(.txt文本)
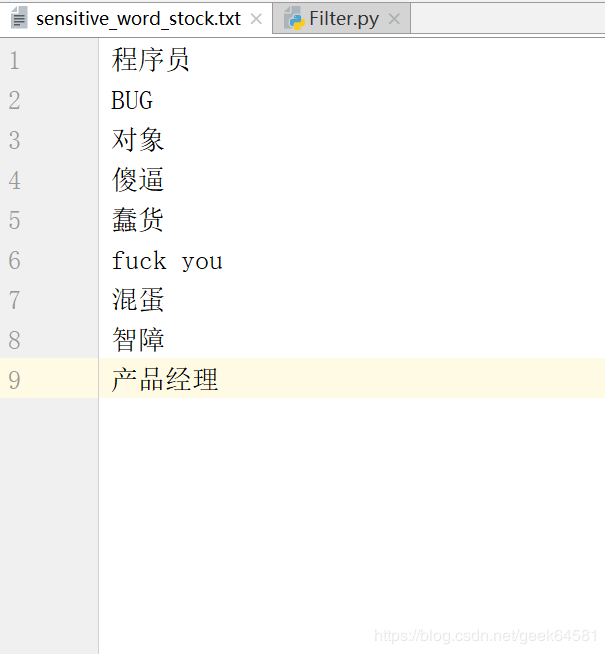
第二步:编写代码在文章中过滤敏感词(递归实现)
# -*- coding: utf-8 -*-
# author 代序春秋
import os
import chardet
# 获取文件目录和绝对路径
curr_dir = os.path.dirname(os.path.abspath(__file__))
# os.path.join()拼接路径
sensitive_word_stock_path = os.path.join(curr_dir, 'sensitive_word_stock.txt')
# 获取存放敏感字库的路径
# print(sensitive_word_stock_path)
class ArticleFilter(object):
# 实现文章敏感词过滤
def filter_replace(self, string):
# string = string.decode("gbk")
# 存放敏感词的列表
filtered_words = []
# 打开敏感词库读取敏感字
with open(sensitive_word_stock_path) as filtered_words_txt:
lines = filtered_words_txt.readlines()
for line in lines:
# strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
filtered_words.append(line.strip())
# 输出过滤好之后的文章
print("过滤之后的文字:" + self.replace_words(filtered_words, string))
# 实现敏感词的替换,替换为*
def replace_words(self, filtered_words, string):
# 保留新字符串
new_string = string
# 从列表中取出敏感词
for words in filtered_words:
# 判断敏感词是否在文章中
if words in string:
# 如果在则用*替换(几个字替换几个*)
new_string = string.replace(words, "*" * len(words))
# 当替换好的文章(字符串)与被替换的文章(字符串)相同时,结束递归,返回替换好的文章(字符串)
if new_string == string:
# 返回替换好的文章(字符串)
return new_string
# 如果不相同则继续替换(递归函数自己调用自己)
else:
# 递归函数自己调用自己
return self.replace_words(filtered_words, new_string)
def main():
while True:
string = input("请输入一段文字:")
run = ArticleFilter()
run.filter_replace(string)
continue
if __name__ == '__main__':
main()运行结果:

看完上述内容,你们对使用python怎么实现一个文章敏感词过滤功能有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。