您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关如何通过selenium抓取某东的TT购买记录并分析趋势的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
本文通过selenium抓取TT信息,存入到mongodb数据库中。
抓取TT产品信息
TT产品页面的连接是
https://list.jd.com/list.html?cat=9192,9196,1502&page=1&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main
上面有个page参数,表示第几页。改变这个参数就可以爬取到不同页面的TT产品。
通过开发者工具看下如果抓取TT的产品信息,例如名字、品牌、价格、评论数量等。
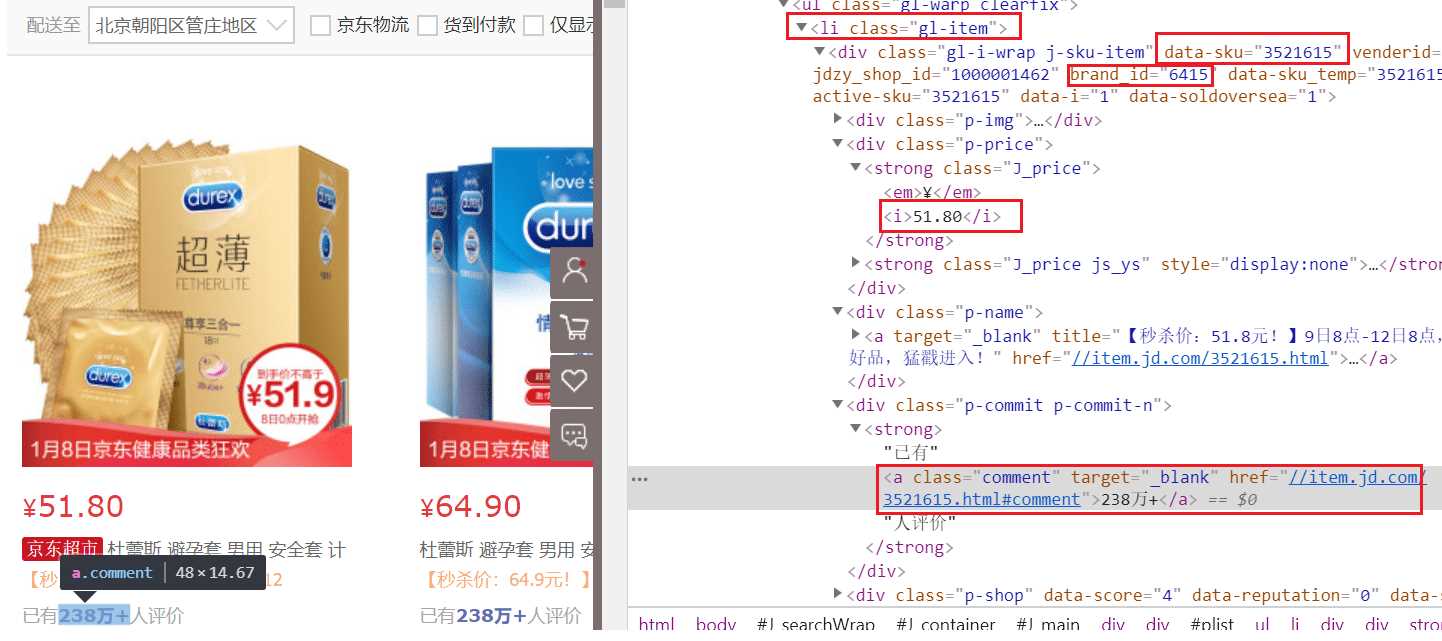
通过上图可以看到一个TT产品信息对应的源代码是一个class为gl-item的li节点<li class='gl-item'>。li节点中data-sku属性是产品的ID,后面抓取产品的评论信息会用到,brand_id是品牌ID。class为p-price的div节点对应的是TT产品的价格信息。class为p-comment的div节点对应的是评论总数信息。
开始使用requests是总是无法解析到TT的价格和评论信息,最后适应selenium才解决了这个问题,如果有人知道怎么解决这问题,望不吝赐教。
下面介绍抓取TT产品评论信息。
点击一个TT产品,会跳转到产品详细页面,点击“商品评论”,然后勾选上“只看当前商品评价”选项(如果不勾选,就会看到该系列产品的评价)就会看到商品评论信息,我们用开发者工具看下如果抓取评论信息。
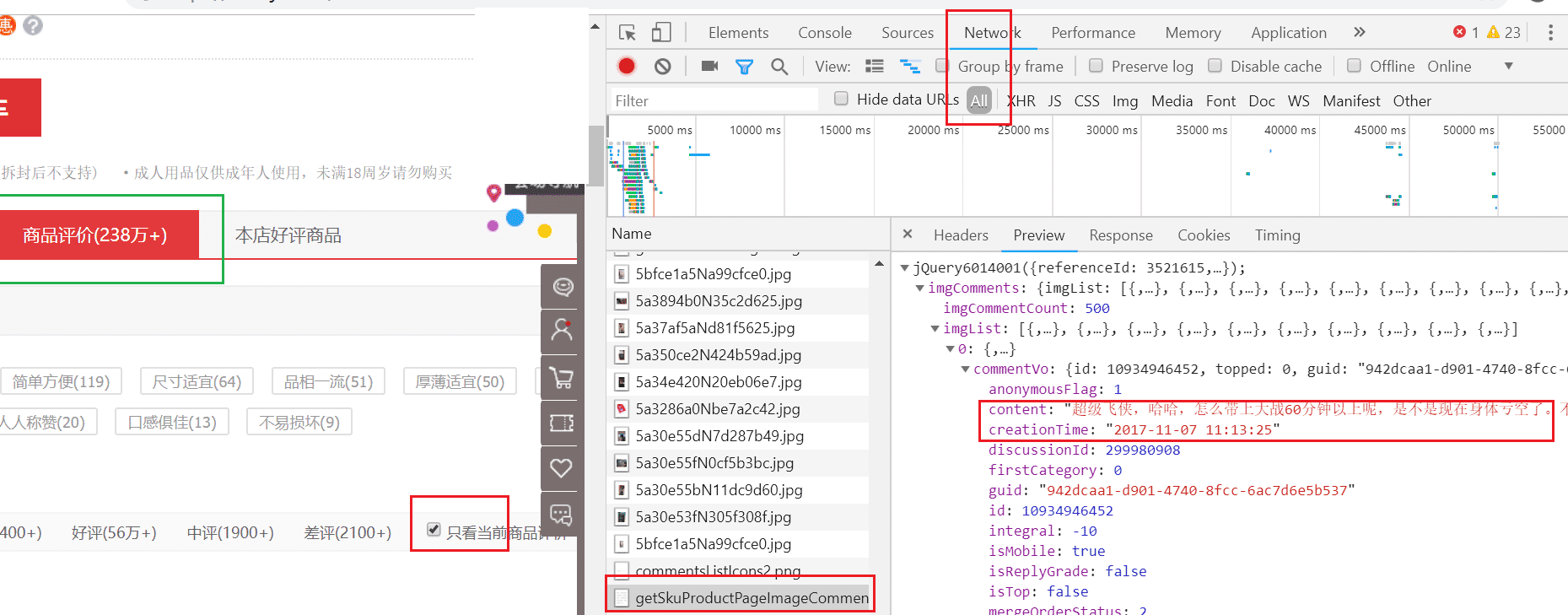
如上图所示,在开发者工具中,点击Network选项,就会看到
https://club.jd.com/discussion/getSkuProductPageImageCommentList.action?productId=3521615&isShadowSku=0&callback=jQuery6014001&page=2&pageSize=10&_=1547042223100
的链接,这个链接返回的是json数据。其中productId就是TT产品页面的data-sku属性的数据。page参数是第几页评论。返回的json数据中,content是评论数,createTime是下单时间。
代码如下:
def parse_product(page,html):
doc = pq(html)
li_list = doc('.gl-item').items()
for li in li_list:
product_id = li('.gl-i-wrap').attr('data-sku')
brand_id = li('.gl-i-wrap').attr('brand_id')
time.sleep(get_random_time())
title = li('.p-name').find('em').text()
