жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪҝз”ЁpandasжҖҺд№ҲеҺ»йҮҚеӨҚиЎҢпјҹзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
ж•°жҚ®её§дҪңдёәдёҖдёӘдҫӢеӯҗпјҡ
import pandas as pd
data=pd.DataFrame({'дә§е“Ғ':['A','A','A','A'],'ж•°йҮҸ':[50,50,30,30]})pandasеҲӨж–ӯdataframeжҳҜеҗҰеҗ«жңүйҮҚеӨҚиЎҢж•°жҚ®з”Ёпјҡdf.duplicated()
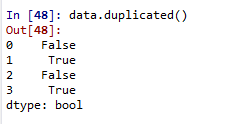
第дёҖж¬ЎеҮәзҺ°зҡ„ж•°жҚ®дёәFalse.йҮҚеӨҚзҡ„ж•°жҚ®иЎҢе°ұиў«и®°еҪ•дёәTrueгҖӮ
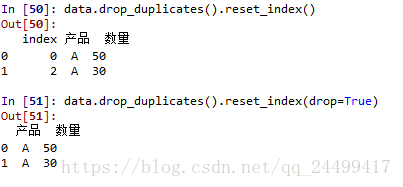
еҺ»жҺүйҮҚеӨҚиЎҢж•°жҚ®дҪҝз”Ёdata.drop_duplicates().

еҸҜд»ҘзңӢеҲ°зҙўеј•д№ұдәҶ,жҲ‘们дҪҝз”Ёdata.reset_index(),йҮҢйқўзҡ„еҸӮж•°drop=TrueпјҢиЎЁжҳҺиҰҒиҲҚжҺүеҺҹжқҘзҡ„зҙўеј•пјҢдёҚ然зҡ„иҜқеҺҹжқҘзҡ„зҙўеј•дјҡдҝқз•ҷдёӢжқҘгҖӮ
еҲҶзұ»жұҮжҖ»дё»иҰҒдҪҝз”Ёgroupby(иЎЁжҳҺжұҮжҖ»зҡ„жқЎд»¶еҲ—)д»ҘеҸҠagg(иҰҒжұҮжҖ»зҡ„еӯ—ж®ө/еҲ—д»ҘеҸҠжұҮжҖ»зҡ„ж–№ејҸпјҡжұӮе’ҢиҝҳжҳҜжңҖеӨ§жңҖе°ҸеҖјжҲ–иҖ…и®Ўж•°)гҖӮе®Ңж•ҙд»Јз ҒеҰӮдёӢеӣҫ
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 20 09:08:10 2018
@author: FanXiaoLei
"""
import pandas as pd
data=pd.DataFrame({'дә§е“Ғ':['A','A','A','A'],'ж•°йҮҸ':[50,50,30,30]})
if data.duplicated:
dataA=data.drop_duplicates().reset_index(drop=True)
print(dataA)
dataB=dataA.groupby(by='дә§е“Ғ').agg({'ж•°йҮҸ':sum})
print('ж•°жҚ®жұҮжҖ»з»“жһң:')
print(dataB)з»“жһңеұ•зӨәеҰӮдёӢеӣҫпјҡ

зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎдҪҝз”ЁpandasжҖҺд№ҲеҺ»йҮҚеӨҚиЎҢзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