您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
微博热搜的爬取较为简单,我只是用了lxml和requests两个库
url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6
1.分析网页的源代码:右键--查看网页源代码.
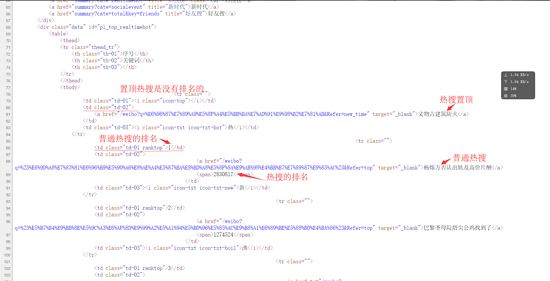
从网页代码中可以获取到信息
(1)热搜的名字都在<td class="td-02">的子节点<a>里
(2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是没有排名的!)
(3)热搜的访问量都在<td class="td-02">的子节点<span>里
2.requests获取网页
(1)先设置url地址,然后模拟浏览器(这一步可以不用)防止被认出是爬虫程序。
###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器,这个请求头windows下都能用
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
(2)利用req uests库的get()和lxml的etr ee()来获 取网页代码
###获取html页面 html=etree.HTML(requests.get(url,headers=header).text)
3.构造xpath路径
上面第一步中三个xath路径分别是:
affair=html.xpath('//td[@class="td-02"]/a/text()')
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
view=html.xpath('//td[@class="td-02"]/span/text()')
xpath的返回结果是列表,所以affair、rank、view都是字符串列表
4.格式化输出
需要注意的是affair中多了一个置顶热搜,我们先将他分离出来。
top=affair[0] affair=affair[1:]
这里利用了python的切片。
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
这里还是没能做到完全对齐。。。
5.全部代码
###导入模块
import requests
from lxml import etree
###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
###主函数
def main():
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
affair=html.xpath('//td[@class="td-02"]/a/text()')
view = html.xpath('//td[@class="td-02"]/span/text()')
top=affair[0]
affair=affair[1:]
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
main()
结果展示:

总结
以上所述是小编给大家介绍的Python网络爬虫之爬取微博热搜,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对亿速云网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。