price_items = li('.p-price').find('.J_price').find('i').items()
price = 0
for price_item in price_items:
price = price_item.text()
break
total_comment_num = li('.p-commit').find('strong a').text()
if total_comment_num.endswith("万+"):
print('总评价数量:' + total_comment_num)
total_comment_num = str(int(float(total_comment_num[0:len(total_comment_num) -2]) * 10000))
print('转换后总评价数量:' + total_comment_num)
elif total_comment_num.endswith("+"):
total_comment_num = total_comment_num[0:len(total_comment_num) - 1]
condom = {}
condom["product_id"] = product_id
condom["brand_id"] = brand_id
condom["condom_name"] = title
condom["total_comment_num"] = total_comment_num
condom["price"] = price
comment_url = 'https://club.jd.com/comment/skuProductPageComments.action?callback=fetchJSON_comment98vv117396&productId=%s&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
comment_url = comment_url %(product_id)
response = requests.get(comment_url,headers = headers)
if response.text == '':
for i in range(0,10):
time.sleep(get_random_time())
try:
response = requests.get(comment_url, headers=headers)
except requests.exceptions.ProxyError:
time.sleep(get_random_time())
response = requests.get(comment_url, headers=headers)
if response.text:
break
else:
continue
text = response.text
text = text[28:len(text) - 2]
jsons = json.loads(text)
productCommentSummary = jsons.get('productCommentSummary')
