жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үдё»иҰҒжҳҜз”ЁPyTorchжқҘе®һзҺ°дёҖдёӘз®ҖеҚ•зҡ„еӣһеҪ’д»»еҠЎгҖӮ
зј–иҫ‘еҷЁпјҡspyder
1.еј•е…Ҙзӣёеә”зҡ„еҢ…еҸҠз”ҹжҲҗдјӘж•°жҚ®
import torch import torch.nn.functional as F # дё»иҰҒе®һзҺ°жҝҖжҙ»еҮҪж•° import matplotlib.pyplot as plt # з»ҳеӣҫзҡ„е·Ҙе…· from torch.autograd import Variable # з”ҹжҲҗдјӘж•°жҚ® x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim = 1) y = x.pow(2) + 0.2 * torch.rand(x.size()) # еҸҳдёәVariable x, y = Variable(x), Variable(y)
е…¶дёӯtorch.linspaceжҳҜдёәдәҶз”ҹжҲҗиҝһз»ӯй—ҙж–ӯзҡ„ж•°жҚ®пјҢ第дёҖдёӘеҸӮж•°иЎЁзӨәиө·зӮ№пјҢ第дәҢдёӘеҸӮж•°иЎЁзӨәз»ҲзӮ№пјҢ第дёүдёӘеҸӮж•°иЎЁзӨәе°ҶиҝҷдёӘеҢәй—ҙеҲҶжҲҗе№іеқҮеҮ д»ҪпјҢеҚіз”ҹжҲҗеҮ дёӘж•°жҚ®гҖӮеӣ дёәtorchеҸӘиғҪеӨ„зҗҶдәҢз»ҙзҡ„ж•°жҚ®пјҢжүҖд»ҘжҲ‘们用torch.unsqueezeз»ҷдјӘж•°жҚ®ж·»еҠ дёҖдёӘз»ҙеәҰпјҢdimиЎЁзӨәж·»еҠ еңЁз¬¬еҮ з»ҙгҖӮtorch.randиҝ”еӣһзҡ„жҳҜ[0,1)д№Ӣй—ҙзҡ„еқҮеҢҖеҲҶеёғгҖӮ
2.з»ҳеҲ¶ж•°жҚ®еӣҫеғҸ
еңЁдёҠиҝ°д»Јз ҒеҗҺйқўеҠ дёӢйқўзҡ„д»Јз ҒпјҢ然еҗҺиҝҗиЎҢеҸҜеҫ—дјӘж•°жҚ®зҡ„еӣҫеҪўеҢ–иЎЁзӨәпјҡ
# з»ҳеҲ¶ж•°жҚ®еӣҫеғҸ plt.scatter(x.data.numpy(), y.data.numpy()) plt.show()

3.е»әз«ӢзҘһз»ҸзҪ‘з»ң
class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer self.predict = torch.nn.Linear(n_hidden, n_output) # output layer def forward(self, x): x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.predict(x) # linear output return x net = Net(n_feature=1, n_hidden=10, n_output=1) # define the network print(net) # net architecture
