жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPythonе®һзҺ°зҲ¬еҸ–иұҶз“Јж•°жҚ®пјҢж–Үз« еҶ…е®№иҙЁйҮҸиҫғй«ҳпјҢеӣ жӯӨе°Ҹзј–еҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҜ№зӣёе…ізҹҘиҜҶжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
д»Јз ҒеҰӮдёӢ
from bs4 import BeautifulSoup #зҪ‘йЎөи§ЈжһҗпјҢиҺ·еҸ–ж•°жҚ® import sys #жӯЈеҲҷиЎЁиҫҫејҸпјҢиҝӣиЎҢж–Үеӯ—еҢ№й…Қ import re import urllib.request,urllib.error #жҢҮе®ҡurlпјҢиҺ·еҸ–зҪ‘йЎөж•°жҚ® import xlwt #дҪҝз”ЁиЎЁж ј import sqlite3 import lxml
д»ҘдёҠжҳҜеј•з”Ёзҡ„еә“пјҢеј•з”Ёеә“зҡ„ж–№жі•еҫҲз®ҖеҚ•пјҢзӣҙжҺҘдёҠеӣҫпјҡ
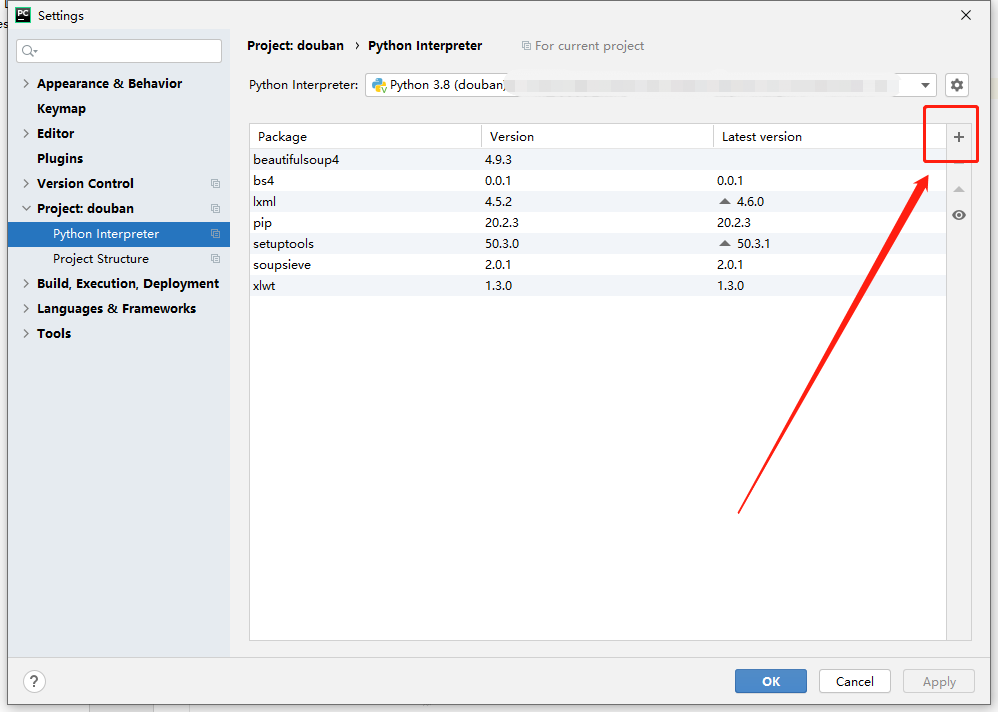
дёҠйқўз¬¬дёҖжӯҘз®—жңүдәҶпјҢдёӢйқўеҲҶжЁЎеқ—жқҘпјҢжӯҘйӘӨ算第дәҢжӯҘжқҘпјҡ
иҝҷдёӘж”ҫеңЁејҖеӨҙ
def main():
baseurl ="https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath=('douban.xls')
saveData(datalist,savepath)иҝҷдёӘж”ҫеңЁжң«е°ҫ
if __name__ == '__main__':
main()
дёҚйҡҫзңӢеҮәиҝҷжҳҜдё»еҮҪж•°пјҢйҮҢйқўзҡ„иҜқжҳҜеҜ№еӯҗеҮҪж•°зҡ„и°ғз”ЁпјҢдёӢйқўжҳҜ第дёүдёӘжӯҘйӘӨпјҡеӯҗеҮҪж•°зҡ„д»Јз Ғ
еҜ№зҪ‘йЎөжӯЈеҲҷиЎЁиҫҫжҸҗеҸ–пјҲж”ҫеңЁдё»еҮҪж•°зҡ„еҗҺйқўе°ұеҸҜд»Ҙпјү
findLink = re.compile(r'<a href="(.*?)" rel="external nofollow" rel="external nofollow" >') #еҲӣе»әжӯЈеҲҷиЎЁиҫҫејҸеҜ№иұЎпјҢиЎЁзӨә规еҲҷпјҲеӯ—з¬ҰдёІзҡ„жЁЎејҸпјү
#еҪұзүҮеӣҫзүҮ
findImg = re.compile(r'<img.*src="(.*?)" width="100"/>',re.S)#re.SеҸ–ж¶ҲжҚўиЎҢз¬Ұ
#еҪұзүҮзүҮйқў
findtitle= re.compile(r'<span class="title">(.*?)</span>')
#еҪұзүҮиҜ„еҲҶ
fileRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
#жүҫеҲ°иҜ„д»·зҡ„дәәж•°
findJudge = re.compile(r'<span>(\d*)дәәиҜ„д»·</span>')
#жүҫеҲ°жҰӮиҜҶ
findInq =re.compile(r'<span class="inq">(.*?)</span>')
#жүҫеҲ°еҪұзүҮзҡ„зӣёе…іеҶ…е®№
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
зҲ¬ж•°жҚ®ж ёеҝғеҮҪж•°
def getData(baseurl):
datalist=[]
for i in range(0,10):#и°ғз”ЁиҺ·еҸ–йЎөйқўзҡ„еҮҪж•°10ж¬Ў
url = baseurl + str(i*25)
html = askURl(url)
#йҖҗдёҖи§Јжһҗ
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data=[]
item = str(item)
link = re.findall(findLink,item)[0] #reеә“з”ЁжқҘйҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸжҹҘжүҫжҢҮе®ҡзҡ„еӯ—з¬ҰдёІ
data.append(link)
titles =re.findall(findtitle,item)
if(len(titles)==2):
ctitle=titles[0].replace('\xa0',"")
data.append(ctitle)#ж·»еҠ дёӯж–ҮеҗҚ
otitle = titles[1].replace("\xa0/\xa0Perfume:","")
data.append(otitle)#ж·»еҠ еӨ–еӣҪеҗҚ
else:
data.append(titles[0])
data.append(' ')#еӨ–еӣҪеҗҚеӯ—з•ҷз©ә