# productCommentSummary = response.json().get('productCommentSummary')
poor_count = productCommentSummary.get('poorCount')
general_count = productCommentSummary.get('generalCount')
good_count = productCommentSummary.get('goodCount')
comment_count = productCommentSummary.get('commentCount')
poor_rate = productCommentSummary.get('poorRate')
good_rate = productCommentSummary.get('goodRate')
general_rate = productCommentSummary.get('generalRate')
default_good_count = productCommentSummary.get('defaultGoodCount')
condom["poor_count"] = poor_count
condom["general_count"] = general_count
condom["good_count"] = good_count
condom["comment_count"] = comment_count
condom["poor_rate"] = poor_rate
condom["good_rate"] = good_rate
condom["general_rate"] = general_rate
condom["default_good_count"] = default_good_count
collection.insert(condom)
comments = jsons.get('comments')
if comments:
for comment in comments:
print('解析评论')
condom_comment = {}
reference_time = comment.get('referenceTime')
content = comment.get('content')
product_color = comment.get('productColor')
user_client_show = comment.get('userClientShow')
user_level_name = comment.get('userLevelName')
is_mobile = comment.get('isMobile')
creation_time = comment.get('creationTime')
guid = comment.get("guid")
condom_comment["reference_time"] = reference_time
condom_comment["content"] = content
condom_comment["product_color"] = product_color
