жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еңЁдјҒдёҡдёӯпјҢдёҖдәӣйҮҚиҰҒзҡ„ж•°жҚ®дёҖиҲ¬йғҪдјҡеӯҳеӮЁеңЁзЎ¬зӣҳдёӯпјҢиҷҪ然硬зӣҳжң¬иә«зҡ„жҖ§иғҪд№ҹеңЁдёҚж–ӯжҸҗй«ҳпјҢдҪҶжҳҜж— и®әзЎ¬зӣҳзҡ„еӯҳеҸ–йҖҹеәҰжңүеӨҡеҝ«пјҢдјҒдёҡжүҖиҝҪеҜ»зҡ„йҰ–е…ҲжҳҜеҸҜйқ жҖ§пјҢ然еҗҺжүҚжҳҜж•ҲзҺҮгҖӮеҰӮжһңж•°жҚ®йқўдёҙдёўеӨұзҡ„йЈҺйҷ©пјҢеҶҚеҘҪзҡ„硬件д№ҹж— жі•зҺ©дјҡдјҒдёҡзҡ„жҚҹеӨұпјҢеҠ д№Ӣиҝ‘еҮ е№ҙдә‘и®Ўз®—зҡ„еҮәзҺ°пјҢеҜ№еӯҳеӮЁжҸҗеҮәдәҶжӣҙй«ҳзҡ„иҰҒжұӮгҖӮиҖҢеҲҶеёғејҸеӯҳеӮЁйҖҗжёҗиў«дәә们жүҖжҺҘеҸ—пјҢе®ғе…·жңүжӣҙеҘҪзҡ„жҖ§иғҪгҖҒй«ҳжү©еұ•д»ҘеҸҠеҸҜйқ жҖ§гҖӮеӨ§йғЁеҲҶеҲҶеёғејҸи§ЈеҶіж–№жЎҲйғҪжҳҜйҖҡиҝҮе…ғжңҚеҠЎеҷЁеӯҳж”ҫзӣ®еҪ•з»“жһ„зӯүе…ғж•°жҚ®пјҢе…ғж•°жҚ®жңҚеҠЎеҷЁжҸҗдҫӣдәҶж•ҙдёӘеҲҶеёғејҸеӯҳеӮЁзҡ„зҙўеј•е·ҘдҪңгҖӮдҪҶжҳҜдёҖж—Ұе…ғж•°жҚ®жңҚеҠЎеҷЁжҚҹеқҸпјҢж•ҙдёӘеҲҶеёғејҸеӯҳеӮЁйғҪе°Ҷж— жі•иҝӣиЎҢе·ҘдҪңгҖӮдёӢйқўжҲ‘们е°Ҷд»Ӣз»ҚдёҖз§Қж— е…ғжңҚеҠЎеҷЁзҡ„еҲҶеёғејҸеӯҳеӮЁи§ЈеҶіж–№жЎҲвҖ”вҖ”GlusterFSгҖӮ
GlusterFSжҳҜдёҖдёӘејҖжәҗзҡ„еҲҶеёғејҸж–Ү件系з»ҹпјҢеҗҢж—¶д№ҹжҳҜScale-OutеӯҳеӮЁи§ЈеҶіж–№жЎҲGlusterFSзҡ„ж ёеҝғгҖӮеңЁеӯҳеӮЁж•°жҚ®ж–№йқўе…·жңүеҫҲејәеӨ§зҡ„жү©еұ•иғҪеҠӣпјҢйҖҡиҝҮжү©еұ•дёҚеҗҢзҡ„иҠӮзӮ№еҸҜд»Ҙж”ҜжҢҒPBзә§еҲ«зҡ„еӯҳеӮЁе®№йҮҸгҖӮGlusterFSеҖҹеҠ©TCP/IPжҲ–InfiniBand RDMAзҪ‘з»ңе°ҶеҲҶж•Јзҡ„еӯҳеӮЁиө„жәҗжұҮиҒҡеңЁдёҖиө·пјҢеҗҢдёҖжҸҗдҫӣеӯҳеӮЁжңҚеҠЎпјҢ并дҪҝз”ЁеҚ•дёҖе…ЁеұҖе‘Ҫд»Өз©әй—ҙжқҘз®ЎзҗҶж•°жҚ®гҖӮGlusterFSеҹәдәҺеҸҜе ҶеҸ зҡ„з”ЁжҲ·з©әй—ҙд»ҘеҸҠж— е…ғзҡ„и®ҫи®ЎпјҢеҸҜдёәеҗ„з§ҚдёҚеҗҢзҡ„ж•°жҚ®иҙҹиҪҪжҸҗдҫӣдјҳејӮзҡ„жҖ§иғҪгҖӮ
GlusterFSдё»иҰҒз”ұеӯҳеӮЁжңҚеҠЎеҷЁгҖҒе®ўжҲ·з«ҜеҸҠNFS/SambaеӯҳеӮЁзҪ‘е…іпјҲеҸҜйҖүпјҢж №жҚ®йңҖиҰҒйҖүжӢ©дҪҝз”Ёпјүз»„жҲҗгҖӮеҰӮеӣҫпјҡ
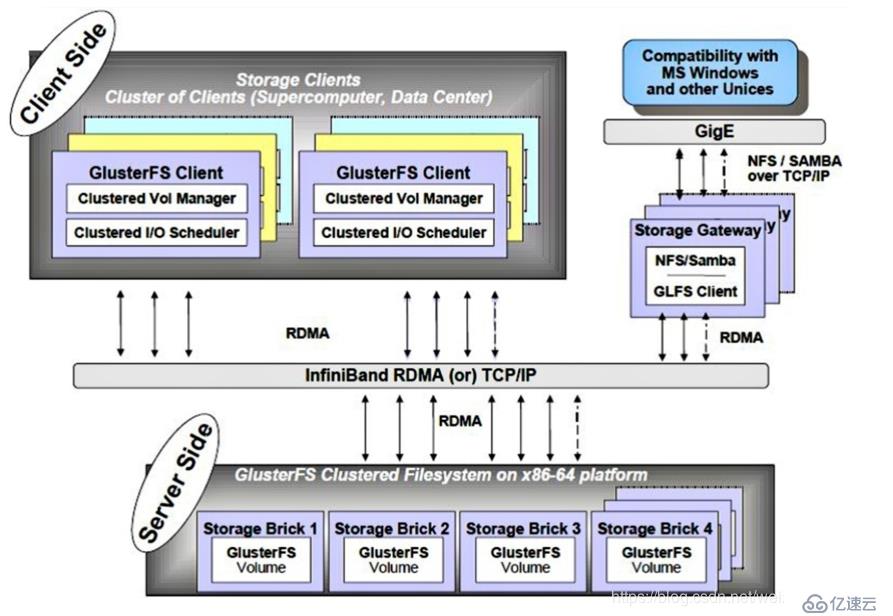
GlusterFSжһ¶жһ„дёӯжңҖеӨ§зҡ„и®ҫи®Ўзү№зӮ№е°ұжҳҜжІЎжңүе…ғж•°жҚ®жңҚеҠЎеҷЁз»„件пјҢиҝҷжңүеҠ©дәҺжҸҗеҚҮж•ҙдёӘзі»з»ҹзҡ„жҖ§иғҪгҖҒеҸҜйқ жҖ§е’ҢзЁіе®ҡжҖ§гҖӮдј з»ҹзҡ„еҲҶеёғејҸж–Ү件系з»ҹеӨ§еӨҡйҖҡиҝҮе…ғжңҚеҠЎеҷЁжқҘеӯҳеӮЁе…ғж•°жҚ®пјҢе…ғж•°жҚ®еҢ…еҗ«еӯҳеӮЁиҠӮзӮ№дёҠзҡ„зӣ®еҪ•дҝЎжҒҜгҖҒзӣ®еҪ•з»“жһ„зӯүпјҢиҝҷж ·зҡ„и®ҫи®ЎеңЁжөҸи§Ҳзӣ®еҪ•ж—¶ж•ҲзҺҮйқһеёёй«ҳпјҢдҪҶжҳҜд№ҹеӯҳеңЁдёҖдәӣзјәйҷ·пјҢеҰӮеҚ•зӮ№ж•…йҡңпјҢдёҖж—Ұе…ғж•°жҚ®жңҚеҠЎеҷЁеҮәзҺ°ж•…йҡңпјҢеҚідҪҝиҠӮзӮ№е…·еӨҮеҶҚй«ҳзҡ„еҶ—дҪҷжҖ§пјҢж•ҙдёӘеӯҳеӮЁзі»з»ҹд№ҹе°Ҷеҙ©жәғпјҢиҖҢGlusterFSеҲҶеёғејҸж–Ү件系з»ҹжҳҜеҹәдәҺж— е…ғжңҚеҠЎеҷЁзҡ„и®ҫи®ЎпјҢж•°жҚ®жЁӘеҗ‘жү©еұ•иғҪеҠӣејәпјҢе…·еӨҮиҫғй«ҳзҡ„еҸҜйқ жҖ§еҸҠеӯҳеӮЁж•ҲзҺҮгҖӮ GlusterFSж”ҜжҢҒTCP/IPе’ҢInfiniBand RDMAй«ҳйҖҹзҪ‘з»ңдә’иҒ”пјҢе®ўжҲ·з«ҜеҸҜйҖҡиҝҮеҺҹеЈ°GlusterFSеҚҸи®®и®ҝй—®ж•°жҚ®пјҢе…¶д»–жІЎжңүиҝҗиЎҢGlusterFSе®ўжҲ·з«Ҝзҡ„з»Ҳз«ҜеҸҜйҖҡиҝҮNFS/CIFSж ҮеҮҶеҚҸи®®йҖҡиҝҮеӯҳеӮЁзҪ‘е…іи®ҝй—®ж•°жҚ®гҖӮ
