жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»Ӣз»Қ
жң¬ж–Үе°Ҷеұ•зӨәеҰӮдҪ•еҲ©з”ЁPythonзҲ¬иҷ«жқҘе®һзҺ°иҜ—жӯҢжҺҘйҫҷгҖӮ
иҜҘйЎ№зӣ®зҡ„жҖқи·ҜеҰӮдёӢпјҡ
еҲ©з”ЁзҲ¬иҷ«зҲ¬еҸ–иҜ—жӯҢпјҢеҲ¶дҪңиҜ—жӯҢиҜӯж–ҷеә“пјӣ
е°ҶиҜ—жӯҢеҲҶеҸҘпјҢеҪўжҲҗеӯ—е…ёпјҡй”®пјҲkeyпјүдёәиҜҘеҸҘйҰ–еӯ—зҡ„жӢјйҹіпјҢеҖјпјҲvalueпјүдёәиҜҘжӢјйҹіеҜ№еә”зҡ„иҜ—еҸҘпјҢ并е°Ҷеӯ—е…ёдҝқеӯҳдёәpickleж–Ү件пјӣ
иҜ»еҸ–pickleж–Ү件пјҢзј–еҶҷзЁӢеәҸпјҢд»Ҙexeж–Ү件еҪўејҸиҝҗиЎҢиҜҘзЁӢеәҸгҖӮ
иҜҘйЎ№зӣ®е®һзҺ°зҡ„иҜ—жӯҢжҺҘйҫҷпјҢ规еҲҷдёәдёӢдёҖеҸҘзҡ„йҰ–еӯ—дёҺдёҠдёҖеҸҘзҡ„е°ҫеӯ—зҡ„жӢјйҹіпјҲеҢ…жӢ¬еЈ°и°ғпјүдёҖиҮҙгҖӮдёӢйқўе°ҶеҲҶжӯҘи®Іиҝ°иҜҘйЎ№зӣ®зҡ„е®һзҺ°иҝҮзЁӢгҖӮ
иҜ—жӯҢиҜӯж–ҷеә“
йҰ–е…ҲпјҢжҲ‘们еҲ©з”ЁPythonзҲ¬иҷ«жқҘзҲ¬еҸ–иҜ—жӯҢпјҢеҲ¶дҪңиҜӯж–ҷеә“гҖӮзҲ¬еҸ–зҡ„зҪ‘еқҖдёәпјҡhttps://www.gushiwen.orgпјҢйЎөйқўеҰӮдёӢпјҡ
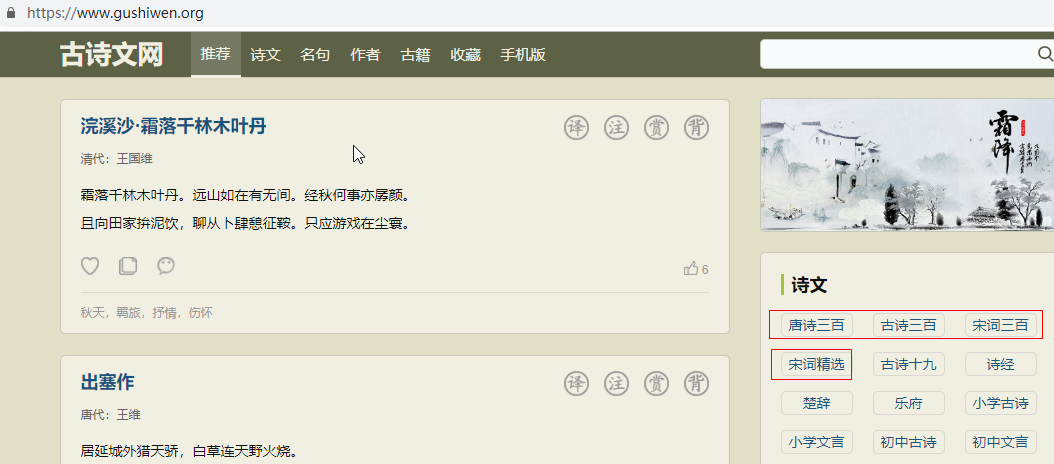
з”ұдәҺжң¬ж–Үдё»иҰҒдёәиҜ•дәҶеұ•зӨәиҜҘйЎ№зӣ®зҡ„жҖқи·ҜпјҢеӣ жӯӨпјҢеҸӘзҲ¬еҸ–дәҶиҜҘйЎөйқўдёӯзҡ„е”җиҜ—дёүзҷҫйҰ–гҖҒеҸӨиҜ—дёүзҷҫгҖҒе®ӢиҜҚдёүзҷҫгҖҒе®ӢиҜҚзІҫйҖүпјҢдёҖе…ұеӨ§зәҰ1100еӨҡйҰ–иҜ—жӯҢгҖӮдёәдәҶеҠ йҖҹзҲ¬иҷ«пјҢйҮҮ用并еҸ‘е®һзҺ°зҲ¬иҷ«пјҢ并дҝқеӯҳеҲ°poem.txtж–Ү件гҖӮе®Ңж•ҙзҡ„PythonзЁӢеәҸеҰӮдёӢпјҡ
import re
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# зҲ¬еҸ–зҡ„иҜ—жӯҢзҪ‘еқҖ
urls = ['https://so.gushiwen.org/gushi/tangshi.aspx',
'https://so.gushiwen.org/gushi/sanbai.aspx',
'https://so.gushiwen.org/gushi/songsan.aspx',
'https://so.gushiwen.org/gushi/songci.aspx'
]
poem_links = []
# иҜ—жӯҢзҡ„зҪ‘еқҖ
for url in urls:
# иҜ·жұӮеӨҙйғЁ
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
content = soup.find_all('div', class_="sons")[0]
links = content.find_all('a')
for link in links:
poem_links.append('https://so.gushiwen.org'+link['href'])
