жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үе®һдҫӢи®Іиҝ°дәҶPythonзҲ¬иҷ«жЎҶжһ¶Scrapyеҹәжң¬з”Ёжі•гҖӮеҲҶдә«з»ҷеӨ§е®¶дҫӣеӨ§е®¶еҸӮиҖғпјҢе…·дҪ“еҰӮдёӢпјҡ
Xpath
<html> <head> <title>ж Үйўҳ</title> </head> <body> <h3>дәҢзә§ж Үйўҳ</h3> <p>зҲ¬иҷ«1</p> <p>зҲ¬иҷ«2</p> </body> </html>
еңЁдёҠиҝ°htmlд»Јз ҒдёӯпјҢжҲ‘иҰҒиҺ·еҸ–h3зҡ„еҶ…е®№,жҲ‘们еҸҜд»ҘдҪҝз”Ёд»ҘдёӢд»Јз ҒиҝӣиЎҢиҺ·еҸ–пјҡ
info = response.xpath("/html/body/h3/text()")
еҸҜд»ҘзңӢеҮә/html/body/h3дёәеҶ…е®№зҡ„еұӮж¬Ўз»“жһ„пјҢtext()еҲҷжҳҜиҺ·еҸ–h3ж Үзӯҫзҡ„еҶ…е®№гҖӮ//pиҺ·еҸ–жүҖжңүpж ҮзӯҫгҖӮиҺ·еҸ–еёҰе…·дҪ“еұһжҖ§зҡ„ж Үзӯҫпјҡ//ж Үзӯҫ[@еұһжҖ§="еұһжҖ§еҖј"]
<div class="hide"></div>
иҺ·еҸ–classдёәhideзҡ„divж Үзӯҫ
div[@class="hide"]
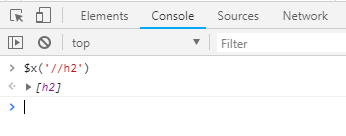
еҶҚжҜ”еҰӮпјҢжҲ‘们еңЁи°·жӯҢChromeжөҸи§ҲеҷЁдёҠзҡ„Consoleз•ҢйқўдҪҝз”Ё$x['//h3']е‘Ҫд»ӨиҺ·еҸ–йЎөйқўдёӯзҡ„h3е…ғзҙ дҝЎжҒҜпјҡ
xmlfeedжЁЎжқҝ
еҲӣе»әдёҖдёӘxmlfeedжЁЎжқҝзҡ„зҲ¬иҷ«
scrapy genspider -t xmlfeed abc iqianyue.com
ж ёеҝғд»Јз Ғ:
from scrapy.spiders import XMLFeedSpider
class AbcSpider(XMLFeedSpider):
name = 'abc'
start_urls = ['http://yum.iqianyue.com/weisuenbook/pyspd/part12/test.xml']
iterator = 'iternodes' # иҝӯд»ЈеҷЁпјҢй»ҳи®ӨдёәiternodesпјҢжҳҜдёҖдёӘеҹәдәҺжӯЈеҲҷиЎЁиҫҫејҸзҡ„й«ҳжҖ§иғҪиҝӯд»ЈеҷЁгҖӮйҷӨдәҶiternodes,иҝҳжңүвҖңhtmlвҖқе’ҢвҖңxmlвҖқ
itertag = 'person' # и®ҫзҪ®д»Һе“ӘдёӘиҠӮзӮ№(ж Үзӯҫ)ејҖе§Ӣиҝӯд»Ј
# parse_nodeдјҡеңЁиҠӮзӮ№дёҺжҸҗдҫӣзҡ„ж ҮзӯҫеҗҚзӣёз¬Ұж—¶иҮӘеҠЁи°ғз”Ё
def parse_node(self, response, selector):
i = {}
xpath = "/person/email/text()"
info = selector.xpath(xpath).extract()
print(info)
return i
csvfeedжЁЎжқҝ
еҲӣе»әдёҖдёӘcsvfeedжЁЎжқҝзҡ„зҲ¬иҷ«
scrapy genspider -t csvfeed csvspider iqianyue.com
ж ёеҝғд»Јз Ғ
from scrapy.spiders import CSVFeedSpider
class CsvspiderSpider(CSVFeedSpider):
name = 'csvspider'
allowed_domains = ['iqianyue.com']
