您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了python如何实现爬虫程序,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
什么是网络爬虫
简单的讲,网络爬虫就是模拟人访问web站点的行为来获取有价值的数据。专业的解释:百度百科
分析爬虫需求
确定目标
爬取豆瓣热度在Top100以内的电影的一些信息,包括电影的名称、豆瓣评分、导演、编剧、主演、类型、制片国家/地区、语言、上映日期、片长、IMDb链接等信息。
分析目标
1.借助工具分析目标网页
首先,我们打开豆瓣电影·热门电影,会发现页面总共20部电影,但当查看页面源代码当时候,在源代码中根本找不到这些电影当信息。这是为什么呢?原来豆瓣在这里是通过ajax技术获取电影信息,再动态的将数据加载到页面中的。这就需要借助Chrome的开发者工具,先找到获取电影信息的API。
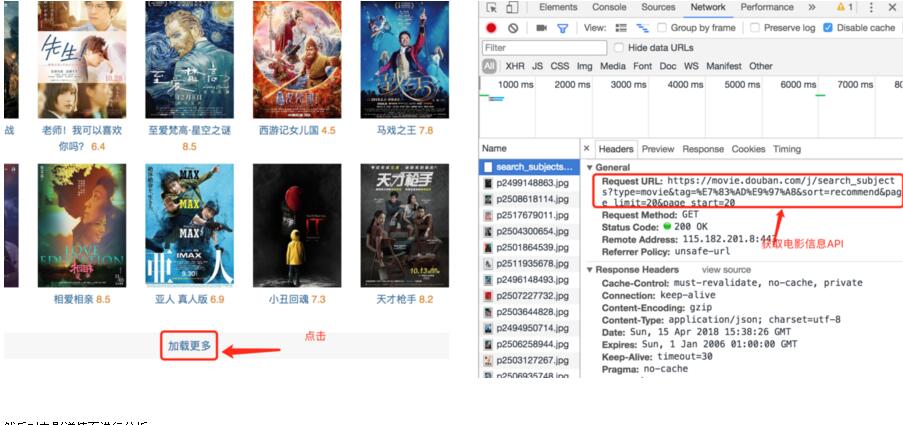
然后对电影详情页进行分析
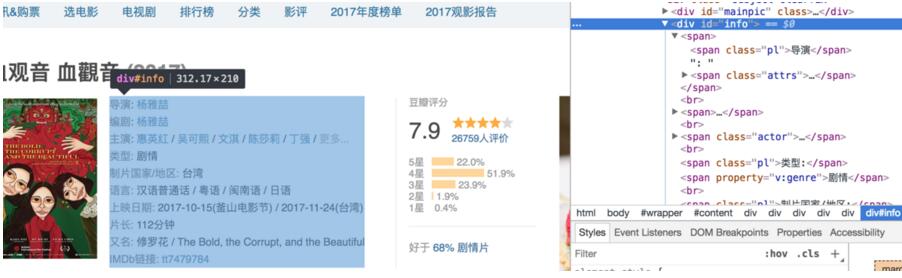
思路分析
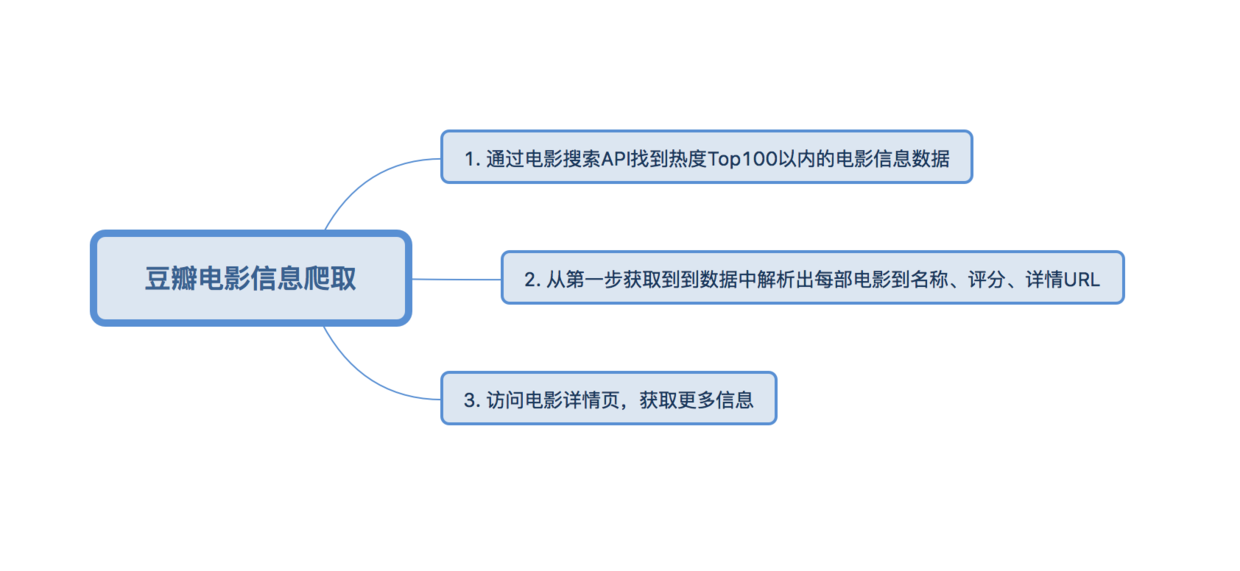
具体实现
开发环境
python3.6
pycharm
主要依赖库
urllib -- 基础性的网络相关操作
lxml -- 通过xpath语法解析HTML页面
json -- 对通过API获取的JSON数据进行操作
re -- 正则操作
代码实现
from urllib import request
from lxml import etree
import json
import re
import ssl
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
def get_headers():
"""
返回请求头信息
:return:
"""
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/65.0.3325.181 Safari/537.36"
}
return headers
def get_url_content(url):
"""
获取指定url的请求内容
:param url:
:return:
"""
content = ''
headers = get_headers()
res = request.Request(url, headers=headers)
try:
resp = request.urlopen(res, timeout=10)
content = resp.read().decode('utf-8')
except Exception as e:
print('exception: %s' % e)
return content
def parse_content(content):
"""
解析网页
:param content:
:return:
"""
movie = {}
html = etree.HTML(content)
try:
info = html.xpath("//div[@id='info']")[0]
movie['director'] = info.xpath("./span[1]/span[2]/a/text()")[0]
movie['screenwriter'] = info.xpath("./span[2]/span[2]/a/text()")[0]