дёҖиҲ¬зҘһз»ҸзҪ‘з»ңзҡ„зұ»йғҪ继жүҝиҮӘtorch.nn.ModuleпјҢ__init__()е’Ңforward()дёӨдёӘеҮҪж•°жҳҜиҮӘе®ҡд№үзұ»зҡ„дё»иҰҒеҮҪж•°гҖӮеңЁ__init__()дёӯйғҪиҰҒж·»еҠ дёҖеҸҘsuper(Net, self).__init__()пјҢиҝҷжҳҜеӣәе®ҡзҡ„ж ҮеҮҶеҶҷжі•пјҢз”ЁдәҺ继жүҝзҲ¶зұ»зҡ„еҲқе§ӢеҢ–еҮҪж•°гҖӮ__init__()дёӯеҸӘжҳҜеҜ№зҘһз»ҸзҪ‘з»ңзҡ„жЁЎеқ—иҝӣиЎҢдәҶеЈ°жҳҺпјҢзңҹжӯЈзҡ„жҗӯе»әжҳҜеңЁforwad()дёӯе®һзҺ°гҖӮиҮӘе®ҡд№үзұ»дёӯзҡ„жҲҗе‘ҳйғҪйҖҡиҝҮselfжҢҮй’ҲжқҘиҝӣиЎҢи®ҝй—®пјҢжүҖд»ҘеҸӮж•°еҲ—иЎЁдёӯйғҪеҢ…еҗ«дәҶselfгҖӮ
еҰӮжһңжғіжҹҘзңӢзҪ‘з»ңз»“жһ„пјҢеҸҜд»Ҙз”Ёprint()еҮҪж•°зӣҙжҺҘжү“еҚ°зҪ‘з»ңгҖӮжң¬ж–Үзҡ„зҪ‘з»ңз»“жһ„иҫ“еҮәеҰӮдёӢпјҡ
Net ( (hidden): Linear (1 -> 10) (predict): Linear (10 -> 1) )
4.и®ӯз»ғзҪ‘з»ң
# и®ӯз»ғ100ж¬Ў for t in range(100): prediction = net(x) # input x and predict based on x loss = loss_func(prediction, y) # дёҖе®ҡиҰҒжҳҜиҫ“еҮәеңЁеүҚпјҢж ҮзӯҫеңЁеҗҺ (1. nn output, 2. target) optimizer.zero_grad() # clear gradients for next train loss.backward() # backpropagation, compute gradients optimizer.step() # apply gradients
и®ӯз»ғзҪ‘з»ңд№ӢеүҚжҲ‘们йңҖиҰҒе…Ҳе®ҡд№үдјҳеҢ–еҷЁе’ҢжҚҹеӨұеҮҪж•°гҖӮtorch.optimеҢ…дёӯеҢ…жӢ¬дәҶеҗ„з§ҚдјҳеҢ–еҷЁпјҢиҝҷйҮҢжҲ‘们йҖүз”ЁжңҖеёёи§Ғзҡ„SGDдҪңдёәдјҳеҢ–еҷЁгҖӮеӣ дёәжҲ‘们иҰҒеҜ№зҪ‘з»ңзҡ„еҸӮж•°иҝӣиЎҢдјҳеҢ–пјҢжүҖд»ҘжҲ‘们иҰҒжҠҠзҪ‘з»ңзҡ„еҸӮж•°net.parameters()дј е…ҘдјҳеҢ–еҷЁдёӯпјҢ并и®ҫзҪ®еӯҰд№ зҺҮпјҲдёҖиҲ¬е°ҸдәҺ1пјүгҖӮ
з”ұдәҺиҝҷйҮҢжҳҜеӣһеҪ’д»»еҠЎпјҢжҲ‘们йҖүжӢ©torch.nn.MSELoss()дҪңдёәжҚҹеӨұеҮҪж•°гҖӮ
з”ұдәҺдјҳеҢ–еҷЁжҳҜеҹәдәҺжўҜеәҰжқҘдјҳеҢ–еҸӮж•°зҡ„пјҢ并且жўҜеәҰдјҡдҝқеӯҳеңЁе…¶дёӯгҖӮжүҖд»ҘеңЁжҜҸж¬ЎдјҳеҢ–еүҚиҰҒйҖҡиҝҮoptimizer.zero_grad()жҠҠжўҜеәҰзҪ®йӣ¶пјҢ然еҗҺеҶҚеҗҺеҗ‘дј ж’ӯеҸҠжӣҙж–°гҖӮ
5.еҸҜи§ҶеҢ–и®ӯз»ғиҝҮзЁӢ
plt.ion() # something about plotting
for t in range(100):
...
if t % 5 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data[0], fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
6.иҝҗиЎҢз»“жһң
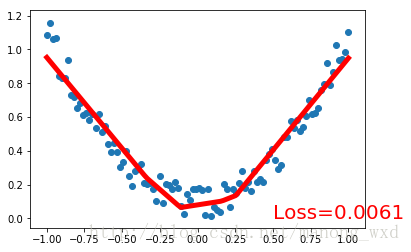
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