жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үе®һдҫӢи®Іиҝ°дәҶPythonдҪҝз”ЁзҲ¬иҷ«зҲ¬еҸ–йқҷжҖҒзҪ‘йЎөеӣҫзүҮзҡ„ж–№жі•гҖӮеҲҶдә«з»ҷеӨ§е®¶дҫӣеӨ§е®¶еҸӮиҖғпјҢе…·дҪ“еҰӮдёӢпјҡ
зҲ¬иҷ«зҗҶи®әеҹәзЎҖ
е…¶е®һзҲ¬иҷ«жІЎжңүеӨ§е®¶жғіиұЎзҡ„йӮЈд№ҲеӨҚжқӮпјҢжңүж—¶еҖҷд№ҹе°ұжҳҜеҮ иЎҢд»Јз Ғзҡ„дәӢе„ҝпјҢеҚғдёҮдёҚиҰҒжҠҠиҮӘе·ұеҗ“еҖ’дәҶгҖӮиҝҷзҜҮе°ұжё…жҷ°ең°и®Іи§ЈдёҖдёӢеҲ©з”ЁPythonзҲ¬иҷ«зҡ„зҗҶи®әеҹәзЎҖгҖӮ
йҰ–е…ҲиҜҙжҳҺзҲ¬иҷ«еҲҶдёәдёүдёӘжӯҘйӘӨпјҢд№ҹе°ұйңҖиҰҒз”ЁеҲ°дёүдёӘе·Ҙе…·гҖӮ
в‘ еҲ©з”ЁзҪ‘йЎөдёӢиҪҪеҷЁе°ҶзҪ‘йЎөзҡ„жәҗз Ғзӯүиө„жәҗдёӢиҪҪгҖӮ
в‘Ў еҲ©з”ЁURLз®ЎзҗҶеҷЁз®ЎзҗҶдёӢиҪҪдёӢжқҘзҡ„URL
в‘ў еҲ©з”ЁзҪ‘йЎөи§ЈжһҗеҷЁи§ЈжһҗйңҖиҰҒзҡ„URLпјҢиҝӣиҖҢиҝӣиЎҢеҢ№й…ҚгҖӮ
зҪ‘йЎөдёӢиҪҪеҷЁ
зҪ‘йЎөдёӢиҪҪеҷЁеёёз”Ёзҡ„жңүдёӨдёӘгҖӮдёҖдёӘжҳҜPythonиҮӘеёҰзҡ„urllib2жЁЎеқ—пјӣеҸҰдёҖдёӘжҳҜ第дёүж–№жҺ§д»¶requestsгҖӮйҖүз”Ёе“ӘдёӘе…¶е®һе·®ејӮдёҚеӨ§пјҢдёӢдёҖзҜҮе°ҶдјҡиҝӣиЎҢе®һи·өж“ҚдҪңдёҫдҫӢгҖӮ
URLз®ЎзҗҶеҷЁ
urlз®ЎзҗҶеҷЁжңүдёүеӨ§зұ»гҖӮ
в‘ еҶ…еӯҳпјҡд»ҘsetеҪўејҸеӯҳеӮЁеңЁеҶ…еӯҳдёӯ
в‘Ў еӯҳеӮЁеңЁе…ізі»еһӢж•°жҚ®еә“mysqlзӯү
в‘ў зј“еӯҳж•°жҚ®еә“redisдёӯ
зҪ‘йЎөи§ЈжһҗеҷЁ
зҪ‘йЎөи§ЈжһҗеҷЁдёҖе…ұжңүеӣӣзұ»пјҡ
1.жӯЈеҲҷиЎЁиҫҫејҸпјҢдёҚиҝҮеҜ№дәҺеӨӘеӨҚжқӮзҡ„еҢ№й…Қе°ұдјҡжңүдәӣйҡҫеәҰпјҢеұһдәҺжЁЎзіҠеҢ№й…ҚгҖӮ