- жү©еұ•жҖ§е’Ңй«ҳжҖ§иғҪгҖӮGlusterFSеҲ©з”ЁеҸҢйҮҚзү№жҖ§жқҘжҸҗдҫӣй«ҳе®№йҮҸеӯҳеӮЁи§ЈеҶіж–№жЎҲгҖӮ
пјҲ1пјүScale-Outжһ¶жһ„йҖҡиҝҮеўһеҠ еӯҳеӮЁиҠӮзӮ№зҡ„ж–№ејҸжқҘжҸҗй«ҳеӯҳеӮЁе®№йҮҸе’ҢжҖ§иғҪпјҲзЈҒзӣҳгҖҒи®Ўз®—жңәе’ҢI/Oиө„жәҗйғҪеҸҜд»ҘзӢ¬з«ӢеўһеҠ пјүпјҢж”ҜжҢҒ10GBEе’ҢInfiniBandзӯүй«ҳйҖҹзҪ‘з»ңдә’иҒ”пјӣ
пјҲ2пјүGlusterеј№жҖ§е“ҲеёҢи§ЈеҶідәҶGlusterFSеҜ№е…ғж•°жҚ®жңҚеҠЎеҷЁзҡ„дҫқиө–пјҢGlusterFSйҮҮз”Ёеј№жҖ§з®—жі•еңЁеӯҳеӮЁжұ дёӯе®ҡдҪҚж•°жҚ®пјҢж”ҫејғдәҶдј з»ҹзҡ„йҖҡиҝҮе…ғж•°жҚ®жңҚеҠЎеҷЁе®ҡдҪҚж•°жҚ®пјҢGlusterFSдёӯеҸҜд»ҘжҷәиғҪзҡ„е®ҡдҪҚд»»ж„Ҹж•°жҚ®еҲҶзүҮпјҲе°Ҷж•°жҚ®еҲҶзүҮеӯҳеӮЁеңЁдёҚеҗҢиҠӮзӮ№дёҠпјүпјҢдёҚйңҖиҰҒжҹҘзңӢзҙўеј•жҲ–иҖ…жғіе…ғж•°жҚ®жңҚеҠЎеҷЁжҹҘиҜўгҖӮиҝҷз§Қи®ҫи®ЎжңәеҲ¶е®һзҺ°дәҶеӯҳеӮЁзҡ„жЁӘеҗ‘жү©еұ•пјҢж”№е–„дәҶеҚ•зӮ№ж•…йҡңеҸҠжҖ§иғҪ瓶йўҲпјҢзңҹжӯЈе®һзҺ°дәҶ并иЎҢеҢ–ж•°жҚ®и®ҝй—®гҖӮ- й«ҳеҸҜз”ЁжҖ§гҖӮGlusterFSйҖҡиҝҮй…ҚзҪ®жҹҗдәӣзұ»еһӢзҡ„еӯҳеӮЁеҚ·пјҢеҸҜд»ҘеҜ№ж–Ү件иҝӣиЎҢиҮӘеҠЁеӨҚеҲ¶пјҲзұ»дјјдәҺRAID1пјүпјҢеҚідҪҝжҹҗдёӘиҠӮзӮ№еҮәзҺ°ж•…йҡңпјҢд№ҹдёҚеҪұе“Қж•°жҚ®зҡ„и®ҝй—®гҖӮеҪ“ж•°жҚ®еҮәзҺ°дёҚдёҖиҮҙж—¶пјҢиҮӘеҠЁдҝ®еӨҚеҠҹиғҪиғҪеӨҹжҠҠж•°жҚ®жҒўеӨҚеҲ°жӯЈзЎ®зҡ„зҠ¶жҖҒпјҢж•°жҚ®зҡ„дҝ®еӨҚжҳҜд»ҘеўһйҮҸзҡ„ж–№ејҸеңЁеҗҺеҸ°жү§иЎҢпјҢдёҚдјҡеҚ з”ЁеӨӘеӨҡзі»з»ҹиө„жәҗгҖӮGlusterFSеҸҜд»Ҙж”ҜжҢҒжүҖжңүзҡ„еӯҳеӮЁпјҢд»ҘеҶ…е®ғжІЎжңүи®ҫи®ЎиҮӘе·ұзҡ„з§Ғжңүж•°жҚ®ж–Үд»¶ж јејҸпјҢиҖҢжҳҜйҮҮз”Ёж“ҚдҪңзі»з»ҹдёӯж ҮеҮҶзҡ„зЈҒзӣҳж–Ү件系з»ҹпјҲеҰӮEXT3гҖҒXFSзӯүпјүжқҘеӯҳеӮЁж–Ү件пјҢж•°жҚ®еҸҜд»ҘдҪҝз”Ёдј з»ҹзҡ„и®ҝй—®зЈҒзӣҳзҡ„ж–№ејҸиў«и®ҝй—®пјӣ
- е…ЁеұҖз»ҹдёҖе‘ҪеҗҚз©әй—ҙгҖӮе…ЁеұҖз»ҹдёҖе‘ҪеҗҚз©әй—ҙе°ҶжүҖжңүзҡ„еӯҳеӮЁиө„жәҗиҒҡйӣҶжҲҗдёҖдёӘеҚ•дёҖзҡ„иҷҡжӢҹеӯҳеӮЁжұ пјҢеҜ№з”ЁжҲ·е’Ңеә”з”ЁеұҸи”ҪдәҶзү©зҗҶеӯҳеӮЁдҝЎжҒҜгҖӮеӯҳеӮЁиө„жәҗпјҲзұ»дјјдәҺLVMпјүеҸҜд»Ҙж №жҚ®з”ҹдә§зҺҜеўғдёӯзҡ„йңҖиҰҒиҝӣиЎҢеј№жҖ§жү©еұ•жҲ–收缩гҖӮеңЁеӨҡиҠӮзӮ№еңәжҷҜдёӯпјҢе…ЁеұҖз»ҹдёҖе‘ҪеҗҚз©әй—ҙиҝҳеҸҜд»ҘеҹәдәҺдёҚеҗҢиҠӮзӮ№еҒҡиҙҹиҪҪеқҮиЎЎпјҢеӨ§еӨ§жҸҗй«ҳдәҶеӯҳеҸ–ж•ҲзҺҮпјӣ