imgSrc = re.findall(findImg,item)[0]
data.append(imgSrc)
rating=re.findall(fileRating,item)[0]
data.append(rating)
judgenum = re.findall(findJudge,item)[0]
data.append(judgenum)
inq=re.findall(findInq,item)
if len(inq) != 0:
inq =inq[0].replace(".","")
data.append(inq)
else:
data.append(" ")
bd=re.findall(findBd,item)[0]
bd=re.sub('<br(\s+)?/>(\s+)?'," ",bd) #еҺ»жҺү<br/>
bd =re.sub('\xa0'," ",bd)
data.append(bd.strip()) #еҺ»жҺүеүҚеҗҺзҡ„з©әж ј
datalist.append(data) #жҠҠеӨ„зҗҶеҘҪзҡ„дёҖйғЁз”өеҪұдҝЎжҒҜж”ҫе…Ҙdatalist
return datalistиҺ·еҸ–жҢҮе®ҡзҪ‘йЎөеҶ…е®№
def askURl(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;WOW64) Apple"
+"WebKit / 537.36(KHTML, likeGecko) Chrome / 78.0.3904.108 Safari / 537.36"
}
#е‘ҠиҜүиұҶз“ЈжҲ‘们жҳҜжөҸи§ҲеҷЁжҲ‘们еҸҜд»ҘжҺҘеҸ—д»Җд№Ҳж°ҙе№ізҡ„еҶ…е®№
request = urllib.request.Request(url,headers=head)
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return htmlе°ҶзҲ¬дёӢжқҘзҡ„ж•°жҚ®дҝқеӯҳеҲ°иЎЁж јдёӯ
ef saveData(datalist,savepath):
print("дҝқеӯҳдёӯгҖӮгҖӮгҖӮ")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # еҲӣе»әworkbookеҜ№иұЎ
sheet = book.add_sheet('douban',cell_overwrite_ok=True) #еҲӣе»әе·ҘдҪңиЎЁ cell_overwrite_okиЎЁзӨәзӣҙжҺҘиҰҶзӣ–
col = ("з”өеҪұиҜҰжғ…й“ҫжҺҘ","еҪұзүҮдёӯж–ҮзҪ‘","еҪұзүҮеӨ–еӣҪеҗҚ","еӣҫзүҮй“ҫжҺҘ","иҜ„еҲҶ","иҜ„д»·ж•°","жҰӮеҶө","зӣёе…ідҝЎжҒҜ")
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%dжқЎ" %(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)д»ҘдёҠе°ұжҳҜж•ҙдёӘзҲ¬ж•°жҚ®зҡ„ж•ҙдёӘзЁӢеәҸпјҢиҝҷд»…д»…жҳҜдёҖдёӘйқһеёёз®ҖеҚ•зҡ„зҲ¬еҸ–пјҢеҰӮжһңжғіиҰҒзҲ¬жӣҙйҡҫзҡ„зҪ‘йЎөйңҖиҰҒе®һж—¶еҲҶжһҗ
ж•ҙдёӘзЁӢеәҸд»Јз Ғ
from bs4 import BeautifulSoup #зҪ‘йЎөи§ЈжһҗпјҢиҺ·еҸ–ж•°жҚ®
import sys #жӯЈеҲҷиЎЁиҫҫејҸпјҢиҝӣиЎҢж–Үеӯ—еҢ№й…Қ
import re
import urllib.request,urllib.error #жҢҮе®ҡurlпјҢиҺ·еҸ–зҪ‘йЎөж•°жҚ®
import xlwt #дҪҝз”ЁиЎЁж ј
import sqlite3
import lxml
def main():
baseurl ="https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath=('douban.xls')
saveData(datalist,savepath)
#еҪұзүҮж’ӯж”ҫй“ҫжҺҘ
findLink = re.compile(r'<a href="(.*?)" rel="external nofollow" rel="external nofollow" >') #еҲӣе»әжӯЈеҲҷиЎЁиҫҫејҸеҜ№иұЎпјҢиЎЁзӨә规еҲҷпјҲеӯ—з¬ҰдёІзҡ„жЁЎејҸпјү
#еҪұзүҮеӣҫзүҮ
findImg = re.compile(r'<img.*src="(.*?)" width="100"/>',re.S)#re.SеҸ–ж¶ҲжҚўиЎҢз¬Ұ
#еҪұзүҮзүҮйқў
findtitle= re.compile(r'<span class="title">(.*?)</span>')
#еҪұзүҮиҜ„еҲҶ
fileRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
#жүҫеҲ°иҜ„д»·зҡ„дәәж•°