2.html.parserпјҢиҝҷжҳҜpythonиҮӘеёҰзҡ„и§Јжһҗе·Ҙе…·гҖӮ
3.Beautiful SoupпјҢдёҖз§Қ第дёүж–№жҺ§д»¶пјҢйЎҫеҗҚжҖқд№үпјҢзҫҺе‘ізҡ„жұӨпјҢз”Ёиө·жқҘзЎ®е®һеҫҲж–№дҫҝпјҢеҫҲејәеӨ§гҖӮ
4.lxmlпјҲapt.xmlпјүпјҢ第дёүж–№жҺ§д»¶гҖӮ
д»ҘдёҠзҡ„иҝҷдәӣе…ЁйғЁеұһдәҺз»“жһ„еҢ–и§ЈжһҗпјҲDOMж ‘пјү
д»Җд№ҲејҸз»“жһ„еҢ–и§ЈжһҗпјҲDOMпјүпјҹ
Document Object Model(DOM)жҳҜдёҖз§Қж ‘зҡ„еҪўејҸгҖӮ
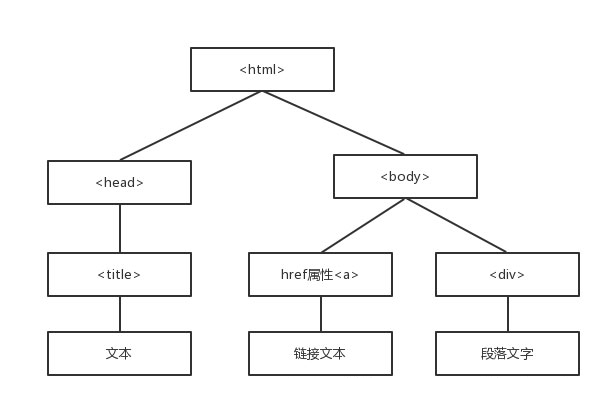
Beautiful Soupзҡ„иҜӯжі•
htmlзҪ‘йЎөвҖ”>еҲӣе»әBeautifulSoupеҜ№иұЎвҖ”>жҗңзҙўиҠӮзӮ№ find_allпјҲпјү/findпјҲпјүвҖ”>и®ҝй—®иҠӮзӮ№пјҢеҗҚз§°пјҢеұһжҖ§пјҢж–Үеӯ—зӯүвҖҰвҖҰ
Beautiful Soupе®ҳж–№ж–ҮжЎЈ
е®һзҺ°д»Јз Ғ
иҜҙиҝҮдәҶзҗҶи®әеҹәзЎҖпјҢйӮЈд№ҲзҺ°еңЁе°ұжқҘе®һи·өдёҖдёӘпјҢиҰҒзҲ¬еҸ–дёҖдёӘйқҷжҖҒзҪ‘йЎөзҡ„жүҖжңүеӣҫзүҮгҖӮ
иҝҷйҮҢдҪҝз”Ёзҡ„зҪ‘йЎөдёӢиҪҪеҷЁжҳҜpythonиҮӘеёҰзҡ„urllib2пјҢ然еҗҺеҲ©з”ЁжӯЈеҲҷиЎЁиҫҫејҸеҢ№й…ҚпјҢиҫ“еҮәз»“жһңгҖӮ
д»ҘдёӢдёәжәҗз Ғпјҡ
//еј•е…Ҙе°ҸйңҖиҰҒз”ЁеҲ°зҡ„жЁЎеқ—
import urllib2
import re
def main():
//еҲ©з”Ёurllib2зҡ„urlopenж–№жі•пјҢдёӢиҪҪеҪ“еүҚurlзҡ„зҪ‘йЎөеҶ…е®№
req = urllib2.urlopen('http://www.imooc.com/course/list')
//е°ҶзҪ‘йЎөеҶ…е®№еӯҳеӮЁеҲ°bufеҸҳйҮҸдёӯ
buf = req.read()