- еј№жҖ§еҚ·з®ЎзҗҶгҖӮGlusterFSйҖҡиҝҮе°Ҷж•°жҚ®еӮЁеӯҳеңЁйҖ»иҫ‘еҚ·дёӯпјҢйҖ»иҫ‘еҚ·д»ҺйҖ»иҫ‘еӯҳеӮЁжұ иҝӣиЎҢзӢ¬з«ӢйҖ»иҫ‘еҲ’еҲҶгҖӮйҖ»иҫ‘еӯҳеӮЁжұ еҸҜд»ҘеңЁзәҝиҝӣиЎҢеўһеҠ е’Ң移йҷӨпјҢдёҚдјҡеҜјиҮҙдёҡеҠЎдёӯж–ӯгҖӮйҖ»иҫ‘еҚ·еҸҜд»Ҙж №жҚ®йңҖжұӮеңЁзәҝеўһй•ҝжҲ–еўһеҮҸпјҢ并еҸҜд»ҘеңЁеӨҡдёӘиҠӮзӮ№дёӯиҙҹиҪҪеқҮиЎЎгҖӮж–Ү件系з»ҹй…ҚзҪ®жӣҙж”№д№ҹеҸҜд»Ҙе®һж—¶еңЁзәҝиҝӣиЎҢ并еә”з”ЁпјҢд»ҺиҖҢеҸҜд»ҘйҖӮеә”е·ҘдҪңиҙҹиҪҪжқЎд»¶еҸҳеҢ–жҲ–еңЁзәҝжҖ§иғҪи°ғдјҳпјӣ
- еҹәдәҺж ҮеҮҶеҚҸи®®гҖӮGlusterеӯҳеӮЁжңҚеҠЎж”ҜжҢҒNFSгҖҒCIFSгҖҒHTTPгҖҒFTPгҖҒFTPгҖҒSMBеҸҠGlusterеҺҹз”ҹеҚҸи®®пјҢе®Ңе…ЁдёҺPOSIXж ҮеҮҶе…је®№гҖӮзҺ°жңүеә”з”ЁзЁӢеәҸдёҚйңҖиҰҒеҒҡд»»дҪ•дҝ®ж”№е°ұеҸҜд»ҘеҜ№Glusterдёӯзҡ„ж•°жҚ®иҝӣиЎҢи®ҝй—®пјҢд№ҹеҸҜд»ҘдҪҝз”Ёдё“з”ЁAPIиҝӣиЎҢи®ҝй—®пјҲж•ҲзҺҮжӣҙй«ҳпјүпјҢиҝҷеңЁе…¬жңүдә‘зҺҜеўғдёӯйғЁзҪІGlusterж—¶йқһеёёжңүз”ЁпјҢGlusterеҜ№дә‘жңҚеҠЎжҸҗдҫӣе•Ҷдё“з”ЁAPlиҝӣиЎҢжҠҪиұЎпјҢ然еҗҺжҸҗдҫӣж ҮеҮҶPOSIXеҖҹеҸЈпјӣ
- BrickпјҲеӯҳеӮЁеқ—пјүпјҡжҢҮеҸҜдҝЎдё»жңәжұ дёӯз”ұдё»жңәжҸҗдҫӣзҡ„з”ЁдәҺзү©зҗҶеӯҳеӮЁзҡ„дё“з”ЁеҲҶеҢәпјҢжҳҜGlusterFSдёӯзҡ„еҹәжң¬еӯҳеӮЁеҚ•е…ғпјҢеҗҢж—¶д№ҹжҳҜеҸҜдҝЎеӯҳеӮЁжұ дёӯжңҚеҠЎеҷЁдёҠеҜ№еӨ–жҸҗдҫӣзҡ„еӯҳеӮЁзӣ®еҪ•пјҢеӯҳеӮЁзӣ®еҪ•зҡ„ж јејҸз”ұжңҚеҠЎеҷЁе’Ңзӣ®еҪ•зҡ„з»қеҜ№и·Ҝеҫ„жһ„жҲҗпјҢиЎЁзӨәж–№жі•дёәSERVERпјҡEXPORT пјҢжҜ”еҰӮпјҡ192.168.1.4/date/mydir/пјӣ
- VolumeпјҲйҖ»иҫ‘еҚ·пјүпјҡдёҖдёӘйҖ»иҫ‘еҚ·жҳҜдёҖз»„Brickзҡ„йӣҶеҗҲгҖӮеҚ·жҳҜж•°жҚ®еӯҳеӮЁзҡ„йҖ»иҫ‘и®ҫеӨҮпјҢзұ»дјјдәҺLVMдёӯзҡ„йҖ»иҫ‘еҚ·гҖӮеӨ§йғЁеҲҶGlusterз®ЎзҗҶж“ҚдҪңжҳҜеңЁеҚ·дёҠиҝӣиЎҢзҡ„пјӣ
- FUSEпјҡжҳҜдёҖдёӘеҶ…ж ёжЁЎеқ—пјҢе…Ғи®ёз”ЁжҲ·еҲӣе»әиҮӘе·ұзҡ„ж–Ү件系з»ҹпјҢж— йЎ»дҝ®ж”№еҶ…ж ёд»Јз Ғпјӣ
- VFSпјҡеҶ…ж ёз©әй—ҙеҜ№з”ЁжҲ·з©әй—ҙжҸҗдҫӣеҗ§зҡ„и®ҝй—®зЈҒзӣҳзҡ„жҺҘеҸЈпјӣ
- GlusterdпјҲеҗҺеҸ°з®ЎзҗҶиҝӣзЁӢпјүпјҡеңЁеӯҳеӮЁзҫӨйӣҶдёӯзҡ„жҜҸдёӘиҠӮзӮ№дёҠйғҪиҰҒиҝҗиЎҢпјӣ
еҰӮеӣҫпјҡ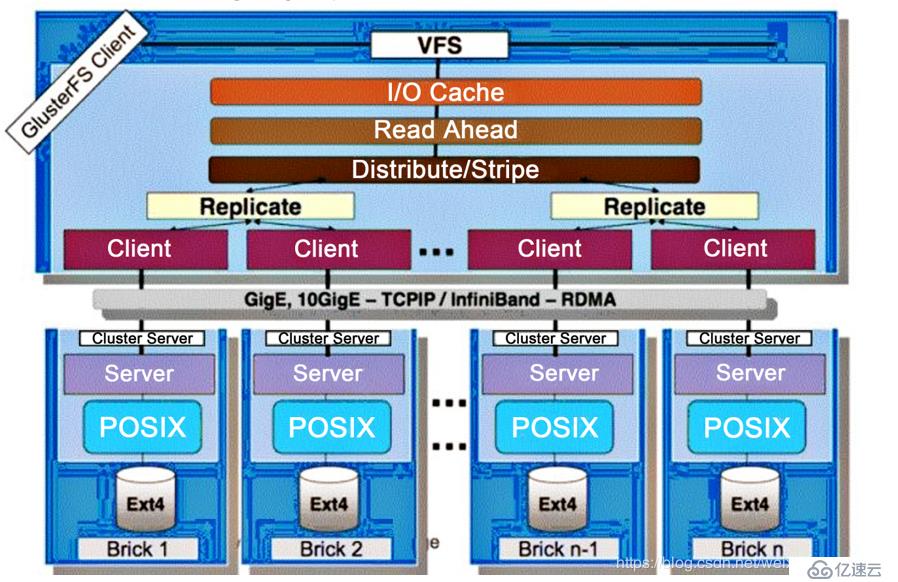
GlusterFSйҮҮз”ЁжЁЎеқ—еҢ–гҖҒе Ҷж ҲејҸзҡ„з»“жһ„пјҢеҸҜд»Ҙж №жҚ®йңҖжұӮй…ҚзҪ®е®ҡеҲ¶еҢ–зҡ„еә”з”ЁзҺҜеўғпјҢеҰӮеӨ§ж–Ү件еӯҳеӮЁгҖҒжө·йҮҸе°Ҹж–Ү件еӯҳеӮЁгҖҒдә‘еӯҳеӮЁгҖҒеӨҡдј иҫ“еҚҸи®®еә”з”ЁзӯүгҖӮйҖҡиҝҮеҜ№жЁЎеқ—иҝӣиЎҢеҗ„з§Қз»„еҗҲпјҢжҺҘеҸЈе®һзҺ°еӨҚжқӮзҡ„еҠҹиғҪгҖӮдҫӢеҰӮпјҡReplicateжЁЎеқ—еҸҜе®һзҺ°RAID1пјҢStripeжЁЎеқ—еҸҜе®һзҺ°RAID0пјҢйҖҡиҝҮдёӨиҖ…зҡ„з»„еҗҲеҸҜе®һзҺ°RAID10е’ҢRAID01пјҢеҗҢж—¶иҺ·еҫ—жӣҙй«ҳзҡ„жҖ§иғҪе’ҢеҸҜйқ жҖ§гҖӮ