poem_list = []
# зҲ¬еҸ–иҜ—жӯҢйЎөйқў
def get_poem(url):
#url = 'https://so.gushiwen.org/shiwenv_45c396367f59.aspx'
# иҜ·жұӮеӨҙйғЁ
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
poem = soup.find('div', class_='contson').text.strip()
poem = poem.replace(' ', '')
poem = re.sub(re.compile(r"\([\s\S]*?\)"), '', poem)
poem = re.sub(re.compile(r"пјҲ[\s\S]*?пјү"), '', poem)
poem = re.sub(re.compile(r"гҖӮ\([\s\S]*?пјү"), '', poem)
poem = poem.replace('!', 'пјҒ').replace('?', 'пјҹ')
poem_list.append(poem)
# еҲ©з”Ёе№¶еҸ‘зҲ¬еҸ–
executor = ThreadPoolExecutor(max_workers=10) # еҸҜд»ҘиҮӘе·ұи°ғж•ҙmax_workers,еҚізәҝзЁӢзҡ„дёӘж•°
# submit()зҡ„еҸӮж•°пјҡ 第дёҖдёӘдёәеҮҪж•°пјҢ д№ӢеҗҺдёәиҜҘеҮҪж•°зҡ„дј е…ҘеҸӮж•°пјҢе…Ғи®ёжңүеӨҡдёӘ
future_tasks = [executor.submit(get_poem, url) for url in poem_links]
# зӯүеҫ…жүҖжңүзҡ„зәҝзЁӢе®ҢжҲҗпјҢжүҚиҝӣе…ҘеҗҺз»ӯзҡ„жү§иЎҢ
wait(future_tasks, return_when=ALL_COMPLETED)
# е°ҶзҲ¬еҸ–зҡ„иҜ—еҸҘеҶҷе…Ҙtxtж–Ү件
poems = list(set(poem_list))
poems = sorted(poems, key=lambda x:len(x))
for poem in poems:
poem = poem.replace('гҖҠ','').replace('гҖӢ','') \
.replace('пјҡ', '').replace('вҖң', '')
print(poem)
with open('F://poem.txt', 'a') as f:
f.write(poem)
f.write('\n')
иҜҘзЁӢеәҸзҲ¬еҸ–дәҶ1100еӨҡйҰ–иҜ—жӯҢпјҢ并е°ҶиҜ—жӯҢдҝқеӯҳиҮіpoem.txtж–Ү件пјҢеҪўжҲҗжҲ‘们зҡ„иҜ—жӯҢиҜӯж–ҷеә“гҖӮеҪ“然пјҢиҝҷдәӣиҜ—жӯҢ并дёҚиғҪзӣҙжҺҘдҪҝз”ЁпјҢйңҖиҰҒжё…зҗҶж•°жҚ®пјҢжҜ”еҰӮжңүдәӣиҜ—жӯҢж ҮзӮ№дёҚ规иҢғпјҢжңүдәӣ并дёҚжҳҜиҜ—жӯҢпјҢеҸӘжҳҜиҜ—жӯҢзҡ„еәҸзӯүзӯүпјҢиҝҷдёӘиҝҮзЁӢйңҖиҰҒдәәе·Ҙж“ҚдҪңпјҢиҷҪ然зЁҚжҳҫйә»зғҰпјҢдҪҶдёәдәҶеҗҺйқўзҡ„иҜ—жӯҢеҲҶеҸҘж•ҲжһңпјҢд№ҹжҳҜеҖјеҫ—зҡ„гҖӮ
иҜ—жӯҢеҲҶеҸҘ
