您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
爬取网站为:http://xiaohua.zol.com.cn/youmo/
查看网页机构,爬取笑话内容时存在如下问题:
1、每页需要进入“查看更多”链接下面网页进行进一步爬取内容每页查看更多链接内容比较多,多任务进行,这里采用线程池的方式,可以有效地控制系统中并发线程的数量。避免当系统中包含有大量的并发线程时,导致系统性能下降,甚至导致 Python 解释器崩溃,引入线程池,花费时间更少,更效率。
2、查看链接笑话页内容,div元素内部文本分布比较混乱。有的分布在<p>链接内有的属于div的文本,可采用正则表达式的方式解决。
注意2种获取元素节点的方式:
1)lxml获取节点字符串
res=requests.get(url,headers=headers)
html = res.text
lxml 获取节点写法
element=etree.HTML(html)
divEle=element.xpath("//div[@class='article-text']")[0] # 获取div节点
div= etree.tostring(divEle, encoding = 'utf-8' ).decode('utf-8') # 转换为div字符串
2)正则表达式写法1,过滤回车、制表符和p标签
# 第一种方式:replace
content = re.findall('<div class="article-text">(.*?)</div>',html,re.S)
content = content[0].replace('\r','').replace('\t','').replace('<p>','').replace('</p>','').strip()
3)正则表达式写法2,过滤回车、制表符和p标签
# 第二种方式:sub for index in range(len(content)): content[index] = re.sub(r'(\r|\t|<p>|<\/p>)+','',content[index]).strip() list = ''.join(content) print(list)
3、完整代码
index.py
import requests
import threadpool
import time
import os,sys
import re
from lxml import etree
from lxml.html import tostring
class ScrapDemo():
next_page_url="" #下一页的URL
page_num=1 #当前页
detail_url_list=0 #详情页面URL地址list
deepth=0 #设置抓取的深度
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"
}
fileNum=0
def __init__(self,url):
self.scrapyIndex(url)
def threadIndex(self,urllist): #开启线程池
if len(urllist) == 0:
print("请输入需要爬取的地址")
return False
ScrapDemo.detail_url_list=len(urllist)
pool=threadpool.ThreadPool(len(urllist))
requests=threadpool.makeRequests(self.detailScray,urllist)
for req in requests:
pool.putRequest(req)
time.sleep(0.5)
pool.wait()
def detailScray(self,url): # 获取html结构
if not url == "":
url='http://xiaohua.zol.com.cn/{}'.format(url)
res=requests.get(url,headers=ScrapDemo.headers)
html=res.text
# element=etree.HTML(html)
# divEle=element.xpath("//div[@class='article-text']")[0] # Element div
self.downloadText(html)
def downloadText(self,ele): # 抓取数据并存为txt文件
clist = re.findall('<div class="article-text">(.*?)</div>',ele,re.S)
for index in range(len(clist)):
'''
正则表达式:过滤掉回车、制表符和p标签
'''
clist[index]=re.sub(r'(\r|\t|<p>|<\/p>)+','',clist[index])
content="".join(clist)
# print(content)
basedir=os.path.dirname(__file__)
filePath=os.path.join(basedir)
filename="xiaohua{0}-{1}.txt".format(ScrapDemo.deepth,str(ScrapDemo.fileNum))
file=os.path.join(filePath,'file_txt',filename)
try:
f=open(file,"w")
f.write(content)
if ScrapDemo.fileNum == (ScrapDemo.detail_url_list - 1):
print(ScrapDemo.next_page_url)
print(ScrapDemo.deepth)
if not ScrapDemo.next_page_url == "":
self.scrapyIndex(ScrapDemo.next_page_url)
except Exception as e:
print("Error:%s" % str(e))
ScrapDemo.fileNum=ScrapDemo.fileNum+1
print(ScrapDemo.fileNum)
def scrapyIndex(self,url):
if not url == "":
ScrapDemo.fileNum=0
ScrapDemo.deepth=ScrapDemo.deepth+1
print("开启第{0}页抓取".format(ScrapDemo.page_num))
res=requests.get(url,headers=ScrapDemo.headers)
html=res.text
element=etree.HTML(html)
a_urllist=element.xpath("//a[@class='all-read']/@href") # 当前页所有查看全文
next_page=element.xpath("//a[@class='page-next']/@href") # 获取下一页的url
ScrapDemo.next_page_url='http://xiaohua.zol.com.cn/{}'.format(next_page[0])
if not len(next_page) == 0 and ScrapDemo.next_page_url != url:
ScrapDemo.page_num=ScrapDemo.page_num+1
self.threadIndex(a_urllist[:])
else:
print('下载完成,当前页数为{}页'.format(ScrapDemo.page_num))
sys.exit()
runscrapy.py
from app import ScrapDemo url="http://xiaohua.zol.com.cn/youmo/" ScrapDemo(url)
运行如下:
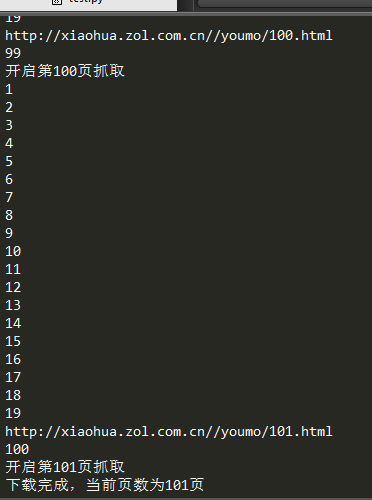
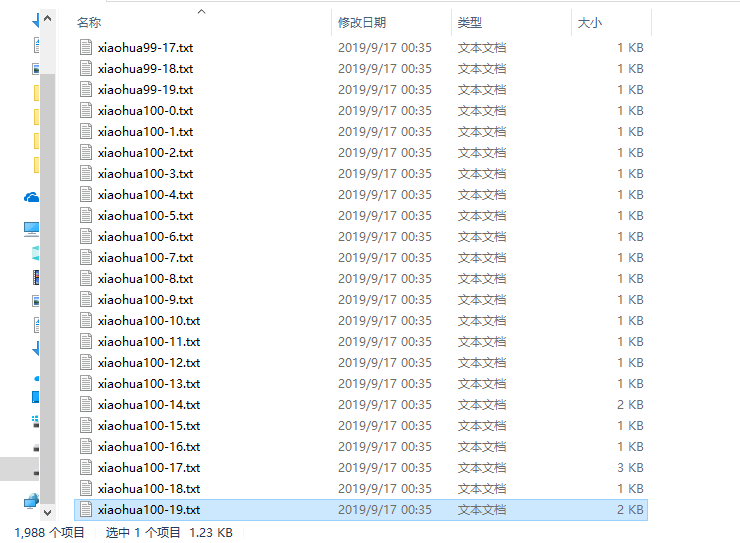
总共1988个文件,下载完成。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。