GlusterFSжҳҜжЁЎеқ—еҢ–е Ҷж ҲејҸзҡ„жһ¶жһ„и®ҫи®ЎгҖӮжЁЎеқ—жҲҗдёәTranslatorпјҢжҳҜGlusterFSжҸҗдҫӣзҡ„дёҖз§ҚејәеӨ§зҡ„жңәеҲ¶пјҢеҖҹеҠ©иҝҷз§ҚиүҜеҘҪе®ҡд№үзҡ„жҺҘеҸЈеҸҜд»Ҙй«ҳж•Ҳз®Җдҫҝең°жү©еұ•ж–Ү件系з»ҹзҡ„еҠҹиғҪгҖӮ
пјҲ1пјүжңҚеҠЎеҷЁдёҺе®ўжҲ·з«Ҝзҡ„и®ҫи®Ўй«ҳеәҰжЁЎеқ—еҢ–зҡ„еҗҢдәӢжЁЎеқ—жҺҘеҸЈжҳҜе…је®№зҡ„пјҢеҗҢдёҖдёӘtranstatorеҸҜеҗҢдәӢеңЁе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁеҠ иҪҪпјӣ
пјҲ2пјүGlusterFSдёӯжүҖжңүзҡ„еҠҹиғҪйғҪжҳҜйҖҡиҝҮtranstatorе®һзҺ°зҡ„пјҢе…¶дёӯе®ўжҲ·з«ҜиҰҒжҜ”жңҚеҠЎеҷЁжӣҙеӨҚжқӮгҖӮжүҖд»ҘеҠҹиғҪзҡ„йҮҚзӮ№дё»иҰҒйӣҶдёӯеңЁе®ўжҲ·з«ҜдёҠпјӣ
GlusterFSж•°жҚ®и®ҝй—®жөҒзЁӢеҰӮеӣҫпјҡ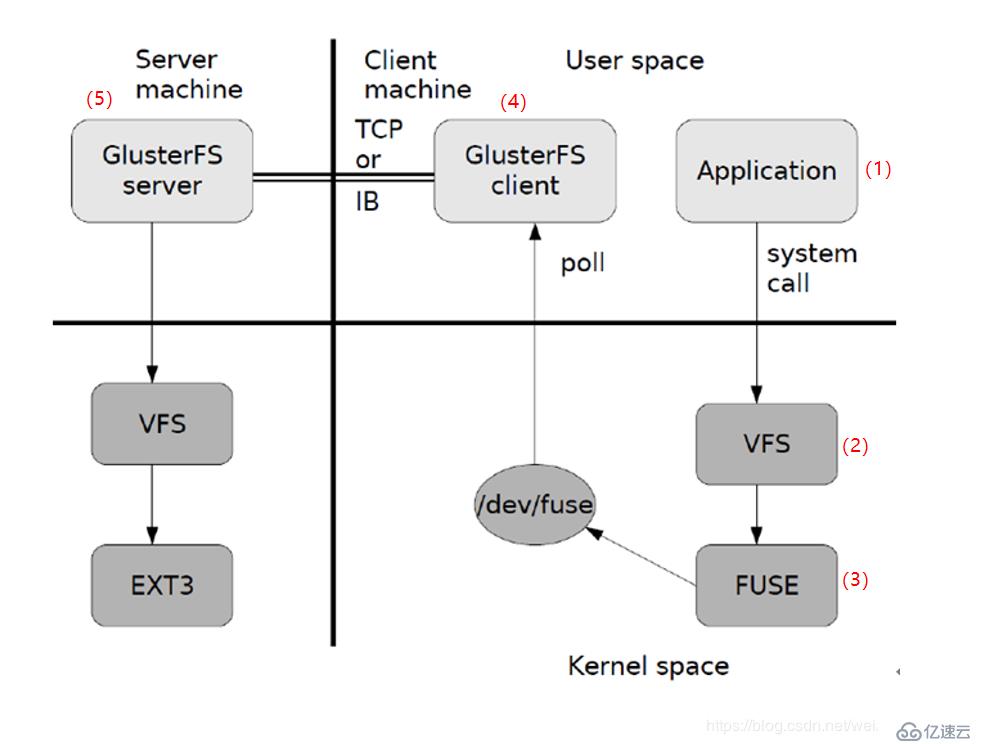
еӣҫдёӯжүҖзӨәеҸӘжҳҜGlusterFSж•°жҚ®и®ҝй—®зҡ„дёҖдёӘжҰӮиҰҒеӣҫпјҢеӨ§иҮҙиҝҮзЁӢпјҡ
пјҲ1пјүе®ўжҲ·з«ҜжҲ–еә”з”ЁзЁӢеәҸйҖҡиҝҮGlusterFSзҡ„жҢӮеңЁзӮ№и®ҝй—®ж•°жҚ®пјӣ
пјҲ2пјүLinuxзі»з»ҹеҶ…ж ёйҖҡиҝҮVFS API收еҲ°иҜ·жұӮ并еӨ„зҗҶпјӣ
пјҲ3пјүVFSе°Ҷж•°жҚ®йҖ’дәӨз»ҷFUSEеҶ…ж ёж–Ү件系з»ҹпјҢ并еҗ‘зі»з»ҹжіЁеҶҢдәҶдёҖдёӘе®һйҷ…зҡ„ж–Ү件系з»ҹFUSEпјҢиҖҢFUSEж–Ү件系з»ҹеҲҷжҳҜе°Ҷж•°жҚ®йҖҡиҝҮ/dev/fuseи®ҫеӨҮж–Ү件йҖ’дәӨз»ҷGlusterFS clientз«ҜгҖӮеҸҜд»Ҙе°ҶFUSEж–Ү件系з»ҹзҗҶи§ЈдёәдёҖдёӘд»ЈзҗҶпјӣ
пјҲ4пјүGlusterFS client收еҲ°ж•°жҚ®еҗҺгҖӮclientж №жҚ®й…ҚзҪ®ж–Ү件еҜ№ж•°жҚ®иҝӣиЎҢеӨ„зҗҶпјӣ
пјҲ5пјүз»ҸиҝҮGlusterFS clientеӨ„зҗҶеҗҺпјҢйҖҡиҝҮзҪ‘з»ңе°Ҷж•°жҚ®дј йҖ’иҮіиҝңз«Ҝзҡ„GlusterFS ServerпјҢ并且е°Ҷж•°жҚ®еҶҷе…ҘжңҚеҠЎеҷЁеӯҳеӮЁи®ҫеӨҮгҖӮ
еј№жҖ§HASHз®—жі•дҪҝз”ЁDavies-Meyerз®—жі•пјҢйҖҡиҝҮHASHз®—жі•еҫ—еҲ°дёҖдёӘ32дҪҚзҡ„ж•ҙж•°иҢғеӣҙпјҢеҒҮи®ҫйҖ»иҫ‘еҚ·дёӯжңүNдёӘеӯҳеӮЁеҚ•дҪҚBrickпјҢеҲҷ32дҪҚзҡ„ж•ҙж•°иҢғеӣҙиў«еҲ’еҲҶдёәNдёӘиҝһз»ӯзҡ„еӯҗз©әй—ҙпјҢжҜҸдёӘз©әй—ҙеҜ№еә”дёҖдёӘBrickгҖӮеҪ“з”ЁжҲ·жҲ–еә”з”ЁзЁӢеәҸи®ҝй—®жҹҗдёҖдёӘе‘ҪеҗҚз©әй—ҙж—¶пјҢйҖҡиҝҮеҜ№иҜҘе‘ҪеҗҚз©әй—ҙи®Ўз®—HASHеҖјпјҢж №жҚ®иҜҘHASHеҖјеҜ№еә”зҡ„32дҪҚж•ҙж•°з©әй—ҙе®ҡдҪҚж•°жҚ®жүҖеңЁзҡ„BrickгҖӮ
еј№жҖ§HASHз®—жі•зҡ„дјҳзӮ№иЎЁзҺ°еҰӮдёӢпјҡ
- дҝқиҜҒж•°жҚ®е№іеқҮеҲҶеёғеңЁжҜҸдёӘBrickдёӯпјӣ
- и§ЈеҶідәҶеҜ№е…ғж•°жҚ®жңҚеҠЎеҷЁзҡ„дҫқиө–пјҢиҝӣиҖҢи§ЈеҶідәҶеҚ•зӮ№ж•…йҡңеҸҠи®ҝ问瓶йўҲпјӣ
зҺ°еңЁжҲ‘们еҒҮи®ҫеҲӣе»әдёҖдёӘеҢ…еҗ«еӣӣдёӘBrickиҠӮзӮ№зҡ„GlusterFSеҚ·пјҢеңЁжңҚеҠЎз«Ҝзҡ„BrickжҢӮиҪҪзӣ®еҪ•дјҡз»ҷеӣӣдёӘBrickе№іеқҮеҲҶй…Қ2^32зҡ„еҢәй—ҙзҡ„иҢғеӣҙз©әй—ҙгҖӮGlusterFS hashеҲҶеёғеҢәй—ҙжҳҜдҝқеӯҳеңЁзӣ®еҪ•дёҠиҖҢдёҚжҳҜж №жҚ®жңәеҷЁеҺ»еҲҶеёғеҢәй—ҙгҖӮеҰӮеӣҫпјҡ
