您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Python3怎么实现爬虫爬取数据并存入mysql数据库,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
Python主要应用于:1、Web开发;2、数据科学研究;3、网络爬虫;4、嵌入式应用开发;5、游戏开发;6、桌面应用开发。
具体如下:
抓包工具页面如图:
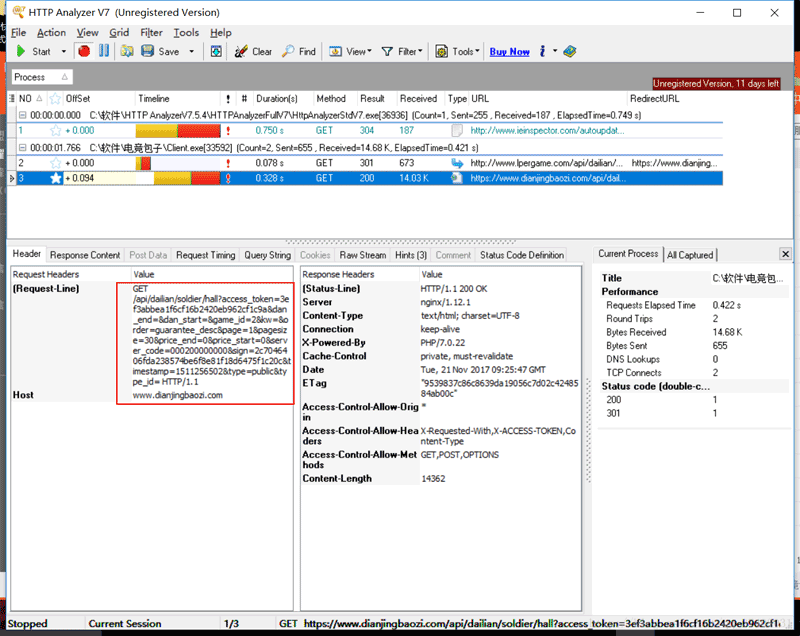
首先是爬虫,先找到数据存储的页面,再用正则爬出。
# -*- coding:utf-8 -*-
import re
import requests
import pymysql #Python3的mysql模块,Python2 是mysqldb
import datetime
import time
def GetResults():
requests.adapters.DEFAULT_RETRIES = 5 #有时候报错,我在网上找的不知道啥意思,好像也没用。
reg = [r'"id":(.*?),',
r'"order_no":"(.*?)",',
r'"order_title":"(.*?)",',
r'"publish_desc":"(.*?)",',
r'"game_area":"(.*?)\\/(.*?)\\/(.*?)",',
r'"order_current":"(.*?)",',
r'"order_content":"(.*?)",',
r'"order_hours":(.*?),',
r'"order_price":"(.*?)",',
r'"add_price":"(.*?)",',
r'"safe_money":"(.*?)",',
r'"speed_money":"(.*?)",',
r'"order_status_desc":"(.*?)",',
r'"order_lock_desc":"(.*?)",',
r'"cancel_type_desc":"(.*?)",',
r'"kf_status_desc":"(.*?)",',
r'"is_show_pwd":(.*?),',
r'"game_pwd":"(.*?)",',
r'"game_account":"(.*?)",',
r'"game_actor":"(.*?)",',
r'"left_hours":"(.*?)",',
r'"created_at":"(.*?)",',
r'"account_id":"(.*?)",',
r'"mobile":"(.*?)",',
r'"contact":"(.*?)",',
r'"qq":"(.*?)"},']
results=[]
try:
for l in range(1,2): #页码
proxy = {'HTTP':'61.135.155.82:443'} #代理ip
html = requests.get('https://www.dianjingbaozi.com/api/dailian/soldier/hall?access_token=3ef3abbea1f6cf16b2420eb962cf1c9a&dan_end=&dan_start=&game_id=2&kw=&order=price_desc&page=%d'%l+'&pagesize=30&price_end=0&price_start=0&server_code=000200000000&sign=ca19072ea0acb55a2ed2486d6ff6c5256c7a0773×tamp=1511235791&type=public&type_id=%20HTTP/1.1',proxies=proxy) # 用get的方式访问。网页解码成中文。接单大厅页。
#
html=html.content.decode('utf-8')
outcome_reg_order_no = re.findall(r'"order_no":"(.*?)","game_area"', html) #获取订单编号,因为订单详情页url与订单编号有关。
for j in range(len(outcome_reg_order_no)):
html_order = requests.get('http://www.lpergame.com/api/dailian/order/detail?access_token=eb547a14bad97e1ee5d835b32cb83ff1&order_no=' +outcome_reg_order_no[j] + '&sign=c9b503c0e4e8786c2945dc0dca0fabfa1ca4a870×tamp=1511146154 HTTP/1.1',proxies=proxy) #订单详细页
html_order=html_order.content.decode('utf-8')
# print(html_order)
outcome_reg = []
for i in range(len(reg)):#每条订单
outcome = re.findall(reg[i], html_order)
if i == 4:
for k in range(len(outcome)):
outcome_reg.extend(outcome[k])
else:
outcome_reg.extend(outcome)
results.append(outcome_reg) #结果集
return results
except:
time.sleep(5) #有时太频繁会报错。
print("失败")
pass根据爬虫结果建表,这里变量名要准确。并且要设置唯一索引,使每次爬的只有新订单入库。
