您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下Node.js中怎么爬取豆瓣数据,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
1、需要解决的问题
搭建服务
怎么处理爬到的数据
怎么自动打开默认浏览器
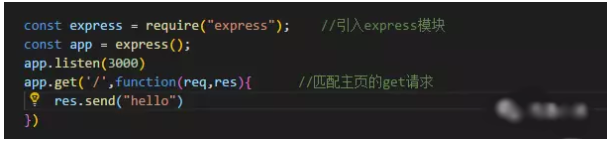
2、搭建服务
搭建服务有好几种方式,一开始我用的http,但是http有个弊端就是不能解析https协议的url,所以就用了express,解析https协议的网址我用了request包,豆瓣的网址是https的,
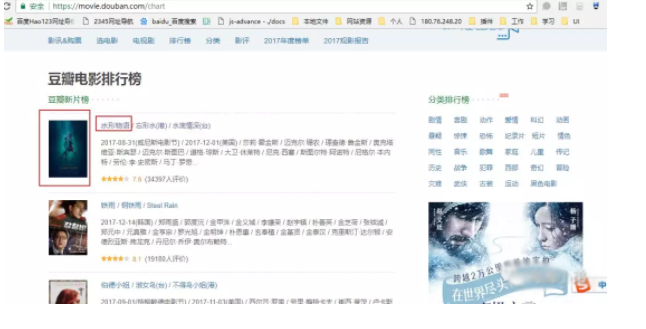
今天爬取的是https://movie.douban.com/chart这个网址;如下图,我要获取的有三个部分,图片、电影名字、电影链接.
3、怎么处理爬到的数据
我们用request爬到的数据,怎么处理呢?cheerio包可以让我们像Jq那样处理爬到的html数据。
①、首先解析数据,取到爬取网页的html数据;
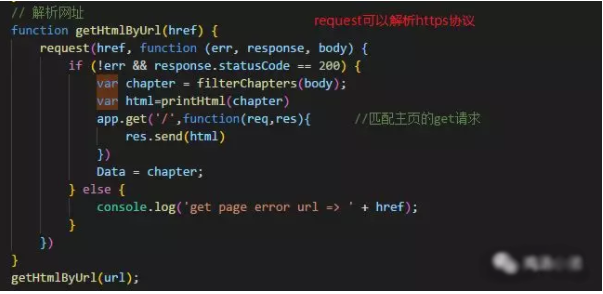
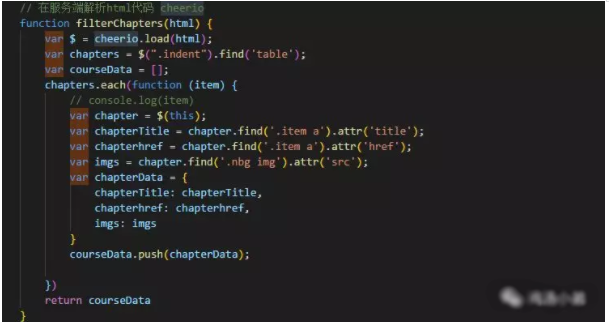
②、然后利用cheerio包操作爬到的数据,取到你想要的数据。
③、取到数据,创建html,输出到页面。如下图,我用的字符串拼接,办法有点笨,还没有找到更好的办法。
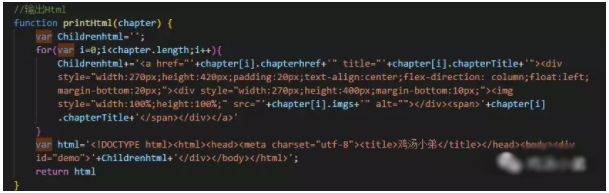
4、怎么自动打开默认浏览器
不知道你有没有看vue-cli中webpack的配置,自动打开浏览器,vue-cli用的opn包.
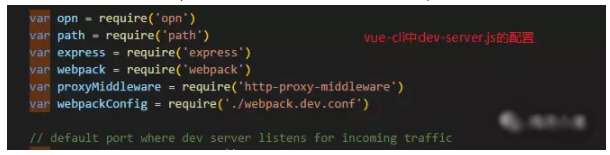
这个包用起来很方便,引入包,直接调用opn(url)即可;
5、展示
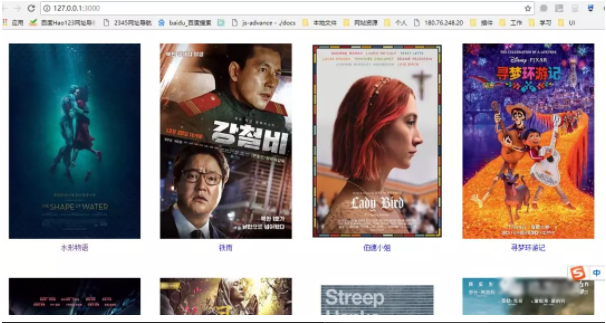
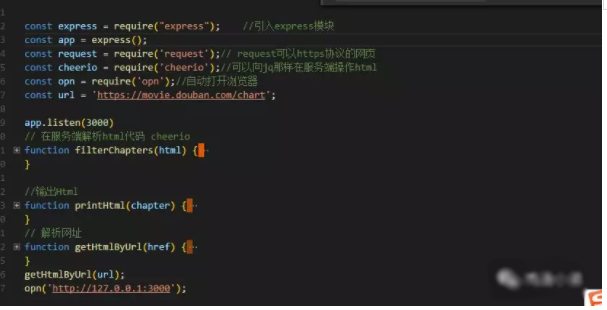
以上是“Node.js中怎么爬取豆瓣数据”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。