Brick*иЎЁзӨәдёҖдёӘзӣ®еҪ•пјҢеҲҶеёғеҢәй—ҙдҝқеӯҳеңЁжҜҸдёӘBrickжҢӮиҪҪзӮ№зӣ®еҪ•зҡ„жү©еұ•еұһжҖ§дёҠгҖӮ
еңЁеҚ·дёӯеҲӣе»әеӣӣдёӘж–Ү件гҖӮи®ҝй—®ж–Ү件时пјҢйҖҡиҝҮеҝ«йҖҹHashеҮҪж•°и®Ўз®—еҮәеҜ№еә”зҡ„HASHеҖјпјҢ然еҗҺж №жҚ®и®Ўз®—еҮәжқҘзҡ„HASHеҖјеҜ№еә”зҡ„еӯҗз©әй—ҙж•ЈеҲ—еҲ°жңҚеҠЎеҷЁзҡ„BrickдёҠпјҢеҰӮеӣҫпјҡ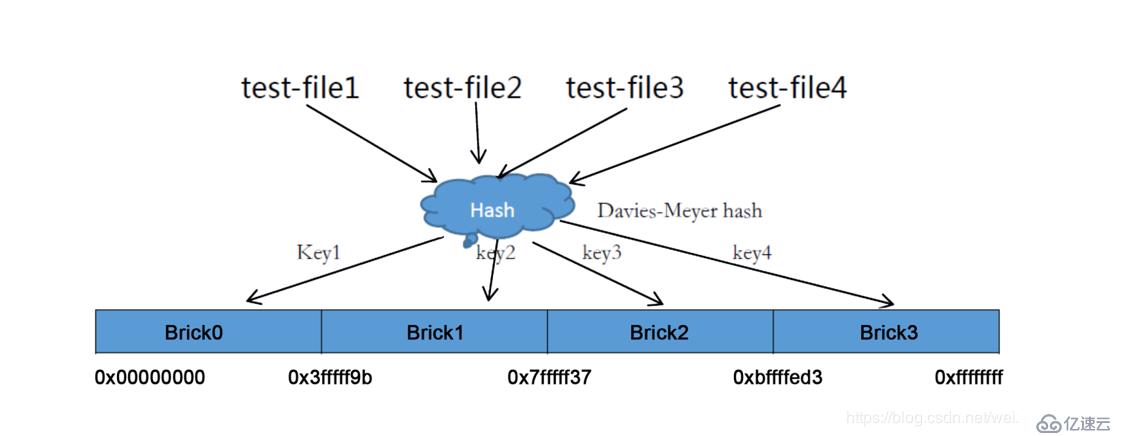
GlusterFSж”ҜжҢҒдёғз§ҚеҚ·пјҢиҝҷдёғз§ҚеҚ·еҸҜд»Ҙж»Ўи¶ідёҚеҗҢеә”з”ЁеҜ№й«ҳжҖ§иғҪгҖҒй«ҳеҸҜз”Ёзҡ„йңҖжұӮгҖӮиҝҷдёғз§ҚеҚ·еҲҶеҲ«жҳҜпјҡ
- пјҲ1пјүеҲҶеёғејҸеҚ·пјҲDistribute volumeпјүпјҡж–Ү件йҖҡиҝҮHASHз®—жі•еҲҶеёғеҲ°жүҖжңүBrick ServerдёҠпјҢиҝҷз§ҚеҚ·жҳҜGlusterfзҡ„еҹәзЎҖпјӣд»Ҙж–Ү件дёәеҚ•дҪҚж №жҚ®HASHз®—жі•ж•ЈеҲ—еҲ°дёҚеҗҢзҡ„BrickпјҢе…¶е®һеҸӘжҳҜжү©еӨ§дәҶзЈҒзӣҳз©әй—ҙпјҢеҰӮжһңжңүдёҖдёӘзЈҒзӣҳжҚҹеқҸпјҢж•°жҚ®д№ҹе°ҶдёўеӨұпјҢеұһдәҺж–Ү件зә§зҡ„RAID0пјҢдёҚе…·еӨҮе®№й”ҷиғҪеҠӣпјӣ
- пјҲ2пјүжқЎеёҰеҚ·пјҲStripe volumeпјүпјҡзұ»дјјдәҺRAID0пјҢж–Ү件被еҲҶдёәж•°жҚ®еқ—并д»ҘиҪ®иҜўзҡ„ж–№ејҸеҲҶеёғеҲ°еӨҡдёӘBrick ServerдёҠпјҢж–Ү件еӯҳеӮЁд»Ҙж•°жҚ®еқ—дёәеҚ•дҪҚпјҢж”ҜжҢҒеӨ§ж–Ү件еӯҳеӮЁпјҢж–Ү件и¶ҠеӨ§пјҢиҜ»еҸ–ж•ҲзҺҮи¶Ҡй«ҳпјӣ
- пјҲ3пјүеӨҚеҲ¶еҚ·пјҲReplica volumeпјүпјҡе°Ҷж–Ү件еҗҢжӯҘеҲ°еӨҡдёӘBrickдёҠпјҢдҪҝе…¶е…·еӨҮеӨҡдёӘж–Ү件еүҜжң¬пјҢеұһдәҺж–Ү件зә§RAID1пјҢе…·жңүе®№й”ҷиғҪеҠӣгҖӮеӣ дёәж•°жҚ®еҲҶж•ЈеҲ°еӨҡдёӘBrickдёӯпјҢжүҖд»ҘиҜ»жҖ§иғҪеҫ—еҲ°дәҶеҫҲеӨ§жҸҗеҚҮпјҢдҪҶеҶҷжҖ§иғҪдёӢйҷҚпјӣ
- пјҲ4пјүеҲҶеёғејҸжқЎеёҰеҚ·пјҲDistribute Stripe volumeпјүпјҡBrick Serverж•°йҮҸжҳҜжқЎеёҰж•°пјҲж•°жҚ®еқ—еҲҶеёғзҡ„Brickж•°йҮҸпјүзҡ„еҖҚж•°пјҢе…јеӨҮеҲҶеёғејҸеҚ·е’ҢжқЎеёҰеҚ·зҡ„зү№зӮ№пјӣ
- пјҲ5пјүеҲҶеёғејҸеӨҚеҲ¶еҚ·пјҲDistribute Replica volumeпјүпјҡBrick Serverж•°йҮҸжҳҜй•ңеғҸж•°пјҲж•°жҚ®еүҜжң¬ж•°йҮҸпјүзҡ„еҖҚж•°пјҢе…·жңүеҲҶеёғејҸеҚ·е’ҢеӨҚеҲ¶еҚ·зҡ„зү№зӮ№пјӣ
- пјҲ6пјүжқЎеёҰеӨҚеҲ¶еҚ·пјҲStripe Replica volumeпјүпјҡзұ»дјјдәҺRAID10пјҢеҗҢж—¶е…·жңүжқЎеёҰеҚ·е’ҢеӨҚеҲ¶еҚ·зҡ„зү№зӮ№пјӣ
- пјҲ7пјүеҲҶеёғејҸжқЎеёҰеӨҚеҲ¶еҚ·пјҲDistribute Stripe Replica volumeпјүпјҡдёүз§Қеҹәжң¬еҚ·зҡ„еӨҚеҗҲеҚ·пјҢйҖҡеёёз”ЁдәҺзұ»Map Reduceеә”з”Ёпјӣ
дёӢйқўиҜҰз»Ҷд»Ӣз»ҚеҮ з§ҚйҮҚиҰҒзҡ„еҚ·зұ»еһӢпјҡ