condom_comment["user_client_show"] = user_client_show
condom_comment["user_level_name"] = user_level_name
condom_comment["is_mobile"] = is_mobile
condom_comment["creation_time"] = creation_time
condom_comment["guid"] = guid
collection_comment.insert(condom_comment)
parse_comment(product_id)
def parse_comment(product_id):
comment_url = 'https://club.jd.com/comment/skuProductPageComments.action?callback=fetchJSON_comment98vv117396&productId=%s&score=0&sortType=5&page=%d&pageSize=10&isShadowSku=0&fold=1'
for i in range(1,200):
time.sleep(get_random_time())
time.sleep(get_random_time())
print('抓取第' + str(i) + '页评论')
url = comment_url%(product_id,i)
response = requests.get(url, headers=headers,timeout=10)
print(response.status_code)
if response.text == '':
for i in range(0,10):
print('抓取不到数据')
response = requests.get(comment_url, headers=headers)
if response.text:
break
else:
continue
text = response.text
print(text)
text = text[28:len(text) - 2]
print(text)
jsons = json.loads(text)
comments = jsons.get('comments')
if comments:
for comment in comments:
print('解析评论')
condom_comment = {}
reference_time = comment.get('referenceTime')
content = comment.get('content')
product_color = comment.get('productColor')
user_client_show = comment.get('userClientShow')
user_level_name = comment.get('userLevelName')
is_mobile = comment.get('isMobile')
creation_time = comment.get('creationTime')