def mysql_create():
mysql_host = ''
mysql_db = 'zyc'
mysql_user = 'zyc'
mysql_password = ''
mysql_port = 3306
db = pymysql.connect(host=mysql_host, port=mysql_port, user=mysql_user, password=mysql_password, db=mysql_db,charset='utf8') # 连接数据库编码注意是utf8,不然中文结果输出会乱码
sql_create = "CREATE TABLE DUMPLINGS (id CHAR(10),order_no CHAR(50),order_title VARCHAR(265),publish_desc VARCHAR(265),game_name VARCHAR(265),"\
"game_area VARCHAR(265),game_area_distinct VARCHAR(265),order_current VARCHAR(3908),order_content VARCHAR(3908),order_hours CHAR(10)," \
"order_price FLOAT(10),add_price FLOAT(10),safe_money FLOAT(10),speed_money FLOAT(10),order_status_desc VARCHAR(265),"\
"order_lock_desc VARCHAR(265),cancel_type_desc VARCHAR(265),kf_status_desc VARCHAR(265),is_show_pwd TINYINT,game_pwd CHAR(50),"\
"game_account VARCHAR(265),game_actor VARCHAR(265),left_hours VARCHAR(265),created_at VARCHAR(265),account_id CHAR(50),"\
"mobile VARCHAR(265),mobile2 VARCHAR(265),contact VARCHAR(265),contact2 VARCHAR(265),qq VARCHAR(265),"\
"PRIMARY KEY (`id`),UNIQUE KEY `no`(`order_no`))ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8"
sql_key="CREATE UNIQUE INDEX id ON DUMPLINGS(id)"
cursor = db.cursor()
cursor.execute("DROP TABLE IF EXISTS DUMPLINGS")
cursor.execute(sql_create)# 执行SQL语句
cursor.execute(sql_key)
db.close() # 关闭数据库连把数据导入Mysql,注意编码和字段之间的匹配。
def IntoMysql(results):
mysql_host = ''
mysql_db = 'zyc'
mysql_user = 'zyc'
mysql_password = ''
mysql_port = 3306
db = pymysql.connect(host=mysql_host, port=mysql_port, user=mysql_user, password=mysql_password, db=mysql_db,charset='utf8') # 连接数据库编码注意是utf8,不然中文结果输出会乱码
cursor = db.cursor()
for j in range(len(results)):
try:
sql = "INSERT INTO DUMPLINGS(id,order_no,order_title,publish_desc ,game_name," \
"game_area,game_area_distinct,order_current,order_content,order_hours," \
"order_price,add_price,safe_money,speed_money,order_status_desc," \
"order_lock_desc,cancel_type_desc,kf_status_desc,is_show_pwd,game_pwd," \
"game_account,game_actor,left_hours,created_at,account_id," \
"mobile,mobile2,contact,contact2,qq) VALUES ("
for i in range(len(results[j])):
sql = sql + "'" + results[j][i] + "',"
sql = sql[:-1] + ")"
sql = sql.encode('utf-8')
cursor.execute(sql)
db.commit()
except:pass
db.close()每十秒运行一次。
mysql_create()
i=0
while True:
results = GetResults()
IntoMysql(results)
i=i+1
print("爬虫次数:",i)
time.sleep(10)结果如图:
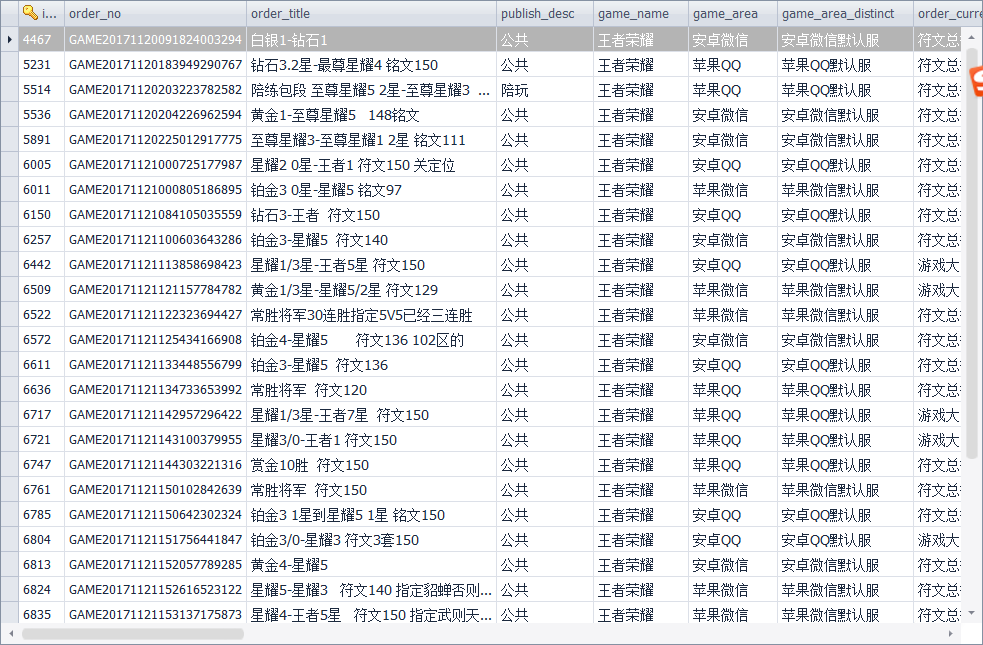
关于“Python3怎么实现爬虫爬取数据并存入mysql数据库”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。