//е°Ҷbufдёӯзҡ„жүҖжңүеҶ…е®№дёҺйңҖиҰҒеҢ№й…Қзҡ„urlиҝӣиЎҢжҜ”еҜ№гҖӮиҝҷйҮҢзҡ„жӯЈеҲҷиЎЁиҫҫејҸжҳҜж №жҚ®йқҷжҖҒзҪ‘йЎөзҡ„жәҗз Ғеҫ—еҮәзҡ„пјҢжҹҘзңӢйқҷжҖҒзҪ‘йЎөжәҗз ҒејҖеҗҜејҖеҸ‘иҖ…жЁЎејҸпјҢжҢүF12еҚіеҸҜгҖӮ然еҗҺзЎ®е®ҡеӣҫзүҮеқ—пјҢжҹҘзңӢеҜ№еә”жәҗз ҒеҶ…е®№пјҢжүҫеҮә规еҫӢпјҢзј–еҶҷжӯЈеҲҷиЎЁиҫҫејҸгҖӮ
listurl = re.findall(r'src=.+\.jpg',buf)
i = 0
//е°Ҷз»“жһңеҫӘзҺҜеҶҷе…Ҙж–Ү件
for url in listurl:
f = open(str(i)+'.jpg','w')
req = urllib2.urlopen(url[5:])
buf1 = req.read()
f.write(buf1)
i+=1
if __name__ == '__main__':
main()
иҮіжӯӨдёҖдёӘйқҷжҖҒзҪ‘йЎөзҡ„еӣҫзүҮзҲ¬иҷ«е°ұе®ҢжҲҗдәҶпјҢдёӢйқўжқҘзңӢдёӢж•ҲжһңгҖӮ
иҝҷжҳҜйқҷжҖҒзҪ‘йЎөпјҡ
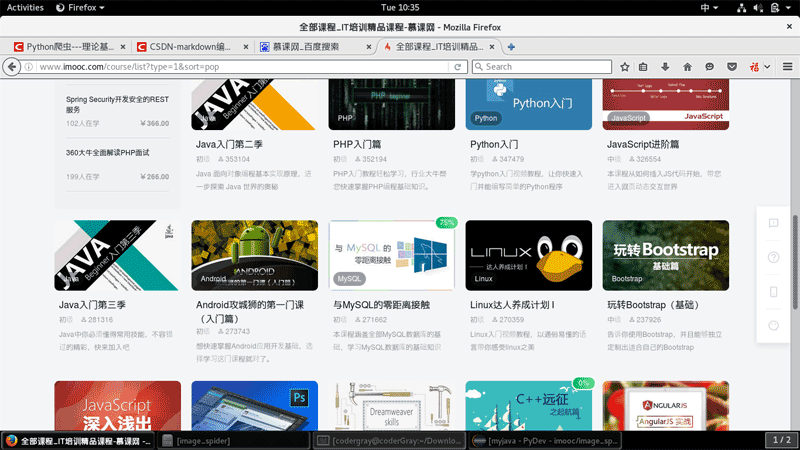
д»ҘдёӢжҳҜзҲ¬еҸ–зҡ„з»“жһңпјҡ

жӣҙеӨҡе…ідәҺPythonзӣёе…іеҶ…е®№еҸҜжҹҘзңӢжң¬з«ҷдё“йўҳпјҡгҖҠPython Socketзј–зЁӢжҠҖе·§жҖ»з»“гҖӢгҖҒгҖҠPythonжӯЈеҲҷиЎЁиҫҫејҸз”Ёжі•жҖ»з»“гҖӢгҖҒгҖҠPythonж•°жҚ®з»“жһ„дёҺз®—жі•ж•ҷзЁӢгҖӢгҖҒгҖҠPythonеҮҪж•°дҪҝз”ЁжҠҖе·§жҖ»з»“гҖӢгҖҒгҖҠPythonеӯ—з¬ҰдёІж“ҚдҪңжҠҖе·§жұҮжҖ»гҖӢгҖҒгҖҠPythonе…Ҙй—ЁдёҺиҝӣйҳ¶з»Ҹе…ёж•ҷзЁӢгҖӢеҸҠгҖҠPythonж–Ү件дёҺзӣ®еҪ•ж“ҚдҪңжҠҖе·§жұҮжҖ»гҖӢ
еёҢжңӣжң¬ж–ҮжүҖиҝ°еҜ№еӨ§е®¶PythonзЁӢеәҸи®ҫи®ЎжңүжүҖеё®еҠ©гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