guid = comment.get("guid")
id = comment.get("id")
condom_comment["reference_time"] = reference_time
condom_comment["content"] = content
condom_comment["product_color"] = product_color
condom_comment["user_client_show"] = user_client_show
condom_comment["user_level_name"] = user_level_name
condom_comment["is_mobile"] = is_mobile
condom_comment["creation_time"] = creation_time
condom_comment["guid"] = guid
condom_comment["id"] = id
collection_comment.insert(condom_comment)
else:
break如果想要获取抓取TT数据和评论的代码,请关注我的公众号“python_ai_bigdata”,然后恢复TT获取代码。
一共抓取了8934条产品信息和17万条评论(购买)记录。
产品最多的品牌
先分析8934个产品,看下哪个品牌的TT在京东上卖得最多。由于品牌过多,京东上销售TT的品牌就有299个,我们只取卖得最多的前10个品牌。
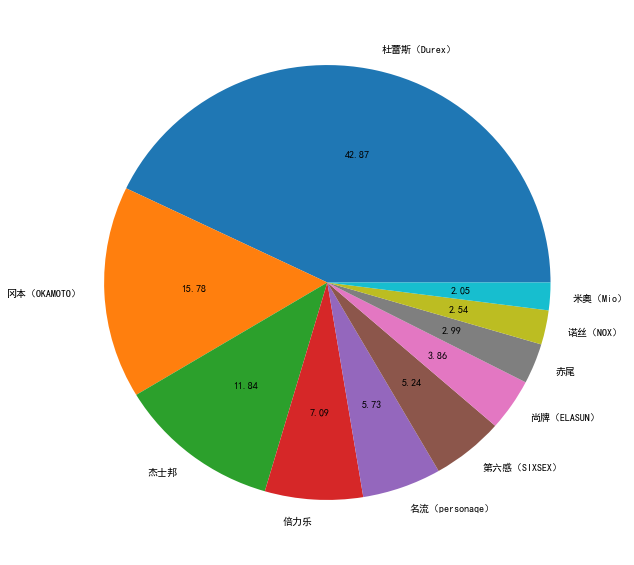
从上面的图可以看出,排名第1的是杜杜,冈本次之,邦邦第3,前10品牌分别是杜蕾斯、冈本、杰士邦、倍力乐、名流、第六感、尚牌、赤尾、诺丝和米奥。这10个品牌中有5个是我没见过的,分别是倍力乐、名流、尚牌、赤尾和米奥,其他的都见过,特别是杜杜和邦邦常年占据各大超市收银台的醒目位置。
这10个品牌中,杜蕾斯来自英国,冈本来自日本,杰士邦、第六感、赤尾、米奥和名流是国产的品牌,第六感是杰士邦旗下的一个避孕套品牌;倍力乐是中美合资的品牌,尚牌来自泰国,诺丝是来自美国的品牌。
代码:
import pymongo
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas import DataFrame,Series
client = pymongo.MongoClient(host='localhost',port=27017)
db = client.condomdb
condom_new = db.condom_new
cursor = condom_new.find()
condom_df = pd.DataFrame(list(cursor))
brand_name_df = condom_df['brand_name'].to_frame()
brand_name_df['condom_num'] = 1
brand_name_group = brand_name_df.groupby('brand_name').sum()