еҲҶеёғејҸеҚ·жҳҜGlusterFSзҡ„й»ҳи®ӨеҚ·пјҢеңЁеҲӣе»әеҚ·ж—¶пјҢй»ҳи®ӨйҖүйЎ№е°ұжҳҜеҲӣе»әеҲҶеёғејҸеҚ·гҖӮеңЁиҜҘжЁЎејҸдёӢпјҢ并没жңүеҜ№ж–Ү件иҝӣиЎҢеҲҶеқ—еӨ„зҗҶпјҢж–Ү件зӣҙжҺҘеӯҳеӮЁеңЁжҹҗдёӘServerиҠӮзӮ№дёҠпјҢзӣҙжҺҘдҪҝз”Ёжң¬ең°ж–Ү件系з»ҹиҝӣиЎҢж–Ү件еӯҳеӮЁпјҢеӨ§йғЁеҲҶLinuxе‘Ҫд»Өе’Ңе·Ҙе…·еҸҜд»Ҙ继з»ӯжӯЈеёёдҪҝз”ЁгҖӮйңҖиҰҒйҖҡиҝҮжү©еұ•ж–Ү件еұһжҖ§дҝқеӯҳHASHеҖјпјҢзӣ®еүҚж”ҜжҢҒзҡ„еә•еұӮж–Ү件系з»ҹжңүext3гҖҒext4гҖҒZFSгҖҒXFSзӯүгҖӮ
з”ұдәҺдҪҝз”Ёжң¬ең°ж–Ү件系з»ҹпјҢжүҖд»ҘеӯҳеҸ–ж•ҲзҺҮ并没жңүжҸҗй«ҳпјҢеҸҚиҖҢдјҡеӣ дёәзҪ‘з»ңйҖҡдҝЎзҡ„еҺҹеӣ иҖҢжңүжүҖйҷҚдҪҺпјӣеҸҰеӨ–ж”ҜжҢҒи¶…еӨ§еһӢж–Ү件д№ҹдјҡжңүдёҖе®ҡзҡ„йҡҫеәҰпјҢеӣ дёәеҲҶеёғејҸеҚ·дёҚдјҡеҜ№ж–Ү件иҝӣиЎҢеҲҶеқ—еӨ„зҗҶгҖӮиҷҪ然ext4е·Із»ҸеҸҜд»Ҙж”ҜжҢҒжңҖеӨ§16TBзҡ„еҚ•дёӘж–Ү件пјҢдҪҶжҳҜжң¬ең°еӯҳеӮЁи®ҫеӨҮзҡ„е®№йҮҸе®һеңЁжңүйҷҗгҖӮ
еҰӮеӣҫпјҡ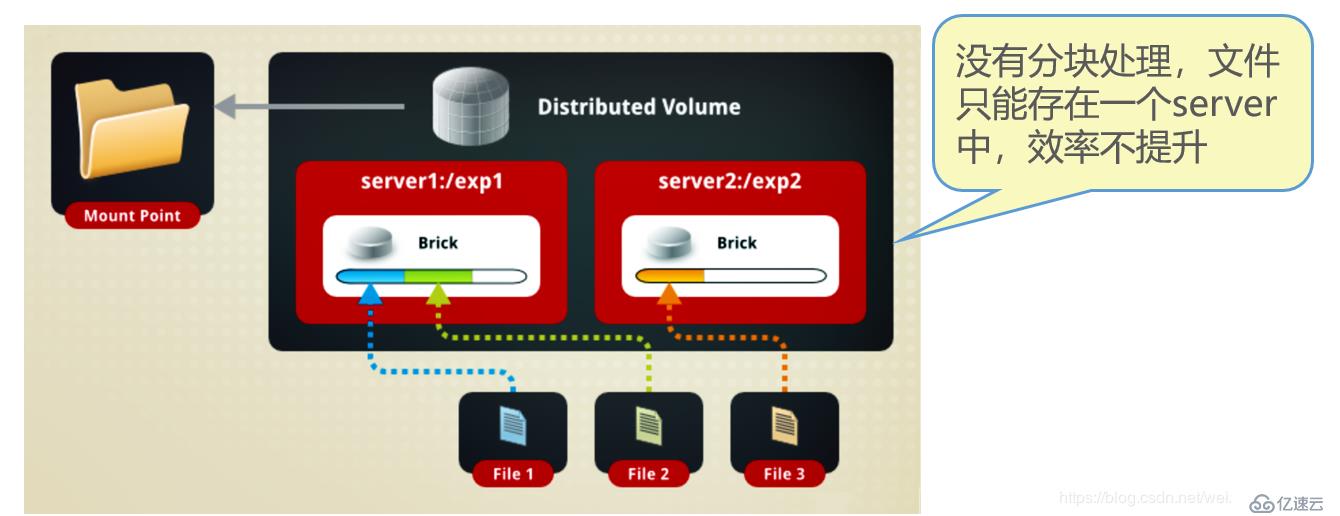
еҰӮеӣҫжүҖзӨәпјҡFile1е’ҢFile2еӯҳж”ҫеңЁServer1пјҢиҖҢFile3еӯҳж”ҫеңЁServer2пјҢж–Ү件йғҪжҳҜйҡҸжңәеӯҳеӮЁпјҢдёҖдёӘж–Ү件иҰҒд№ҲеңЁServer1дёҠпјҢиҰҒд№ҲеңЁServer2дёҠпјҢдёҚиғҪеҲҶеқ—еҗҢж—¶еӯҳж”ҫеңЁServer1е’ҢServer2дёҠгҖӮ
еҲҶеёғејҸеҚ·е…·жңүеҰӮдёӢзү№зӮ№пјҡ
- ж–Ү件еҲҶеёғеңЁдёҚеҗҢзҡ„жңҚеҠЎеҷЁпјҢеёғеұҖеҲ«еҶ—дҪҷжҖ§пјӣ
- жӣҙе®№жҳ“е»үд»·ең°жү©еұ•еҚ·зҡ„еӨ§е°Ҹпјӣ
- еҚ•зӮ№ж•…йҡңдјҡйҖ жҲҗж•°жҚ®дёўеӨұпјӣ
- дҫқиө–дәҺеә•еұӮзҡ„ж•°жҚ®дҝқжҠӨпјӣ
еҲӣе»әеҲҶеёғејҸеҚ·зҡ„е‘Ҫд»Өпјҡ
[root@localhost ~]# gluster volume create dis-volume server1:/dir1 server2:/dir2
//еҲӣе»әдёҖдёӘеҗҚдёәdis-volumeзҡ„еҲҶеёғеҚ·пјҢж–Ү件е°Ҷж №жҚ®HASHеҲҶеёғеңЁserver1пјҡ/dir1гҖҒserver2:/dir2дёӯ
Creation of dis-volume has been successful
Please start the volume to access dataStripeжЁЎејҸзӣёеҪ“дәҺRAID0пјҢеңЁиҜҘжЁЎејҸдёӢпјҢж №жҚ®еҒҸ移йҮҸе°Ҷж–Ү件еҲҶжҲҗNеқ—пјҲNдёӘжқЎеёҰиҠӮзӮ№пјүпјҢиҪ®иҜўең°еӯҳеӮЁеңЁжҜҸдёӘBrick ServerиҠӮзӮ№гҖӮиҠӮзӮ№жҠҠжҜҸдёӘж•°жҚ®еқ—йғҪдҪңдёәжҷ®йҖҡж–Ү件еӯҳе…Ҙжң¬ең°ж–Ү件系з»ҹдёӯпјҢйҖҡиҝҮжү©еұ•еұһжҖ§и®°еҪ•жҖ»еқ—ж•°е’ҢжҜҸеқ—зҡ„еәҸеҸ·гҖӮеңЁй…ҚзҪ®ж—¶жҢҮе®ҡзҡ„жқЎеёҰж•°еҝ…йЎ»зӯүдәҺеҚ·дёӯBrickжүҖеҢ…еҗ«зҡ„еӯҳеӮЁжңҚеҠЎеҷЁж•°пјҢеңЁеӯҳеӮЁеӨ§ж–Ү件时пјҢжҖ§иғҪе°ӨдёәзӘҒеҮәпјҢдҪҶжҳҜдёҚе…·еӨҮеҶ—дҪҷжҖ§гҖӮ
еҰӮеӣҫпјҡ
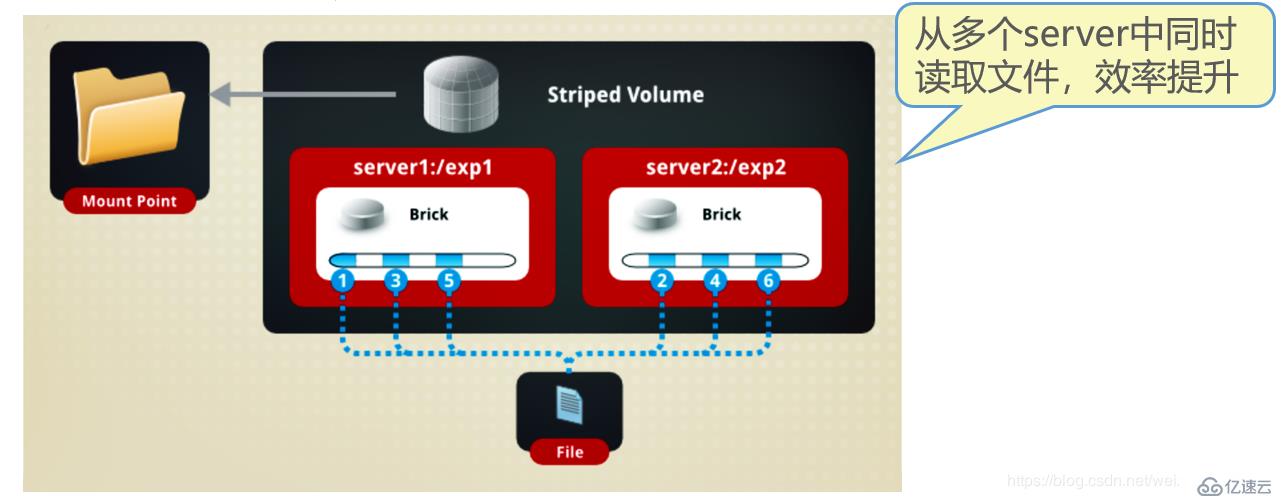
Fileиў«еҲҶеүІдёә6ж®өпјҢ1гҖҒ3гҖҒ5ж”ҫеңЁServer1, 2гҖҒ4гҖҒ6ж”ҫеңЁServer2дёӯпјҒ
жқЎеёҰеҚ·е…·жңүеҰӮдёӢзү№зӮ№пјҡ
- ж•°жҚ®иў«еҲҶеүІжҲҗжӣҙе°Ҹеқ—еҲҶеёғеҲ°еқ—жңҚеҠЎеҷЁзҫӨдёӯзҡ„дёҚеҗҢжқЎеёҰеҢәпјӣ
- еҲҶеёғеҮҸе°‘дәҶиҙҹиҪҪдё”жӣҙе°Ҹзҡ„ж–Ү件еҠ йҖҹдәҶеӯҳеҸ–зҡ„йҖҹеәҰпјӣ
- жІЎжңүж•°жҚ®еҶ—дҪҷпјӣ
еҲӣе»әжқЎеёҰеҚ·зҡ„е‘Ҫд»Өпјҡ