movie['actors'] = '/'.join(info.xpath("./span[3]/span[2]/a/text()"))
movie['type'] = '/'.join(info.xpath("./span[@property='v:genre']/"
"text()"))
movie['initialReleaseDate'] = '/'.\
join(info.xpath(".//span[@property='v:initialReleaseDate']/text()"))
movie['runtime'] = \
info.xpath(".//span[@property='v:runtime']/text()")[0]
def str_strip(s):
return s.strip()
def re_parse(key, regex):
ret = re.search(regex, content)
movie[key] = str_strip(ret[1]) if ret else ''
re_parse('region', r'<span class="pl">制片国家/地区:</span>(.*?)<br/>')
re_parse('language', r'<span class="pl">语言:</span>(.*?)<br/>')
re_parse('imdb', r'<span class="pl">IMDb链接:</span> <a href="(.*?)" rel="external nofollow" '
r'target="_blank" >')
except Exception as e:
print('解析异常: %s' % e)
return movie
def spider():
"""
爬取豆瓣前100部热门电影
:return:
"""
recommend_moives = []
movie_api = 'https://movie.douban.com/j/search_subjects?' \
'type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend' \
'&page_limit=100&page_start=0'
content = get_url_content(movie_api)
json_dict = json.loads(content)
subjects = json_dict['subjects']
for subject in subjects:
content = get_url_content(subject['url'])
movie = parse_content(content)
movie['title'] = subject['title']
movie['rate'] = subject['rate']
recommend_moives.append(movie)
print(len(recommend_moives))
print(recommend_moives)
if __name__ == '__main__':
spider()效果
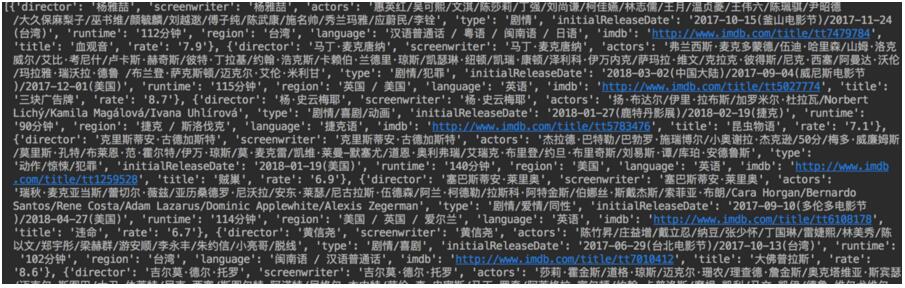
感谢你能够认真阅读完这篇文章,希望小编分享的“python如何实现爬虫程序”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。