brand_name_sort = brand_name_group.sort_values(by='condom_num', ascending=False)
brand_name_top10 = brand_name_sort.head(10)
# print(3 * np.random.rand(4))
index_list = []
labels = []
value_list = []
for index,row in brand_name_top10.iterrows():
index_list.append(index)
labels.append(index)
value_list.append(int(row['condom_num']))
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
series_condom = pd.Series(value_list, index=index_list, name='')
series_condom.plot.pie(labels=labels,
autopct='%.2f', fontsize=10, figsize=(10, 10))卖得最好的产品
可以根据产品评价数量来判断一个产品卖得好坏,评价数最多的产品通常也是卖得最好的。
产品评论中有个产品评论总数的字段,我们就根据这个字段来排序,看下评论数量最多的前10个产品是什么(也就是评论数量最多的)。

从上图可以看出,卖得最好的还是杜杜的产品,10席中占了6席。杜杜的情爱四合一以1180000万的销量排名第一。
最受欢迎的是超薄的TT,占了8席,持久型的也比较受欢迎,狼牙套竟然也上榜了,真是大大的出乎我的意料。
销量分析
下图是TT销量最好的10天
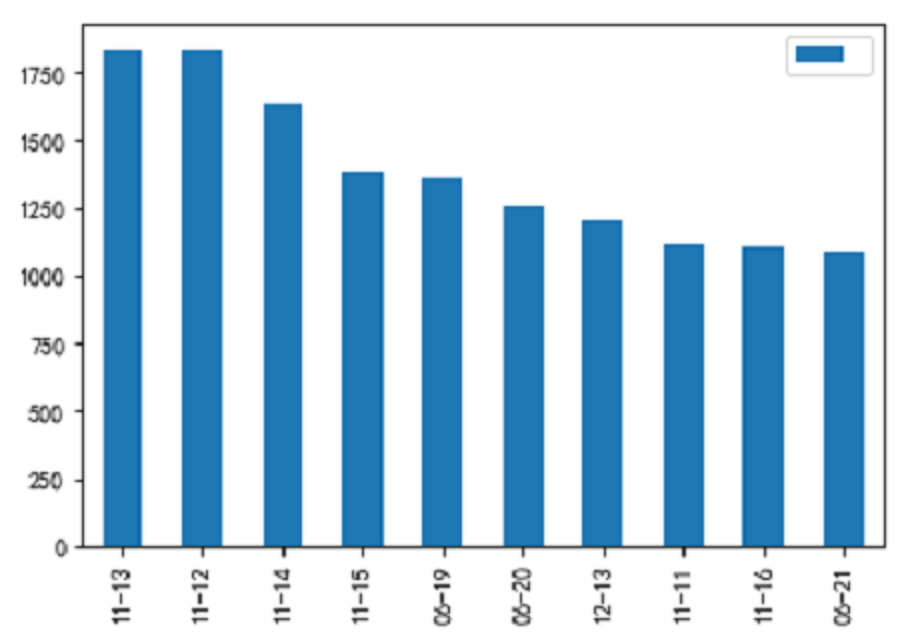
可以看出这10天分别分布在6月、11月和12月,应该和我们熟知的618、双11和双12购物节有关。
现在很多电商都有自己的购物节,像618,双11和双12。由于一个产品最多只能显示100页的评论,每页10条评论,一个产品最多只能爬取到1000条评论,对于销量达到118万的情爱四合一来说,1000条评论不具有代表性,但是总的来说通过上图的分析,可以知道电商做活动的月份销量一般比较好。
下图是每个月份TT销售量柱状图,更加验证了上面的说法。
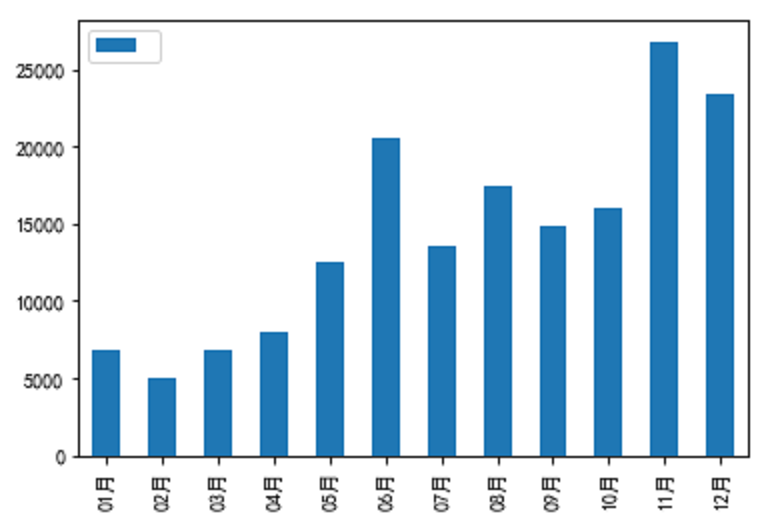
11月的销量最好,12月次之,6月份的销量第三。
购物平台
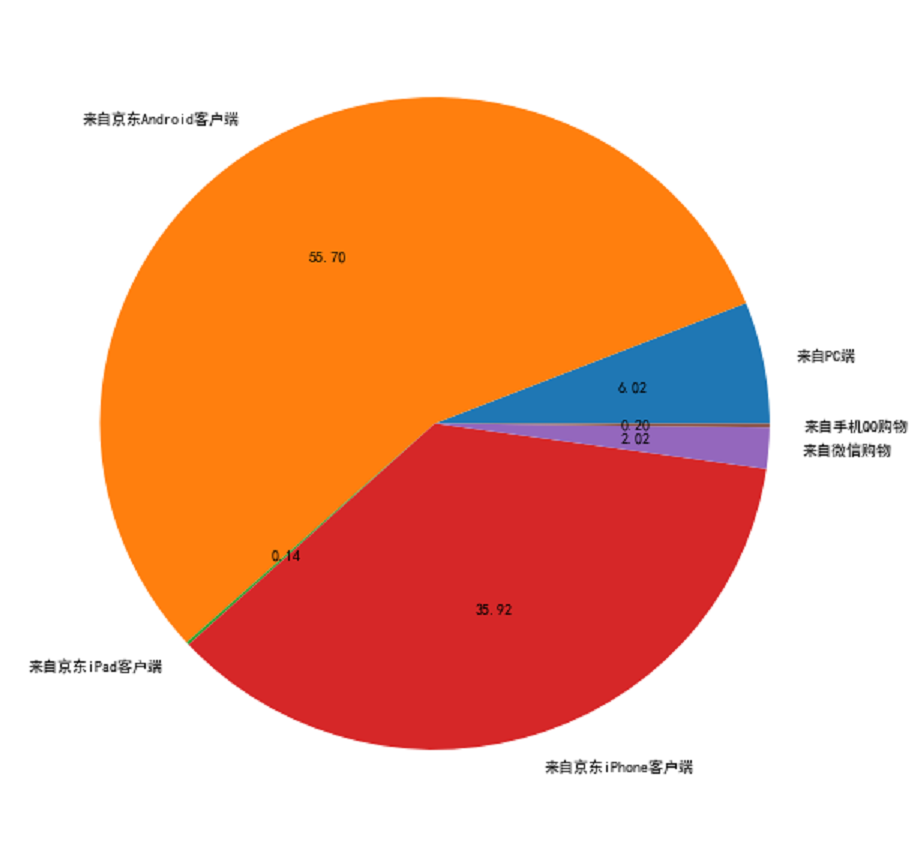
通过京东app购买TT的最多,91%的用户来自京东Android客户端和iphone客户端。6%的用户来自PC端,这几年4G的发展有关。
通过上面的分析可以知道,超薄的TT最受欢迎。杜杜的产品卖得最好,这和他们的营销方案有关,杜杜的文案可以称作教科书级的,每次发布文案都引起大家的讨论,堪称个个经典。移动客户端购买TT已经成为主流,占据90%以上的流量。
感谢各位的阅读!关于“如何通过selenium抓取某东的TT购买记录并分析趋势”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。