[root@localhost ~]# gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
//еҲӣе»әдёҖдёӘеҗҚдёәStripe-volumeзҡ„жқЎеёҰеҚ·пјҢж–Ү件е°ҶеҲҶеқ—иҪ®иҜўең°еӯҳеӮЁеңЁserver1:/dir1 гҖҒserver2:/dir2дёӨдёӘBrickдёӯ
Creation of rep-volume has been successful
Please start the volume to access dataеӨҚеҲ¶жЁЎејҸпјҢд№ҹз§°дёәAFRпјҢзӣёеҪ“дәҺRAID1гҖӮеҚіеҗҢдёҖж–Ү件дҝқеӯҳдёҖд»ҪжҲ–еӨҡд»ҪеүҜжң¬пјҢжҜҸдёӘиҠӮзӮ№дҝқеӯҳзӣёеҗҢзҡ„еҶ…е®№е’Ңзӣ®еҪ•з»“жһ„гҖӮеӨҚеҲ¶жЁЎејҸеӣ дёәиҰҒдҝқеӯҳеүҜжң¬пјҢжүҖд»ҘзЈҒзӣҳеҲ©з”ЁзҺҮиҫғдҪҺгҖӮеҰӮжһңеӨҡдёӘиҠӮзӮ№дёҠзҡ„еӯҳеӮЁз©әй—ҙдёҚдёҖиҮҙпјҢйӮЈд№Ҳе°ҶжҢүз…§жңЁжЎ¶ж•Ҳеә”еҸ–жңҖдҪҺиҠӮзӮ№зҡ„е®№йҮҸдҪңдёәиҜҘеҚ·зҡ„жҖ»е®№йҮҸгҖӮеңЁй…ҚзҪ®еӨҚеҲ¶еҚ·ж—¶пјҢеӨҚеҲ¶ж•°еҝ…йЎ»зӯүдәҺеҚ·дёӯBrickжүҖеҢ…еҗ«зҡ„еӯҳеӮЁжңҚеҠЎеҷЁж•°пјҢеӨҚеҲ¶еҚ·е…·еӨҮеҶ—дҪҷжҖ§пјҢеҚідҪҝдёҖдёӘиҠӮзӮ№жҚҹеқҸпјҢд№ҹдёҚеҪұе“Қж•°жҚ®зҡ„жӯЈеёёдҪҝз”ЁгҖӮ
еҰӮеӣҫпјҡ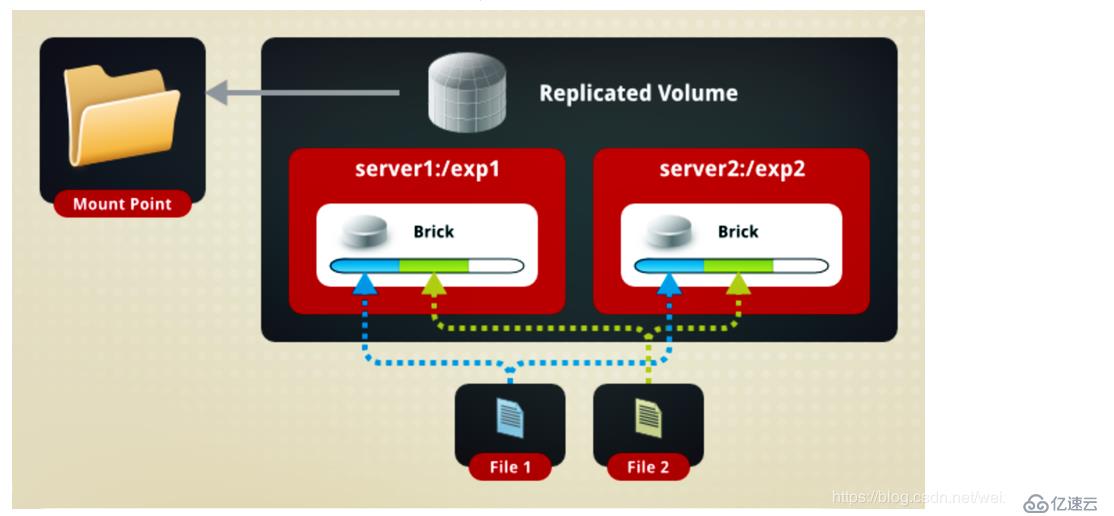
File1е’ҢFile2еҗҢж—¶еӯҳж”ҫеңЁServer1е’ҢServer2дёҠпјҢзӣёеҪ“дәҺServer2дёӯзҡ„ж–Ү件жҳҜServer1дёӯж–Ү件зҡ„еүҜжң¬пјҒ
еӨҚеҲ¶еҚ·е…·жңүд»ҘдёӢзү№зӮ№пјҡ
- еҚ·дёӯжүҖжңүзҡ„жңҚеҠЎеҷЁеқҮдҝқеӯҳдёҖдёӘе®Ңж•ҙзҡ„еүҜжң¬пјӣ
- еҚ·зҡ„еүҜжң¬ж•°йҮҸеҸҜз”ұе®ўжҲ·еҲӣе»әзҡ„ж—¶еҖҷеҶіе®ҡпјӣ
- иҮіе°‘жңүдёӨдёӘеқ—жңҚеҠЎеҷЁжҲ–иҖ…жӣҙеӨҡзҡ„жңҚеҠЎеҷЁпјӣ
- е…·жңүеҶ—дҪҷжҖ§пјӣ
еҲӣе»әеӨҚеҲ¶еҚ·зҡ„е‘Ҫд»Өпјҡ
[root@localhost ~]# gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
//еҲӣе»әеҗҚдёәrep-volumeзҡ„еӨҚеҲ¶еҚ·пјҢж–Ү件е°ҶеҗҢж—¶еӯҳеӮЁдёӨдёӘеүҜжң¬пјҢеҲҶеҲ«еңЁServer1:/dir1е’ҢServer2:/dir2дёӨдёӘBrickдёӯ
Creation of rep-volume has been successful
Please start the volume to access dataеҲҶеёғејҸжқЎеёҰеҚ·е…јйЎҫеҲҶеёғејҸе’ҢжқЎеёҰеҚ·зҡ„еҠҹиғҪпјҢдё»иҰҒз”ЁдәҺеӨ§ж–Ү件и®ҝй—®еӨ„зҗҶпјҢеҲӣе»әдёҖдёӘеҲҶеёғејҸжқЎеёҰеҚ·жңҖе°‘йңҖиҰҒ4еҸ°жңҚеҠЎеҷЁгҖӮ
еҰӮеӣҫпјҡ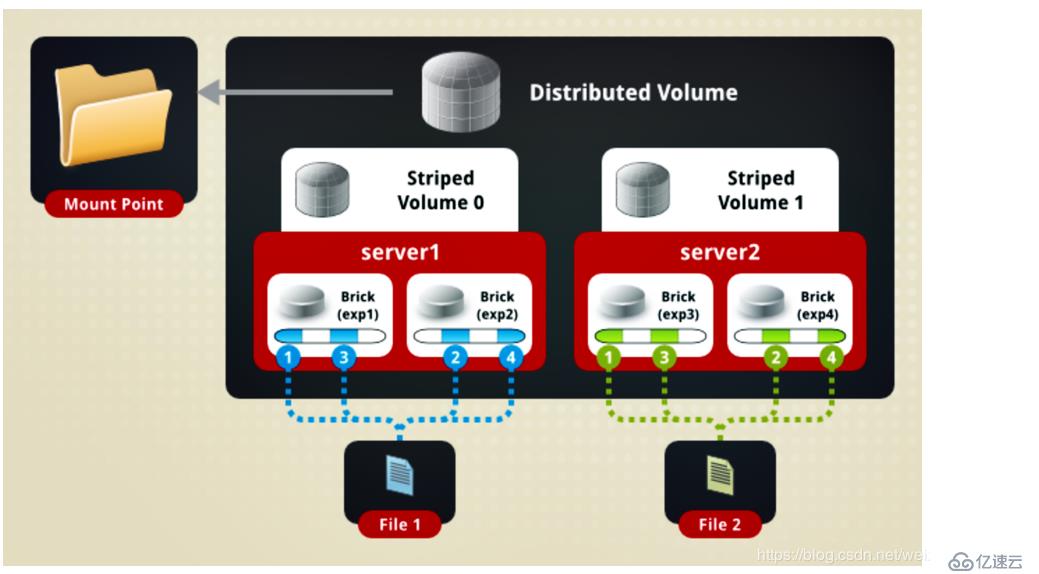
еҰӮеӣҫжүҖзӨәпјҡFile1е’ҢFile2йҖҡиҝҮеҲҶеёғејҸеҚ·зҡ„еҠҹиғҪеҲҶеҲ«е®ҡдҪҚеҲ°Server1е’ҢServer2гҖӮеңЁServer1дёӯпјҢFile1иў«еҲҶеүІжҲҗ4ж®өпјҢе…¶дёӯ1гҖҒ3еңЁServer1дёӯexp1зӣ®еҪ•дёӯпјӣ2гҖҒ4еңЁServer1дёӯзҡ„exp2зӣ®еҪ•дёӯгҖӮеңЁServer2дёӯпјҢFile2д№ҹиў«еҲҶеүІжҲҗ4ж®өпјҢдёҺFile1дёҖж ·пјҒ
еҲӣе»әеҲҶеёғејҸжқЎеёҰеҚ·зҡ„е‘Ҫд»Өпјҡ
[root@localhost ~]# gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