start_urls = ['http://yum.iqianyue.com/weisuenbook/pyspd/part12/mydata.csv']
# headers дё»иҰҒеӯҳж”ҫcsvж–Ү件дёӯеҢ…еҗ«зҡ„з”ЁдәҺжҸҗеҸ–еӯ—ж®өзҡ„дҝЎжҒҜеҲ—иЎЁ
headers = ['name', 'sex', 'addr', 'email']
# delimiter еӯ—ж®өд№Ӣй—ҙзҡ„й—ҙйҡ”
delimiter = ','
def parse_row(self, response, row):
i = {}
name = row["name"]
sex = row["sex"]
addr = row["addr"]
email = row["email"]
print(name,sex,addr,email)
#i['url'] = row['url']
#i['name'] = row['name']
#i['description'] = row['description']
return i
crawlfeedжЁЎжқҝ
еҲӣе»әдёҖдёӘcrawlfeedжЁЎжқҝзҡ„зҲ¬иҷ«
scrapy genspider -t crawlfeed crawlspider sohu.com
ж ёеҝғд»Јз Ғ
class CrawlspiderSpider(CrawlSpider):
name = 'crawlspider'
allowed_domains = ['sohu.com']
start_urls = ['http://sohu.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
дёҠйқўд»Јз ҒrulesйғЁеҲҶдёӯзҡ„LinkExtractorдёәиҝһжҺҘжҸҗеҸ–еҷЁгҖӮ
LinkExtractorдёӯеҜ№еә”зҡ„еҸӮж•°еҸҠеҗ«д№ү
| еҸӮж•°еҗҚ | еҸӮж•°еҗ«д№ү |
|---|---|
| allow | жҸҗеҸ–з¬ҰеҗҲжӯЈеҲҷиЎЁиҫҫејҸзҡ„й“ҫжҺҘ |
| deny | дёҚжҸҗеҸ–з¬ҰеҗҲжӯЈеҲҷиЎЁиҫҫејҸзҡ„й“ҫжҺҘ |
| restrict_xpaths | дҪҝз”ЁXPathиЎЁиҫҫејҸдёҺallowе…ұеҗҢдҪңз”ЁжҸҗеҸ–еҗҢж—¶з¬ҰеҗҲеҜ№еә”XPathиЎЁиҫҫејҸе’ҢеҜ№еә”жӯЈеҲҷиЎЁиҫҫејҸзҡ„й“ҫжҺҘ |
| allow_domains | е…Ғи®ёжҸҗеҸ–зҡ„еҹҹеҗҚпјҢжҜ”еҰӮжҲ‘们жғіеҸӘжҸҗеҸ–жҹҗдёӘеҹҹеҗҚдёӢзҡ„й“ҫжҺҘж—¶дјҡз”ЁеҲ° |
| deny_domains | иҝӣеҲ¶жҸҗеҸ–зҡ„еҹҹеҗҚ |
жӣҙеӨҡе…ідәҺPythonзӣёе…іеҶ…е®№еҸҜжҹҘзңӢжң¬з«ҷдё“йўҳпјҡгҖҠPython Socketзј–зЁӢжҠҖе·§жҖ»з»“гҖӢгҖҒгҖҠPythonжӯЈеҲҷиЎЁиҫҫејҸз”Ёжі•жҖ»з»“гҖӢгҖҒгҖҠPythonж•°жҚ®з»“жһ„дёҺз®—жі•ж•ҷзЁӢгҖӢгҖҒгҖҠPythonеҮҪж•°дҪҝз”ЁжҠҖе·§жҖ»з»“гҖӢгҖҒгҖҠPythonеӯ—з¬ҰдёІж“ҚдҪңжҠҖе·§жұҮжҖ»гҖӢгҖҒгҖҠPythonе…Ҙй—ЁдёҺиҝӣйҳ¶з»Ҹе…ёж•ҷзЁӢгҖӢеҸҠгҖҠPythonж–Ү件дёҺзӣ®еҪ•ж“ҚдҪңжҠҖе·§жұҮжҖ»гҖӢ
еёҢжңӣжң¬ж–ҮжүҖиҝ°еҜ№еӨ§е®¶PythonзЁӢеәҸи®ҫи®ЎжңүжүҖеё®еҠ©гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