жңүдәҶиҜ—жӯҢиҜӯж–ҷеә“пјҢжҲ‘们йңҖиҰҒеҜ№иҜ—жӯҢиҝӣиЎҢеҲҶеҸҘпјҢеҲҶеҸҘзҡ„ж ҮеҮҶдёәпјҡжҢүз…§з»“е°ҫдёәгҖӮпјҹпјҒиҝӣиЎҢеҲҶеҸҘпјҢиҝҷеҸҜд»Ҙз”ЁжӯЈеҲҷиЎЁиҫҫејҸе®һзҺ°гҖӮд№ӢеҗҺпјҢе°ҶеҲҶеҸҘеҘҪзҡ„иҜ—жӯҢеҶҷжҲҗеӯ—е…ёпјҡй”®пјҲkeyпјүдёәиҜҘеҸҘйҰ–еӯ—зҡ„жӢјйҹіпјҢеҖјпјҲvalueпјүдёәиҜҘжӢјйҹіеҜ№еә”зҡ„иҜ—еҸҘпјҢ并е°Ҷеӯ—е…ёдҝқеӯҳдёәpickleж–Ү件гҖӮе®Ңж•ҙзҡ„Pythonд»Јз ҒеҰӮдёӢпјҡ
import re
import pickle
from xpinyin import Pinyin
from collections import defaultdict
def main():
with open('F://poem.txt', 'r') as f:
poems = f.readlines()
sents = []
for poem in poems:
parts = re.findall(r'[\s\S]*?[гҖӮпјҹпјҒ]', poem.strip())
for part in parts:
if len(part) >= 5:
sents.append(part)
poem_dict = defaultdict(list)
for sent in sents:
print(part)
head = Pinyin().get_pinyin(sent, tone_marks='marks', splitter=' ').split()[0]
poem_dict[head].append(sent)
with open('./poemDict.pk', 'wb') as f:
pickle.dump(poem_dict, f)
main()
жҲ‘们еҸҜд»ҘзңӢдёҖдёӢиҜҘpickleж–Ү件пјҲpoemDict.pkпјүзҡ„еҶ…е®№пјҡ

еҪ“然пјҢдёҖдёӘжӢјйҹіеҸҜд»ҘеҜ№еә”еӨҡдёӘиҜ—жӯҢгҖӮ
иҜ—жӯҢжҺҘйҫҷ
иҜ»еҸ–pickleж–Ү件пјҢзј–еҶҷзЁӢеәҸпјҢд»Ҙexeж–Ү件еҪўејҸиҝҗиЎҢиҜҘзЁӢеәҸгҖӮ
дёәдәҶиғҪеӨҹеңЁзј–иҜ‘еҪўжҲҗexeж–Ү件зҡ„ж—¶еҖҷдёҚеҮәй”ҷпјҢжҲ‘们йңҖиҰҒж”№еҶҷxpinyinжЁЎеқ—зҡ„_init_.pyж–Ү件пјҢе°ҶиҜҘж–Ү件зҡ„е…ЁйғЁд»Јз ҒеӨҚеҲ¶иҮіmypinyin.pyпјҢ并е°Ҷд»Јз Ғдёӯзҡ„дёӢйқўиҝҷеҸҘд»Јз Ғ
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),
'Mandarin.dat')
ж”№еҶҷдёә
data_path = os.path.join(os.getcwd(), 'Mandarin.dat')
иҝҷж ·жҲ‘们е°ұе®ҢжҲҗдәҶmypinyin.pyж–Ү件гҖӮ
жҺҘдёӢжқҘпјҢжҲ‘们йңҖиҰҒзј–еҶҷиҜ—жӯҢжҺҘйҫҷзҡ„д»Јз ҒпјҲPoem_Jielong.pyпјүпјҢе®Ңж•ҙд»Јз ҒеҰӮдёӢпјҡ
import pickle
from mypinyin import Pinyin
import random
import ctypes
STD_INPUT_HANDLE = -10