//еҲӣе»әдәҶдёҖдёӘеҗҚдёәdis-stripeзҡ„еҲҶеёғејҸжқЎеёҰеҚ·пјҢй…ҚзҪ®еҲҶеёғејҸзҡ„жқЎеёҰеҚ·ж—¶пјҢеҚ·дёӯBrickжүҖеҢ…еҗ«зҡ„еӯҳеӮЁжңҚеҠЎеҷЁж•°еҝ…йЎ»жҳҜжқЎеёҰж•°зҡ„еҖҚж•°(>=2еҖҚ)
Creation of rep-volume has been successful
Please start the volume to access dataжіЁж„ҸпјҡеҲӣе»әеҚ·ж—¶пјҢеӯҳеӮЁжңҚеҠЎеҷЁзҡ„ж•°йҮҸеҰӮжһңзӯүдәҺжқЎеёҰжҲ–еӨҚеҲ¶ж•°пјҢйӮЈд№ҲеҲӣе»әзҡ„жҳҜжқЎеёҰеҚ·жҲ–еӨҚеҲ¶еҚ·пјӣеҰӮжһңеӯҳеӮЁжңҚеҠЎеҷЁзҡ„ж•°йҮҸжҳҜжқЎеёҰеҚ·жҲ–еӨҚеҲ¶еҚ·зҡ„2еҖҚз”ҡиҮіжӣҙеӨҡпјҢйӮЈд№Ҳе°ҶеҲӣе»әеҲҶеёғејҸжқЎеёҰеҚ·жҲ–еҲҶеёғејҸеӨҚеҲ¶еҚ·гҖӮ
еҲҶеёғејҸеӨҚеҲ¶еҚ·е…јйЎҫеҲҶеёғејҸеҚ·е’ҢеӨҚеҲ¶еҚ·зҡ„еҠҹиғҪпјҢдё»иҰҒз”ЁдәҺйңҖиҰҒеҶ—дҪҷзҡ„жғ…еҶөдёӢпјҢеҰӮеӣҫпјҡ
еҰӮеӣҫжүҖзӨәпјҡFile1е’ҢFile2йҖҡиҝҮеҲҶеёғејҸjauntyзҡ„еҠҹиғҪеҲҶеҲ«е®ҡдҪҚеҲ°Server1е’ҢServer2гҖӮеңЁеӯҳж”ҫFile1ж—¶пјҢFile1ж №жҚ®еӨҚеҲ¶еҚ·зҡ„зү№жҖ§пјҢе°ҶеӯҳеңЁдёӨдёӘзӣёеҗҢзҡ„еүҜжң¬пјҢеҲҶеҲ«жҳҜServer1дёӯзҡ„exp1зӣ®еҪ•е’ҢServer2дёӯзҡ„exp2зӣ®еҪ•пјҢеңЁеӯҳж”ҫFile2ж—¶пјҢFile2ж №жҚ®еӨҚеҲ¶еҚ·зҡ„зү№жҖ§пјҢд№ҹе°ҶеӯҳеңЁдёӨдёӘзӣёеҗҢзҡ„еүҜжң¬пјҢеҲҶеҲ«жҳҜServer3дёӯзҡ„exp3зӣ®еҪ•е’ҢServer4дёӯзҡ„exp4зӣ®еҪ•гҖӮ
еҲӣе»әеҲҶеёғејҸеӨҚеҲ¶еҚ·зҡ„е‘Ҫд»Өпјҡ
[root@localhost ~]# gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
//еҲӣе»әдәҶдёҖдёӘеҗҚдёәdis-repзҡ„еҲҶеёғејҸжқЎеёҰеҚ·пјҢй…ҚзҪ®еҲҶеёғејҸзҡ„еӨҚеҲ¶еҚ·ж—¶пјҢеҚ·дёӯBrickжүҖеҢ…еҗ«зҡ„еӯҳеӮЁжңҚеҠЎеҷЁж•°еҝ…йЎ»жҳҜжқЎеёҰж•°зҡ„еҖҚж•°(>=2еҖҚ)
Creation of rep-volume has been successful
Please start the volume to access dataеҒҮеҰӮеӯҳеңЁ8еҸ°жңҚеҠЎеҷЁпјҢеҪ“еӨҚеҲ¶еүҜжң¬дёә2ж—¶пјҢжҢүз…§жңҚеҠЎеҷЁеҲ—иЎЁзҡ„йЎәеәҸпјҢжңҚеҠЎеҷЁ1е’Ң2дҪңдёәдёҖдёӘеӨҚеҲ¶пјҢжңҚеҠЎеҷЁ3е’Ң4дҪңдёәдёҖдёӘеӨҚеҲ¶пјҢжңҚеҠЎеҷЁ5е’Ң6дҪңдёәдёҖдёӘеӨҚеҲ¶пјҢжңҚеҠЎеҷЁ7е’Ң8дҪңдёәдёҖдёӘеӨҚеҲ¶пјӣеҪ“еӨҚеҲ¶еүҜжң¬дёә4ж—¶пјҢжҢүз…§жңҚеҠЎеҷЁеҲ—иЎЁзҡ„йЎәеәҸпјҢжңҚеҠЎеҷЁ1/2/3./4дҪңдёәдёҖдёӘеӨҚеҲ¶пјҢжңҚеҠЎеҷЁ5/6/7/8дҪңдёәдёҖдёӘеӨҚеҲ¶гҖӮ
е…ідәҺиҝҷдәӣзҗҶи®әжҰӮеҝө并дёҚжҳҜеҫҲйҡҫпјҢеҹәжң¬зңӢдёҖйҒҚе°ұиғҪжҳҺзҷҪе…¶дёӯзҡ„ж„ҸжҖқпјҢйӮЈиҝҷйҮҢд№ҹе°ұдёҚеӨҡиҜҙдәҶпјҒ
иҝҷзҜҮеҚҡж–Үдё»иҰҒд»Ӣз»ҚзҗҶи®әпјҢе…ідәҺе®һжҲҳеҸҜд»ҘеҸӮиҖғеҚҡж–ҮпјҡйғЁзҪІGlusterFSеҲҶеёғејҸж–Ү件系з»ҹпјҢе®һжҲҳпјҒпјҒпјҒ
вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ” жң¬ж–ҮиҮіжӯӨз»“жқҹпјҢж„ҹи°ўйҳ…иҜ» вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