findJudge = re.compile(r'<span>(\d*)дәәиҜ„д»·</span>')
#жүҫеҲ°жҰӮиҜҶ
findInq =re.compile(r'<span class="inq">(.*?)</span>')
#жүҫеҲ°еҪұзүҮзҡ„зӣёе…іеҶ…е®№
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
def getData(baseurl):
datalist=[]
for i in range(0,10):#и°ғз”ЁиҺ·еҸ–йЎөйқўзҡ„еҮҪж•°10ж¬Ў
url = baseurl + str(i*25)
html = askURl(url)
#йҖҗдёҖи§Јжһҗ
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data=[]
item = str(item)
link = re.findall(findLink,item)[0] #reеә“з”ЁжқҘйҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸжҹҘжүҫжҢҮе®ҡзҡ„еӯ—з¬ҰдёІ
data.append(link)
titles =re.findall(findtitle,item)
if(len(titles)==2):
ctitle=titles[0].replace('\xa0',"")
data.append(ctitle)#ж·»еҠ дёӯж–ҮеҗҚ
otitle = titles[1].replace("\xa0/\xa0Perfume:","")
data.append(otitle)#ж·»еҠ еӨ–еӣҪеҗҚ
else:
data.append(titles[0])
data.append(' ')#еӨ–еӣҪеҗҚеӯ—з•ҷз©ә
imgSrc = re.findall(findImg,item)[0]
data.append(imgSrc)
rating=re.findall(fileRating,item)[0]
data.append(rating)
judgenum = re.findall(findJudge,item)[0]
data.append(judgenum)
inq=re.findall(findInq,item)
if len(inq) != 0:
inq =inq[0].replace(".","")
data.append(inq)
else:
data.append(" ")
bd=re.findall(findBd,item)[0]
bd=re.sub('<br(\s+)?/>(\s+)?'," ",bd) #еҺ»жҺү<br/>
bd =re.sub('\xa0'," ",bd)
data.append(bd.strip()) #еҺ»жҺүеүҚеҗҺзҡ„з©әж ј
datalist.append(data) #жҠҠеӨ„зҗҶеҘҪзҡ„дёҖйғЁз”өеҪұдҝЎжҒҜж”ҫе…Ҙdatalist
return datalist
#еҫ—еҲ°жҢҮе®ҡдёҖдёӘurlзҡ„зҪ‘йЎөеҶ…е®№
def askURl(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;WOW64) Apple"
+"WebKit / 537.36(KHTML, likeGecko) Chrome / 78.0.3904.108 Safari / 537.36"
}
#е‘ҠиҜүиұҶз“ЈжҲ‘们жҳҜжөҸи§ҲеҷЁжҲ‘们еҸҜд»ҘжҺҘеҸ—д»Җд№Ҳж°ҙе№ізҡ„еҶ…е®№
request = urllib.request.Request(url,headers=head)
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def saveData(datalist,savepath):
print("дҝқеӯҳдёӯгҖӮгҖӮгҖӮ")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # еҲӣе»әworkbookеҜ№иұЎ
sheet = book.add_sheet('douban',cell_overwrite_ok=True) #еҲӣе»әе·ҘдҪңиЎЁ cell_overwrite_okиЎЁзӨәзӣҙжҺҘиҰҶзӣ–
col = ("з”өеҪұиҜҰжғ…й“ҫжҺҘ","еҪұзүҮдёӯж–ҮзҪ‘","еҪұзүҮеӨ–еӣҪеҗҚ","еӣҫзүҮй“ҫжҺҘ","иҜ„еҲҶ","иҜ„д»·ж•°","жҰӮеҶө","зӣёе…ідҝЎжҒҜ")
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%dжқЎ" %(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)
if __name__ == '__main__':
main()е…ідәҺPythonе®һзҺ°зҲ¬еҸ–иұҶз“Јж•°жҚ®е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