STD_OUTPUT_HANDLE = -11
STD_ERROR_HANDLE = -12
FOREGROUND_DARKWHITE = 0x07 # жҡ—зҷҪиүІ
FOREGROUND_BLUE = 0x09 # и“қиүІ
FOREGROUND_GREEN = 0x0a # з»ҝиүІ
FOREGROUND_SKYBLUE = 0x0b # еӨ©и“қиүІ
FOREGROUND_RED = 0x0c # зәўиүІ
FOREGROUND_PINK = 0x0d # зІүзәўиүІ
FOREGROUND_YELLOW = 0x0e # й»„иүІ
FOREGROUND_WHITE = 0x0f # зҷҪиүІ
std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE)
# и®ҫзҪ®CMDж–Үеӯ—йўңиүІ
def set_cmd_text_color(color, handle=std_out_handle):
Bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color)
return Bool
# йҮҚзҪ®ж–Үеӯ—йўңиүІдёәжҡ—зҷҪиүІ
def resetColor():
set_cmd_text_color(FOREGROUND_DARKWHITE)
# еңЁCMDдёӯд»ҘжҢҮе®ҡйўңиүІиҫ“еҮәж–Үеӯ—
def cprint(mess, color):
color_dict = {
'и“қиүІ': FOREGROUND_BLUE,
'з»ҝиүІ': FOREGROUND_GREEN,
'еӨ©и“қиүІ': FOREGROUND_SKYBLUE,
'зәўиүІ': FOREGROUND_RED,
'зІүзәўиүІ': FOREGROUND_PINK,
'й»„иүІ': FOREGROUND_YELLOW,
'зҷҪиүІ': FOREGROUND_WHITE
}
set_cmd_text_color(color_dict[color])
print(mess)
resetColor()
color_list = ['и“қиүІ','з»ҝиүІ','еӨ©и“қиүІ','зәўиүІ','зІүзәўиүІ','й»„иүІ','зҷҪиүІ']
# иҺ·еҸ–еӯ—е…ё
with open('./poemDict.pk', 'rb') as f:
poem_dict = pickle.load(f)
#for key, value in poem_dict.items():
#print(key, value)
MODE = str(input('Choose MODE(1 for дәәе·ҘжҺҘйҫҷ, 2 for жңәеҷЁжҺҘйҫҷ): '))
while True:
try:
if MODE == '1':
enter = str(input('\nиҜ·иҫ“е…ҘдёҖеҸҘиҜ—жҲ–дёҖдёӘеӯ—ејҖе§Ӣпјҡ'))
while enter != 'exit':
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')
tail = test.split()[-1]
if tail not in poem_dict.keys():
cprint('ж— жі•жҺҘиҝҷеҸҘиҜ—гҖӮ\n', 'зәўиүІ')
MODE = 0
break
else:
cprint('\nжңәеҷЁеӣһеӨҚпјҡ%s'%random.sample(poem_dict[tail], 1)[0], random.sample(color_list, 1)[0])
enter = str(input('дҪ зҡ„еӣһеӨҚпјҡ'))[:-1]
MODE = 0
if MODE == '2':
enter = input('\nиҜ·иҫ“е…ҘдёҖеҸҘиҜ—жҲ–дёҖдёӘеӯ—ејҖе§Ӣпјҡ')
for i in range(10):
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')
tail = test.split()[-1]
if tail not in poem_dict.keys():
cprint('------>ж— жі•жҺҘдёӢеҺ»дәҶе•Ұ...', 'зәўиүІ')
MODE = 0
break
else:
answer = random.sample(poem_dict[tail], 1)[0]
cprint('пјҲ%dпјү--> %s' % (i+1, answer), random.sample(color_list, 1)[0])
enter = answer[:-1]
print('\nпјҲ*****жңҖеӨҡеұ•зӨәеүҚ10еӣһжҺҘйҫҷгҖӮ*****пјү')
MODE = 0
except Exception as err:
print(err)
finally:
if MODE not in ['1','2']:
MODE = str(input('\nChoose MODE(1 for дәәе·ҘжҺҘйҫҷ, 2 for жңәеҷЁжҺҘйҫҷ): '))
зҺ°еңЁж•ҙдёӘйЎ№зӣ®зҡ„з»“жһ„еҰӮдёӢпјҲMandarin.datж–Ү件д»ҺxpinyinжЁЎеқ—еҜ№еә”зҡ„ж–Ү件еӨ№дёӢеӨҚеҲ¶иҝҮжқҘпјүпјҡ
еҲҮжҚўиҮіиҜҘж–Ү件еӨ№пјҢиҫ“е…Ҙд»ҘдёӢе‘Ҫд»ӨеҚіеҸҜз”ҹжҲҗexeж–Ү件пјҡ
pyinstaller -F Poem_jielong.py
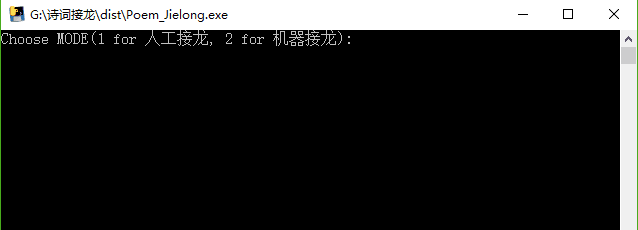
жң¬йЎ№зӣ®зҡ„иҜ—жӯҢжҺҘйҫҷжңүдёӨз§ҚжЁЎејҸпјҢдёҖз§Қдёәдәәе·ҘжҺҘйҫҷпјҢе°ұжҳҜдҪ е…Ҳиҫ“е…ҘдёҖеҸҘиҜ—жҲ–дёҖдёӘеӯ—пјҢ然еҗҺе°ұжҳҜи®Ўз®—жңәеӣһеӨҚдёҖеҸҘпјҢдҪ еӣһеӨҚдёҖеҸҘпјҢиҙҹиҙЈиҜ—жӯҢжҺҘйҫҷзҡ„规еҲҷпјӣеҸҰдёҖз§ҚжЁЎејҸдёәжңәеҷЁжҺҘйҫҷпјҢе°ұжҳҜдҪ е…Ҳиҫ“е…ҘдёҖеҸҘиҜ—жҲ–дёҖдёӘеӯ—пјҢжңәеҷЁдјҡиҮӘеҠЁиҫ“еҮәеҗҺйқўзҡ„жҺҘйҫҷиҜ—еҸҘпјҲжңҖеӨҡ10дёӘпјүгҖӮ
е…ҲжөӢиҜ•дәәе·ҘжҺҘйҫҷжЁЎејҸпјҡ
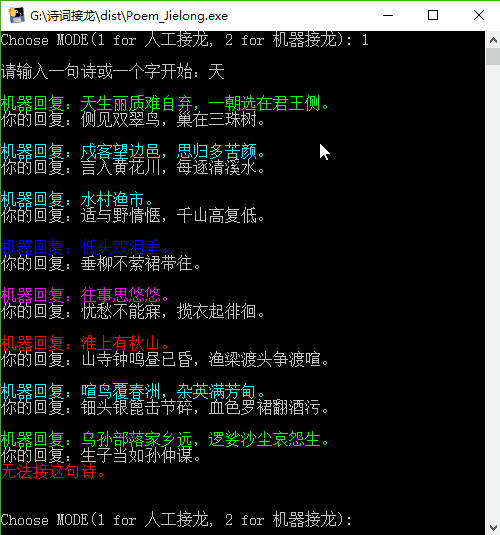
еҶҚжөӢиҜ•жңәеҷЁжҺҘйҫҷжЁЎејҸпјҡ
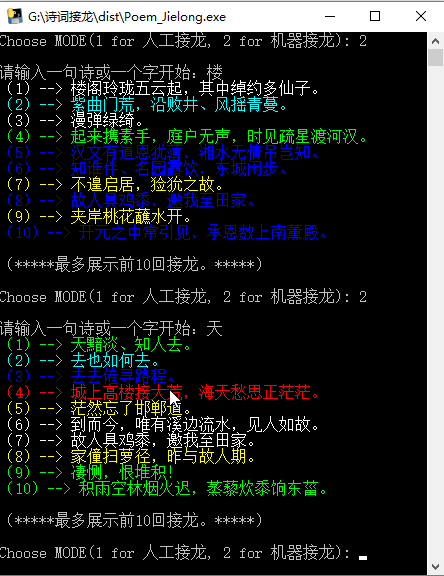
жҖ»з»“
иҜҘйЎ№зӣ®зҡ„Githubең°еқҖдёәпјҡhttps://github.com/percent4/Shicijielong
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