您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“Python爬虫某东商品评论信息采集流程分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python爬虫某东商品评论信息采集流程分析”吧!
一、接口查找
随意点击某一商品,跳转详情页,点击商品评价

继续下翻,查看评论展示页数,这里只显示100页
要查找真正的评论接口,直接刷新页面,找起来相当麻烦。
打开调试,清空请求内容,直接点击查看第二页的接口信息,如下图
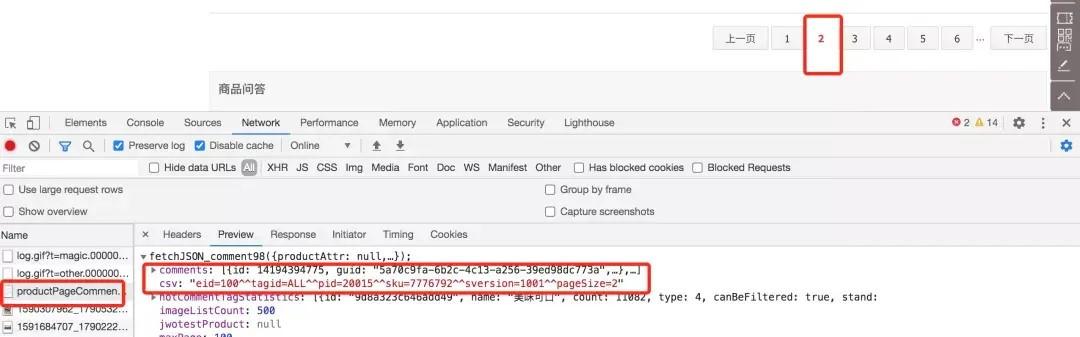
查看response信息,根据字段comments很容易判断这就是要找的评论接口,里面还包含了热门评论信息。
二、参数查找
先截图记录下点击第二页的请求参数
接着继续点击第三页内容,左侧搜索框中直接搜索productP,过滤无用的接口信息,查看请求参数,并和前一页的请求参数做比较。
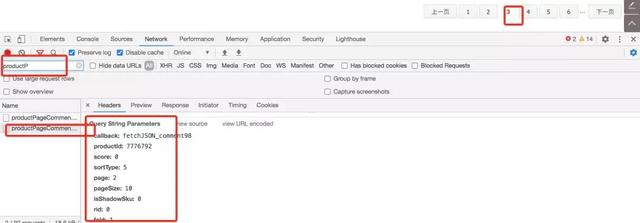
分析到这里可以得到如下结论
productId代表当前商品的ID,更换商品ID,便可以采集不同商品的评论
page代表访问的页数,这里计算页数从0开始,参数请求的页数等于实际点击的页数减1
三、代码测试
代码如下,请求时需要在headers中加入ua和referer,这里翻页只设置2
执行结果如下:

代码里只提取了商品ID,评论内容,评论时间,如下图红框标注的数据
如果要提取其他字段信息,可在代码中自行添加。
一、接口查找
搜索以食品为例,输入食品,点击搜索

继续下翻,查看商品返回页数,这里也是最大返回100页信息
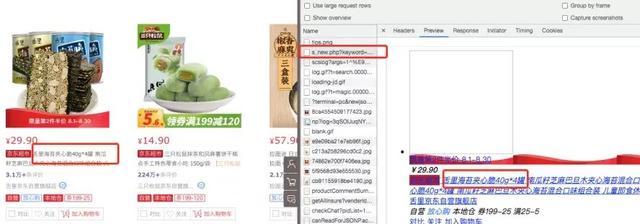
二、参数查找
同样的,根据下滑,翻页查看参数的变化

页面上商品展示信息较多,有可能出现会临时加载一次请求的可能,继续下翻,恰好可以看到新增了一次请求,请求参数如下,看着参数增多了。(注意:新增的参数可以忽略)
接着点击第三页

如果无法发现规律,可继续点击翻页查看变化规则。
接口参数的构造逻辑有以下几点:
每一页有两次请求,page初始值为1
s的值每次请求增加25,初始值为1
其他参数值不变,部分新增参数可以忽略
三、html页面解析
直接定位到页面商品位置,可以看到所有商品信息都在ul标签下的li标签里面
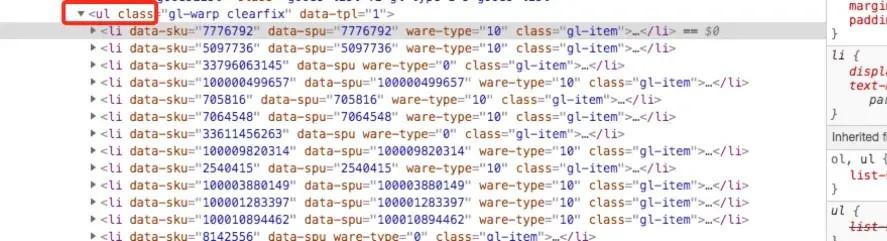
点击li标签,可以看到div/div下的a标签里面,包含商品title信息,商品链接信息,链接当中又包含我们需要提取的product_id信息,右键copy、copy xpath直接提取位置信息。
四、代码测试
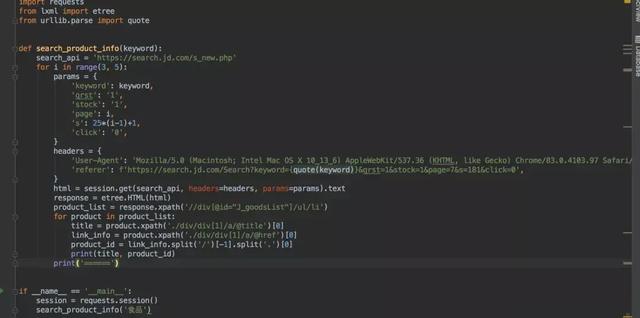
代码如下,注意headers中,referer参数需要进行url编码。
感谢各位的阅读,以上就是“Python爬虫某东商品评论信息采集流程分析”的内容了,经过本文的学习后,相信大家对Python爬虫某东商品评论信息采集流程分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。